前言 该工作是目前唯一实现了大规模高分辨率数据集蒸馏的框架。
本文转载自机器之心
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
过去几年,数据压缩或蒸馏任务引起了人们的广泛关注。通过将大规模数据集压缩成具有代表性的紧凑子集,数据压缩方法有助于实现模型的快速训练和数据的高效存储,同时保留原始数据集中的重要信息。数据压缩在研究和应用中的重要性不可低估,因为它在处理大量数据的过程中起着关键作用。通过采用先进的算法,数据压缩取得了显著的进展。然而,现有解决方案主要擅长压缩低分辨率的小数据集,这种局限性是因为在双层优化过程中执行大量未展开的迭代会导致计算开销巨大。
MBZUAI 和 CMU 团队的最新工作 SRe2L 致力于解决这一问题。该工作是目前唯一实现了大规模高分辨率数据集蒸馏的框架,可以将 Imagenet-1K 原始的 1.2M 数据样本压缩到 0.05M (压缩比 1:20),使用常用的 224x224 分辨率进行蒸馏,在 ImageNet-1K 标准验证集(val set)上取得了目前最高的 60.8% Top-1 精度,远超之前所有 SOTA 方法,如 TESLA (ICML’23) 的 27.9% 的精度。
该工作目前已完全开源,包括蒸馏后的数据,蒸馏过程和训练代码。

论文:https://arxiv.org/abs/2306.13092
代码:https://github.com/VILA-Lab/SRe2L
数据集蒸馏 / 压缩任务的定义和难点
传统的模型蒸馏是为了得到一个更加紧凑的模型,同时保证模型性能尽可能得高。与之不同,数据集蒸馏任务关注于如何得到一个更紧凑同时更具表达能力的压缩后的数据集,数据样本相比原始数据集会少很多(节省从头训练模型的计算开销),同时模型在该压缩后的数据集上训练,在原始数据验证集上测试依然可以得到较好的精度。
数据集蒸馏任务的主要难点在于如何设计一个生成算法来高效可行地生成需要的样本,生成的样本需要包含 / 保留原始数据集中核心的信息。目前比较常用的方法包括梯度匹配、特征匹配、轨迹匹配等等,但是这些方法的一个共同缺点就是没法 scale-up 到大规模数据集上。比如,由于计算量和 GPU 显存的限制,无法蒸馏标准的 ImageNet-1K 或者更大的数据集。计算量和 GPU 显存需要过大的主要原因在于这些方法生成过程需要匹配和保存的信息过多,目前很多 GPU 显存没法容纳所有需要匹配的数据信息,导致这些方法大多数只适用于较小的数据集。
针对这些问题,新论文通过解耦数据生成和模型训练两个步骤,提出了一个三阶段数据集蒸馏算法,蒸馏生成新数据过程只依赖于在原始数据集上预训练好的模型,极大地降低了计算量和显存需求。
解决方案核心思路
之前很多数据集蒸馏方法都是围绕样本生成和模型训练的双层优化 (bi-level optimization) 来展开,或者根据模型参数轨迹匹配 (trajectory matching) 来生成压缩后的数据。这些方法最大的局限在于可扩展性不是很强,需要的显存消耗和计算量都很大,没法很好地扩展到完整的 ImageNet-1K 或者更大的数据集上。
针对这些问题,本文作者提出了解耦数据生成和模型训练的方法,让原始数据信息提取过程和生成数据过程相互独立,这样既避开了更多的内存需求,同时也避免了如果同时处理原始数据和生成数据导致原始数据中的噪声对生成数据造成偏差 (bias)。
具体来说,本文提出了一种新的数据集压缩框架,称为挤压、恢复和重新标记 (SRe2L),如下图所示,该框架在训练过程中解耦模型和合成数据双层优化为两个独立的操作,从而可以处理不同规模的数据集、不同模型架构和高图像分辨率,以实现有效的数据集压缩目的。
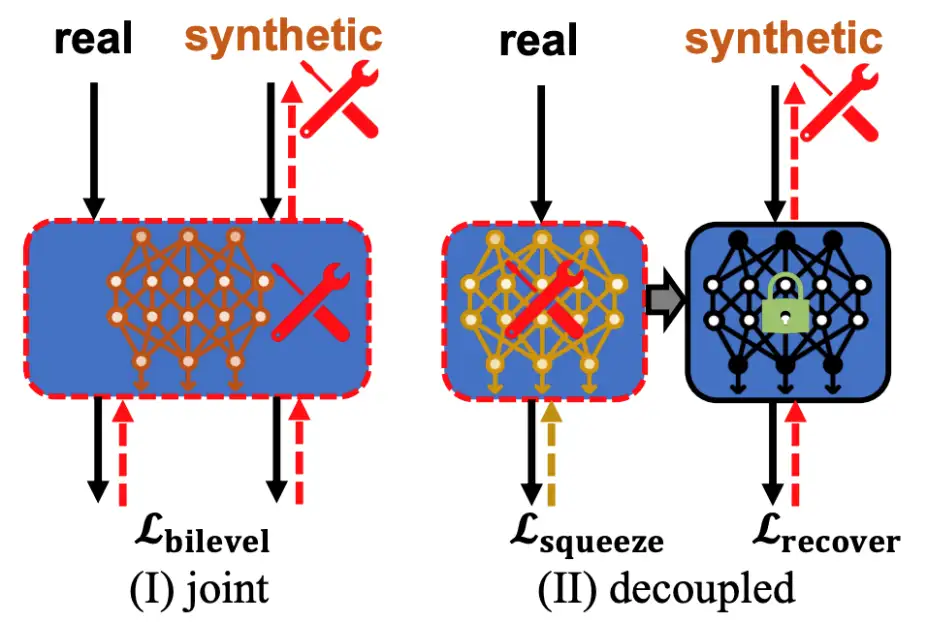
本文提出的方法展示了在不同数据集规模的灵活性,并在多个方面表现出多种优势:1)合成图像的任意分辨率,2)高分辨率下的低训练成本和内存消耗,以及 3)扩展到任意评估网络结构的能力。本文在 Tiny-ImageNet 和 ImageNet-1K 数据集上进行了大量实验,并展示出非常优异的性能。
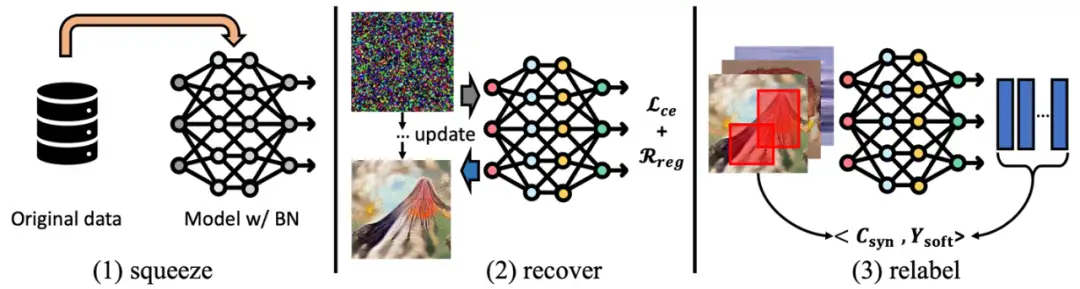
三阶段数据集蒸馏框架
本文提出一个三阶段数据集蒸馏的框架:
- 第一步是将整个数据集的核心信息压缩进一个模型之中,通过模型参数来存储原始数据集中的信息,类似于我们通常进行的模型训练;
- 第二步是将这些高度抽象化的信息从训练好的模型参数中恢复出来,本文讨论了多种不同损失和正则函数对于恢复后图像的质量以及对数据集蒸馏任务的影响;
- 第三步也是提升最大的一步:对生成的数据进行类别标签重新校准。此处作者采用了 FKD 的方式,生成每个 crop 对应的 soft label,并作为数据集新的标签存储起来。
三阶段过程如下图所示:
性能及计算能效比
在 50 IPC 下 (每个类 50 张图),本文提出的方法在 Tiny-ImageNet 和 ImageNet-1K 上实现了目前最高的 42.5% 和 60.8% 的 Top-1 准确率,分别比之前最好方法高出 14.5% 和 32.9%。
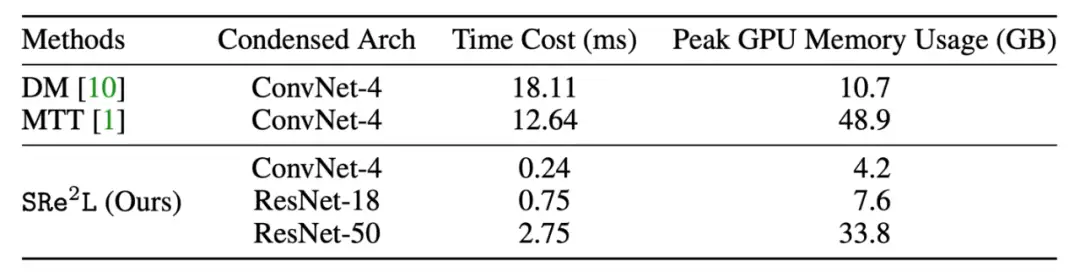
此外,本文提出的方法在速度上也比 MTT 快大约 52 倍 (ConvNet-4) 和 16 倍 (ResNet-18),并且在数据合成过程中内存需求更少,相比 MTT 方法分别减少了 11.6 倍 (ConvNet-4) 和 6.4 倍 (ResNet-18),具体比较如下表所示:
实验结果
实验设置
该工作主要聚焦于大规模数据集蒸馏,因此选用了 ImageNet-Tiny 和 ImageNet-1K 两个相对较大的数据集进行实验。对于骨干网络,本文采用 ResNet-{18, 50, 101} 、ViT-Tiny 和自己构建的 BN-ViT-Tiny 作为目标模型结构。对于测试阶段,跟之前工作相同,文本通过从头开始训练模型来评估压缩后数据集的质量,并报告 ImageNet-Tiny 和 ImageNet-1K 原始验证集上的测试准确性。
在 full ImageNet-1K 数据集上的结果

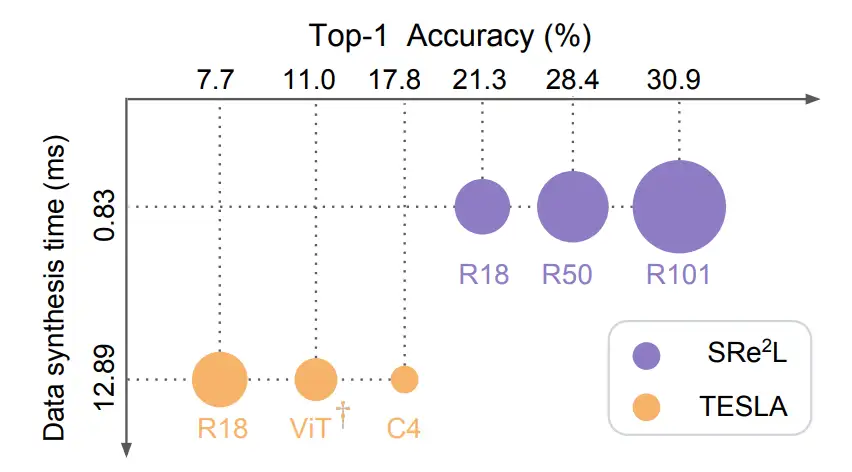
可以看到,在相同 IPC 情况下,本文实验结果远超之前方法 TESLA。同时,对于该方法蒸馏得到的数据集,当模型结构越大,训练得到的精度越高,体现了很好的一致性和扩展能力。
下图是性能对比的可视化结果,可以看到:对于之前方法 TESLA 蒸馏得到的数据集,当模型越大,性能反而越低,这对于大规模数据集蒸馏是一个不好的情况。与之相反,本文提出的方法,模型越大,精度越高,更符合常理和实际应用需求。
压缩后的数据可视化

从上图可以看到,相比于 MTT 生成的数据(第一和第三行),本文生成的数据(第二和第四行)不管是质量、清晰度还是语义信息,都明显更高。
 蒸馏过程图像生成动画
蒸馏过程图像生成动画
此外,包含 50、200 个 IPC(具有 4K 恢复预算)的压缩数据集文件可从以下链接获取:https://zeyuanyin.github.io/projects/SRe2L/
将该方法扩展到持续学习任务上的结果
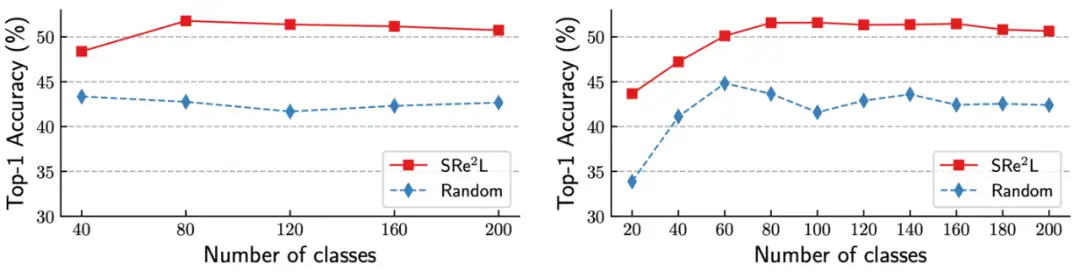
上图展示了 5 步和 10 步的增量学习策略,将 200 个类别(Tiny-ImageNet)分为 5 个或 10 个学习步骤,每步分别容纳 40 个和 20 个类别。可以看到本文的结果明显优于基线(baseline)性能。
更多细节欢迎阅读其论文原文和代码。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
比Meta「分割一切AI」更全能!港科大版图像分割AI来了:实现更强粒度和语义功能
Meta Segment Anything会让CV没前途吗?
CVPR'2023年AQTC挑战赛第一名解决方案:以功能-交互为中心的时空视觉语言对齐方法
6万字!30个方向130篇 | CVPR 2023 最全 AIGC 论文汇总
ICCV2023 | 当尺度感知调制遇上Transformer,会碰撞出怎样的火花?
新加坡国立大学提出最新优化器:CAME,大模型训练成本降低近一半!
SegNetr来啦 | 超越UNeXit/U-Net/U-Net++/SegNet,精度更高模型更小的UNet家族
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:20,首超,模型,生成,60%,ImageNet,1K,数据,蒸馏 From: https://www.cnblogs.com/wxkang/p/17578040.html