作者:Xingzhe.AI
来自:行者AI
前言
2018年Bert的横空出世给自然语言处理带来了巨大的突破,Bert及其衍生模型在多个文本处理下游任务中达到了SOTA的结果。但是这样的提升是有一定代价的,其中之一就是计算量的大幅增长。
BERT-base模型是由12层Transformer构成,模型有大约1亿参数参与运算,而效果更好的BERT-large由24层的Transformer组成,参数量甚至达到了3亿,巨大的参数量对GPU的性能和显存提出了更高的要求,尤其是在企业的落地应用中,需要更加高级的GPU来完成模型训练。在推理过程中的情况也是如此,在部署到线上的实际情况下,对文本分析的响应是ms级的,而租用高算力的服务器需要花费大量的成本,那么有没有方法可以鱼与熊掌兼得,在不牺牲分类精度的情况下减少模型复杂度呢?
答案是肯定的。
1. 将BERT作为服务(减少训练计算量)
正常情况下对将BERT模型用于文本分类是以Fine-tuning(微调)的方式进行的,因为BERT是一个预训练模型,Google已经在大规模文本上学习训练了一个参数模型,我们在进行文本分类时,只需要将预训练参数作为初始参数,再使用我们的训练集对模型进行训练微调就可以达到很好的效果。但是这样的方法要对上亿的参数进行计算,在训练阶段还是很消耗计算资源。此时将BERT模型作为一种产生词向量的服务的思路诞生了,将BERT所有的参数固定,不再参与训练,也就没有反向更新。这种方法将BERT作为一个词向量的生成器,只在服务被调用的时候产生计算,无需训练,极大的节省了训练成本。
这种方法省略了训练过程,这就带来了问题,因为BERT预训练参数来自大规模的语料库,是一种通用的模型,而我们要做的往往是特定领域的文本分类,比如医学文本。因为我们没有对模型微调,模型无法学习到一些特定领域的特殊表达,此时将BERT作为服务的模型结果就会出现大的偏差,对于这样问题,一些解决办法是在BERT后面加一些类似全连接、CNN、LSTM等等基础模型,对这些基础模型进行训练来学习当前数据集中的特殊表示,但是这些模型都是浅层模型,效果比微调bert的结果要差。
总结一下,将BERT作为服务的方法,在牺牲了一定的精度的代价下,节省了训练中的资源消耗,但是没有减少推理中的计算,在服务被调用的时候还是需要较高的计算资源。
2. 对BERT进行蒸馏(减少推理计算量)
学习过化学的同学都知道,可以用蒸馏的方法将精华从大量的材料中提取出来。对BERT的蒸馏也是基于这样的思想。
前面提到BERT-base的模型由12层Transformer组成,一共有1亿的参数量,但是这其中并不是所有的参数都是对于当前任务是有必要的,尤其是对于文本分类这种简单基础的任务,可能只要其中的3千万参数就可以达到很好的效果,在这样思想的指导下很多对BERT蒸馏的方法被提出。
蒸馏的思想由Hinton在NIPS 2014 提出,其核心思想就是由大量预料训练一个复杂的教师网络(Teacher),之后再使用教师网络训练学生网络(Student)。这是蒸馏区别于剪枝等方法的一个重要原因。此外蒸馏中的学生网络学习的是教师网络的泛化能力,并不是对数据的拟合能力。可以理解为学生学习的老师做题的能力而不是学习每道题目的标准答案。
以文本情感分类为例,为了使学生网络学习到教师网络的知识,教师网络不能告诉学生当前句子的情感类别(0或者1),而是应该告诉学生分类概率(比如0.73),这样学生才能够学习到教师网络的知识。而在实际情况中,教师的模型往往有很好的分类效果,得到的概率分布绝大部分在0或者1的周围,此时概率和类别的区别已经不大了,为了更好的提取教师模型的知识,Hinton在计算softmax的公式中加入了平滑参数T,具体公式如下:
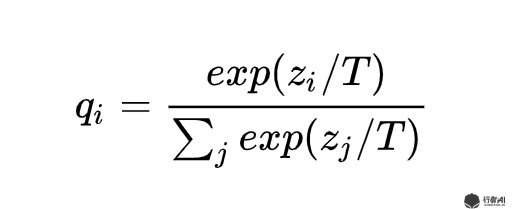
图1. 平滑softmax
蒸馏的目的是得到一个学生网络,这个学生网络的参数量是小于教师网络的,同时,学生网络的效果要和教师网络尽可能的接近。为了达到这样的目的,需要设计一个特殊的loss函数。这个loss函数要既要衡量教师网络与学生网络输出概率值的差异,又要衡量学生网络输出的标签和真实标签的差异。不同的研究人员使用了不同了loss函数,但是他们大体形式如下所示:
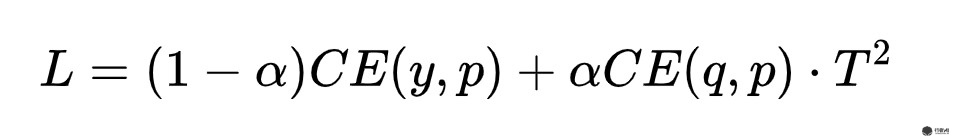
图2. 损失函数通式
其中,CE表示交叉熵损失,也可以替换为MSE,KL散度等其他衡量差异的公式,y为数据真实的label,q是前面公式的结果表示教师网络的输出,p表示学生网络的输出。
2.1 将BERT蒸馏到BiLSTM
Distilled BiLSTM 方法使用Bert-large作为教师网络,双向的LSTM作为学生网络,首先在Bert-large上面对任务进行微调学习,将教师网络训练结束后,使用原始数据集与增强的数据集对学生网络进行训练,loss的设计是与上面的大体思路相同但是细节有差异,本研究使用的是教师网络与学生网络之间 hard label的交叉熵+logits之间的MSE。
因为只使用原始的数据集教师网络模型效果较好,可能导致学生网络无法学习到有效的特征,作者对原始数据集进行了数据增强,具体的方法为:
-
使用[mask] 随机替代原始单词
-
基于POS标签对原始的单词进行同词性单词替换
-
在原始的句子中随机提取n-gram的多个单词构成新的句子
实验结果如下:
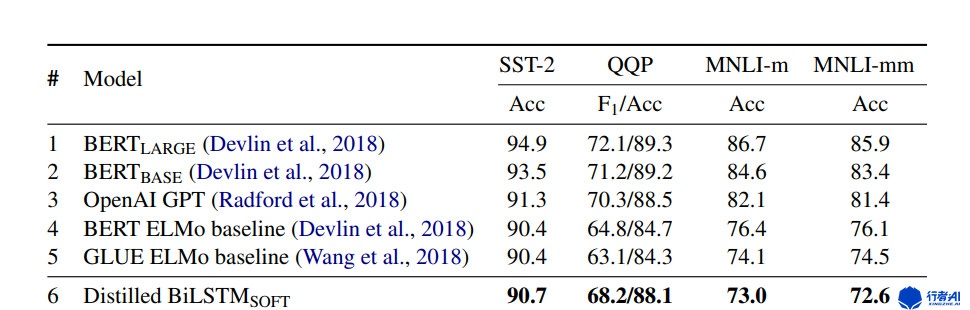
图3. Distilled BiLSTM实验结果
蒸馏后的模型在简单地分类任务上达到了与原始模型可比的效果,但是在复杂的任务上效果不尽如人意。与原始的教师模型相比,参数量减少了100倍,速度提升了15倍 。
2.2 将BERT蒸馏到transformer
将bert蒸馏到LSTM中,效果并不明显,主要有以下几点原因:
-
LSTM的参数量无法准确的表示复杂任务中的语义特征
-
只对微调过的模型进行蒸馏,无法完全学习到教师模型的全部泛化能力
-
只对教师模型的最后一层进行蒸馏是无法提取教师模型的全部知识
针对以上三点,许多研究人员对蒸馏模型进行了改进,后期的学生模型的选择基本为Transformer模型,比如BERT-PKD对Bert的中间层进行蒸馏,DIstillBERT在Bert的预训练阶段就开始蒸馏,TinyBERT更加具体的使用了教师模型的中间层的注意力矩阵,达到了很好的效果。
以TinyBERT为例
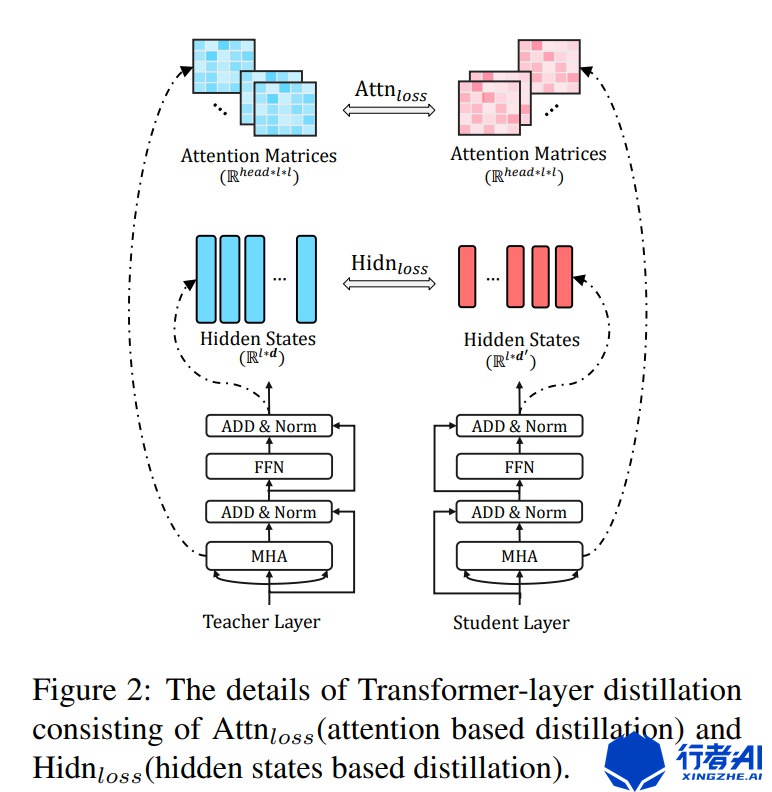
图4. tinyBert分层蒸馏图
此处的表示的是其中一层的蒸馏细节,对教师网络的每层Transformer的隐态和注意力矩阵同时学习,与学生网络的对应层计算得到Attn-loss和Hidn-loss。这与label loss和词向量loss综合起来作为整体的最终的loss。
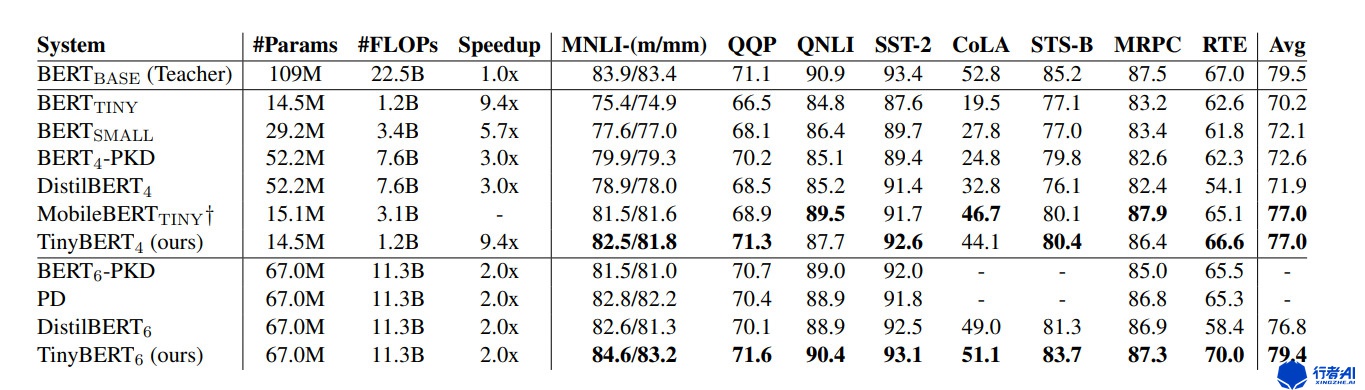
图5. tinyBert实验结果图
与2.1中将bert蒸馏到LSTM的效果有明显的进步。
3. 自适应退出机制(减少推理计算量)
在Bert的多层Transformer的使用中,我们发现每一层的结果都可以进行预测,底层的模型的准确率偏低,而高层的效果更好,这是因为上层的Transformer可以提取更多的语义信息。但是对于一些简单的特征明显的短文本分类任务,在推理时并不需要使用最后一层的结果,取中间层的结果就可以很好的进行预测。这与第二章所讲的蒸馏还存在一定差异,蒸馏是是把教师的知识转移到学生模型上,而早退出机制是自适应的选择在某一个中间层结束推理,这种机制可以在推理过程中大大加速推理速度。同时可以根据业务场景动态的调整自适应置信度阈值。
ACl2020中的FastBert第一次提出这种机制,这是CV领域每个样本走过不同路径的dynamic inference 的延展。作者在每一个Transformer层后面加一个全连接分类器,这些分类器为图中的Branch,原始Bert为主干。在训练过程中对主干进行训练微调。训练结束后,开始自蒸馏训练分支,使用主干的最后一层后面的全连接分类器作为教师,训练学生分支。这种蒸馏是一种自我蒸馏方法。loss的设计为衡量主干和分支的KL散度。
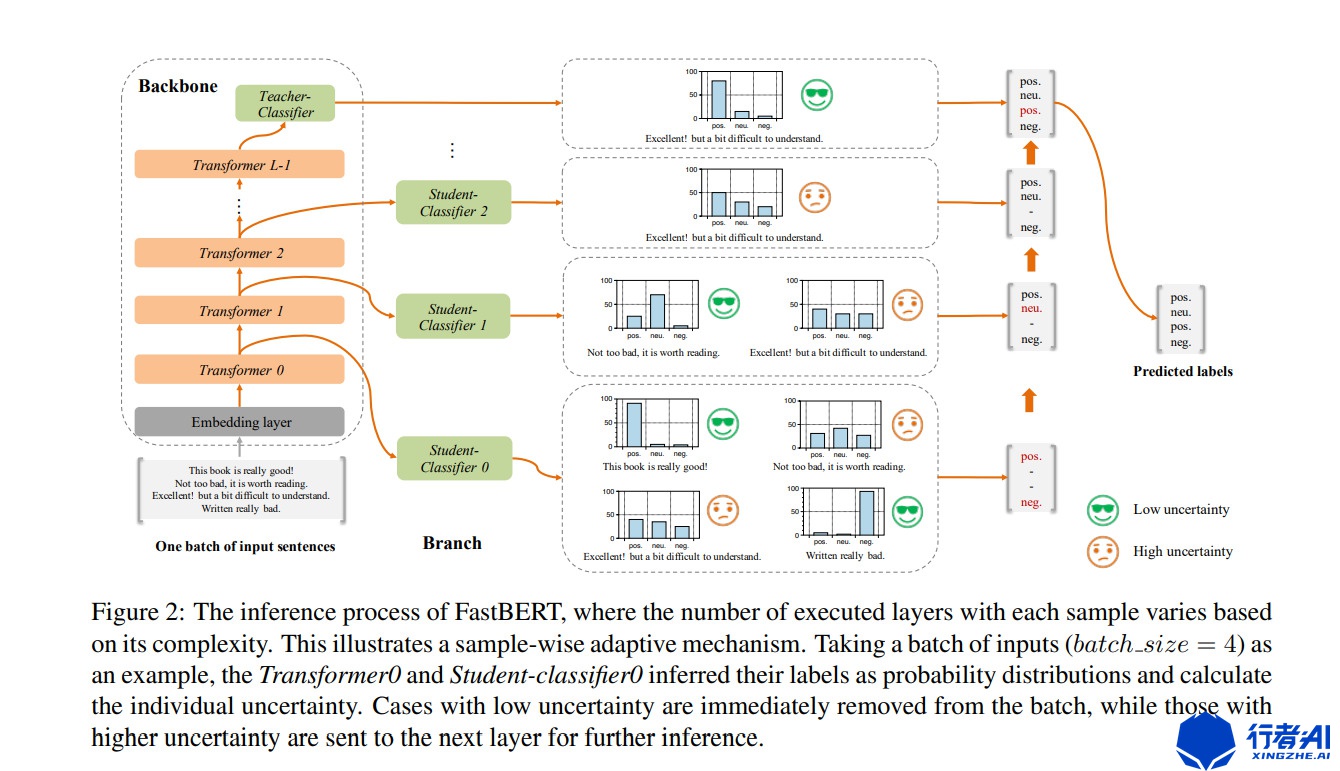
图6. fastBert模型图
在推理过程中,使用自适应的推理。 及根据分支分类器的结果对样本进行层层过滤,简单的直接给结果,困难的继续预测。这里作者定义了新的不确定性指标,用预测结果的熵来衡量,熵越大则不确定性越大:
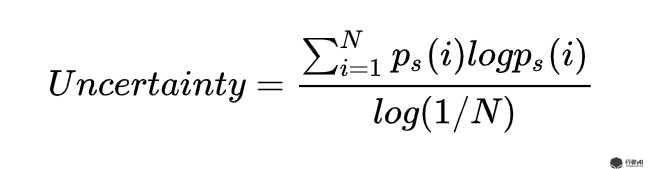
图7. 自适应不确定性指标计算公式
对于每层分类结果,作者用“Speed”代表不确定性的阈值,和推理速度是正比关系。因为阈值越小 => 不确定性越小 => 过滤的样本越少 => 推理速度越慢。
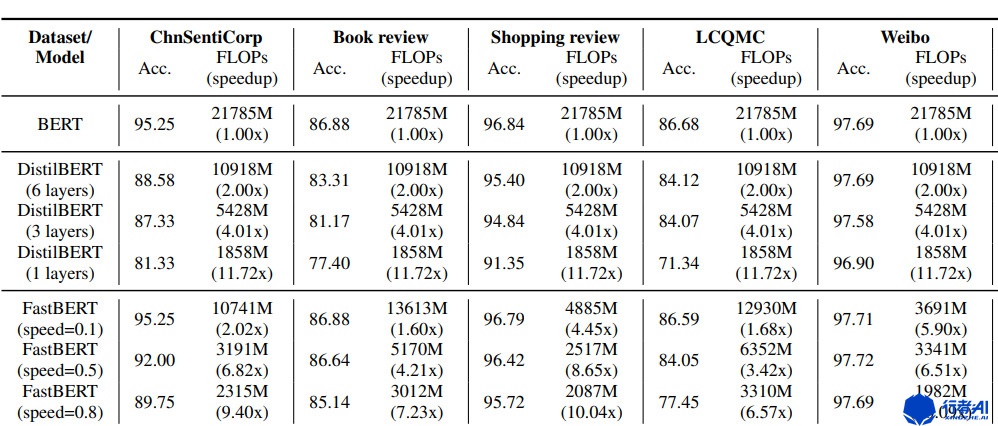
图8. fastBert结果展示图 根据作者的表述,speed=0.1,可以获得1-10倍的速度提升,计算量减半。这种方法在多个数据集的分类上表现出了很好的效果。但是,这个方法只能用于分类任务,需要根据业务进行转换。
4. 使用TextBrower进行实验
TextBrewer 是一个基于PyTorch的、为NLP中的知识蒸馏任务设计的工具包。
对于由哈工大深圳研究生院智能计算研究中心发布的句对二分类任务LCQMC, 任务的目的是判断两个句子的语义是否相同 。
教师网络为RoBERTa-wwm,对比结果情况如下:
| model | LCQMC (Acc) | Layers | Hidden_size | Feed-forward size | Params | Relative size |
|---|---|---|---|---|---|---|
| RoBERTa-wwm | 89.4 | 12 | 768 | 3072 | 108M | 100% |
| Bert | 86.68 | 12 | 768 | 3072 | 108M | 100% |
| T3 | 89.0 (30) | 3 | 768 | 3072 | 44M | 41% |
| T3-small | 88.1 (30) | 3 | 384 | 1536 | 17M | 16% |
| T4-tiny | 88.4 (30) | 4 | 312 | 1200 | 14M | 13% |
以RoBERTa-wwm作为教师网络达到了优于Bert-base的效果。
参考文献:
[1] Distilling the Knowledge in a Neural Network: https://arxiv.org/abs/1503.02531
[2] Distilling Task-Specific Knowledge from BERT into Simple Neural Networks: https://arxiv.org/abs/1903.12136
[3] Patient Knowledge Distillation for BERT Model Compression: https://arxiv.org/abs/1908.09355
[4] DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter: https://arxiv.org/abs/1910.01108
[5] TinyBERT: Distilling BERT for Natural Language Understanding: https://arxiv.org/abs/1909.1035
[6] FastBERT: a Self-distilling BERT with Adaptive Inference Time: https://arxiv.org/abs/2004.02178,
[7] TextBrewer: https://github.com/airaria/TextBrewer
标签:BERT,蒸馏,训练,教师,模型,网络,功夫,深度,文本 From: https://www.cnblogs.com/erwin/p/16741641.html
行者AI(成都潜在人工智能科技有限公司,xingzhe.ai)致力于使用人工智能和机器学习技术提高游戏和文娱行业的生产力,并持续改善行业的用户体验。我们有内容安全团队、游戏机器人团队、数据平台团队、智能音乐团队和自动化测试团队。 > >如果您对世界拥有强烈的好奇心,不畏惧挑战性问题;能够容忍摸索过程中的各种不确定性、并且坚持下去;能够寻找创新的方式来应对挑战,并同时拥有事无巨细的责任心以确保解决方案的有效执行。那么请将您的个人简历、相关的工作成果及您具体感兴趣的职位提交给我们。我们欢迎拥抱挑战、并具有创新思维的人才加入我们的团队。请联系:[email protected] > >如果您有任何关于内容安全、游戏机器人、数据平台、智能音乐和自动化测试方面的需求,我们也非常荣幸能为您服务。可以联系:[email protected]
