Layer Normalization #paper
1. paper-info
1.1 Metadata
- Author:: [[Jimmy Lei Ba]], [[Jamie Ryan Kiros]], [[Geoffrey E. Hinton]]
- 作者机构::
- Keywords:: #DeepLearning , #LayerNormalization
- Journal:: -
- Date:: [[2016-07-21]]
- 状态:: #Done
- 链接:: https://doi.org/10.48550/arXiv.1607.06450
1.2 Abstract
Training state-of-the-art, deep neural networks is computationally expensive. One way to reduce the training time is to normalize the activities of the neurons. A recently introduced technique called batch normalization uses the distribution of the summed input to a neuron over a mini-batch of training cases to compute a mean and variance which are then used to normalize the summed input to that neuron on each training case. This significantly reduces the training time in feed-forward neural networks. However, the effect of batch normalization is dependent on the mini-batch size and it is not obvious how to apply it to recurrent neural networks. In this paper, we transpose batch normalization into layer normalization by computing the mean and variance used for normalization from all of the summed inputs to the neurons in a layer on a single training case. Like batch normalization, we also give each neuron its own adaptive bias and gain which are applied after the normalization but before the non-linearity. Unlike batch normalization, layer normalization performs exactly the same computation at training and test times. It is also straightforward to apply to recurrent neural networks by computing the normalization statistics separately at each time step. Layer normalization is very effective at stabilizing the hidden state dynamics in recurrent networks. Empirically, we show that layer normalization can substantially reduce the training time compared with previously published techniques.
normalization的作用是减少训练次数,内在原因是因为使用过normalization之后,梯度消失的问题得到解决,可以使用更大的学习率使得训练加快
batch normalization: 在一个批次内计算期望和方差。
2. Batch Normalization
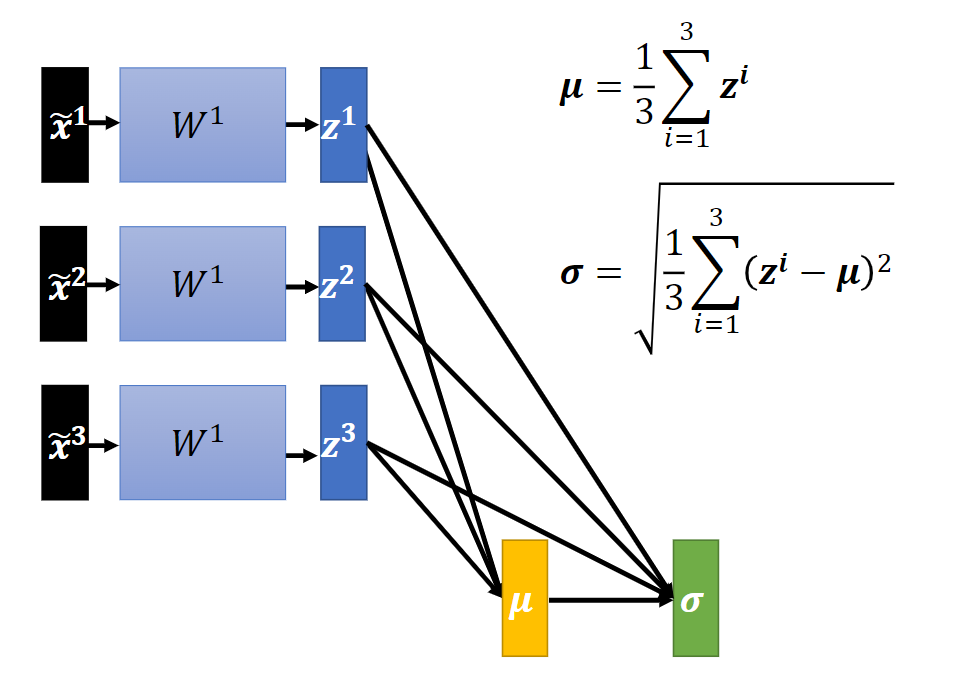
图 2-1
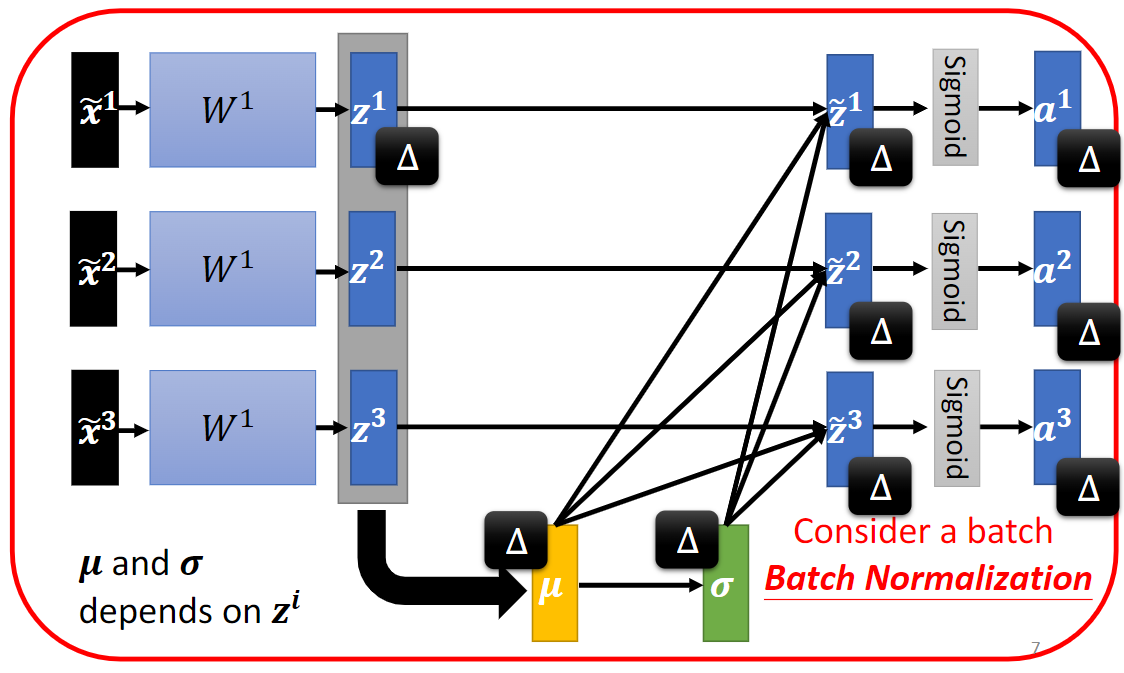
图 2-2
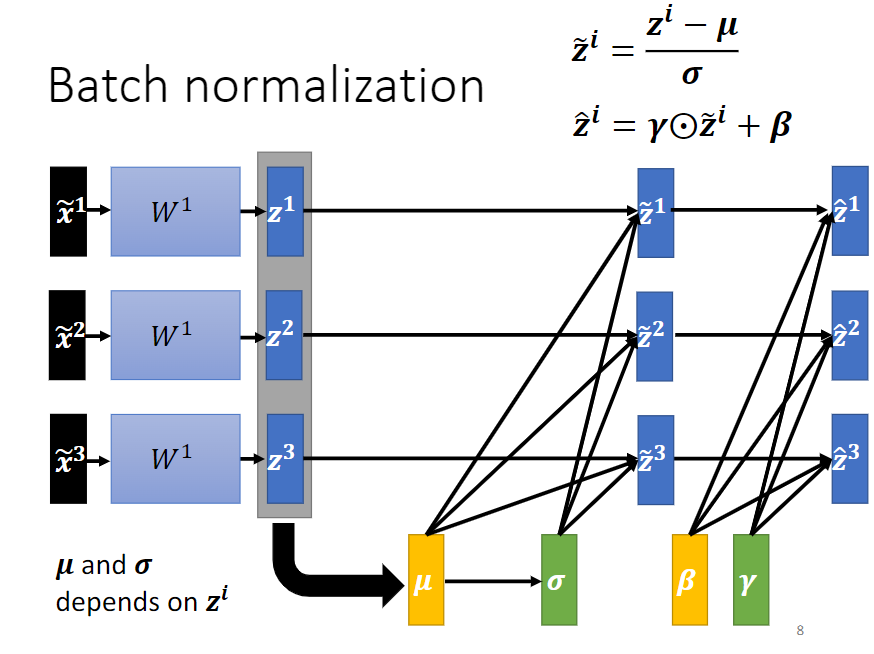
图 2-3
问题:
- 无法处理小批量的数据
- 在RNN效果不好
- 训练后对测试不友好
参考
https://zhuanlan.zhihu.com/p/54171297 模型优化之Batch Normalization
https://zhuanlan.zhihu.com/p/86765356 各种Normalization
3. Layer Normalization
layer normalization 可以克服batch normalization 缺点,layer normalization 是在同一层计算。计算公式如图 3-1
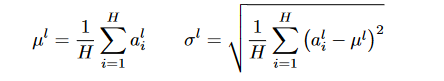
图 3-1 计算公式
3.1 code
import torch
import torch.nn as nn
__all__ = ['LayerNormalization']
class LayerNormalization(nn.Module):
def __init__(self,
normal_shape,
gamma=True,
beta=True,
epsilon=1e-10):
"""Layer normalization layer
See: [Layer Normalization](https://arxiv.org/pdf/1607.06450.pdf)
:param normal_shape: The shape of the input tensor or the last dimension of the input tensor.
:param gamma: Add a scale parameter if it is True.
:param beta: Add an offset parameter if it is True.
:param epsilon: Epsilon for calculating variance.
"""
super(LayerNormalization, self).__init__()
if isinstance(normal_shape, int):
normal_shape = (normal_shape,)
else:
normal_shape = (normal_shape[-1],)
self.normal_shape = torch.Size(normal_shape)
self.epsilon = epsilon
if gamma:
self.gamma = nn.Parameter(torch.Tensor(*normal_shape))
else:
self.register_parameter('gamma', None)
if beta:
self.beta = nn.Parameter(torch.Tensor(*normal_shape))
else:
self.register_parameter('beta', None)
self.reset_parameters()
def reset_parameters(self):
if self.gamma is not None:
self.gamma.data.fill_(1)
if self.beta is not None:
self.beta.data.zero_()
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
var = ((x - mean) ** 2).mean(dim=-1, keepdim=True)
std = (var + self.epsilon).sqrt()
y = (x - mean) / std
if self.gamma is not None:
y *= self.gamma
if self.beta is not None:
y += self.beta
return y
def extra_repr(self):
return 'normal_shape={}, gamma={}, beta={}, epsilon={}'.format(
self.normal_shape, self.gamma is not None, self.beta is not None, self.epsilon,
)
Reference
https://www.cvmart.net/community/detail/3897 神经网络中 Normalization 的发展历程
https://zhuanlan.zhihu.com/p/74516930 NLP中 batch normalization与 layer normalization
标签:beta,normal,self,LayerNormalization2016,batch,shape,normalization From: https://www.cnblogs.com/guixu/p/16739457.html