本文分享自华为云社区《DTSE Tech Talk|第35期:解决大模型“开发难”,昇思MindSpore自动并行技术应用实践》,作者华为云社区精选。
昇思MindSpore是新一代覆盖端边云全场景的开源AI框架,旨在开创全新的AI编程范式,降低开发者门槛,为开发者打造开发友好、运行高效、部署灵活的AI框架,推动人工智能生态繁荣发展。同时,昇思在致力于大规模自动并行、科学计算支持等特性优化之外,还着力打造学习型社区环境,希望凝聚开发者力量共建社区,与开发者共同学习和成长。
昇思MindSpore自动并行技术的实际运用
昇思MindSpore具备丰富的并行能力,能轻松完成4096卡集群、万亿参数规模的训练任务,因此支撑了国内多个领域首发大模型的训练,这些大模型涉及知识问答、知识检索、知识推理、阅读理解、文本/视觉/语音多模态、生物制药、遥感、代码生成等。总共支撑20+大模型训练,6个千亿参数大模型,覆盖NLP、Audio、CV、多模态等领域。
数据并行
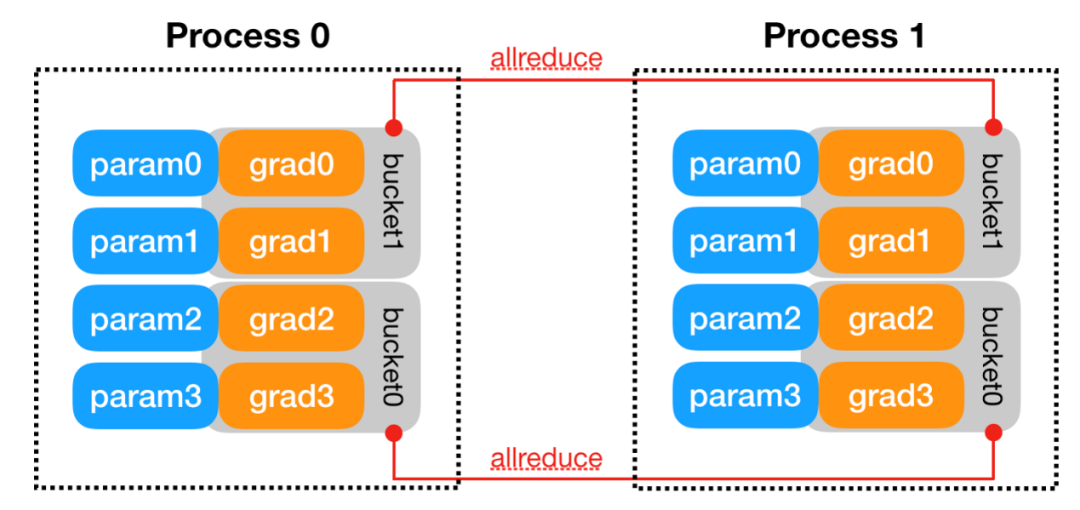
对数据进行切分的并行模式,一般按照batch维度切分,将数据分配到各个计算单元(worker)中,进行模型计算。而在 昇思MindSpore 中是用集合通信这个方式来实现的,利用到了 AllReduce 操作完成的梯度聚合部分。
模型并行
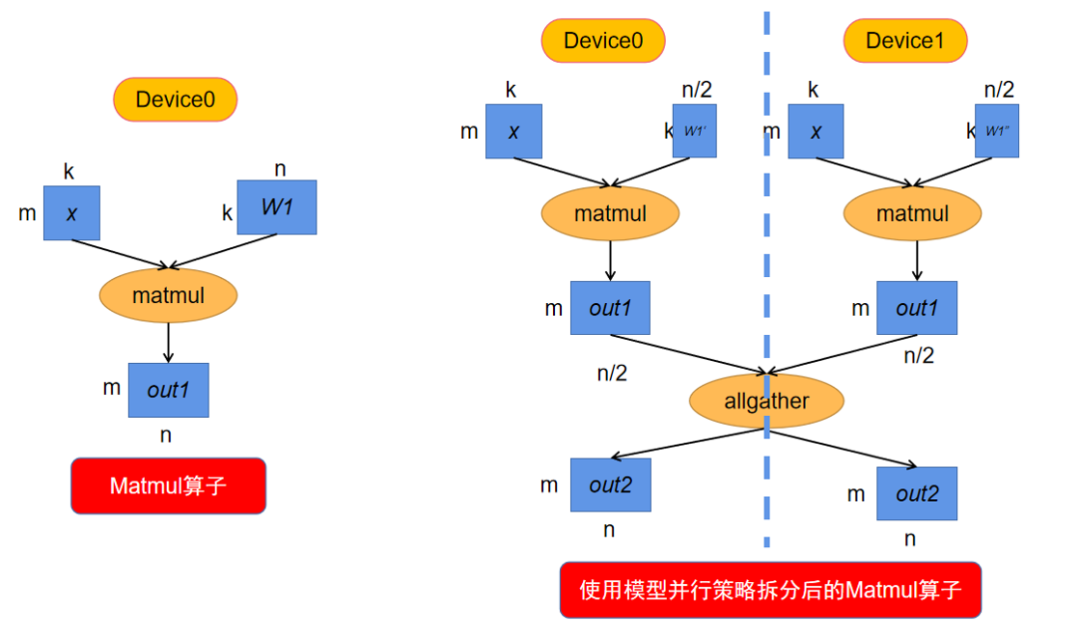
模型并行是算子层面的并行,它利用某些算子的特性将算子拆分到多个设备上进行计算。因此并不是网络中所有的算子都可以拆分计算,可以拆分的算子需满足两点:可以并行计算的算子;算子其中一个输入来自于Parameter。
Pipeline并行
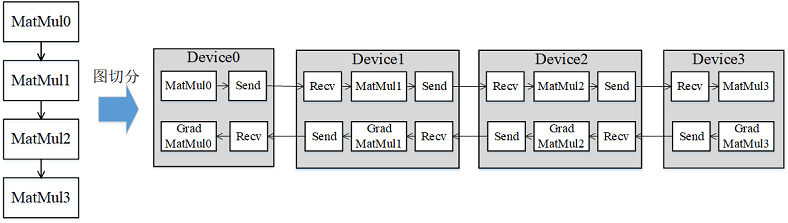
受server间通信带宽低的影响,传统数据并行叠加模型并行的这种混合并行模式的性能表现欠佳,需要引入流水线并行。流水线并行能够将模型在空间上按stage进行切分,每个stage只需执行网络的一部分,大大节省了内存开销,同时缩小了通信域,缩短了通信时间。流水线(Pipeline)并行是将神经网络中的算子切分成多个阶段(Stage),再把阶段映射到不同的设备上,使得不同设备去计算神经网络的不同部分。
内存优化
1、重计算
在计算某些反向算子时,需要用到一些正向算子的计算结果,导致这些正向算子的计算结果需要驻留在内存中,直到依赖它们的反向算子计算完,这些正向算子的计算结果占用的内存才会被复用。这一现象推高了训练的内存峰值,在大规模网络模型中尤为显著。
如:
- Dropout
- Activations
2、优化器并行
在进行数据并行训练时,模型的参数更新部分在各卡间存在冗余计算,优化器并行通过将优化器的计算量分散到数据并行维度的卡上,在大规模网络上(比如Bert、GPT)可以有效减少内存消耗并提升网络性能。
传统的数据并行模式将模型参数在每台设备上都有保有副本,把训练数据切分,在每次迭代后利用通信算子同步梯度信息,最后通过优化器计算对参数进行更新。数据并行虽然能够有效提升训练吞吐量,但并没有最大限度地利用机器资源。其中优化器会引入冗余内存和计算,消除这些冗余是需关注的优化点。
昇思MindSpore分布式并行模式有哪些?
数据并行
用户的网络参数规模在单卡上可以计算的情况下使用。这种模式会在每卡上复制相同的网络参数,训练时输入不同的训练数据,适合大部分用户使用;
半自动并行
用户的神经网络在单卡上无法计算,并且对切分的性能存在较大的需求。用户可以设置这种运行模式,手动指定每个算子的切分策略,达到较佳的训练性能;
自动并行
用户的神经网络在单卡上无法计算,但是不知道如何配置算子策略。用户启动这种模式,昇思MindSpore会自动针对每个算子进行配置策略,适合想要并行训练但是不知道如何配置策略的用户;
混合并行
完全由用户自己设计并行训练的逻辑和实现,用户可以自己在网络中定义AllGather等通信算子。适合熟悉并行训练的用户。
标签:训练,模型,并行,计算,算子,MindSpore From: https://www.cnblogs.com/huaweiyun/p/17603291.html