1. 年龄估计数据集
1.1 MORPH

数据集描述:包含 13,617 名 16 至 77 岁受试者的 55,134 张面部图像。
链接:https://uncw.edu/oic/tech/morph.html
1.2 UTKFace

数据集描述:数据集包含超过 20,000 张带有年龄、性别和种族注释的人脸图像。这些图像涵盖了姿势、面部表情、照明、遮挡、分辨率等方面的巨大变化。该数据集可用于各种任务,例如人脸检测、年龄估计、年龄进展/回归、地标定位等。
链接:https://susanqq.github.io/UTKFace/
1.3 CACD(Cross-Age Celebrity Dataset)

数据集描述:包含来自互联网收集的 2,000 名名人的 163,446 张图像。这些图像是使用名人姓名和年份(2004-2013)作为关键字从搜索引擎收集的。因此,可以通过简单地从拍摄照片的年份减去出生年份来估计图像上名人的年龄。
链接:https://bcsiriuschen.github.io/CARC/
1.4 FGNet

数据集描述:FGNet 是一个用于跨年龄的年龄估计和人脸识别的数据集。它由 82 人的 1,002 张图像组成,年龄范围从 0 到 69,年龄差距高达 45 岁。
链接:https://yanweifu.github.io/FG_NET_data/
1.5 AFAD (Asian Face Age Dataset)
数据集描述:亚洲人脸年龄数据集(AFAD)是为评估年龄估计性能而提出的新数据集,其中包含超过 16 万张人脸图像以及相应的年龄和性别标签。该数据集面向亚洲人脸的年龄估计,因此所有的人脸图像都是针对亚洲人脸的。值得注意的是,AFAD 是迄今为止最大的年龄估计数据集。它非常适合评估如何采用深度学习方法进行年龄估计。
链接:https://afad-dataset.github.io/
1.6 MegaAge
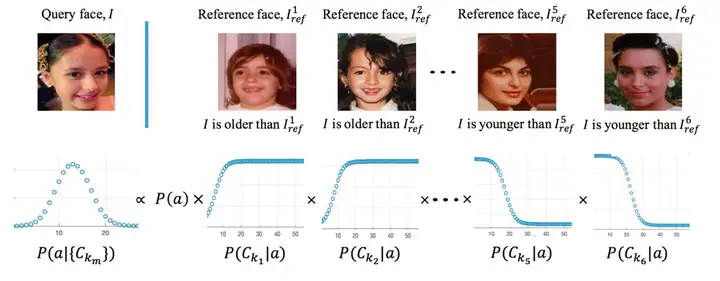
论文:Quantifying Facial Age by Posterior of Age Comparisons
数据集描述:MegaAge是一个大型数据集,由 41,941 个用年龄后验分布注释的人脸组成。生成年龄后验分布的框架:

链接:http://mmlab.ie.cuhk.edu.hk/projects/MegaAge/
1.7 IMDB-WIKI

论文:DEX: Deep EXpectation of apparent age from a single image
数据集描述:从 IMDb 的 20,284 个名人中获得了 460,723 张人脸图像,加上Wikipedia 的 62,328 张,因此总共获得了 523,051 张。
链接:https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
1.8 Adience Benchmark Of Unfiltered Faces For Gender And Age Classification

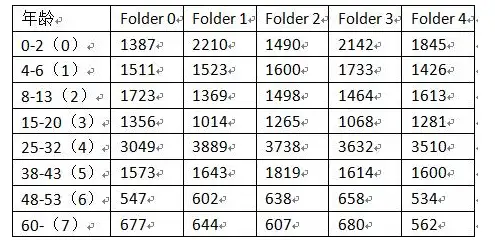
数据集描述:iPhone5或更新的智能手机拍摄的2284人的26580张图片。标签年龄段(0-2, 4-6, 8-13, 15-20, 25-32, 38-43, 48-53, 60+)。
链接:https://www.openu.ac.il/home/hassner/Adience/data.html#frontalized
1.9.ChaLearn LAP Dataset (2015 / 2016)
论文:http://www.cbsr.ia.ac.cn/users/jwan/papers/CVPRW2016_JunWan.pdf
数据集描述:LAP(Look At People)竞赛于2015和2016举办了两年,两年数据集规模分别为5000和8000(基于官网)。与其他数据集的标签为真实年龄不同,LAP数据集的标签是外观显示年龄(apparent age),标签制定平均了至少10个人的标注结果,所以每张图片的年龄标签都是一个正态分布。比赛排名中使用的是结合均值和方差的综合误差E-error【3】。LAP数据集在20-40岁的分布相对均匀,在0-15和65-100区间数据集较少。
链接:http://chalearnlap.cvc.uab.es/dataset/19/description/
小结:
深度学习最常用数据集排名
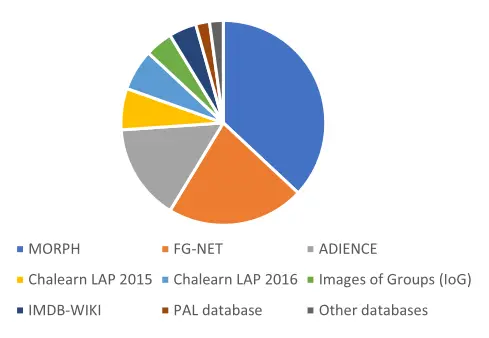
MORPH:标记齐全,最典型,数据适中;
Adience:研究不受约束环境下的年龄估计;
FG-NET:最早发布,样本少,但提供年龄变化的系列图片;
IMDB-WIKI:样本量最大,523,051;
ChaLearn LAP2015/2015: 竞赛数据集5000/8000,使用的是外观显示年龄。
2. 年龄标签
无论是使用哪种方法,对于监督学习来说,势必存在一个对应的标签。而对于年龄估计来说,标签的编码有以下几种方法:
2.1 真实年龄编码
这个容易理解,就是通过人实际年龄直接作为标签,比如真实年龄是20岁或30,那么标签就是20或30,这种编码方式在回归中较为常用
2.2 0/1编码
这种编码方式在分类中较为常用,也就是所谓的one-hot编码。将每一个年龄都看做是一个一维的向量,每个向量中只有该年龄对应的位置处为1,其余为0。假设一个人的年龄为5岁,总共有10个年龄,那么对应的编码便为[0,0,0,0,1,0,0,0,0,0]。
2.3 根据标签年龄分布编码
通常我们的0/1编码结合softmax损失进行分类时,是将所有的标签都同等对待,即我们认为每个标签之间都是相互独立的,彼此之间没有太大关系。但实际上在进行年龄分类的时候,如果有两个年龄40与41,那么我们很难去判断这个人到底是准确的40岁还是41岁,因为这个人可能是40岁零2个月。这两个年龄之间的界限并没有像40与80岁之间那么明确,反而相当模糊,在这种情况下,就不能简单的将两者分开对待,而是有一定的关联的。因此,采用类似高斯映射的方式将标签进行了转化能有很大效果。
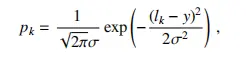
公式中,M表示的原始年龄标签中的最大年龄,表示的是标签的标准方差,y表示图像标签,j表示真实年龄。
3. 评价指标
3.1 平均绝对误差 MAE
平均绝对误差是指估计年龄和真实年龄之间绝对误差的平均值,其表达式为:

MAE是年龄估计中最常用的性能评价方法,MAE越小表示误差范围越小,性能越好。
3.2 累积指数CS
年龄估计性能评价中,人们关注更多的是所估计出的年龄值的绝对误差范围是否在人们能接受的范围内,因此累积指数被用于年龄估计的性能评价中,累积指数的定义如下:

式中,Nθ≤j表示测试图像中估计年龄与真实年龄的绝对误差不超过j年的测试图像数,分母N为所有测试图像的总数。因此CS越大,说明估计年龄越接近真实年龄,年龄估计越准确。
3.3 ϵ−error
有些年龄数据集使用多人进行标注,年龄标注结果可以近似为一个正态分布。E-error会同时衡量估计结果与均值和方差的综合关系。
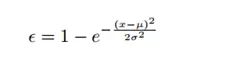
其他的一些指标:准确率,混淆矩阵、误差水平、1-OFF准确率、MSE等。
4. 主流年龄估计算法
基于人脸图像的年龄估计是一类“特殊”的模式识别问题: 一方面由于每个年龄值都可以看作是一个类,所以年龄估计可以被看作是一种分类问题;另一方面,年龄值的增长是一个有序数列的不断变化过程,因此年龄估计也可被视为一种回归性问题。 不同的年龄数据库和不同的年龄特征、分类模式和回归模式具有各自的优越性,因此将二者有机融合可以有效提高年龄估计的精度。年龄估计不同于普通的分类或回归问题,不能用通常的方法解决年龄的预测问题。一些文章将年龄估计的研究方法分为分类、回归、标签分布、Ranking、混合等方法,从目前的最新研究来看,主要以基于混合的方法为主。
4.1 分类方法
由于年龄估计任务的输出是一个整数,比如0-99岁年龄范围,显然他可以看做一个100分类问题,0-99正好看做100个类。虽然分类的方法是最直接清晰的思路,但是年龄本身有连续性,而分类问题忽略了这种天然的内在联系,因为常规的分类任务,类别间是完全独立的,比如猫狗分类。举个例子:
我们一般用softmax+交叉熵做分类任务的损失,假如有三个类别,分别是猫、狗、鸟,它们分别对应的one-hot编码是[1 0 0]、[ 0 1 0]、[0 0 1],当前对一张实际类别是猫的图片进行预测,假设预测结果P1为[0.2 0.6 0.2],P2为[0.2 0.2 0.6],显然这两次预测结果都是错误,并根据交叉熵计算损失是一样大的,在猫、狗、鸟的三分类问题中,这样来计算损失是合理的。
但是假如我们把这个三分类分别对应0岁,1岁和2岁,这样计算损失就不再合理,因为1岁要比2岁,更加接近于0岁,而1岁和2岁产生的损失却一样大,这就是分类问题应用到年龄估计中的弊端,softmax仅仅强调了类间差异的最大化,却忽略了年龄问题本身的连续性。
基于分类的方法可以通过年龄分段减轻这些问题的影响,如【Age and Gender Classification Using Convolutional Neural Networks】,这是早期年龄估计的常用方法,Adience数据集就是分段的。因为年龄段间也是连续的,因此年龄分段不能从跟本上解决问题。
因此,研究人员开始考虑结合回归问题,如【DEX: Deep EXpectation of apparent age from a single image、Easy Real time gender age prediction from webcam video with keras】等将年龄估计问题看做是回归-分类问题,使用分类概率乘以对应标签,得到一个回归结果。该结果比单独分类、回归精度高很多。
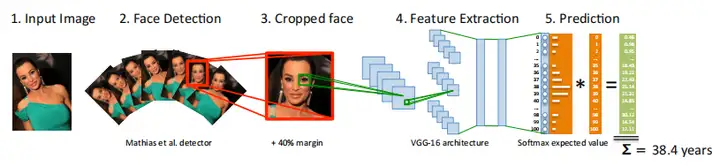
4.2 回归方法
由于年龄的连续性,年龄估计也可以看做回归问题,但是回归处理假设人的衰老是一个“静态”过程,即不同年龄的人的衰老变化规律一致,这显然不适合处理不同人组成的年龄估计问题。解决方法一种是直接将年龄拟合到一个分布而不是某个年龄点,如【Quantifying Facial Age by Posterior of Age Comparisons】
这类方法的重点是标签分布的确定。另一种方法Ordinal Regression结合多分类,将多分类问题的输出转换成回归期望进行学习,如【Ordinal Regression with Multiple Output CNN for Age Estimation】,Ordinal Regression有一些文章叫法是RankingCNN。

4.3 标签分布
DLDL方法将实值年龄转换为离散年龄分布,以适应整个年龄分布。它是一种端到端学习模型,解决了大多数年龄估计任务中训练图像不足的问题。通过将真实年龄值转换为离散年龄分布来拟合整个年龄。在不增加培训样本数量的情况下,将增加与每个类别标签相关的培训实例。
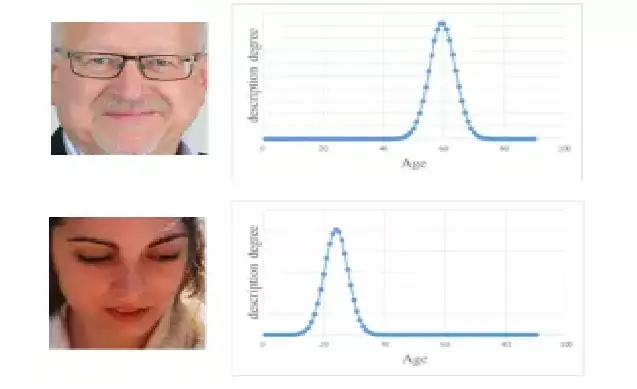
然而,通常观察到,所采用的评估指标与培训目标之间缺乏一致性,因此单纯的使用标签分布方法往往会引起评价指标偏低。解决的方法很简单,就是结合分类与回归,将分布拟合到真实值,如【Learning Expectation of Label Distribution for Facial Age and Attractiveness Estimation】
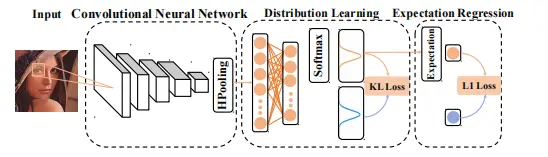
4.4 Ranking方法(Ordinal Regression)
年龄的多分类完全忽略了年龄标签的顺序信息,年龄的回归过度简化成了线性模型。Ranking-CNN针对不同的年龄段独立学习特征,使得学习的特征具有更有效的表现能力。【Using Ranking-CNN for Age Estimation】提出了一种考虑与年龄有关的顺序信息,把年龄估计转化为一个排序问题,具体是通过一系列的二分类来实现,最后,通过合计二分类的结果来得到年龄预测结果。
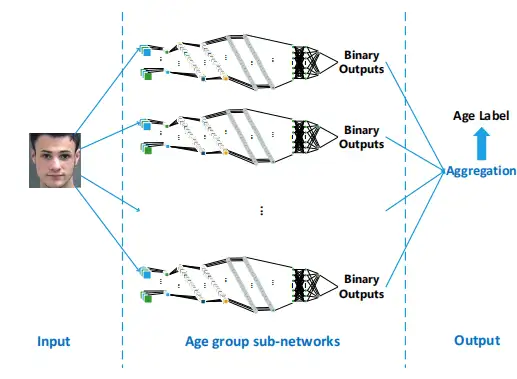
年龄估计过程可以看成是对大量人脸有效信息对进行比较的过程,也就是通过若干组二值分类结果就可以得到相应的年龄估计值,通过寻找当前年龄标签在年龄序列中的相对位置来确定最终的年龄值,从而有效克服了传统的年龄估计方法忽略了人类面部衰老过程中的动态性、模糊性以及个性化的特点。这样定义年龄估计有两个好处:
- 在实际生活中,我们去判断一个人的年龄大于还是小于另一个年龄,要比直接去估计这个年龄更容易,这符合人的主观认知;
- Ordinal的思想不同于直接分类,利用了年龄本身连续性的特点。
小结:分析目前一些最新的研究可以发现,最新的方法不会单独的基于分类、回归或标签分布,而是多者之间的结合,不同的方法既有各自的特定又相互联系,不同方法的组合效果在不同任务、不同数据集间亦有差异,需要面向不同的实现目标专门设计,我们可以从以下的一些最新研究中发现一些灵感。
5. 最新年龄估计算法研究
5.1 一篇综述
论文:(2021)Deep learning approach for facial age classification: a survey of the state‑of‑the‑art
解读:【综述解读】年龄估计Deep learning approach for facial age classification
5.2 另一篇综述
论文:(2020)Neural networks for facial age estimation: a survey on recent advances
解读:【综述解读】年龄估计Neural networks for facial age estimation
5.3 特征融合
特征融合在任何领域都有极强的适用性,是网络提点的一种常用方法。

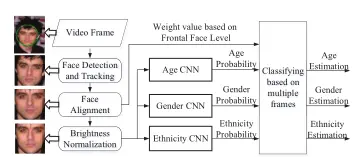
论文:Video system for human attribute analysis using compact convolutional neural network
5.4 多CNN的级联
适用不同CNN提取不同的特征,进而解决不同的任务。
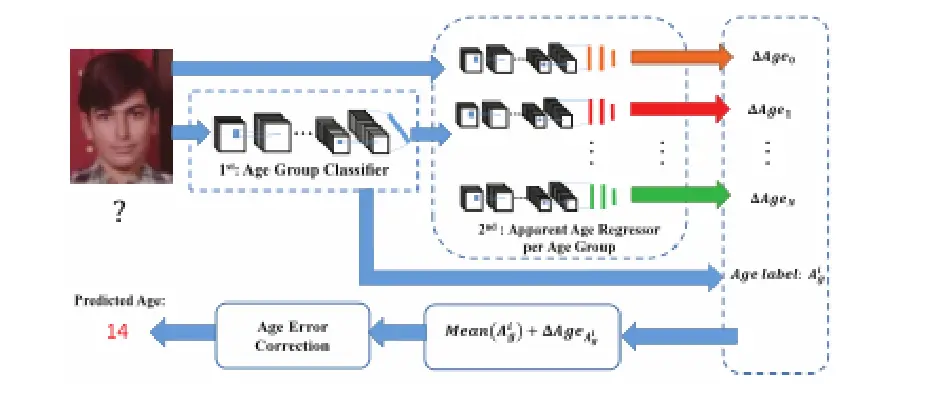
论文:(2016) A cascaded convolutional neural network for age estimation of unconstrained face
针对多任务的级联:
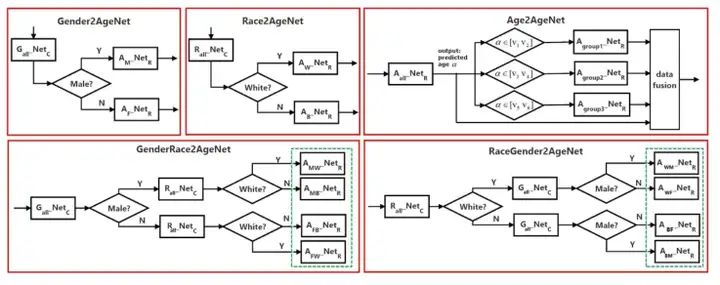
论文:(2018) Auxiliary demographic information assisted age estimation with cascaded structure
5.5 多域数据+年龄差
利用域外数据提高目标数据集精度,引入年龄差loss。
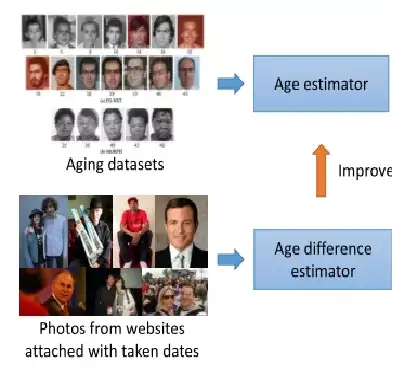
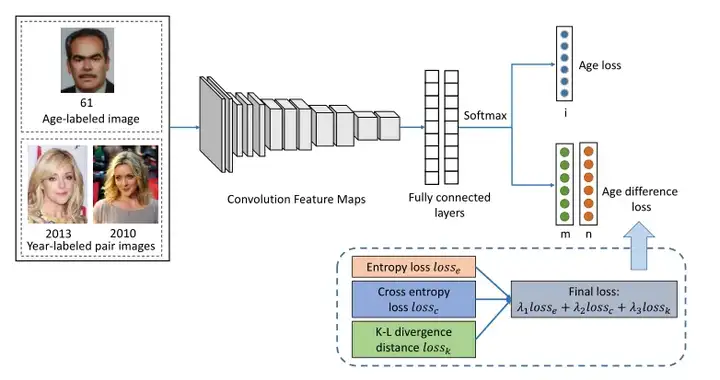
论文:(2016) Facial age estimation with age difference
5.6 隐藏层引出损失比较
合理利用中间层特征。
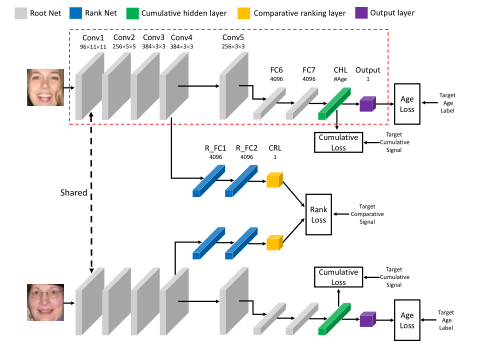
论文:(2017) D2C: deep cumulatively and comparatively learning for human age estimation
5.7 分块与注意力机制
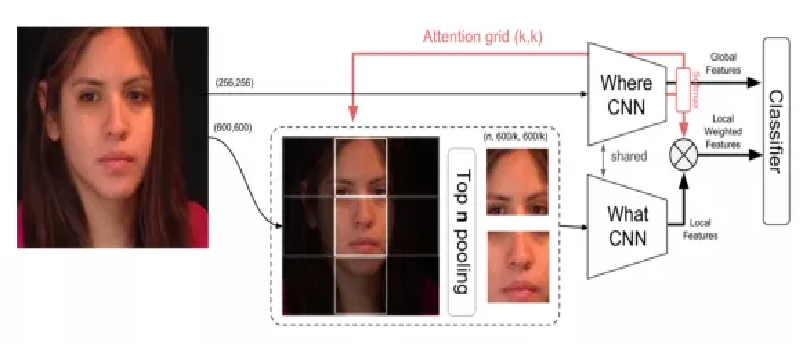
论文:(2017) Age and gender recognition in the wild with deep attention.
5.8 CNN+极限学习机ELM
极限学习机ELM的引入。
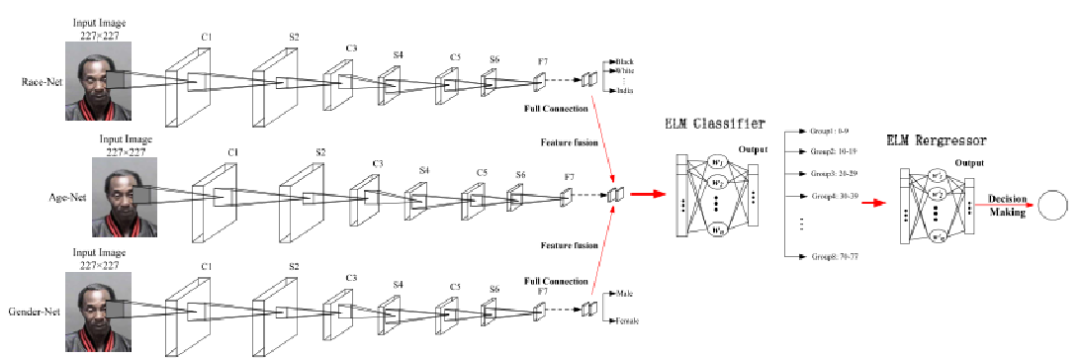
论文:An ensemble CNN2ELM for age estimation
5.9 CNN+LSTM
LSTM引入处理时序信息。
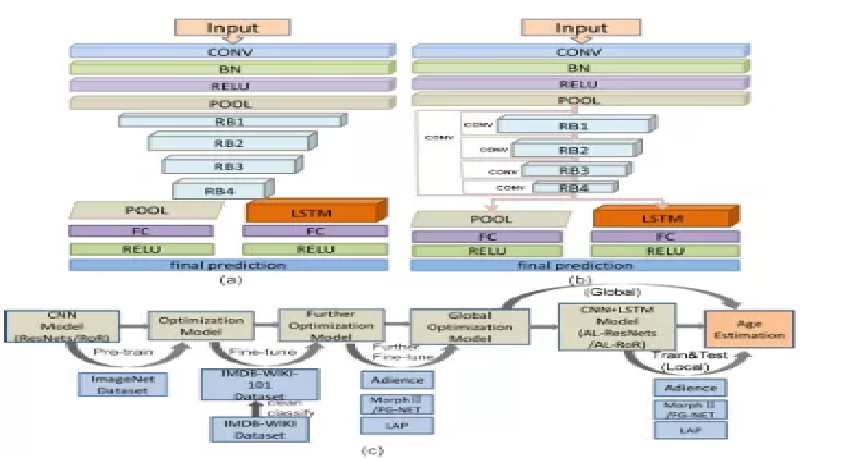
论文:Age estimation by super-resolution reconstruction based on adversarial networks
5.10 自动编码器与生成对抗网络
生成对抗网络的引入与人脸年龄图像的生成。
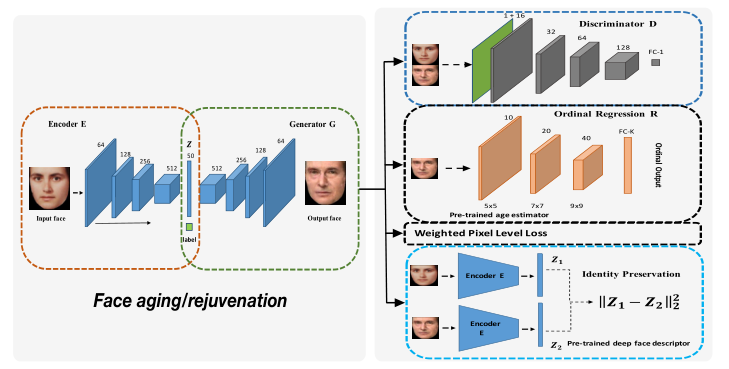
论文:Facial Aging and Rejuvenation by Conditional Multi-Adversarial Autoencoder with Ordinal Regression.
5.11 局部回归+门控网络

论文:Fine-grained age estimation in the wild with attention LSTM networks
5.12 条件多任务
合理利用数据集相关的其他任务。
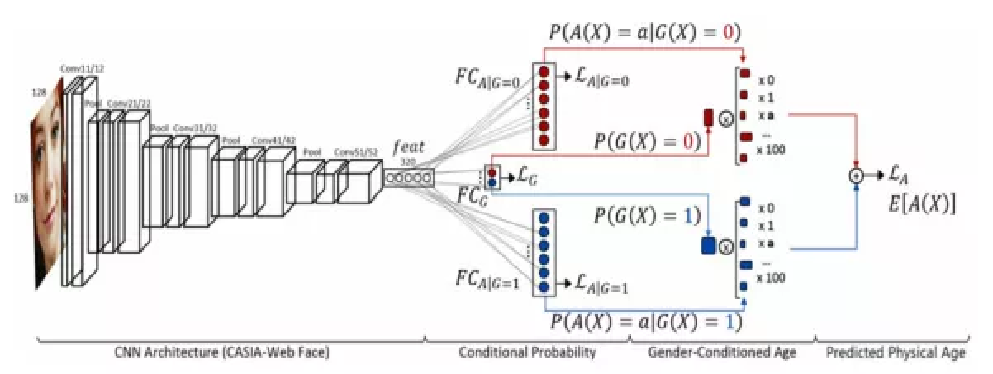
论文:(2018) Deep facial age estimation using conditional multitask learning with weak label expansion.
5.13 多层次、多阶段、多任务结合
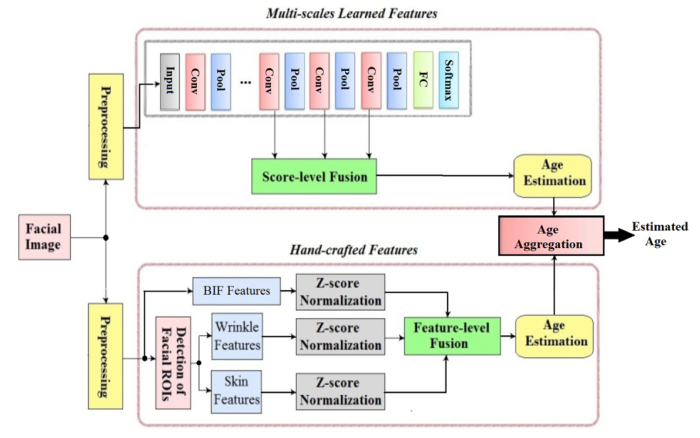
6. 总结
文章对年龄估计任务相关的一些常用数据集、标签方法、评估指标以及主流解决方法进行了详细阐述。并通过对一些最新研究进行分析,总结了近年来年龄估计进展的主要着力点,从方法到网络粗略总结了它们对年龄估计任务的贡献。年龄估计作为软生物识别任务中少有的发展较快的分支,对年龄估计任务的研究,不但有利于人脸识别系统性能的提升,对同类型且处于起步阶段的的一些体态估计任务的发展也具有深远意义。
后续我也将继续分享该领域的最新技术总结,以及对相关领域的技术迁移,敬请期待!
年龄估计论文推荐:
【综述解读】年龄估计Neural networks for facial age estimation
【综述解读】年龄估计Deep learning approach for facial age classification
【论文解读】基于条件多对抗自动编码网络的面部衰老与年轻化方法
编 人脸年龄估计
人脸年龄估计是指机器根据面部图像推测出人的大概年龄或者所属年龄范围(年龄段)。基于人脸的年龄估计系统一般分为人脸检测与定位,年龄特征提取,年龄估计,系统性能评价几个部分。应用如…
ShuZyc
【技术综述】人脸年龄估计研究现状(2018年版)
龙鹏-笔名言有三地球年龄是如何精确测定的?
1956年,加州理工学院(California Institute of Technology)的克莱尔·帕特森(Claire Patterson)采用陨石的铅同位素定年法测得地球的准确年龄:4.55±0.07Ga(45.5亿年),这与目前公认…
地学拾贝C3AE - 轻量级年龄识别模型
前言 年龄识别,传统上主要是分类、回归、rank几类方法。无论怎么实现,为基于学习的方法简化学习目标,降低模型学习成本都是一直以来的追求,不仅可以降低学习时间,更可以提升收敛准确性…
tatat发表于legbl... 标签:标签,age,分类,估计,人脸,年龄 From: https://www.cnblogs.com/flyingsir/p/17631098.html