自从 ChatGPT 出现以来,我们见证了大语言模型 (LLM) 领域前所未有的发展,尤其是对话类模型,经过微调以后可以根据给出的提示语 (prompt) 来完成相关要求和命令。然而,直到如今我们也无法对比这些大模型的性能,因为缺乏一个统一的基准,难以严谨地去测试它们各自的性能。评测我们发给它们的指令以及对话模型本身,从本质上来讲就很困难,毕竟用户的评价标准都是围绕对回答的质量的主观感受; 而现有的自然语言处理任务的性能评价标准,却大多局限于特定指标和某些定量标准。
在这一领域,通常当一个新的大语言模型发布时,都会这么宣传: 我们的模型比在百分之多少的情况下优于 ChatGPT。这句话的潜在意思是,模型使用某些基于 GPT-4 的评价标准,在百分之多少的情况下优于 ChatGPT。这些分数实际想表达的是一种不同评价标准的代替方案: 由人类打标者提供的分数。利用人类反馈的强化学习 (RLHF) 大量提供了对比两个模型的接口和数据。这些从 RLHF 而来的数据被用来训练一个奖励模型,用以评判哪个回答是更好的,但为模型输出结果进行打分和排名的这一思想已经演变成了一种更通用的模型评测工具。
这里我们展示一些示例,分别来自我们的盲测数据中的 instruct 和 code-instruct 两个子集合。

从迭代速度来讲,使用一个语言模型去评测模型输出已经十分高效了,但这里遗漏了一个大问题: 有没有调研这个下游的快捷工具是否针对原有的评测形式进行了校准对齐。在本文中,我们将会详细了解: 通过扩展 Open LLM Leaderboard 评测体系,哪些时候你需要相信或不相信你从你选择的大语言模型中得到的数据标签。
现如今,各种排行榜已经开始涌现,比如 LMSYS 以及 nomic / GPT4All 等,用以从各种角度对比模型。但我们仍需要一个更完整的资源,用以对比模型性能。有些人会使用现有的 NLP 测试基准,看一看提问回答的能力; 还有些人会用一些众包的、开放式问答的排行榜。为了为大家提供一个更全面通用的评测方法,我们扩展了 Hugging Face Open LLM Leaderboard,囊括了各个自动化的学术评测基准、专业人员的打标,以及 GPT-4 相关的评测方法。
目录
评估开源模型的偏好
在训练阶段的任何时间点,人工组织数据的需求从内在来看都是成本很高的。迄今为止,在这一领域仅存在少量人工标注的偏好数据集可以用来训练大模型,例如 Anthropic’s HHH data、OpenAssistant’s dialogue rankings 或是 OpenAI 的 Learning to Summarize / WebGPT 数据集。相同的偏好标签也可以用模型输出获取,用以构建两两模型间的 Elo 排序 (Elo 排序 是常用于象棋或游戏中的一种通过两两对比构建全局排行榜的方法,排名越高越好)。当给到标注者的文本源是由我们关注的模型生成时,数据就变得很有趣了。
训练模型的过程会发生很多意想不到的趣事,所以我们需要对各个开源模型做一个更严格的对照实验,看看偏好收集过程如何转化为当今盛行的 GPT-4/ChatGPT 偏好评估,以及与它们的差异对比。
为了这一目的,我们组织了一个指令提示语的集合,以及对应的一系列由开源模型 ( Koala 13b、Vicuna 13b、OpenAssistant 12b、Dolly 12b) 完成的补全。

我们从 Self-Instruct 评测集中收集了一系列高质量、由人编写的提示语,同时也从数据商那里收集了一些早期的讨论类对话数据,涵盖了生成、头脑风暴、问答、总结、常识、编程等各种任务类别。总共有 327 条覆盖这些任务类型的提示语,其中 25 条是编程相关的。
这里我们列出一些提示语相关的数据统计,包括其句子长度。
| prompt | completions | |
|---|---|---|
| count | 327 | 327 |
| length (mean ± std. dev.) in tokens | 24 ± 38 | 69 ± 79 |
| min. length | 3 | 1 |
| 25% percentile length | 10 | 18 |
| 50% percentile length | 15 | 42 |
| 75% percentile length | 23 | 83 |
| max | 381 | 546 |
借助这些数据,我们开始使用 Scale AI 和 GPT-4 去评估模型质量。我们针对偏好模型使用 Antropic 的方法,并要求打分者去依照利克特 (Likert) 量表打 1 到 8 分。在这个范围内,1 分代表打分者相比第一个模型,对当前模型有强烈偏好; 4 分表示基本与第一个模型持平; 8 分则代表评价者的观点与 1 分完全相反。
人工 Elo 结果
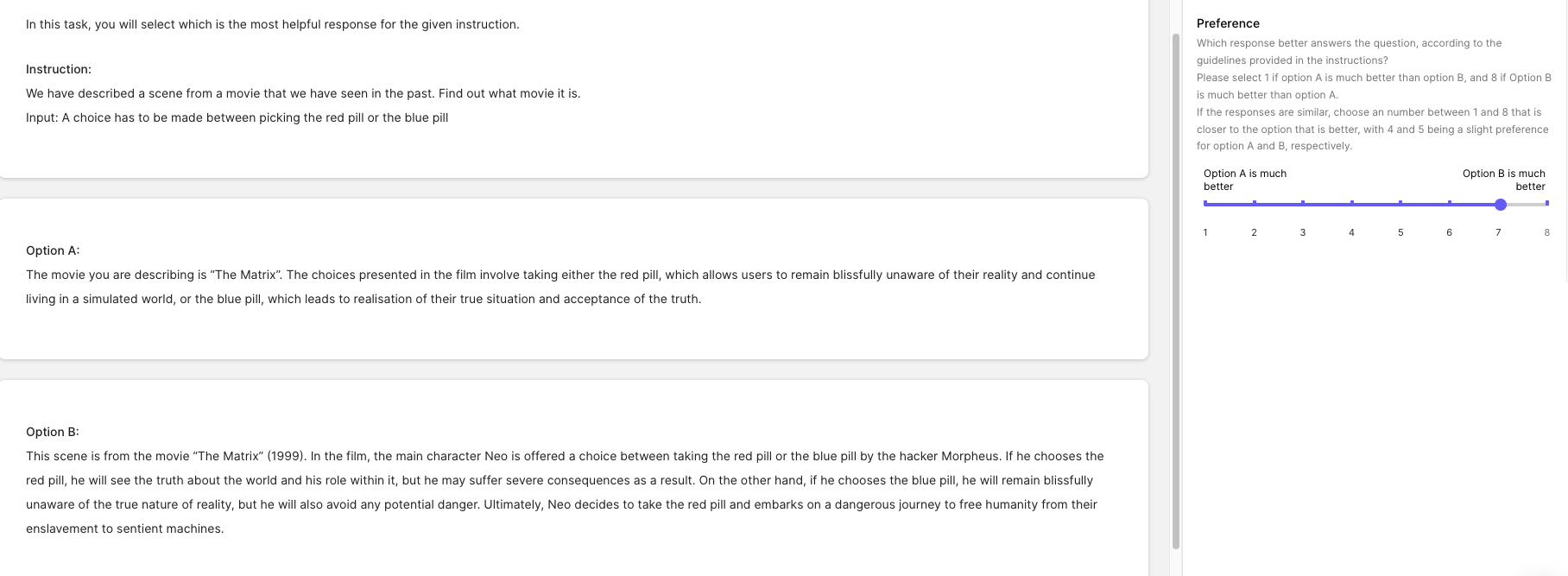
我们与 Scale AI 合作,为一些开源的指令调教的模型基于我们的盲测集收集了高质量的人工标注。我们要求标注者以一种两两对比的形式,针对有用性和真实性对模型的回答打分。为此,我们为每个提示语生成了 $ n \choose 2 $ 个组合对,其中 \(n\) 是我们要评测的模型的数量。下图就是一个为人工标注者提供的打分页面,其中包含了给标注者发出的任务指示 (相关工具由 Scale AI 提供)。
使用这一数据,我们依据两两模型间的胜率“自举地”估算出了 Elo 排序结果。如果读者对 Elo 的过程感兴趣,可以阅读 LMSYS 的这篇 notebook,我们盲测集上的 Elo 分数也在 leaderboard 上有列出。
在本文中,我们会展示“自举”估算 Elo 的方法以及其中的错误估算。下表列出了依据我们盲测集和标注人员的排行榜:
**************不含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来) **************
| Model | Elo ranking (median) | 5th and 95th percentiles |
|---|---|---|
| Vicuna-13B | 1140 | 1061 ↔ 1219 |
| Koala-13B | 1073 | 999 ↔ 1147 |
| Oasst-12B | 986 | 913 ↔ 1061 |
| Dolly-12B | 802 | 730 ↔ 878 |
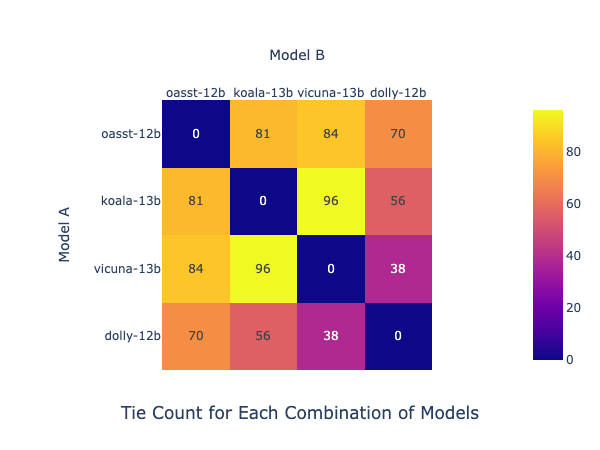
针对利克特量表,打分打到 4 或 5 分是否构成一场胜利也很有争议。所以我们也计算了一个当 4 或 5 分表示平局时的 Elo 排序。但基于这一改变,我们并没有观察到模型间相互胜负的太大变化。平局的计数 (每对模型间对局 327 次) 和新的 Elo 排序如下图所示。每格的数字代表两个模型的平局数,比如,Koala-13B 和 Vicuna-13B 之间由最多的平局 (96 次),说明它们可能性能非常相近。
注意这张表的读法: 选取一行,如 oasst-12b ,然后横向看这个模型和其它各个模型分别有多少场平局。
**************包含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来) **************
| Model | Elo ranking (median) | 5th and 95th percentiles |
|---|---|---|
| Vicuna-13B | 1130 | 1066 ↔ 1192 |
| Koala-13B | 1061 | 998 ↔ 1128 |
| Oasst-12B | 988 | 918 ↔ 1051 |
| Dolly-12B | 820 | 760 ↔ 890 |
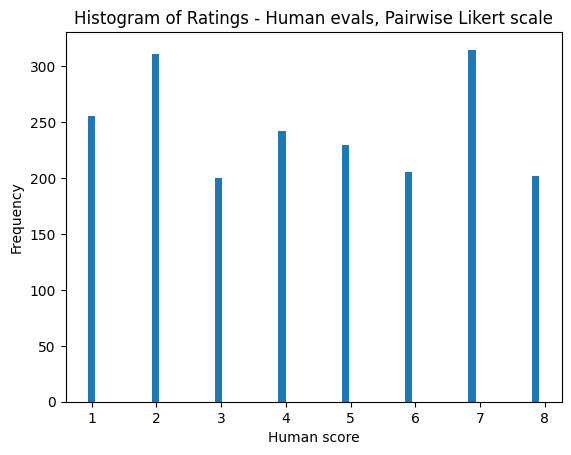
下图统计了打分的分布情况,数据来自 Scale AI taskforce。
在本文接下来内容中,你还会看到基于不同数据生成准测的相似分析流程。
GPT-4 的 Elo 结果
接下来我们来看看 GPT-4 如何对比结果。几个待评测模型的顺序不变,但相对的间隔变了。
不含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
|---|---|---|
| vicuna-13b | 1134 | 1036 ↔ 1222 |
| koala-13b | 1082 | 989 ↔ 1169 |
| oasst-12b | 972 | 874 ↔ 1062 |
| dolly-12b | 812 | 723 ↔ 909 |
包含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)
提醒一下,利克特 1 到 8 分量表中,4 或 5 分代表平局
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
|---|---|---|
| vicuna-13b | 1114 | 1033 ↔ 1194 |
| koala-13b | 1082 | 995 ↔ 1172 |
| oasst-12b | 973 | 885 ↔ 1054 |
| dolly-12b | 831 | 742 ↔ 919 |
为此,我们使用了一个由 FastChat evaluation prompts 改编而来的提示语,以便用较短的句子长度来获得更快和更低成本的生成结果 (比如解释性的话语大多数时间都舍弃掉了)。
### Question
{question}
### The Start of Assistant 1's Answer
{answer_1}
### The End of Assistant 1's Answer
### The Start of Assistant 2's Answer
{answer_2}
### The End of Assistant 2's Answer
### System
We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.
Please compare the helpfulness, relevance, accuracy, level of details of their responses.
The rating should be from the set of 1, 2, 3, 4, 5, 6, 7, or 8, where higher numbers indicated that Assistant 2 was better than Assistant 1.
Please first output a single line containing only one value indicating the preference between Assistant 1 and 2.
In the subsequent line, please provide a brief explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment.
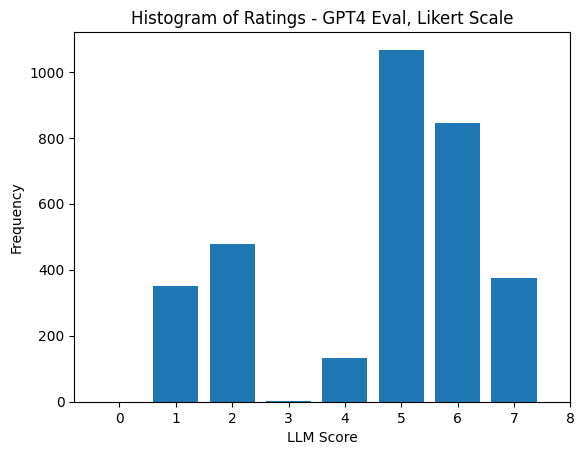
下面基于 GPT-4 关于回答的柱状图开始显示一个基于大语言模型评测的明显问题了: 位置偏差 ( positional bias )。哪个模型对应上面的 answer_1 是完全随机的。
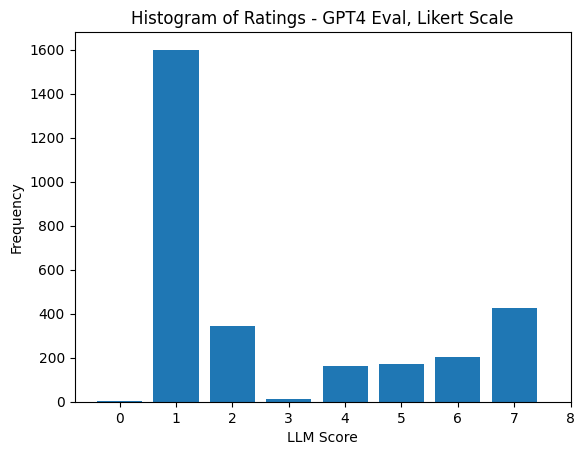
鉴于 GPT-4 评价的不确定性,我们决定加上一个新的评测基准: 高度训练过的人类打标者的补全。我们希望知道人类给出的 Elo 排序会是什么样的。
GPT-4 Elo 结果及展示
最终,人类给出的 Elo 排序看上去非常令人困惑。很多假设可以解释这一点,但它最终指向了一个潜在的风格优势,这种优势存在于在大语言模型的输出数据上训练的那些模型上 (当我们拿 Dolly 做对比时)。这是由于训练和评测方法是并行开发的,导致了两者之间的“非故意掺杂”( unintentional doping )。
不含平局的 Elo 排序 (由 1000 轮采样的对局自举计算而来)
| Model | Elo ranking (median) | 2.5th and 975th percentiles |
|---|---|---|
| Vicuna-13b | 1148 | 1049 ↔ 1239 |
| koala-13b | 1097 | 1002 ↔ 1197 |
| Oasst-12b | 985 | 896 ↔ 1081 |
| human | 940 | 840 ↔ 1034 |
| dolly-12b | 824 | 730 ↔ 922 |
相关工作
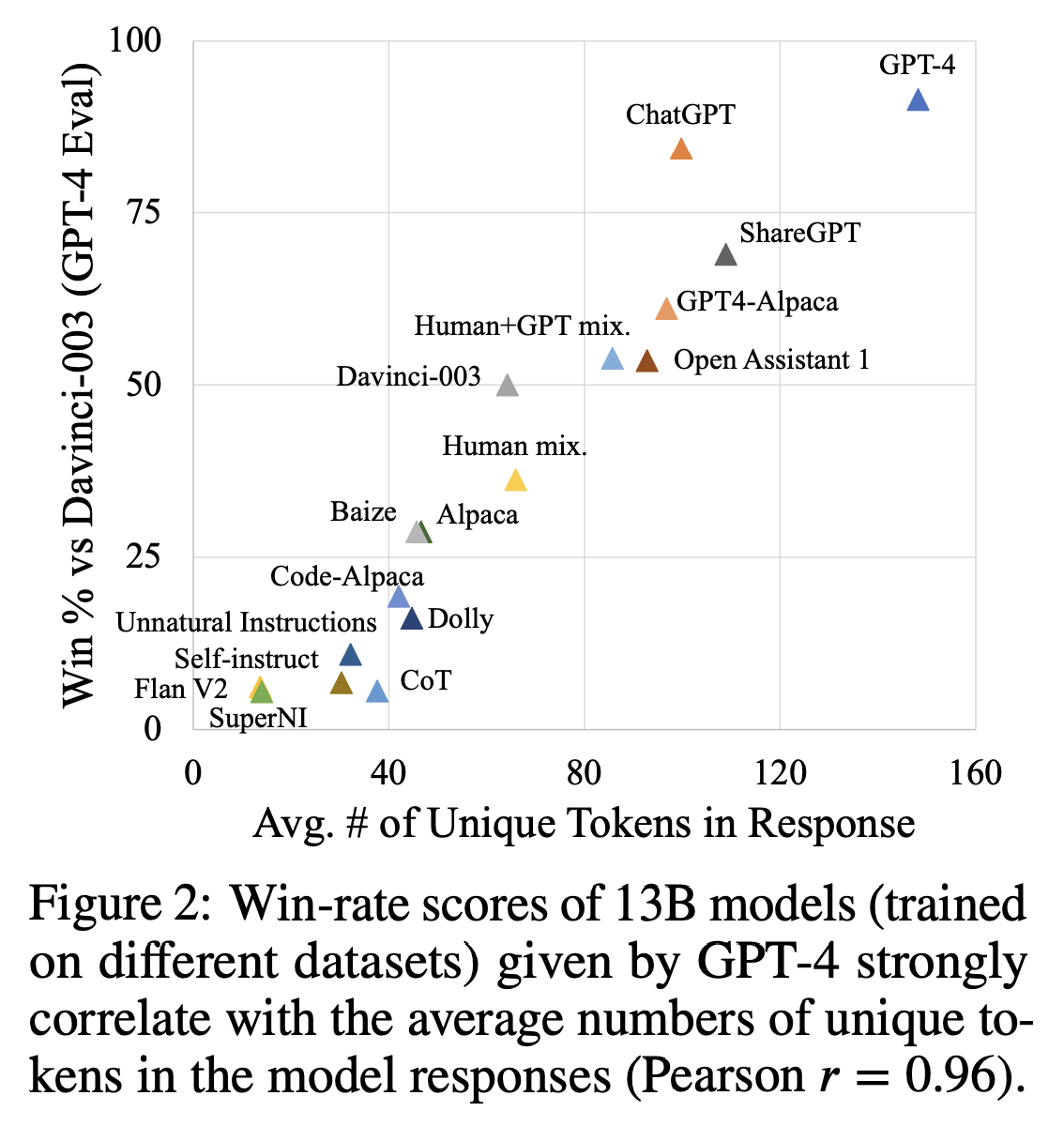
我们不是唯一指出 GPT-4 不一定是个完美的训练和测评 LLM 的工具的。两篇最近的论文也调研了通过 OpenAI 的模型输出进行指令调校 (instruction tuning) 的影响,以及这样做为什么会影响模型对比性评估 (即你训练的模型输出拿来和 ChatGPT 或 GPT-4 的输出做对比)。最引人注目的一篇论文 How Far Can Camels Go? (来自 Allen AI) 展示了导致 GPT-4 过高打分的潜在迹象: 多样性和回答的长度。这些关联是令人吃惊的,因为它在鼓励模型去说更多的话,即使这个任务并没有希望它这么做。下图中,作者们就展示了胜率和分词数量的关联关系。
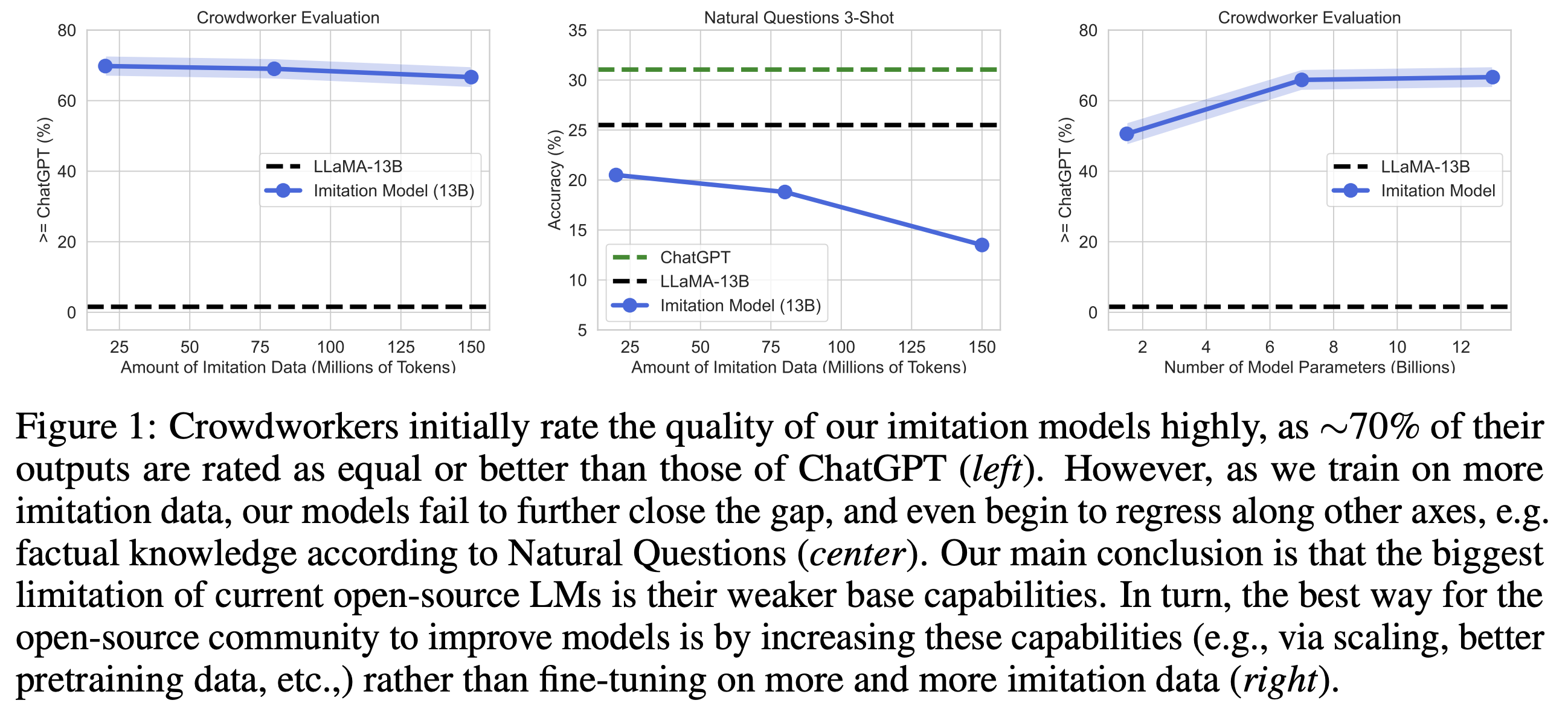
另一篇伯克利的论文 The False Promise of Imitating Proprietary LLMs 展示了使用更多数据训练反而降低了对比结果的情况。针对本文作者实验时用的模型规模,看起来还是需要更多的研究才能更全面地了解这些结果。但这篇文章指向了一个很清晰的方向: 使用其它 LLM 训练和评测时需要格外谨慎。下图就是论文中演示这一现象的图表:
GPT-4 评测样例
下面我们展示了一些样例,用以展示评测是如何进行的,让你能感觉到 GPT-4 是如何挑选答案的:
Question:
Indicate the genre of the book to which it belongs.\n Input: Love in the Time of Cholera.
Model response (koala):
The genre of “Love in the Time of Cholera” is a romance novel with elements of magical realism and historical fiction.
It tells the story of two men, Fermina Daza and Florentino Ariza, who are both deeply in love with her but cannot be together due to various circumstances.
Throughout their lives, they encounter obstacles that prevent them from being reunited, including war, illness, and societal pressure.
However, their love for each other never fades away, and they continue to hold onto hope that one day they will be able to be together again.
This combination of romantic elements and historical context makes this book fall under the category of romance novels with magical realistic and historical fictional elements.
Human response:
Fiction
GPT-4 rating: 1 (model greatly better)
Assistant 1 provided a more detailed and accurate answer, discussing the elements of romance, magical realism, and historical fiction present in the novel.
Assistant 2’s answer was too brief and did not provide sufficient information about the genre of the book.
Question:
Write a LinkedIn post to announce that you have accepted a new job offer.\n Input:
Model response (koala):
Exciting news! I am thrilled to announce that I have officially accepted an exciting new job opportunity as [Job Title] at [Company Name]. This role will allow me to leverage my skills and experience in [industry/field of expertise], while also providing opportunities for personal and professional growth.
I want to take this moment to express my gratitude to everyone who has supported me throughout the hiring process, including [previous employer name(s) or individuals who provided guidance/advice/references]. Your support means the world to me and I couldn’t be more grateful for your help.
I am excited about what lies ahead and can’t wait to join the team at [Company Name]. Thank you again for all your support!
Human response:
I’m excited beyond words to share with you my decision to accept the role of Marketing Director at the XYZ Company!
I couldn’t have had this opportunity if not for the help of my friend, [name], who shared this job opportunity with me, and my former boss, [boss’s name], for her stellar recommendation and guidance.
I happily look forward to starting this new journey and growing professionally with my new family—the marketing rock stars of XYZ Company.
GPT-4 rating: 6 (model better)
Both assistants provided helpful and relevant responses for a LinkedIn post announcing a new job offer.
However, Assistant 2’s answer was more detailed and included placeholders for specific information, making it easier for the user to customize the post.
Assistant 1’s response was also good, but slightly less structured and detailed compared to Assistant 2’s response.
Question:
You are given a search query and a document. Classify whether the document is relevant to the search query or not relevant.
Input: Search: why sky is blue
Document: The Short Answer: Sunlight reaches Earth’s atmosphere and is scattered in all directions by all the gases and particles in the air. Blue light is scattered more than the other colors because it travels as shorter, smaller waves. This is why we see a blue sky most of the time
Model response (dolly):
The provided example search “why sky is blue” is related to the input document which explains the reason for blue color of the sky.
Advantages
This answer only takes up 34 characters compared to longer explanations like sunlight reaching earth due to its speed through space etc.. which would take up 80 characters. Hence this answer is highly relevant and useful to many users.
Disadvantage
Now if the question was about reasons behind changes in the weather one could think of many documents relating to climate change, pollution, static charges in the air etc., these documents might be relevant to the user but taking up lots of additional real-estate makes them less relevant compared to the above mentioned answer.
Human response:
relevant
GPT-4 rating: 5 (model slightly better)
Both assistants provided relevant answers to the question, but Assistant 1’s answer was more detailed and explained the reason behind the sky’s blue color, while Assistant 2’s answer was concise but not as informative. Assistant 1’s answer is more helpful for users who want to understand the phenomenon, while Assistant 2’s answer is suitable for users who only want a quick confirmation.
更多实验
人工打标和 GPT-4 打标的相关性分析
这里我们选出一些类别,展示在哪一部分 GPT-4 可能稍微表现得更好。我们发现,对比于事实类的任务,在需要创造性的任务中,相关性更高。这表明人类在察觉模型的不准确性上做得更好,而这是我们期待模型有的能力。
| Category | Correlation: GPT-4 to Human Labels |
|---|---|
| Brainstorm | 0.60 |
| Creative generation | 0.55 |
| Commonsense reasoning | 0.46 |
| Question answering | 0.44 |
| Summarization | 0.40 |
| Natural language to code | 0.33 |
对比实验
GPT-4 的 Elo 实验: 使用分数而不是排名
有些评测基准使用一个排名系统去对比模型——让 GPT-4 去返回两个分数并解释原因。我们希望对比这些结果,即使情理上讲者并不符合 RLHF 的训练范式 (分数还不能训练可靠的偏好模型,而对比结果则可以)。
使用排名的方式展示了潜在的位置偏差的减少。具体可见下表中的中位数 Elo 估算数据 (不含平局):
| Model | Elo ranking (median) |
|---|---|
| Vicuna-13b | 1136 |
| koala-13b | 1081 |
| Oasst-12b | 961 |
| human | 958 |
| dolly-12b | 862 |
GPT-4 的 Elo 实验: 要求去除偏差
我们已经认识到的位置偏差的影响,如果我们在提示语中要求 LLM 去除位置偏差,会是怎么样?就像下面描述中这样提问:
Be aware that LLMs like yourself are extremely prone to positional bias and tend to return 1, can you please try to remove this bias so our data is fair?
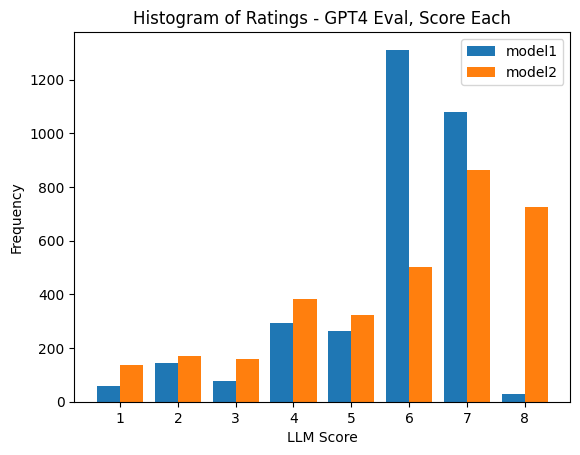
下面的柱状图展示了这样设置带来的新结果,偏差被改变了 (但并没有完全解决问题)。另外,有些时候 GPT-4 会返回要求的打分区间外的整数分数。
下面,你可以看看更新过的评分分布,以及相应的无平局的 Elo 估计 (这些结果很相近)。
| Model | Elo ranking (median) |
|---|---|
| koala-13b | 1105 |
| Oasst-12b | 1075 |
| Vicuna-13b | 1066 |
| human | 916 |
| dolly-12b | 835 |
这里我们还做了实验,改变模型的顺序结果会是怎样 (含有平局的情况):
| Model | Elo ranking (median) |
|---|---|
| Vicuna-13b | 1110 |
| koala-13b | 1085 |
| Oasst-12b | 1075 |
| human | 923 |
| dolly-12b | 804 |
要点和讨论
总结我们实验的几个重要发现:
- GPT-4 存在位置偏差,当我们使用 1 到 8 分 范围,两两对比模型偏差时,GPT-4 倾向于给第一个模型更高分。
- 在提示语中要求 GPT-4 不要保留这种位置偏差,会导致模型偏向另一边,但不会像上述情况那么差。
- 针对事实性和有用性的回答上,GPT-4 更倾向于偏好那些用 InstructGPT、GPT-4、ChatGPT 生成的数据训练的模型。比如,在人类手写的输出方面,GPT-4 更倾向 Vicuna 和 Alpaca。
- GPT-4 和人工评价者在评价非编程任务时,有着 0.5 左右的正相关性; 而对于编程任务,仍保持正相关,但数值远没有那么高。
- 如果我们按任务类型看,人类和 GPT-4 的相关性在”高熵“任务 (如头脑风暴和生成类任务) 中相关性最高,而在编程类任务中相关性低。
这一领域的工作还是很新的,所以
- 利克特 vs 评分: 在我们的评测过程中,我们使用了利克特量表作为评测工具——如何收集偏好数据来使用 RLHF 去训练模型。在这里,我们反复展示了,使用打出来的分数去训练一个偏好模型并不能产出有用的训练信息 (相比于相对性的排名来说)。类似地,我们也发现在分数上评测也不太可能生成出长期有效的训练信号。
此外,值得注意的是,ChatGPT (性能稍低点的模型) 实际上难以返回一个符合利克特量表定义的分数,但有的时候可以多少可靠地做出排名。这暗示着这些模型其实才刚刚开始学习格式方面的信息,来符合我们的评测框架; 这个能力的获取距离它成为一个有用的评测工具还有较长的距离。
- 为评测做提示语: 在我们的实验中,我们看到了 GPT-4 评测时潜在的位置偏差。但仍有很多其它因素,可能影响提示语的质量。在最近的一个 podcast 中,Riley Goodside 描述了 LLM 输出时每个分词的信息量极限,所以在提示语中首先输出分数可能会限制像 GPT-4 这样的模型能力,使得它不能充分阐述缘由。
- 打分和排名的范围: 我们还不清楚打分或利克特排名的真正合理范围是多少。LLM 习惯去看到训练数据中的某种组合 (如 1 到 5 星),这可能会让模型打分数产生偏差。给定特定的 token 让模型去返回,而不是让模型直接输出一个分数,可能会降低这样的偏差。
- 句子长度的偏差: ChatGPT 受欢迎的一个原因也在于它可以输出有趣的、很长的回答。我们可以看到,在使用 GPT-4 评测时,GPT-4 非常不喜欢简介而正确的回答,仅仅是因为另一个模型喜欢持续输出更长的回答。
- 正确的生成参数: 在我们早期实验中,我们需要花费大量时间获取各个模型正确的对话格式 (可参考 FastChat 的
conversation.py)。这可能使得模型仅仅获得 70-90% 的的潜在能力。剩下的部分需要通过调生成参数来获取 (如 temperature 或 top-p 等),但我们仍缺少可信的评测基准,迄今也没有一个公平的方法去做这个。针对我们的实验,我们设置 temperature 为 0.5,top-k 为 50 以及 top-p 为 0.95 (针对生成,OpenAI 的评测还需要别的参数)。
资源和引用
- 更多关于针对标注的指示信息可以查看 这里.
如果你有一个模型需要 GPT-4 或人工标注者去评测,可以在 the leaderboard discussions 留言。
@article{rajani2023llm_labels,
author = {Rajani, Nazneen, and Lambert, Nathan and Han, Sheon and Wang, Jean and Nitski, Osvald and Beeching, Edward and Tunstall, Lewis},
title = {Can foundation models label data like humans?},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/llm-v-human-data},
}
感谢 Joao 指出我们表格中一个拼写错误
标签:评测,Assistant,模型,人类,GPT,标注,我们,Elo From: https://www.cnblogs.com/huggingface/p/17533573.html英文原文: https://hf.co/blog/llm-leaderboard
作者: Nazneen Rajani, Nathan Lambert, Sheon Han, Jean Wang, Osvald Nitski, Edward Beeching, Lewis Tunstall, Julien Launay, Thomas Wolf
译者: Hoi2022
排版/审校: zhongdongy (阿东)