VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
论文:Huang, Wenlong et al., VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
https://voxposer.github.io/
https://voxposer.github.io/voxposer.pdf
stanford lifeifei等。一作wenlong huang参与了palm-e系列的工作,并且是Language models as zero-shot planners的一作
又是利用了everyday robot的机械臂
文章即将开源代码,现在开放了各阶段的Prompts
(把我的论文笔记放在这儿,如果有人看就接着写)
背景
- LLM具备很多actionable knowledge,之前微软ChatGPT for Robotics等工作利用LLM,通过推理和规划的方式在high-level/mid-level上操控机器人。但是他们往往需要预先定义好motion primitives,这是瓶颈(LLM4Robotics文档中提到的定义好控制原语上的瓶颈)
- 也属于LLM for Robotics
做了什么
-
用语言模型和视觉语言模型来提取affordance和constraints(可行性和约束),组成一个3D仿真环境中的value map
- 利用LLM代码编写能力,和视觉语言模型(VLM)交互
- 把知识融入agent的observation space中
-
在3D的仿真环境中,根据前面提取的affordance和constraint,motion planner可以通过一组开放的(自由形式的)语言指令和一组开放的对象,zero-shot地合成机器人操作任务的轨迹(6自由度,末端执行器)
-
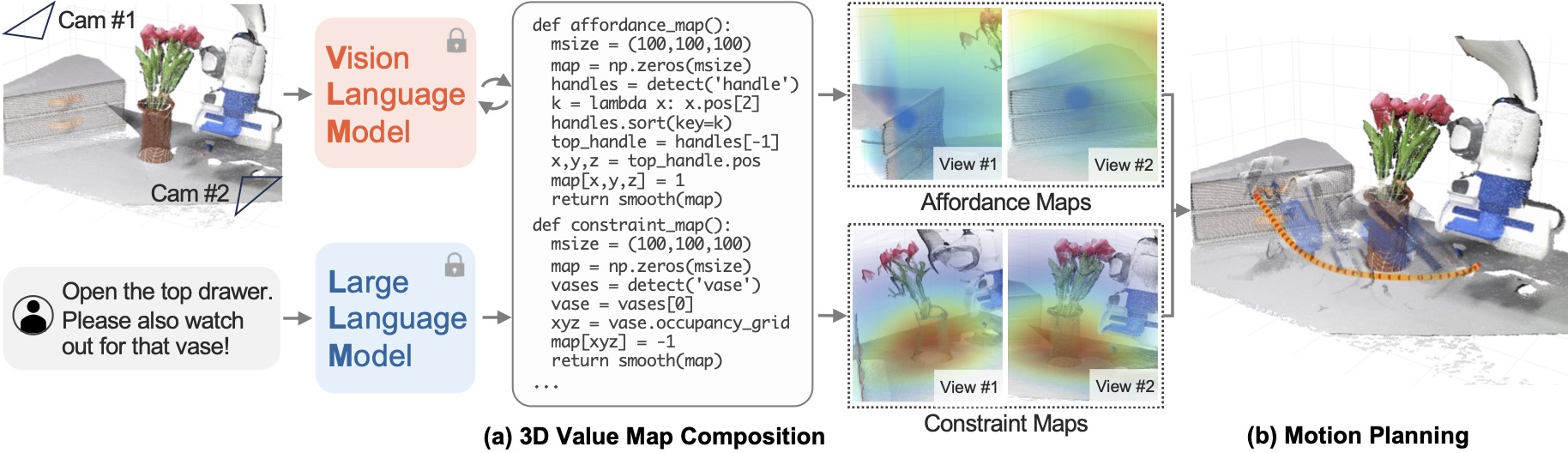
下图就是通过语言模型和视觉语言模型,在3D value map中识别出对应的物体"top drawer",识别出约束"watch out for that vase",然后在3D仿真中进行模拟操作"open"
-


-
在模拟和真实机器人环境中,展示了执行以自由形式的自然语言指定的 30 多种日常操作任务的能力。

怎么做的
-
下面的图中,首先有一个环境(3D仿真环境,两个视角),有个人为指定的语言目标,LLM和VLM交互生成绘制affordance和constraint value map的代码,然后代码绘制关于affordance和constraint的value map。
- 其中affordance maps中,蓝色区域就是要抓取操控的目标,代表high reward
- constraint map中,红色区域就是约束,也就是要避开的障碍,代表high cost
- value map中,机器人尽量往蓝色区域走,避开红色区域
-
结合这两个value map,motion planner操作机械臂去完成语言指定的目标
-
随着环境的变化,camera中的图像也会变化,VLM会持续改进代码,让机器人在不同阶段到达不同目标,多阶段地合成轨迹
-
每个阶段(子任务)是如何控制、得到轨迹的呢?采用的是零阶地优化下面的方程式,也就是随机采样轨迹然后评分。因为value map有效地给出了dense reward,而且可以在每一步都重新规划,所以他们惊讶地发现这样简单的启发式方法也可以实现各种具体任务
- \[\min_{\tau_i^r} \{F_{task}(T_i, l_i)+ F_{control}(\tau_i^r)\} \quad subject\ to\ C(T_i) \]
-
其中Ti是环境状态的演变,li是根据语言任务目标拆解出来的子任务,\(\tau_i^r\)是机器人的轨迹,Ftask是机器人达到各个子任务的程度的负值(轨迹的负value),Fcontrol是control的cost,C(Ti)是constraint
-
-
这里是没有训练的
- 真实环境部署:真实世界中,相当于已经有了3D环境,直接放两个相机,后面的步骤是一样的
- LLM使用的是GPT-4的API,VLM和感知:调用open-vocab detector OWL-ViT得到bounding box,通过SAM得到mask,然后用video tracker XMEM 来track the mask。 tracked mask使用RGB-D来重建3D点云。 (需要综合NLP、CV的很多工作和知识)
效果
- 真实环境——模拟环境
- 右图模拟环境中,展示了planning不同阶段的value map,planning过程中首先把毛巾拿起来,然后拿到架子上方,然后放手

-
可以抵抗外部干扰
- 因为语言模型(应该是指VLM)的输出和历史可以存下来,方法会闭环地处理视觉反馈、重新评估生成代码,因此人为给予干扰之后可以让语言模型重新生成代码,然后用MPC进行快速重新的规划
-
Emergent的行为能力
- 估计物理特性:给定两个质量未知的块,机器人的任务是使用可用的工具进行物理实验,以确定哪个块更重。
- 行为常识推理:在机器人摆桌子的任务中,用户可以指定行为偏好,例如“我是左撇子”,这需要机器人在任务上下文中理解其含义。
- 细粒度语言修正:对于“给茶壶盖上盖子”等精度要求较高的任务,用户可以向机器人发出“你偏离了1厘米”等精确指令。
- 多步视觉程序:给定一个“精确打开抽屉一半”的任务,由于没有对象模型,因此信息不足,但是机器人可以根据视觉反馈提出多步操作策略,首先完全打开抽屉,同时记录手柄位移,然后将其关闭抽屉至中点以满足要求。
潜在应用
- 利用value map热力图(蓝色区域表示目标位置,红色区域表示constraints)可以很好地表征3D空间中的特征,结合若干个camera视角就可以用上VLM。热力图是连接上层语义和下层操控的桥梁,整体连接方式如下:语言目标、3D环境->VLM,LLM->生成绘制affordance和constraint value map的代码->value map热力图->机器人各阶段操控
- 依赖于3D视觉的发展、视觉语言大模型的发展
- 热力图实际上就是表示了一个宏观一点的reward/cost,可以指导底层控制策略的cost(for MPC),或reward(for RL)
- 很重要的特点是,value map是一种特别精准的reward/cost
- 用这种热力图的方式来表示reward/cost,是直接用LLM表示reward/cost的替代方式
- 蓝色区域表示affordance,红色区域表示constraints这些重要信息都在value map中表示出来了
- 利用value map表示任务目标,合成的轨迹也可以通过MPC在大量操控任务中鲁棒地执行
- 从场景来看,这些机械臂系列的任务主要是局限空间中的手部的工作,比如家中的家务、工厂机械臂等。
局限性
- 下层的motion planner没有突破,可能导致其泛化性不是很好,在底层的操作上难以泛化到各种场景的各种物品(还有各种机械臂)
- 因为万一value map给得不精准、不dense或者有问题,就会导致的底层的MPC难以完成预期的目标
- 精细的区分视觉中的各个物体?涉及到更加强大的场景理解,VLM可能还是存在障碍。比如说眼前有五个瓶子,要拿起空瓶子扔掉。依赖于外部感知模块
- 需要繁琐的手工的prompt engineering
- 现在还是在桌面上的局限操作,没有扩展到更广阔的的空间
- 虽然适用于高效的动力学学习,但仍然需要通用的动力学模型来实现具有相同泛化水平的接触丰富的任务(?)
- 运动规划器仅考虑末端执行器轨迹,而全臂规划也是可行的,并且可能是更好的设计选择
- 太慢了,视频中即使是加速8倍,仍然很慢。可能是因为拆分的subtask较多,或者每个subtask需要根据视觉反馈、LLM输出来调整代码、调用控制模块解算控制轨迹,合起来就比较慢