1. 什么是驾车ETA
临近节假,长途自驾返乡的你是否曾为无法预知路上到底有多堵而纠结?通勤上班,作为有车一族的你是否在为路况变幻莫测的早晚高峰而烦恼?外出旅行,赶火车、赶飞机的你是否还在为担心错过班次而焦虑?不要慌,高德的驾车ETA帮你预知未来路况,让每个用户轻松成为“时间管理大师”!
**ETA(Estimated Time of Arrival),即预估到达时间,指的是用户在当前时刻出发按照给定路线前往目的地预计需要的时长。**如图1展示了驾车ETA在导航软件的前端页面上呈现的形态,用户在使用过程中会主要参考这一数据安排行程时间、进行出行相关决策;对于打车的场景,平台呈现给用户的预估价也基于这一数据进行计算。因此,如何准确地预估ETA对于高德地图的诸多业务板块都起到至关重要的作用。
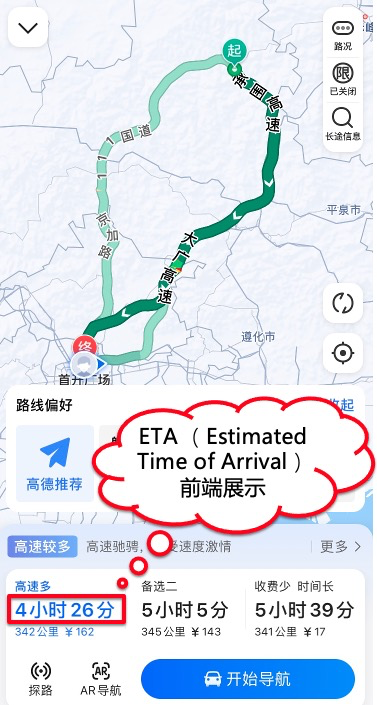
图1 ETA在高德地图上的前端展示
为方便后文表述,这里先简单介绍一下ETA相关的技术概念:
link:路段,是分叉口之间基本的道路组成单元。
trace:轨迹,对应的是一个由一连串link组成的序列。
SP(Speed Profile):同一特征日相同时间区间的历史平均速度,按10min聚合。例如每周一早上9:00-9:10,某个link上所有轨迹,可以将过去几周聚合求一个平均速度,这个平均速度可以代表对这个link在未来周一早上9:00-9:10这个时间区间内通行速度的静态预测。
AutoLR(Autonavi Location Reference):实时路况,道路当前通行耗时,每分钟都会发布新的值。
link通行耗时真值:在一个5min的时间窗口内进入某一link的所有轨迹,在完成去噪后求取平均值,即得到该link在该5min窗口内的通行耗时真值。
2. 业务板块
图2展示了ETA业务的各个板块。
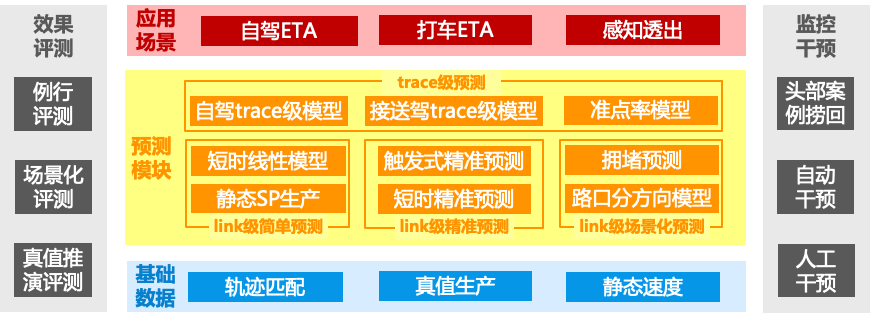
图2 ETA整体框架
基础数据层面,link场景分层根据历史实走真值将link归为不同类别。每类link预测的难度不同,例如有些link的通行时间每天鲜有拥堵,则可直接利用静态SP预测,因此调用的预测模块也不尽相同。真值生产及推演系统首先将各个link上5min窗口的实走轨迹聚合求平均通行时间,得到link通行耗时真值;同时利用真值推演工具可推算给定trace的通行耗时真值。link级、trace级的通行耗时真值是模型训练、模型评估、线上问题调查等一系列工作的数据基石。
预测模块层面,有三大预测模块可用于link级预测。
一是静态SP:该方法通过历史均值进行预测,不利用实时信息。
二是线性模型,该模块在ETA服务中被调用,通过实时信息AutoLR和历史信息SP来拟合link级真值。
三是精准预测,该模块作为算法服务提供link级预测结果,通过深度学习模型利用实时通行速度、流量等信息对较为复杂的突发路况进行预测。
预测功能层面,除link级预测外,ETA服务还提供trace级预测功能,对用户规划的整条路线进行ETA预测;以及准点率预测功能,对给定trace级预测结果的可信度做出判断。
应用场景层面,自驾、打车业务都需使用ETA,但两者样本分布以及重点关注的场景不尽相同。ETA的算法能力在前端页面还涉及到一些其他形式的透出,例如拥堵段预计通过耗时、拥堵未来趋势说明,以及准点率等等。
效果评测层面,涉及到自身link级、trace级基础指标评测,对真值推演结果的评测、各个场景的效果评估。监控干预层面,涉及到实时捞取头部问题case、对问题link的ETA进行自动干预、人工干预等。
3. ETA的预测流程
线上的ETA服务为其他服务提供ETA预测计算接口。精准预测模型部署在另外的算法服务中,该服务每分钟将link级多时间跨度预测值写入缓存,ETA服务按需查取相应值。对某个link进行预测时,有精准预测值的情况下将优先使用精准预测结果。ETA服务中的线性模型提供link级多时间跨度预测能力。在精准预测没有被触发的情况下,查看是否有实时路况以及待预测时刻与发起预测时刻时间差是否在1小时以内,满足上述条件则使用线性模型预测的结果。SP数据加载在ETA服务内存中,由于是静态历史均值,预测时间跨度可达未来一周。link级预测中,最低优先级的是利用SP进行静态预测。
link级预测结果可按照上述方案获取,那么整条路线的ETA要如何计算呢?这里就要用到link序列ETA推演的功能。假如用户规划的路线如图3所示,则在进行预测时,link1应选取对应距离当前[0min, 5min)时间跨度的通行时间预测值,例如该预测值为11min;则用户预计进入link2的时刻为11min之后,在link2上的通行时间应该选取link2对应[10min, 15min)时间跨度的通行时间预测值……依此逻辑推演到最后一根link(若推演到的某根link累积时间已超出1h,则用SP作为预测值),从而得到对整条路线ETA的预测。
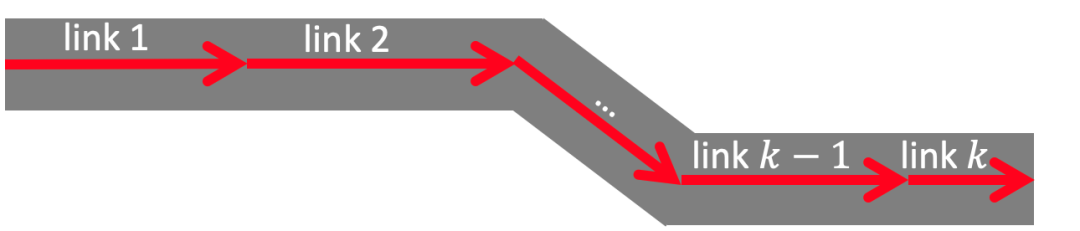
图3 link序列ETA推演
4. ETA预测的难点及解决方案
在一些出行量大且拥堵规律复杂多变的场景,准确预估ETA的挑战性极大。例如工作日的早晚高峰,路况非常复杂,而且学校寒暑假后的开学、以往疫情期的反复、一些特殊日期(例如七夕、圣诞等)出行需求的剧增,都会使得历史规律无法直接复用。
为了能让深度模型提前感知拥堵的到来,我们在预测中引入了“未来流量”。想象这样的场景:来自北京的用户A由于家到公司较远,每天早上6点就要开车途径北五环去公司。9月1日,他像往常一样早上6点开车出门。走到北五环,用户A发现今天格外堵。直到在北五环上堵得快要迟到,才突然醒悟,原来今天是开学第一天,早高峰车流量大幅增加,后悔自己没有出发前没早点打开高德看看ETA。
我们注意到,由于用户A出发很早,出发时刻全程路况仍非常畅通,此时各个link流量也基本和8月无区别。这样,想要让模型能预判未来会出现比往常严重很多的拥堵,就必须引入能在用户出发时刻就与8月相同时间有明显区分度的特征。用户A的例子中,在他刚刚出发时,北五环上车流很小,但已经有很多像他一样早起且需要走北五环的用户开着导航从家里出发了,这些人虽然还没有上五环,但只要他们不偏航且完全按照ETA预估的时间行进,那么未来任意时刻这些用户的位置我们都可以推算得到,这意味着我们可以统计“未来的交通流量”。也就是说,这些已经在导航中的用户,未来各个时间片上会在北五环的各个link上分别形成多大的交通流量,都可以统计到(注:这里统计到的流量是匿名的聚合总量)。如图4所示,我们把这个统计量称作“未来的交通流量”特征。上面的例子中,早上6点,有很多需要上北五环的用户已经出发了,因此此时五环上的link已经显著高于8月份。

图4 计划中的交通流量
模型层面,我们提出了一种新的用于通行时间预测的深度学习框架:混合时空图卷积网络(H-STGCN),该框架利用上述计划中交通流量提升模型效果。
在该模型中,我们设计了域转换器,以此整合异质模态的交通流量特征。同时,我们设计了复合邻接矩阵使得图卷积层能够更好地捕捉路段间的接近性。实验发现,在真实场景数据集上,H-STGCN和较先进的其他时空预测模型相比取得了显著更优的效果,在突发拥堵的预测上优势尤为明显。这项研究成果在为用户带来更优出行体验的同时,相应论文也被AI领域国际顶级会议KDD2020接收。
5. ETA的效果评估
对应link级预测与trace级预测,ETA效果的评估也有link级评测与trace级评测。
5.1. link级评测
trace计算参与的角色众多,涉及到方方面面(实时信息、历史统计信息、道路推演等)都会给trace级别的ETA带来影响,我们为了更好的衡量在单独link上ETA的计算质量,我们提出了link eta的评估方法。
bad link率
bad link率计算方法为,bad link批次总数同总link批次数的比值。bad link率越低,link级预测效果越好。bad link批次的定义如公式:
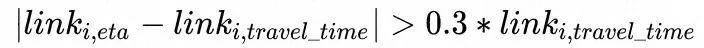
i表示批次id,满足这个条件即为bad link。
MSE
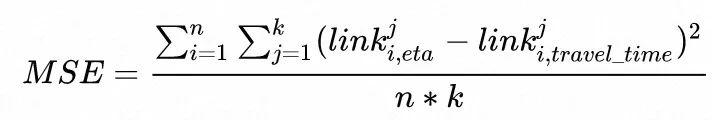
这里的n指的是link数量,k指的是评估批次数量。MSE越低,link级预测效果越好。
5.2. trace级评测
通过对比用户实走时长和ETA行前预测的结果,可以对用户全行程轨迹的ETA质量进行评估。使用trace级评测,可以监控trace的MSE、MAE、MAPE、优良率、恶劣率等指标。
6. 总结
本文对高德驾车ETA整体的业务板块进行了简要的介绍。
标签:真值,预测,trace,用户,ETA,link,高德,驾车 From: https://www.cnblogs.com/amap_tech/p/17533047.html