金融时间序列预测方法合集:CNN、LSTM、随机森林、ARMA预测股票价格(适用于时序问题)、相似度计算、各类评判指标绘图(数学建模科研适用)
1.使用CNN模型预测未来一天的股价涨跌-CNN(卷积神经网络)
使用CNN模型预测未来一天的股价涨跌
数据介绍
open 开盘价;close 收盘价;high 最高价
low 最低价;volume 交易量;label 涨/跌
训练规模
特征数量×5;天数×5 = 5 × 5
卷积过程
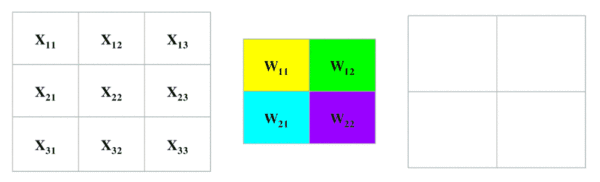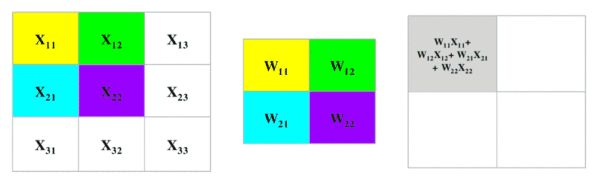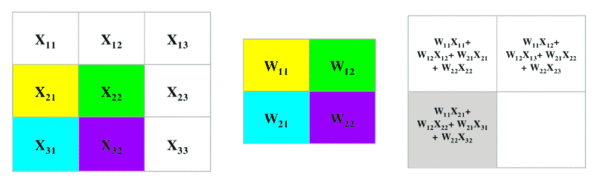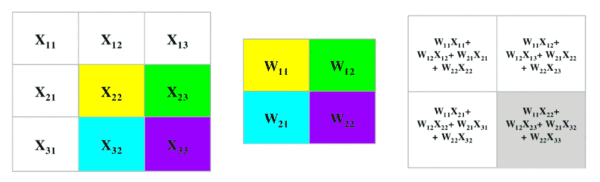
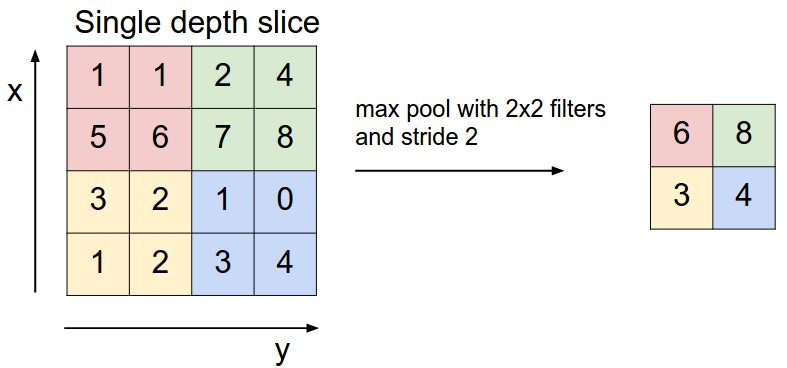
最大池化过程
代码流程
- 获取股票数据
- 数据归一化
- 数据预处理(划分成5×5)
- 数据集分割(训练集和测试集)
- 定义卷积神经网络
- 评估预测模型
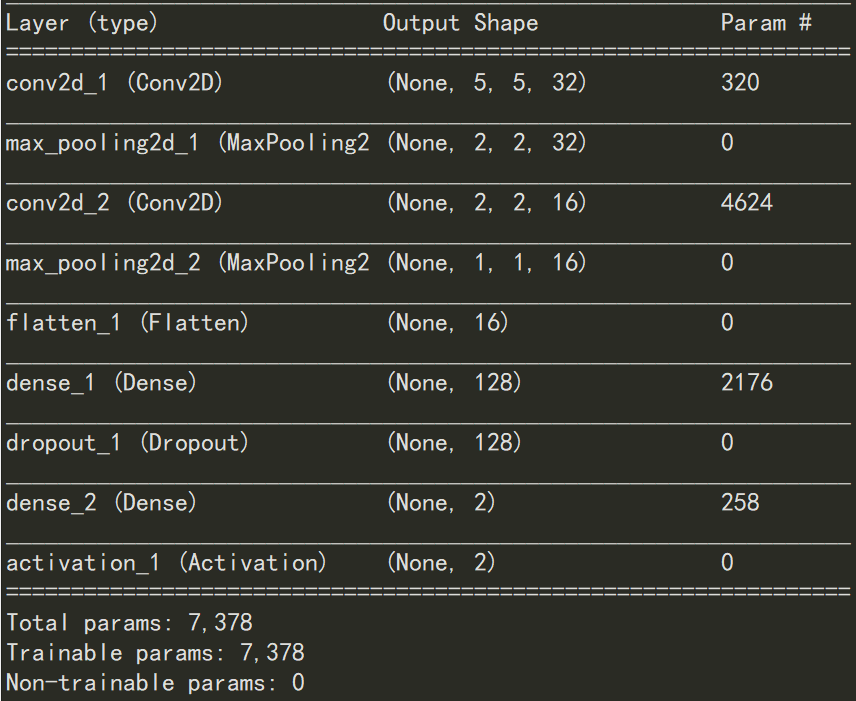
模型架构
码源链接见文末跳转
2.基于LSTM预测股票价格(长短期记忆神经网络)
基于LSTM预测股票价格(简易版)
数据集:
沪深300数据
数据特征:
只选用原始数据特征(开盘价、收盘价、最高价、最低价、交易量)
时间窗口:
15天
代码流程:
读取数据->生成标签(下一天收盘价)->分割数据集->LSTM模型预测->可视化->预测结果评估
LSTM网络结构:

函数介绍:
1、generate_label 生成标签(下一天收盘价)
2、generate_model_data 分割数据集
3、evaluate 结果评估
4、lstm_model LSTM预测模型
5、main 主函数(含可视化)
可视化输出:
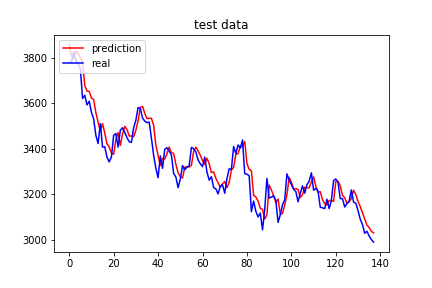
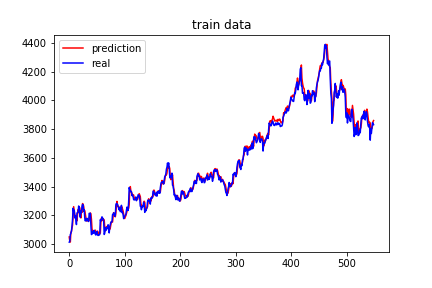
训练集测试集拟合效果:
评估指标:
1、RMSE:55.93668241713906
2、MAE:44.51361108752264
3、MAPE:1.3418267677320612
4、AMAPE:1.3420384401412058
3.基于随机森林预测股票未来第d+k天相比于第d天的涨/跌Random-Forest(随机森林)
基于随机森林预测股票未来第d+k天相比于第d天的涨/跌(简易版)
参考论文:Predicting the direction of stock market prices using random forest
论文流程:
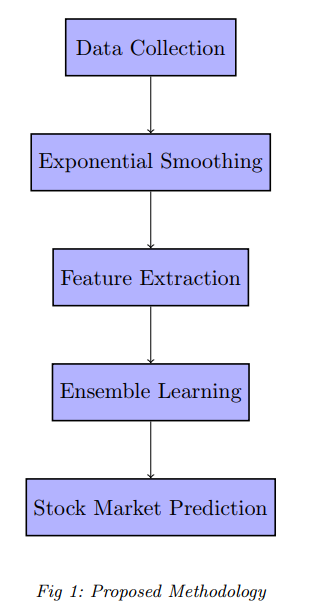
算法流程:
获取金融数据->指数平滑->计算技术指标->数据归一化->随机森林模型预测
函数介绍:
1、get_stock_data 通过Tushare获取原始股票数据
2、exponential_smoothing、em_stock_data 股票指数平滑处理
3、calc_technical_indicators 计算常用的技术指标
4、normalization 数据归一化处理并分割数据集
5、random_forest_model 随机森林模型并返回准确率和特征排名
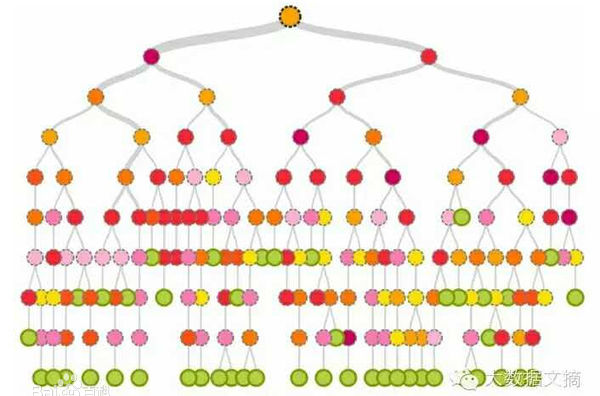
决策树:
(1)ID3: 基于信息增益大的数据特征划分层次
(2)C4.5: 基于信息增益比=信息增益/特征熵划分层次
(3)CART: 基于Gini划分层次
基于Bagging集成学习算法,有多棵决策树组成(通常是CART决策树),其主要特性有:
(1)样本和特征随机采样
(2)适用于数据维度大的数据集
(3)对异常样本点不敏感
(4)可以并行训练(决策树间独立同分布)
算法输出:
注意:算法仅用于参考学习交流,由于是研一时期独立编写(以后可能进一步完善),所公开的代码并非足够完善和严谨,如以下问题:
-
模型涉及参数未寻优(可考虑网格搜索、随机搜索、贝叶斯优化)
-
指数平滑因子
-
随机森林模型树数量、决策树深度、叶子节点最小样本数等
-
未来第k天的选择
-
归一化方法
-
-
随机森林模型其实本身不需要数据归一化(如算法对数据集进行归一化也需要考虑对训练集、验证集、测试集独立归一化)
-
股票预测考虑的数据特征:
-
原始数据特征(open/close/high/low)
-
技术指标(Technical indicator)
-
企业公开公告信息
-
企业未来规划
-
企业年度报表
-
社会舆论
-
股民情绪
-
国家政策
-
股票间影响等
-
4.模型输出结果

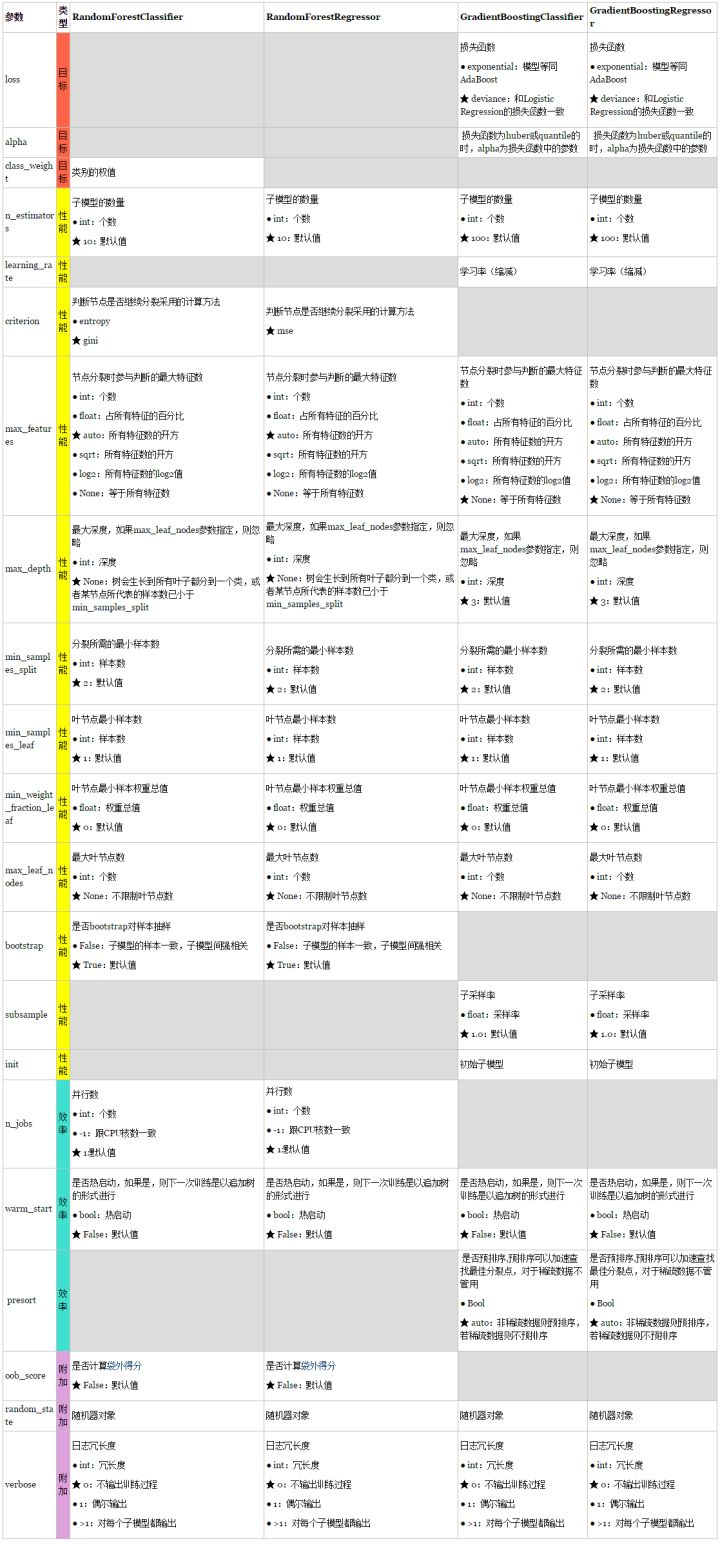
5.随机森林参数优化参考表
4.基于ARMA预测股票价格-ARMA(自回归滑动平均模型)
基于ARMA预测股票价格(5分钟数据)
1.检测数据平稳化
2.差分/对数等数据处理
3.使用ARMA模型预测
备注:部分代码参考网络资源
5.金融时间序列相似度计算
5.1.皮尔逊相关系数( pearson_correlation_coefficient)
1.1 由于不同股票价格范围差距过大,在进行股票时间序列相似度匹配过程中通常考虑对数差处理,其公式如下所示:
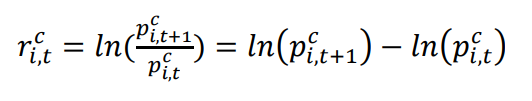
1.2经过对数差处理后的金融时间序列可表示:
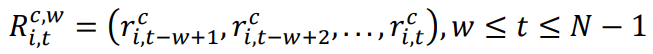
1.3皮尔逊相关系数计算公式:
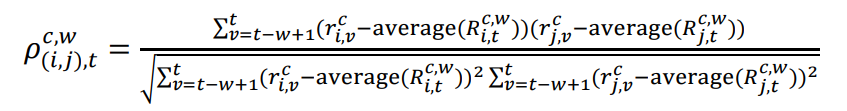
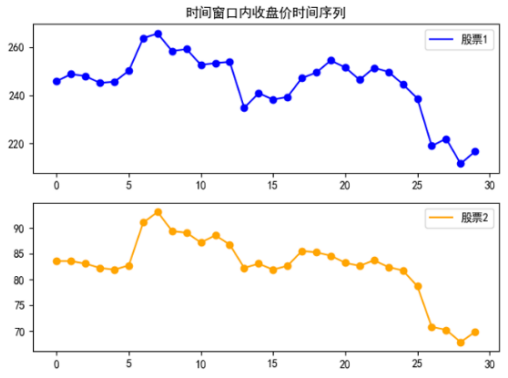
1.4结果
1.4.1相关性较强
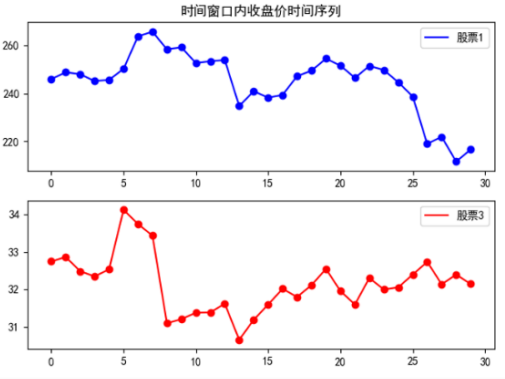
1.4.2相关性较弱
5.2.动态时间规整(dynamic_time_wrapping)
2.1 计算两个金融时间序列的时间点对应数据的欧氏距离
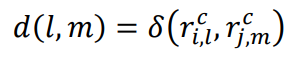
2.2 更新时间点对应数据的距离
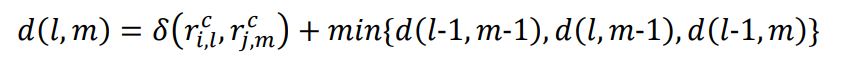
2.3 动态时间规整距离
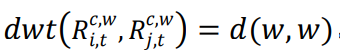
2.4 伪代码

2.5 动态时间规整距离输出图举例
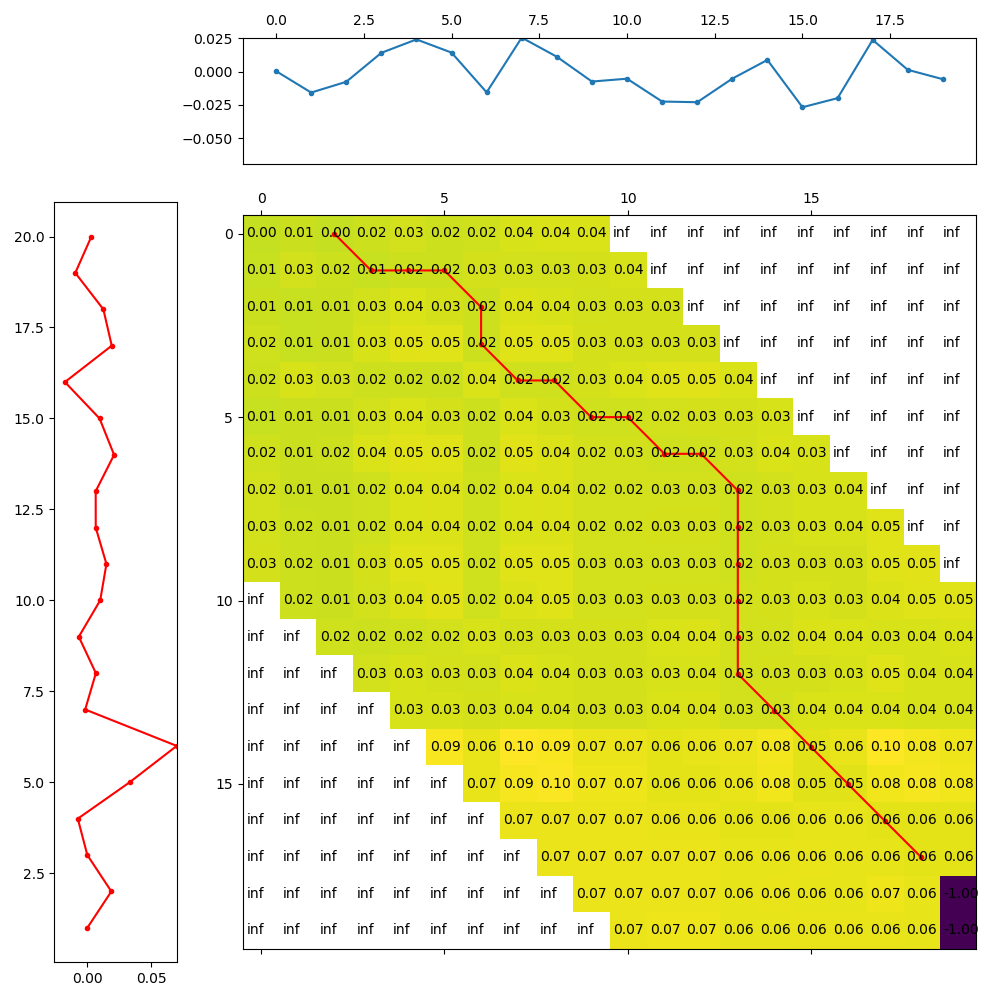
2.6 动态时间规整最优匹配对齐
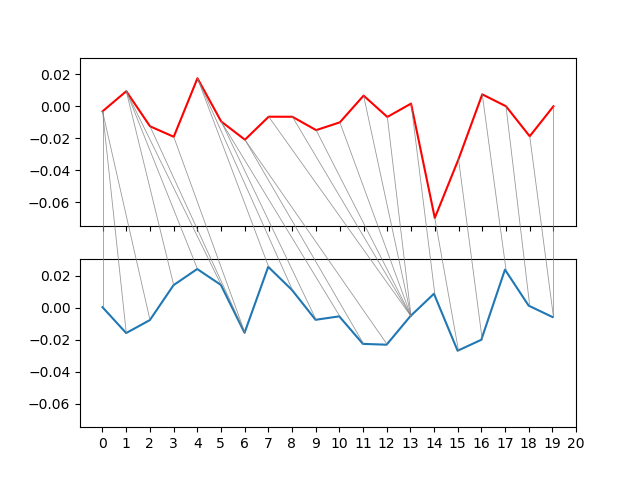
2.7结果
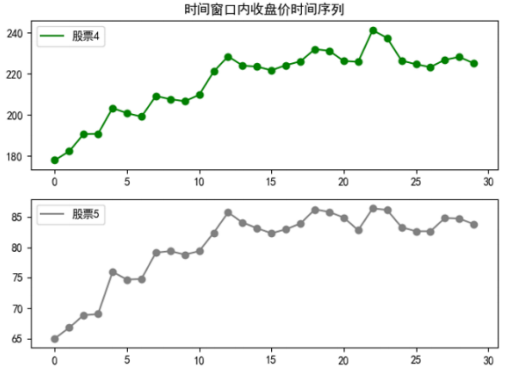
2.7.1动态时间规整距离较短
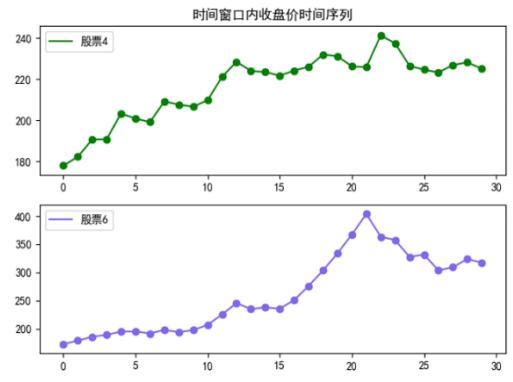
2.7.1动态时间规整距离较长
5.3.余弦相似度(cosine similarity)
6.金融时间序列(其他)
6.1.计算特征方差(calc_variance.py)
open 161211.21669504658
close 161415.73886306392
high 166077.6958545937
low 156622.3645795179
......
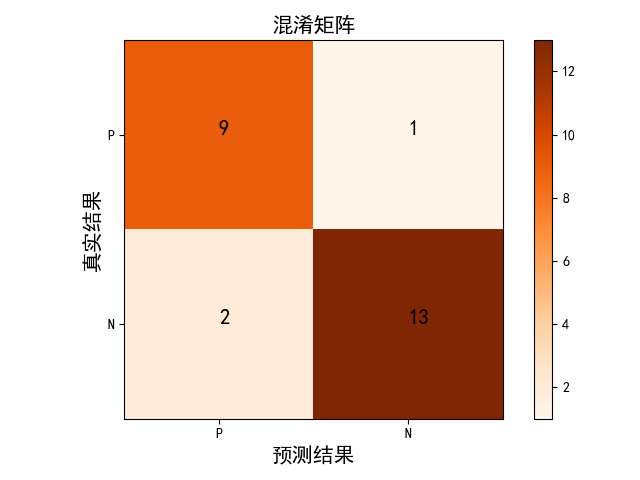
6.2.绘制混淆矩阵(confuse_matrix.py)
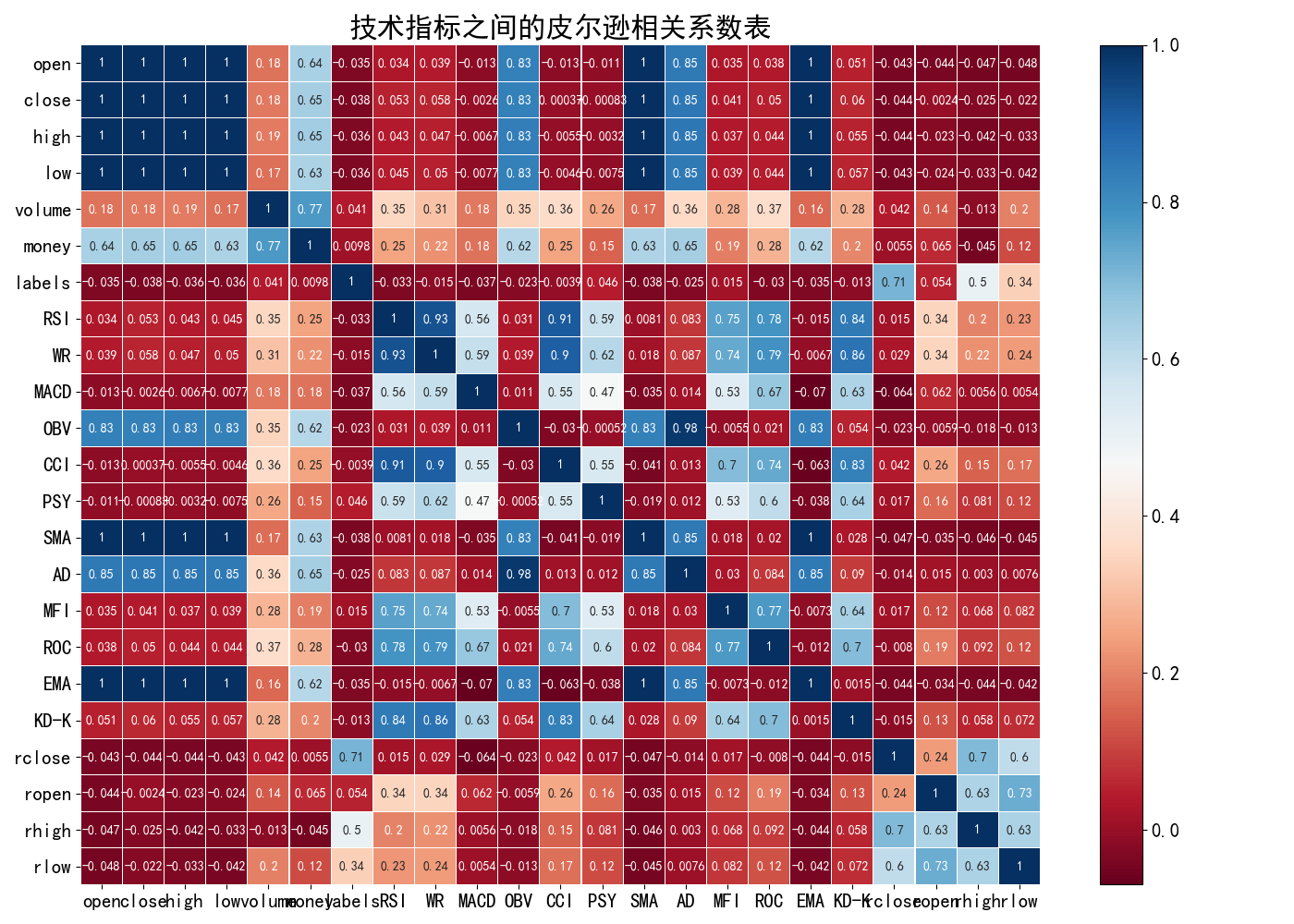
6.3.特征间相关性(corr.py)
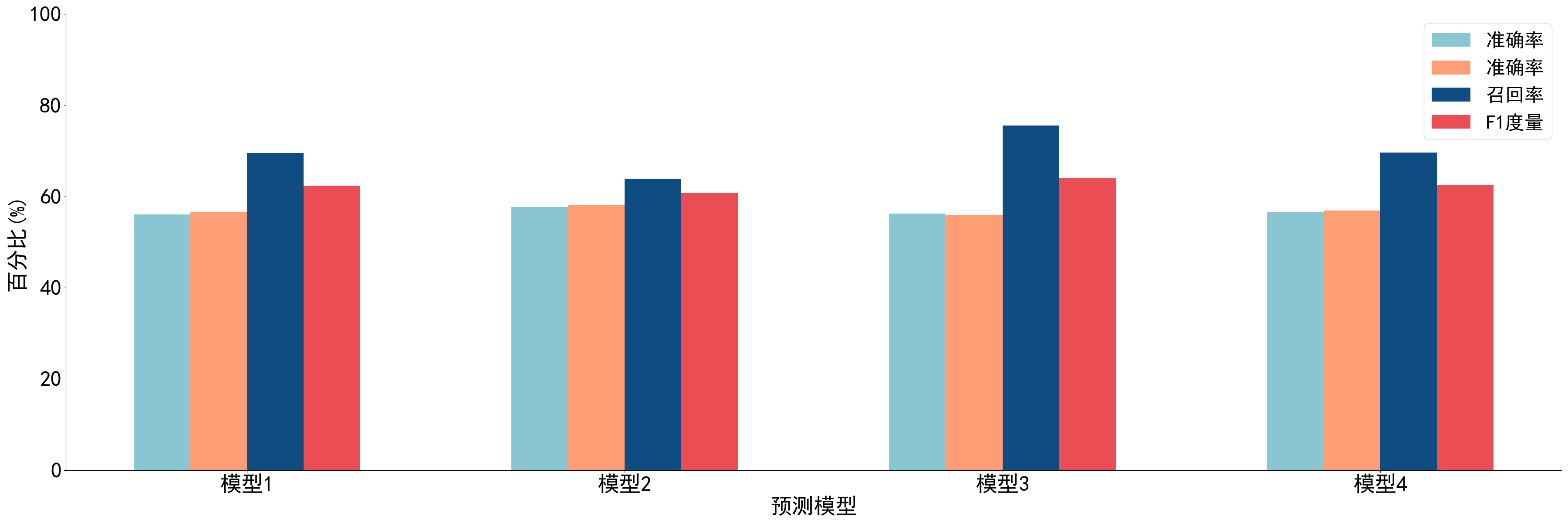
6.4.绘制预测模型性能——柱状图(result_bar.py)
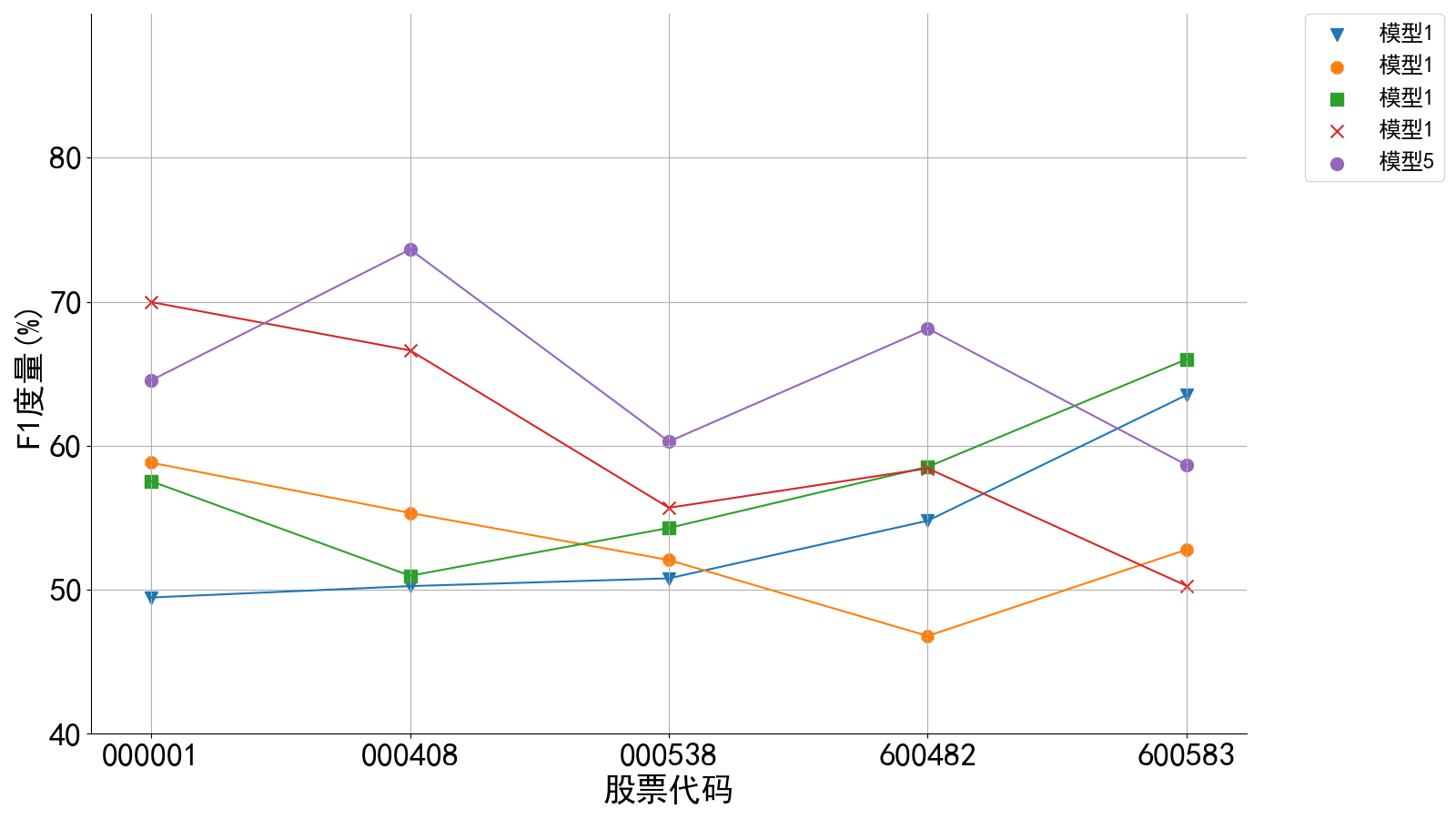
6.5.绘制预测模型性能——折线图(result_plot.py)
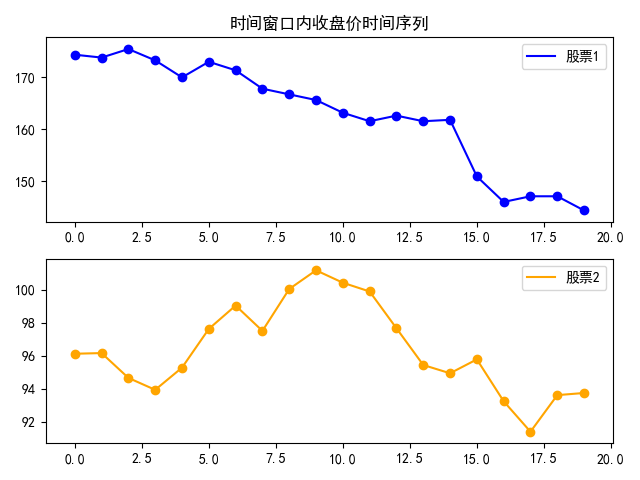
6.6.相似金融时间序列绘制(similarity_time_series.py)
6.7.计算分类的评价指标(evaluation.py)
(1)准确率Accuracy
(2)精确率Precision
(3)召回率Recall
(4)特异度Specificity
(5)综合评价指标F-measure
(6)马修斯相关系数MCC(Matthews Correlation Coefficient)
6.8.窗口数据归一化(normalization.py)
(1)z-score标准化(std)
(2)最大最小归一化(maxmin)
6.9.股票数据下载(download.py)
(1)tushare接口
(2)JQdata接口
6.10.roc曲线绘制(roc.py)
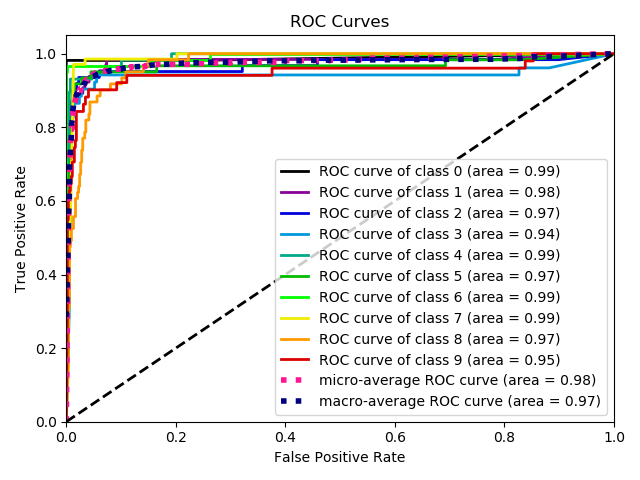
6.11.混淆矩阵绘制(confusion_matrix.py)
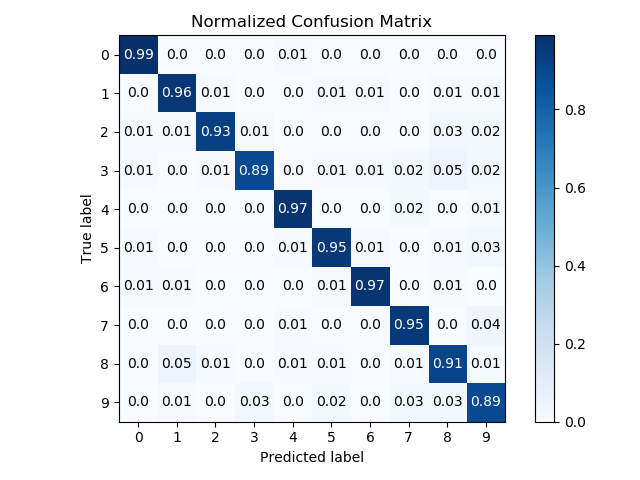
6.12.卡尔曼滤波(kalmanfilter.py)
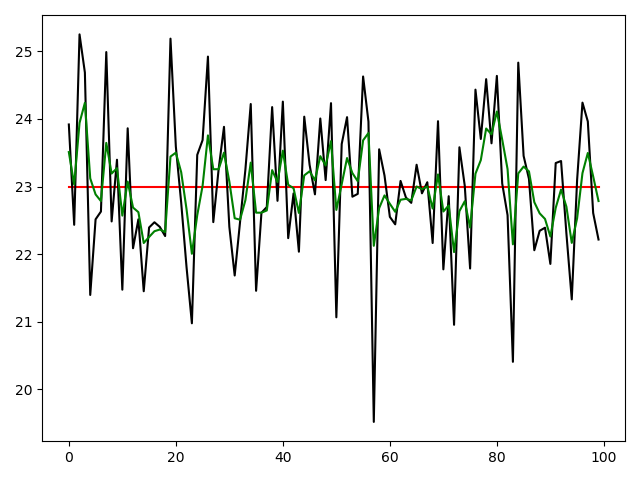
6.13.蜡烛图 (candle.py)
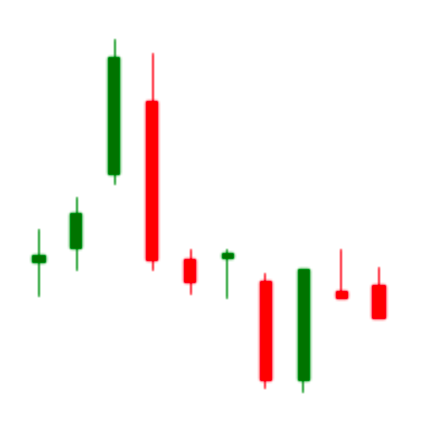
码源链接见文末跳转
更多优质内容请关注公号&知乎:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

