一、贫血模型
1.介绍
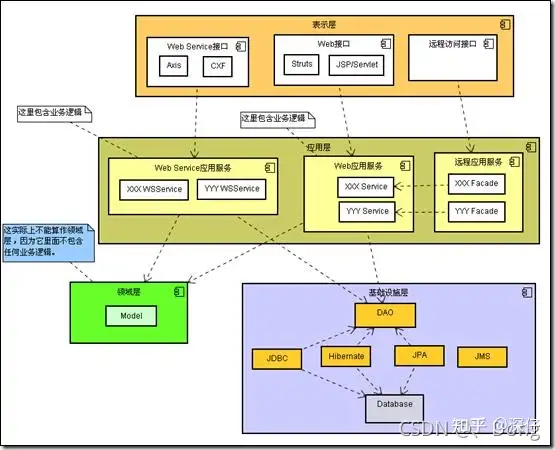
贫血模型是指领域对象里只有get和set方法(POJO),所有的业务逻辑都不包含在内而是放在Business Logic层。
2.优点
各层单向依赖,结构清楚,易于实现和维护。
设计简单易行,底层模型非常稳定。
3.缺点
domain object的部分比较紧密依赖的持久化domain logic被分离到Service层,显得不够OOP(面向对象)。
Service层过于厚重。
4.代码样例
我们一般使用三层架构进行业务开发:
Repository + Entity
Service + BO(Business Object)
Controller + VO(View Object)
在三层架构业务开发中,大家经常使用基于贫血模型的开发模式。贫血模型是指业务逻辑全部放在service层,业务对象只包含数据不包含业务逻辑。我们来看代码实例。
/**
* 账户业务对象
*/
public class AccountBO {
/**
* 账户ID
*/
private String accountId;
/**
* 账户余额
*/
private Long balance;
/**
* 是否冻结
*/
private boolean isFrozen;
public String getAccountId() {
return accountId;
}
public void setAccountId(String accountId) {
this.accountId = accountId;
}
public Long getBalance() {
return balance;
}
public void setBalance(Long balance) {
this.balance = balance;
}
public boolean isFrozen() {
return isFrozen;
}
public void setFrozen(boolean isFrozen) {
this.isFrozen = isFrozen;
}
}
/**
* 转账业务服务实现
*/
@Service
public class TransferServiceImpl implements TransferService {
@Autowired
private AccountService accountService;
@Override
public boolean transfer(String fromAccountId, String toAccountId, Long amount) {
AccountBO fromAccount = accountService.getAccountById(fromAccountId);
AccountBO toAccount = accountService.getAccountById(toAccountId);
/** 检查转出账户 **/
if (fromAccount.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
if (fromAccount.getBalance() < amount) {
throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE);
}
fromAccount.setBalance(fromAccount.getBalance() - amount);
/** 检查转入账户 **/
if (toAccount.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
toAccount.setBalance(toAccount.getBalance() + amount);
/** 更新数据库 **/
accountService.updateAccount(fromAccount);
accountService.updateAccount(toAccount);
return Boolean.TRUE;
}
}
二、充血模型
1.介绍
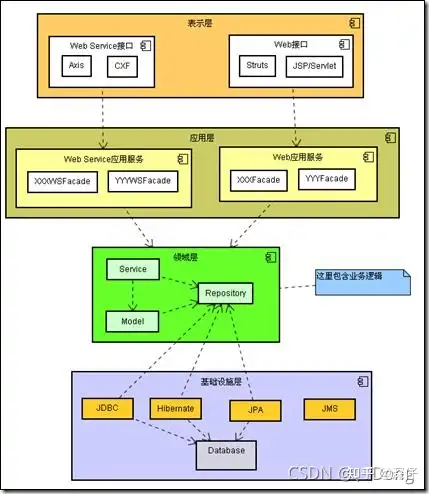
充血模型是指数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格。
2.优点
面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重
3.缺点
缺点是如何划分业务逻辑,什么样的逻辑应该放在Domain Object中,什么样的业务逻辑应该放在Business Logic中,这是很含糊的。
那么切分的原则是什么呢:Rod Johnson提出原则是“case by case”,可重用度高的,和domain object状态密切关联的放在Domain Object中,可重用度低的,和domain object状态没有密切关联的放在Business Logic中。
经过上面的讨论,如何区分domain logic和business logic,我想提出一个改进的区分原则:domain logic只应该和这一个domain object的实例状态有关,而不应该和一批domain object的状态有关。
当你把一个logic放到domain object中以后,这个domain object应该仍然独立于持久层框架之外(Hibernate, JDO),这个domain object仍然可以脱离持久层框架进行单元测试,这个domain object仍然是一个完备的,自包含的,不依赖于外部环境的领域对象,这种情况下,这个logic才是domain logic。
4.代码样例
在基于充血模型DDD开发模式中我们引入了Domain层。Domain层包含了业务对象BO,但并不是仅仅包含数据,这一层也包含业务逻辑,我们来看代码实例。
/**
* 账户业务对象
*/
public class AccountBO {
/**
* 账户ID
*/
private String accountId;
/**
* 账户余额
*/
private Long balance;
/**
* 是否冻结
*/
private boolean isFrozen;
/**
* 出借策略
*/
private DebitPolicy debitPolicy;
/**
* 入账策略
*/
private CreditPolicy creditPolicy;
/**
* 出借方法
*
* @param amount 金额
*/
public void debit(Long amount) {
debitPolicy.preDebit(this, amount);
this.balance -= amount;
debitPolicy.afterDebit(this, amount);
}
/**
* 转入方法
*
* @param amount 金额
*/
public void credit(Long amount) {
creditPolicy.preCredit(this, amount);
this.balance += amount;
creditPolicy.afterCredit(this, amount);
}
public boolean isFrozen() {
return isFrozen;
}
public void setFrozen(boolean isFrozen) {
this.isFrozen = isFrozen;
}
public String getAccountId() {
return accountId;
}
public void setAccountId(String accountId) {
this.accountId = accountId;
}
public Long getBalance() {
return balance;
}
/**
* BO和DO转换必须加set方法这是一种权衡
*/
public void setBalance(Long balance) {
this.balance = balance;
}
public DebitPolicy getDebitPolicy() {
return debitPolicy;
}
public void setDebitPolicy(DebitPolicy debitPolicy) {
this.debitPolicy = debitPolicy;
}
public CreditPolicy getCreditPolicy() {
return creditPolicy;
}
public void setCreditPolicy(CreditPolicy creditPolicy) {
this.creditPolicy = creditPolicy;
}
}
/**
* 入账策略实现
*/
@Service
public class CreditPolicyImpl implements CreditPolicy {
@Override
public void preCredit(AccountBO account, Long amount) {
if (account.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
}
@Override
public void afterCredit(AccountBO account, Long amount) {
System.out.println("afterCredit");
}
}
/**
* 出借策略实现
*/
@Service
public class DebitPolicyImpl implements DebitPolicy {
@Override
public void preDebit(AccountBO account, Long amount) {
if (account.isFrozen()) {
throw new MyBizException(ErrorCodeBiz.ACCOUNT_FROZEN);
}
if (account.getBalance() < amount) {
throw new MyBizException(ErrorCodeBiz.INSUFFICIENT_BALANCE);
}
}
@Override
public void afterDebit(AccountBO account, Long amount) {
System.out.println("afterDebit");
}
}
/**
* 转账业务服务实现
*/
@Service
public class TransferServiceImpl implements TransferService {
@Resource
private AccountService accountService;
@Resource
private CreditPolicy creditPolicy;
@Resource
private DebitPolicy debitPolicy;
@Override
public boolean transfer(String fromAccountId, String toAccountId, Long amount) {
AccountBO fromAccount = accountService.getAccountById(fromAccountId);
AccountBO toAccount = accountService.getAccountById(toAccountId);
fromAccount.setDebitPolicy(debitPolicy);
toAccount.setCreditPolicy(creditPolicy);
fromAccount.debit(amount);
toAccount.credit(amount);
accountService.updateAccount(fromAccount);
accountService.updateAccount(toAccount);
return Boolean.TRUE;
}
}
三、对比分析
1.为什么基于贫血模型的传统开发模式如此受欢迎?
基于贫血模型的传统开发模式,将数据与业务逻辑分离,违反了 OOP 的封装特性,实际上是一种面向过程的编程风格。但是,现在几乎所有的 Web 项目,都是基于这种贫血模型的开发模式,甚至连 Java Spring 框架的官方 demo,都是按照这种开发模式来编写的。
面向过程编程风格有种种弊端,比如,数据和操作分离之后,数据本身的操作就不受限制了。任何代码都可以随意修改数据。既然基于贫血模型的这种传统开发模式是面向过程编程风格的,那它又为什么会被广大程序员所接受呢?关于这个问题,主要是有下面三点原因。
第一点原因是,大部分情况下,我们开发的系统业务可能都比较简单,简单到就是基于 SQL 的 CRUD 操作,所以,我们根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。除此之外,因为业务比较简单,即便我们使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义。
第二点原因是,充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。我们从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,我们只需要定义数据,之后有什么功能开发需求,我们就在 Service 层定义什么操作,不需要事先做太多设计。
第三点原因是,思维已固化,转型有成本。基于贫血模型的传统开发模式经历了这么多年,已经深得人心、习以为常。你随便问一个旁边的大龄同事,基本上他过往参与的所有 Web 项目应该都是基于这个开发模式的,而且也没有出过啥大问题。如果转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的。
2.什么项目应该考虑使用基于充血模型的 DDD 开发模式?
相对应的,基于充血模型的 DDD 开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统。
你可能会有一些疑问,这两种开发模式,落实到代码层面,区别不就是一个将业务逻辑放到 Service 类中,一个将业务逻辑放到 Domain 领域模型中吗?为什么基于贫血模型的传统开发模式,就不能应对复杂业务系统的开发?而基于充血模型的 DDD 开发模式就可以呢?
实际上,除了我们能看到的代码层面的区别之外(一个业务逻辑放到 Service 层,一个放到领域模型中),还有一个非常重要的区别,那就是两种不同的开发模式会导致不同的开发流程。基于充血模型的 DDD 开发模式的开发流程,在应对复杂业务系统的开发的时候更加有优势。为什么这么说呢?我们先来回忆一下,我们平时基于贫血模型的传统的开发模式,都是怎么实现一个功能需求的。
不夸张地讲,我们平时的开发,大部分都是 SQL 驱动(SQL-Driven)的开发模式。我们接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写 SQL 语句来获取数据。之后就是定义 Entity、BO、VO,然后模板式地往对应的 Repository、Service、Controller 类中添加代码。
业务逻辑包裹在一个大的 SQL 语句中,而 Service 层可以做的事情很少。SQL 都是针对特定的业务功能编写的,复用性差。当我要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞。
所以,在这个过程中,很少有人会应用领域模型、OOP 的概念,也很少有代码复用意识。对于简单业务系统来说,这种开发方式问题不大。但对于复杂业务系统的开发来说,这样的开发方式会让代码越来越混乱,最终导致无法维护。
如果我们在项目中,应用基于充血模型的 DDD 的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,我们需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成,使用模板方法模式。
标签:贫血,模型,充血,isFrozen,业务,amount,开发,public From: https://www.cnblogs.com/nyhhd/p/17526063.html