深入探索智能未来:文本生成与问答模型的创新融合
1.Filling Model with T5
1.1背景介绍
该项目用于将句子中 [MASK] 位置通过生成模型还原,以实现 UIE 信息抽取中 Mask Then Filling 数据增强策略。
Mask Then Fill 是一种基于生成模型的信息抽取数据增强策略。对于一段文本,我们其分为「关键信息段」和「非关键信息段」,包含关键词片段称为「关键信息段」。下面例子中标粗的为 关键信息片段,其余的为 非关键片段。
大年三十 我从 北京 的大兴机场 飞回 了 成都。
我们随机 [MASK] 住一部分「非关键片段」,使其变为:
大年三十 我从 北京 [MASK] 飞回 了 成都。
随后,将改句子喂给 filling 模型(T5-Fine Tuned)还原句子,得到新生成的句子:
大年三十 我从 北京 首都机场作为起点,飞回 了 成都。
- 环境安装
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
pip install -r ../requirements.txt
- 数据集准备
项目中提供了一部分示例数据,数据来自DuIE数据集中的文本数据,数据在 data/ 。
若想使用 自定义数据 训练,只需要仿照示例数据构建带 [MASK] 的文本即可,你也可以使用 parse_data.py 快速生成基于 词粒度 的训练数据:
"Bortolaso Guillaume,法国籍[MASK]"中[MASK]位置的文本是: 运动员
"歌曲[MASK]是由歌手海生演唱的一首歌曲"中[MASK]位置的文本是: 《情一动心就痛》
...
每一行用 \t 分隔符分开,第一部分部分为 带[MASK]的文本,后一部分为 [MASK]位置的原始文本(label)。
1.2. 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python train.py \
--pretrained_model "uer/t5-base-chinese-cluecorpussmall" \
--save_dir "checkpoints/t5" \
--train_path "data/train.tsv" \
--dev_path "data/dev.tsv" \
--img_log_dir "logs" \
--img_log_name "T5-Base-Chinese" \
--batch_size 128 \
--max_source_seq_len 128 \
--max_target_seq_len 32 \
--learning_rate 1e-4 \
--num_train_epochs 20 \
--logging_steps 50 \
--valid_steps 500 \
--device cuda:0
正确开启训练后,终端会打印以下信息:
...
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 21.28it/s]
DatasetDict({
train: Dataset({
features: ['text'],
num_rows: 350134
})
dev: Dataset({
features: ['text'],
num_rows: 38904
})
})
...
global step 2400, epoch: 1, loss: 7.44746, speed: 0.82 step/s
global step 2450, epoch: 1, loss: 7.42028, speed: 0.82 step/s
global step 2500, epoch: 1, loss: 7.39333, speed: 0.82 step/s
Evaluation bleu4: 0.00578
best BLEU-4 performence has been updated: 0.00026 --> 0.00578
global step 2550, epoch: 1, loss: 7.36620, speed: 0.81 step/s
...
在 logs/T5-Base-Chinese.png 文件中将会保存训练曲线图:
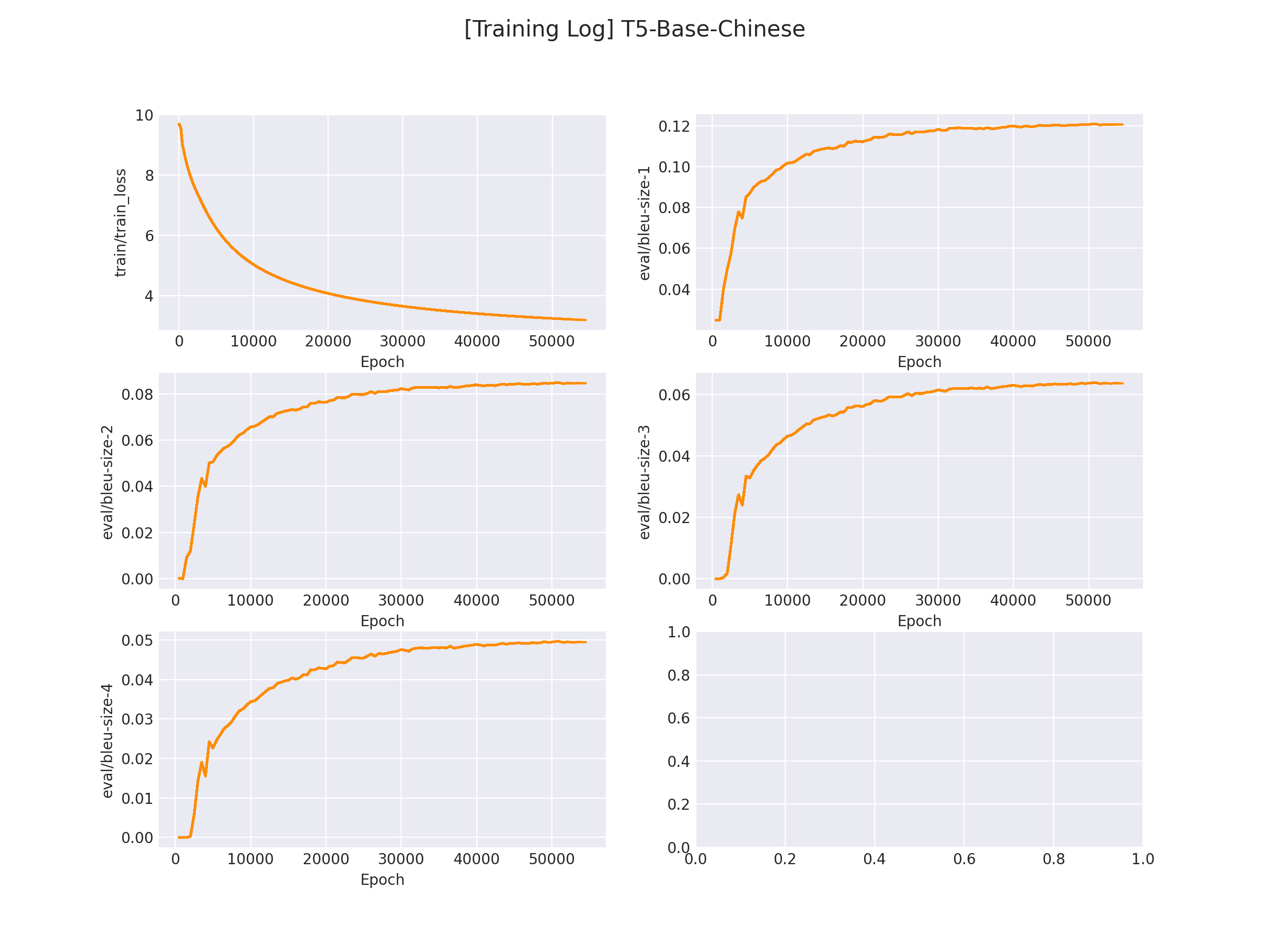
1.3 模型预测
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
if __name__ == "__main__":
masked_texts = [
'"《μVision2单片机应用程序开发指南》是2005年2月[MASK]图书,作者是李宇"中[MASK]位置的文本是:'
]
inference(masked_texts)
python inference.py
得到以下推理结果:
maksed text:
[
'"《μVision2单片机应用程序开发指南》是2005年2月[MASK]图书,作者是李宇"中[MASK]位置的文本是:'
]
output:
[
',中国工业出版社出版的'
]
2.问答模型(Text-Generation, T5 Based)
2.1 背景介绍
问答模型是指通过输入一个「问题」和一段「文章」,输出「问题的答案」。
问答模型分为「抽取式」和「生成式」,抽取式问答可以使用 [UIE] 训练,这个实验中我们将使用「生成式」模型来训练一个问答模型。
我们选用「T5」作为 backbone,使用百度开源的「QA数据集」来训练得到一个生成式的问答模型。
- 环境安装
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
pip install -r ../requirements.txt
2.2 数据集准备
项目中提供了一部分示例数据,数据是百度开源的问答数据集,数据在 data/DuReaderQG 。
若想使用自定义数据训练,只需要仿照示例数据构建数据集即可:
{"context": "违规分为:一般违规扣分、严重违规扣分、出售假冒商品违规扣分,淘宝网每年12月31日24:00点会对符合条件的扣分做清零处理,详情如下:|温馨提醒:由于出售假冒商品24≤N<48分,当年的24分不清零,所以会存在第一年和第二年的不同计分情况。", "answer": "12月31日24:00", "question": "淘宝扣分什么时候清零", "id": 203}
{"context": "生长速度 头发是毛发中生长最快的毛发,一般每天长0.27—0.4mm,每月平均生长约1.0cm,一年大概长10—14cm。但是,头发不可能无限制的生长,一般情况下,头发长至50—60cm,就会脱落再生新发。", "answer": "0.27—0.4mm", "question": "头发一天能长多少", "id": 328}
...
每一行为一个数据样本,json 格式。
其中,"context" 代表参考文章,question 代表问题,"answer" 代表问题答案。
2.3 模型训练
修改训练脚本 train.sh 里的对应参数, 开启模型训练:
python train.py \
--pretrained_model "uer/t5-base-chinese-cluecorpussmall" \
--save_dir "checkpoints/DuReaderQG" \
--train_path "data/DuReaderQG/train.json" \
--dev_path "data/DuReaderQG/dev.json" \
--img_log_dir "logs/DuReaderQG" \
--img_log_name "T5-Base-Chinese" \
--batch_size 32 \
--learning_rate 1e-4 \
--max_source_seq_len 256 \
--max_target_seq_len 32 \
--learning_rate 5e-5 \
--num_train_epochs 50 \
--logging_steps 10 \
--valid_steps 500 \
--device "cuda:0"
正确开启训练后,终端会打印以下信息:
...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 650.73it/s]
DatasetDict({
train: Dataset({
features: ['text'],
num_rows: 14520
})
dev: Dataset({
features: ['text'],
num_rows: 984
})
global step 10, epoch: 1, loss: 9.39613, speed: 1.60 step/s
global step 20, epoch: 1, loss: 9.39434, speed: 1.71 step/s
global step 30, epoch: 1, loss: 9.39222, speed: 1.72 step/s
global step 40, epoch: 1, loss: 9.38739, speed: 1.63 step/s
global step 50, epoch: 1, loss: 9.38296, speed: 1.63 step/s
global step 60, epoch: 1, loss: 9.37982, speed: 1.71 step/s
global step 70, epoch: 1, loss: 9.37385, speed: 1.71 step/s
global step 80, epoch: 1, loss: 9.36876, speed: 1.69 step/s
global step 90, epoch: 1, loss: 9.36209, speed: 1.72 step/s
global step 100, epoch: 1, loss: 9.35349, speed: 1.70 step/s
...
在 logs/DuReaderQG 文件下将会保存训练曲线图:
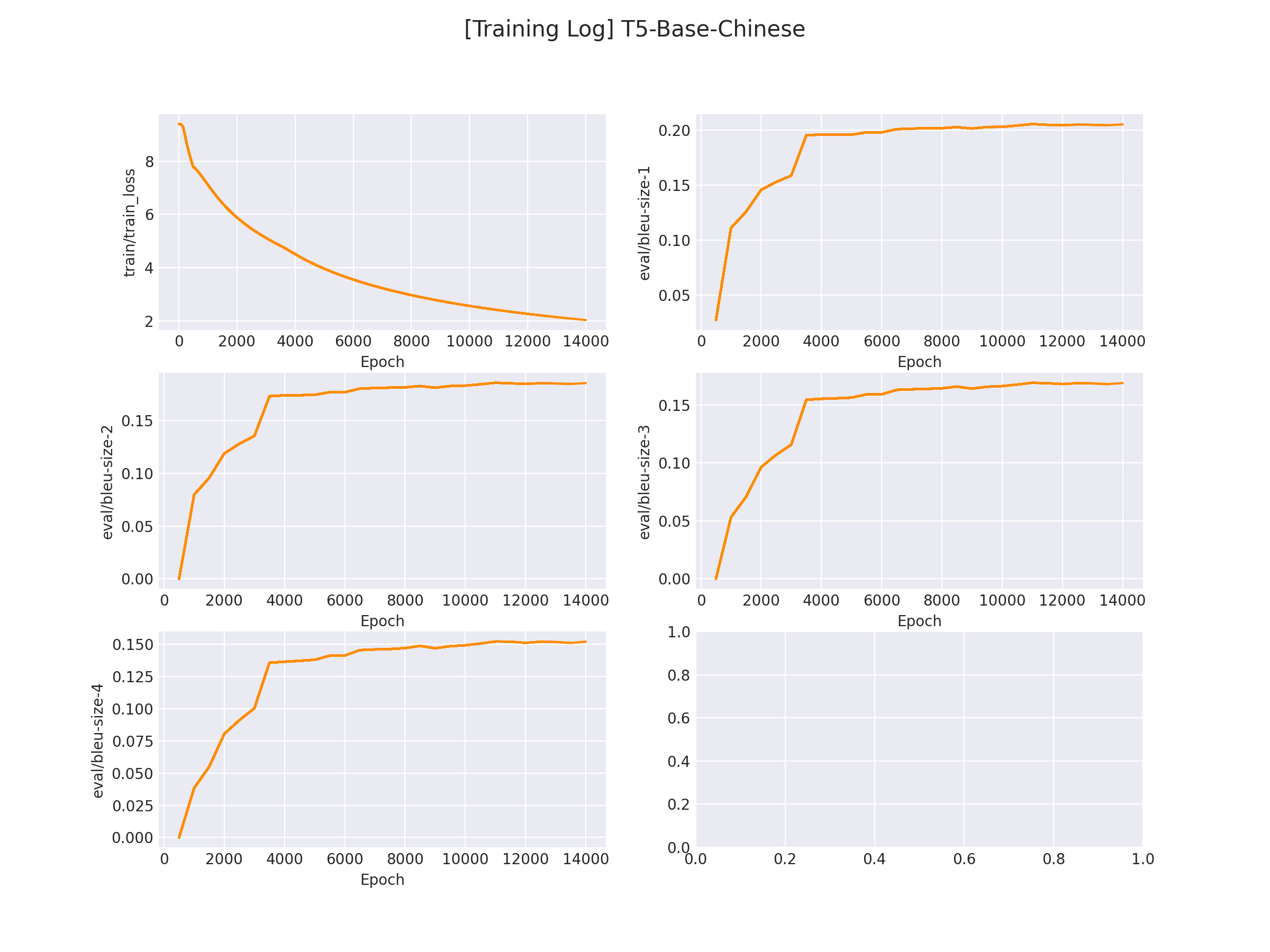
2.4 模型推理
完成模型训练后,运行 inference.py 以加载训练好的模型并应用:
...
if __name__ == '__main__':
question = '治疗宫颈糜烂的最佳时间'
context = '专家指出,宫颈糜烂治疗时间应选在月经干净后3-7日,因为治疗之后宫颈有一定的创面,如赶上月经期易发生感染。因此患者应在月经干净后3天尽快来医院治疗。同时应该注意,术前3天禁同房,有生殖道急性炎症者应治好后才可进行。'
inference(qustion=question, context=context)
运行推理程序:
python inference.py
得到以下推理结果:
Q: "治疗宫颈糜烂的最佳时间"
C: "专家指出,宫颈糜烂治疗时间应选在月经干净后3-7日,因为治疗之后宫颈有一定的创面,如赶上月经期易发生感染。因此患者应在月经干净后3天尽快来医院治疗。同时应该注意,术前3天禁同房,有生殖道急性炎症者应治好后才可进行。"
A: "答案:月经干净后3-7日"
项目链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/answer_generation/readme.md
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
