准备知识
PyTorch分布式通信的程序包相关的API。
torch.distributed.init_process_group(),初始化进程组。torch.distributed.get_rank(),可以获得当前进程的rank,rank % torch.torch.cuda.device_count()可以得到当前节点的ranklocal_rank。torch.distributed.get_world_size(),可以获得进程组的进程数量。torch.distributed.barrier(),同步进程组内的所有进程,阻塞所有进程直到所有进程都执行到操作。
调用集合通信API前,必须先初始化进程组torch.distributed.init_process_group("nccl")。
如何运行多机多卡训练程序?
deepspeed、torch实现了命令行launcher程序deepspeed 和torchrun。
launcher程序里,会创建RANK、WORLD_SIZE等环境变量。
以deepspeed为例:
deepspeed --num_gpus NUM_GPUS --num_nodes NUM_NODES --hostfile HOSTFILE program.py
多机训练时必须要配置NCCL_SOCKET_IFNAME环境变量。
集合通信操作
NCCL支持集合通信操作(Collective Operations):
AllReduce,进程组内所有进程进行规约操作,最终所有进程得到统一的Tensor。ReduceScatter,进程组内所有进程先进行reduce操作,再进行scatter操作,每个进程得到Tensor的一部分。AllGather,进程组内所有进程的Tensor聚合成一个Tensor列表,并且最终所有进程都有一个Tensor列表副本。Broadcast,进程组内的一个进程将Tensor广播给其他进程。
以下Python相关代码保存在github gist上。
AllReduce
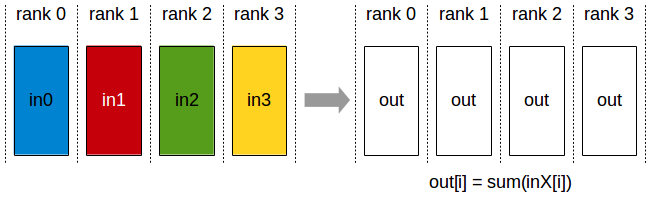
PyTorch torch.distributed.all_reduce()接口:
输入和输出都一个Tensor,而且接口是in-place操作,即直接修改原始Tensor的值,而不是新创建一个Tensor。
def dist_allreduce():
print_rank_0("all_reduce:")
torch.distributed.barrier()
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
tensor = torch.tensor(rank)
input_tensor = tensor.clone()
torch.distributed.all_reduce(tensor)
logging.info(f"all_reduce, rank: {rank}, before allreduce tensor: {repr(input_tensor)}, after allreduce tensor: {repr(tensor)}")
torch.distributed.barrier()
日志:
INFO:root:all_reduce:
INFO:root:all_reduce, rank: 0, before allreduce tensor: tensor(0, device='cuda:0'), after allreduce tensor: tensor(6, device='cuda:0')
INFO:root:all_reduce, rank: 3, before allreduce tensor: tensor(3, device='cuda:3'), after allreduce tensor: tensor(6, device='cuda:3')
INFO:root:all_reduce, rank: 1, before allreduce tensor: tensor(1, device='cuda:1'), after allreduce tensor: tensor(6, device='cuda:1')
INFO:root:all_reduce, rank: 2, before allreduce tensor: tensor(2, device='cuda:2'), after allreduce tensor: tensor(6, device='cuda:2')
ReduceScatter
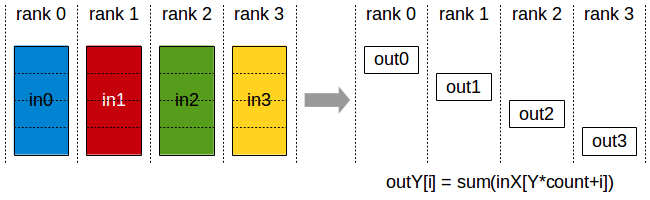
PyTorch torch.distributed.reduce_scatter()接口:
输入:Tensor列表,列表的长度等于world_size
输出:Tensor
def dist_reducescatter():
print_rank_0("reduce_scatter:")
torch.distributed.barrier()
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
output = torch.empty(1, dtype=torch.int64)
input_list = [torch.tensor(rank) for i in range(world_size)]
torch.distributed.reduce_scatter(output, input_list, op=ReduceOp.SUM)
torch.distributed.barrier()
logging.info(f"reduce_scatter, rank: {rank}, input_list: {input_list}, tensor: {repr(output)}")
torch.distributed.barrier()
日志:
INFO:root:reduce_scatter:
INFO:root:reduce_scatter, rank: 0, input_list: [tensor(0, device='cuda:0'), tensor(0, device='cuda:0'), tensor(0, device='cuda:0'), tensor(0, device='cuda:0')], tensor: tensor([6], device='cuda:0')
INFO:root:reduce_scatter, rank: 3, input_list: [tensor(3, device='cuda:3'), tensor(3, device='cuda:3'), tensor(3, device='cuda:3'), tensor(3, device='cuda:3')], tensor: tensor([6], device='cuda:3')
INFO:root:reduce_scatter, rank: 1, input_list: [tensor(1, device='cuda:1'), tensor(1, device='cuda:1'), tensor(1, device='cuda:1'), tensor(1, device='cuda:1')], tensor: tensor([6], device='cuda:1')
INFO:root:reduce_scatter, rank: 2, input_list: [tensor(2, device='cuda:2'), tensor(2, device='cuda:2'), tensor(2, device='cuda:2'), tensor(2, device='cuda:2')], tensor: tensor([6], device='cuda:2')
AllGather
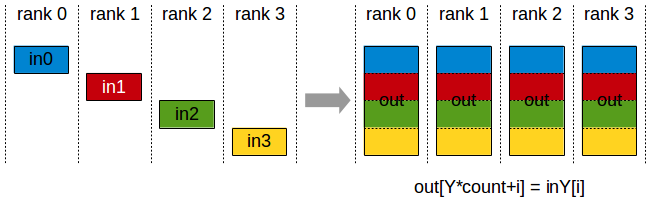
PyTorch torch.distributed.all_gather()接口
输入:Tensor
输出:Tensor列表,列表的长度等于world_size
def dist_allgather():
print_rank_0("allgather:")
torch.distributed.barrier()
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
input_tensor = torch.tensor(rank)
tensor_list = [torch.zeros(1, dtype=torch.int64) for _ in range(world_size)]
torch.distributed.all_gather(tensor_list, input_tensor)
logging.info(f"allgather, rank: {rank}, input_tensor: {repr(input_tensor)}, output tensor_list: {tensor_list}")
torch.distributed.barrier()
日志:
INFO:root:allgather:
INFO:root:allgather, rank: 3, input_tensor: tensor(3, device='cuda:3'), output tensor_list: [tensor([0], device='cuda:3'), tensor([1], device='cuda:3'), tensor([2], device='cuda:3'), tensor([3], device='cuda:3')]
INFO:root:allgather, rank: 2, input_tensor: tensor(2, device='cuda:2'), output tensor_list: [tensor([0], device='cuda:2'), tensor([1], device='cuda:2'), tensor([2], device='cuda:2'), tensor([3], device='cuda:2')]
INFO:root:allgather, rank: 1, input_tensor: tensor(1, device='cuda:1'), output tensor_list: [tensor([0], device='cuda:1'), tensor([1], device='cuda:1'), tensor([2], device='cuda:1'), tensor([3], device='cuda:1')]
INFO:root:allgather, rank: 0, input_tensor: tensor(0, device='cuda:0'), output tensor_list: [tensor([0], device='cuda:0'), tensor([1], device='cuda:0'), tensor([2], device='cuda:0'), tensor([3], device='cuda:0')]
Broadcast
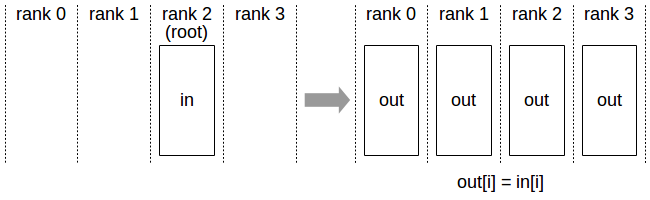
PyTorch torch.distributed.broadcast()接口:
输入:Tensor
输出:Tensor,如果src等于当前rank,将Tensor发送其他rank,如果src不等于当前rank,接收src rank发送的Tensor
def dist_broadcast():
print_rank_0("broadcast:")
torch.distributed.barrier()
rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
tensor = torch.tensor(world_size) if rank == 0 else torch.zeros(1, dtype=torch.int64)
before_tensor = tensor.clone()
torch.distributed.broadcast(tensor, src=0)
logging.info(f"broadcast, rank: {rank}, before broadcast tensor: {repr(before_tensor)} after broadcast tensor: {repr(tensor)}")
torch.distributed.barrier()
日志:
INFO:root:broadcast:
INFO:root:broadcast, rank: 2, before broadcast tensor: tensor(4, device='cuda:2') after broadcast tensor: tensor(4, device='cuda:2')
INFO:root:broadcast, rank: 1, before broadcast tensor: tensor([0], device='cuda:1') after broadcast tensor: tensor([4], device='cuda:1')
INFO:root:broadcast, rank: 3, before broadcast tensor: tensor([0], device='cuda:3') after broadcast tensor: tensor([4], device='cuda:3')
INFO:root:broadcast, rank: 0, before broadcast tensor: tensor([0], device='cuda:0') after broadcast tensor: tensor([4], device='cuda:0')