
前言
我们在进行自动化工作中,还会遇到表格的问题,比如下面的情况:
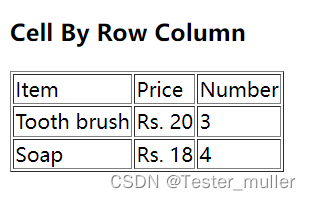
如果我们想要获取表格内的数据,就需要我们先定位表格内的元素。
table 表格场景
我们可以从表格结构中发现,table页面有这几个明显的标签:table、tr、th、td
- table 标示一个表格
- tr 标示这个表格的一行
- th 定义表头单元格
- td 定义单元格标签,一组td标签将将建立一个单元格,td标签必须放在tr标签内
xpath 定位table 表格
我们通常使用xpath定位来定位表格数据,语法如下:
//*[@id="表格id"]/tbody/tr[m]/td[n]
参数说明:m表示第几行,n表示第几列
获取当前表格行数
可以通过定位有多少个tr 元素,计算tr 的个数,就是总行数
语法示例:
//*[@id="table"]/tbody/tr
playwright 获取table表格总行数示例
number = page.locator('//*[@id="table"]/tbody/tr')
print(number.count()) # 统计个数
获取表格数据
- 获取表格第1行的数据
n = page.locator('//*[@id="table"]/tbody/tr[1]')
print(n.inner_text()) # 获取第一行数据
- 获取第3列的数据
a = page.locator('//*[@id="table"]/tbody/tr/td[3]')
for td in a.all():
print(td.inner_text())
- 获取第1行第3列数据
b = page.locator('//*[@id="table"]/tbody/tr[1]/td[3]')
print(b.inner_text())
示例
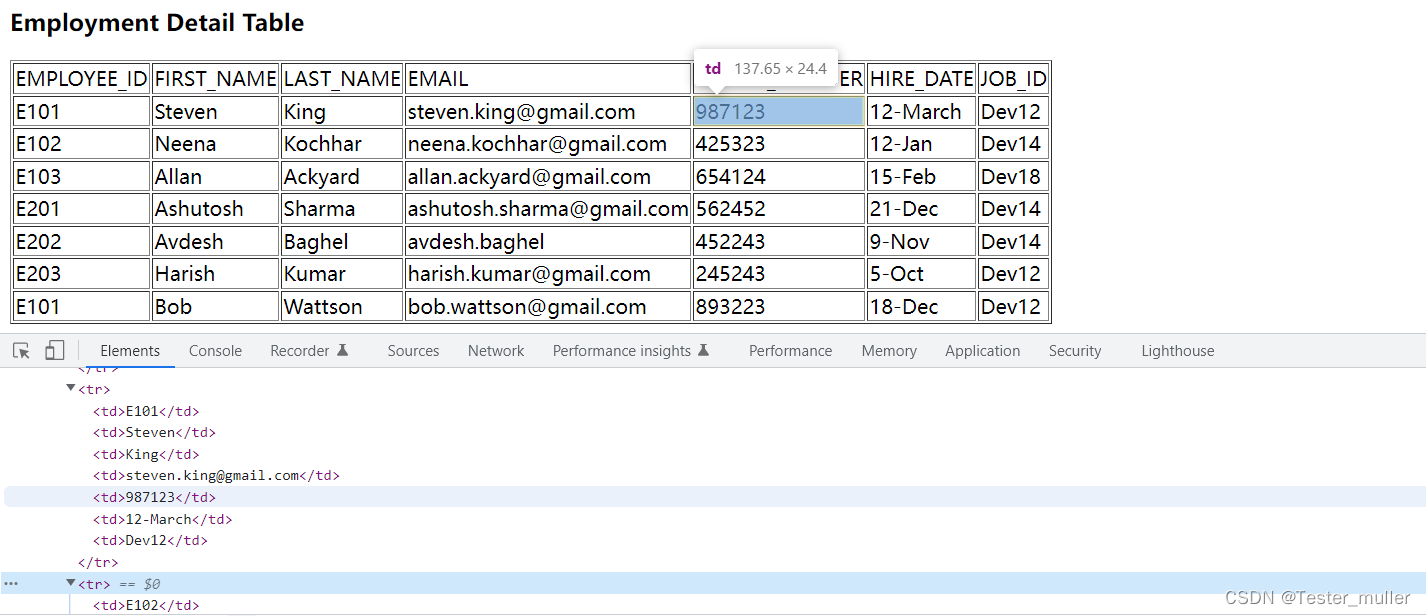
我们还是以上方的表格为例,展示一下playwright对于表格的定位,代码如下:
from playwright.sync_api import Playwright, sync_playwright, expect
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://sahitest.com/demo/tableTest.htm")
# 计算总行数
n = page.locator('//*[@id="t4"]/tbody/tr')
print(n.count())
# 打印表格第一行信息
n1 = page.locator('//*[@id="t4"]/tbody/tr[1]')
for a in n1.all():
print(a.inner_text())
# 打印第一行第三列的数据
n2 = page.locator('//*[@id="t4"]/tbody/tr[1]/td[3]')
print(n2.count())
page.get_by_role("cell", name="EMPLOYEE_ID").click()
page.get_by_role("cell", name="[email protected]").click()
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
--------------------------------------------------
输出结果如下:
8
EMPLOYEE_ID FIRST_NAME LAST_NAME EMAIL PHONE_NUMBER HIRE_DATE JOB_ID
LAST_NAME
总结
本文主要介绍了playwright对表格的处理,后续我们将介绍playwright的其他用法。
标签:web,playwright,表格,tr,table,td,page,软件测试 From: https://www.cnblogs.com/hogwarts/p/17617733.html