推荐:使用NSDT场景编辑器助你快速搭建3D应用场景
XGBoost 应用程序的常见情况是分类预测(如欺诈检测)或回归预测(如房价预测)。但是,也可以扩展 XGBoost 算法以预测时间序列数据。它是如何工作的?让我们进一步探讨这一点。
时间序列预测
数据科学和机器学习中的预测是一种技术,用于根据一段时间内收集的历史数据(以定期或不定期间隔)预测未来的数值。
与每个观测值都独立于另一个观测值的常见机器学习训练数据不同,时序预测的数据必须按连续顺序排列并与每个数据点相关。例如,时间序列数据可以包括月度库存、每周天气、每日销售额等。
让我们看一下来自 Kaggle 的示例时间序列数据每日气候数据。
import pandas as pd
train = pd.read_csv('DailyDelhiClimateTrain.csv')
test = pd.read_csv('DailyDelhiClimateTest.csv')
train.head()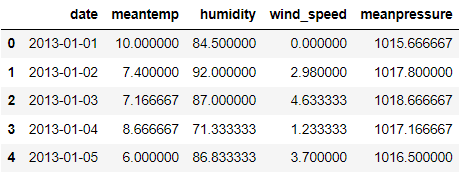
如果我们看一下上面的数据帧,每个特征都是每天记录的。日期列表示观测数据的时间,并且每个观测值都是相关的。
时间序列预测通常包含数据中的趋势、季节性和其他模式来创建预测。查看模式的一种简单方法是可视化它们。例如,我将可视化示例数据集中的平均温度数据。
train["date"] = pd.to_datetime(train["date"])
test["date"] = pd.to_datetime(test["date"])
train = train.set_index("date")
test = test.set_index("date")
train["meantemp"].plot(style="k", figsize=(10, 5), label="train")
test["meantemp"].plot(style="b", figsize=(10, 5), label="test")
plt.title("Mean Temperature Dehli Data")
plt.legend()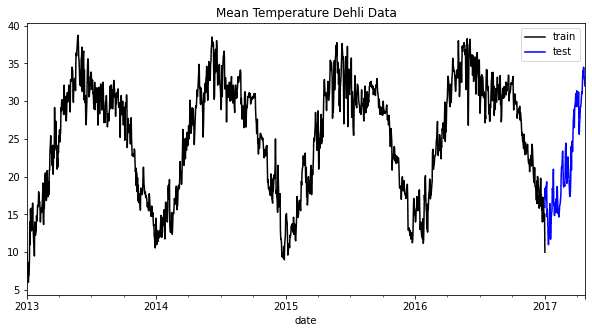
在上图中,我们很容易看到,每年都有一个共同的季节性模式。通过整合这些信息,我们可以了解数据的工作原理,并确定哪个模型可能适合我们的预测模型。
典型的预测模型包括 ARIMA、向量自回归、指数平滑和先知。但是,我们也可以利用XGBoost来提供预测。
XGBoost Forecasting
在准备使用 XGBoost 进行预测之前,我们必须先安装软件包。
pip install xgboost安装后,我们将为模型训练准备数据。理论上,XGBoost Forecasting将实现基于单个或多个特征的回归模型来预测未来的数值。这就是为什么数据训练也必须在数值中。此外,为了将时间运动纳入我们的XGBoost模型中,我们将时间数据转换为多个数值特征。
让我们首先创建一个函数来从日期创建数字特征。
def create_time_feature(df):
df['dayofmonth'] = df['date'].dt.day
df['dayofweek'] = df['date'].dt.dayofweek
df['quarter'] = df['date'].dt.quarter
df['month'] = df['date'].dt.month
df['year'] = df['date'].dt.year
df['dayofyear'] = df['date'].dt.dayofyear
df['weekofyear'] = df['date'].dt.weekofyear
return df接下来,我们将此函数应用于训练和测试数据。
train = create_time_feature(train)
test = create_time_feature(test)
train.head()
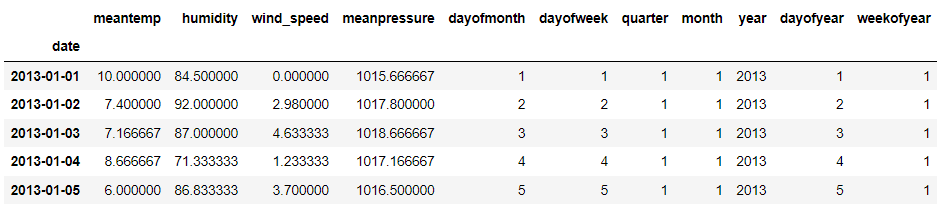
所需信息现已全部可用。接下来,我们将定义我们想要预测的内容。在此示例中,我们将预测平均温度并根据上述数据制作训练数据。
X_train = train.drop('meantemp', axis =1)
y_train = train['meantemp']
X_test = test.drop('meantemp', axis =1)
y_test = test['meantemp']我仍然会使用其他信息(例如湿度)来表明XGBoost也可以使用多变量方法预测值。但是,在实践中,我们只纳入我们在尝试预测时知道存在的数据。
让我们通过将数据拟合到模型中来开始训练过程。对于当前示例,除了树的数量之外,我们不会进行太多的超参数优化。
import xgboost as xgb
reg = xgb.XGBRegressor(n_estimators=1000)
reg.fit(X_train, y_train, verbose = False)在训练过程之后,让我们看看模型的特征重要性。
xgb.plot_importance(reg)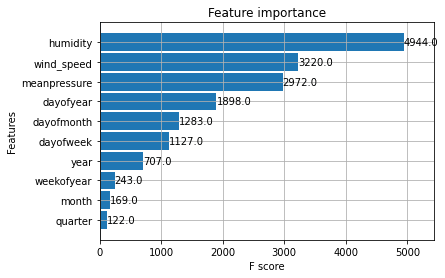
这三个初始特征对预测的帮助并不大,但时间特征也有助于预测。让我们尝试对测试数据进行预测并可视化它们。
test['meantemp_Prediction'] = reg.predict(X_test)
train['meantemp'].plot(style='k', figsize=(10,5), label = 'train')
test['meantemp'].plot(style='b', figsize=(10,5), label = 'test')
test['meantemp_Prediction'].plot(style='r', figsize=(10,5), label = 'prediction')
plt.title('Mean Temperature Dehli Data')
plt.legend()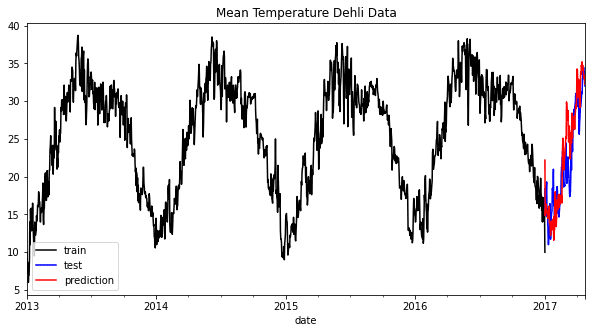
从上图可以看出,预测可能看起来略有偏差,但仍遵循整体趋势。让我们尝试根据错误指标评估模型。
from sklearn.metrics import mean_squared_error, mean_absolute_error, mean_absolute_percentage_error
print('RMSE: ', round(mean_squared_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAE: ', round(mean_absolute_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))
print('MAPE: ', round(mean_absolute_percentage_error(y_true=test['meantemp'],y_pred=test['meantemp_Prediction']),3))RMSE: 11.514
前:2.655
MAPE: 0.133
结果表明,我们的预测可能有13%左右的误差,RMSE在预测中也显示出轻微的误差。可以使用超参数优化来改进模型,但我们已经了解了如何将 XGBoost 用于预测。
结论
XGBoost是一种开源算法,通常用于许多数据科学案例和Kaggle竞赛。通常用例是常见的分类案例,如欺诈检测或回归案例,如房价预测,但XGBoost也可以扩展到时间序列预测。通过使用 XGBoost 回归器,我们可以创建一个可以预测未来数值的模型。
由3D建模学习工作室 整理翻译,转载请注明出处!
标签:meantemp,预测,df,XGBoost,test,train,序列 From: https://www.cnblogs.com/mvrlink/p/17652065.html