
Zookeeper 是一个分布式的协调服务,可以用来管理共享数据、配置信息、命名服务(如 DNS)和分布式锁等。
Zookeeper 的特点是具有高可用、一致性和可靠性,因此也被广泛应用于分布式系统中。
主要组成
Zookeeper的主要组成包括:
-
Leader:Zookeeper集群中的一个节点被选举为Leader,负责协调和处理所有的写请求。
-
Follower:Zookeeper集群中的其他节点被选举为Follower,负责接收客户端请求并将请求转发给Leader节点处理。
-
Observer:Observer节点是Follower节点的一种特殊形式,它不参与集群的投票和Leader选举过程,只接收客户端的读请求,并将请求转发给Leader节点处理。
-
Client:Zookeeper的客户端,可以是任何使用Zookeeper服务的应用程序。
-
Watcher:Zookeeper中的Watcher机制是一种事件监听机制,用于监控Zookeeper中节点的变化情况。当节点的状态发生变化时,Watcher会通知客户端。
服务注册与发现
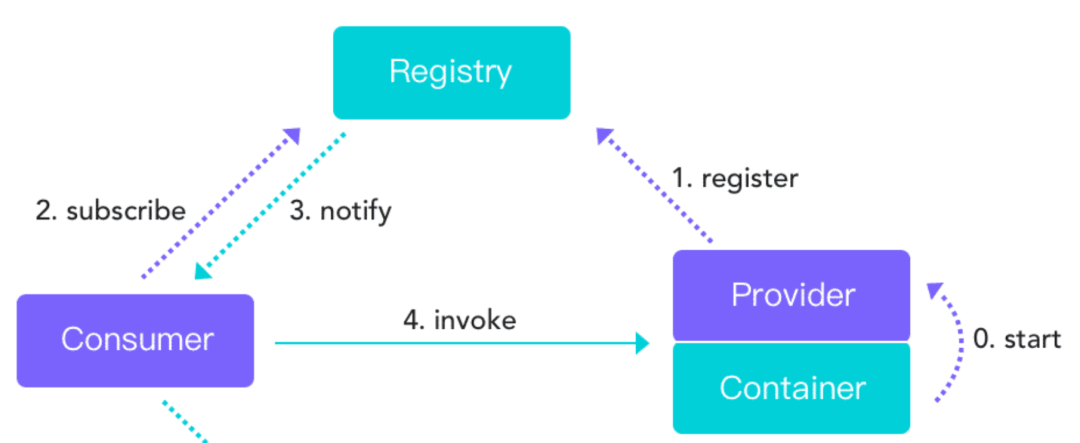
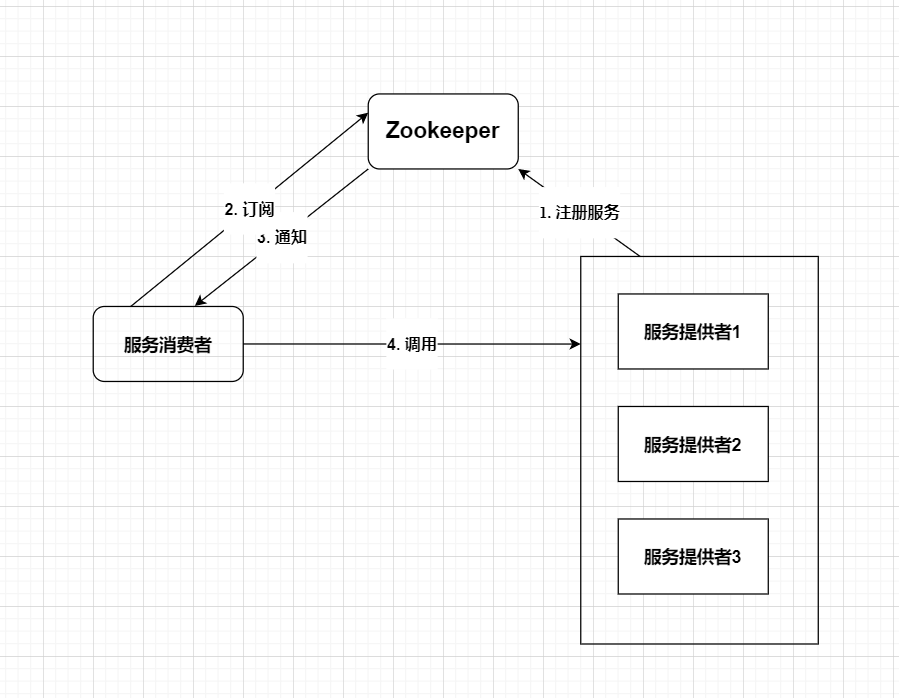
-
服务提供者启动时连接Zookeeper:服务提供者在启动时通过Zookeeper提供的API连接到Zookeeper集群。
-
创建服务节点:服务提供者在Zookeeper上创建一个临时节点,节点的路径通常是一个固定的根路径下加上服务名称和版本号等信息。
-
将服务信息写入节点:服务提供者将自己的服务信息写入节点中,例如IP地址、端口号、协议等信息。
-
服务消费者获取服务列表:服务消费者通过Zookeeper提供的API监听服务节点的变化,获取服务列表。
-
服务消费者调用服务:服务消费者根据获取到的服务列表,调用对应的服务提供者。
-
服务提供者下线:当服务提供者下线时,它创建的临时节点会被删除,Zookeeper会通知服务消费者节点的变化。
总的来说,服务注册流程是一个基于Zookeeper的分布式的服务注册与发现的过程。服务提供者将自己的服务信息写入Zookeeper节点中,服务消费者通过监听节点的变化来获取服务列表,从而实现了服务的注册与发现。
运行流程
-
启动Zookeeper集群:启动Zookeeper集群中的每个节点,节点之间会进行通信,选举出Leader节点。
-
客户端连接:客户端通过Zookeeper提供的API连接到Zookeeper集群。
-
数据操作:客户端可以向Zookeeper集群中写入数据、读取数据或者监听节点的变化等操作。
-
数据同步:Zookeeper集群中的每个节点都会同步数据,当有节点写入数据时,Leader节点会将数据同步到所有Follower节点上。
-
选举Leader:当Leader节点失效时,Zookeeper会进行Leader选举,选举出新的Leader节点。
-
Watcher机制:客户端可以注册Watcher机制,当节点的状态发生变化时,Zookeeper会通知客户端。客户端可以根据Watcher机制的通知来做出相应的处理。
-
关闭连接:客户端可以通过Zookeeper提供的API关闭与Zookeeper集群的连接。
总的来说,Zookeeper的运行流程是一个分布式的协作过程,它通过选举Leader、同步数据、监听节点变化等机制,实现了分布式应用程序的协调与管理。
选举
Zookeeper的正常运行时强依赖于Leader的存在的,所以想要正常运行必须要先选举出Leader角色。
选举的过程是基于Zookeeper节点名称的字典序排序,而不是节点的性能或处理能力。
选举基于Zookeeper的Zab协议的广播版本,该协议保证了全局数据的一致性,主要是通过扩展Paxos协议来实现的。当一个Leader不可用时,剩余的节点立即开始选举新的Leader。
这里要引入一个新的名词Candidate(候选者)节点,关于参与选举Zookeeper中的Leader(领导者)角色网上有不同的说法:
-
参与选举的节点是Follower(跟随者)节点
-
Follower(跟随者)和Candidate(候选者)节点 参与选举Leader
二者的区别我们后文会做说明,此处只需要记住这两种说法都不错。
选举机制
节点名称在Zookeeper中是唯一的,如果多个节点拥有相同的名称,则会发生错误,因此节点名称的选择是非常重要的。可以通过有意义的命名规则来确保节点名称的唯一性,以避免命名相同或类似的节点。
不过,当在同一节点上部署多个Zookeeper服务器实例时,每个实例必须有一个独特标识符,例如端口号或服务器编号,以确保它们的名称不同,从而避免冲突。
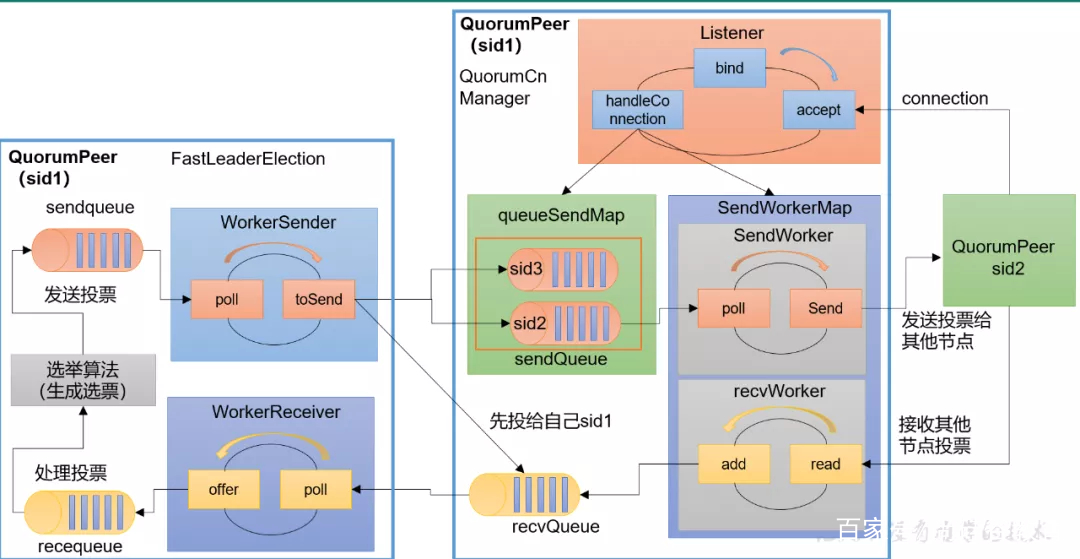
选举流程如下:
启动选举
-
每个节点创建一个临时节点(EPHEMERAL),如果创建成功,则表示该节点已经存活。
-
每个节点获取所有服务节点,并将其放入一个数组中,然后按照节点名称的字母顺序排序,选择第一个节点为Leader。
-
如果当前节点成为Leader,则使用标记(例如,在标记中写入“Leader”)来标识这个节点是Leader,并设置watcher。
-
如果发生故障,被选举节点将会失去zooKeeper服务器的心跳,我们知道,zookeeper最初的心跳间隔是2s(在初始化代码中) ,这意味着在Leader崩溃后,需要5个心跳周期才能确保Leader已经非活动状态。
Leader节点挂掉重新选举
这时,所有的非Leader节点将参与新的选举。
-
在新一轮的选举中,只有等待心跳超过5个tick的节点才参与投票。如果一次投票中没有选出新的Leader,则等待一个tick,并随机等待一段时间,然后重新开始新的选举。
-
在新选出Leader的节点回复(更新)客户端之前,客户端将不能读取任何数据,原因是,Zookeeper在处理写请求时,Leader节点会在整个集群之间进行同步,直到大多数Follower节点可以复制我们的写操作,读操作总是从Follower节点中发生,直到客户端读到Leader节点才会通知。
观察者作用
Zookeeper中,观察者(watcher)是一种机制,用于实现数据变更的通知和事件驱动。
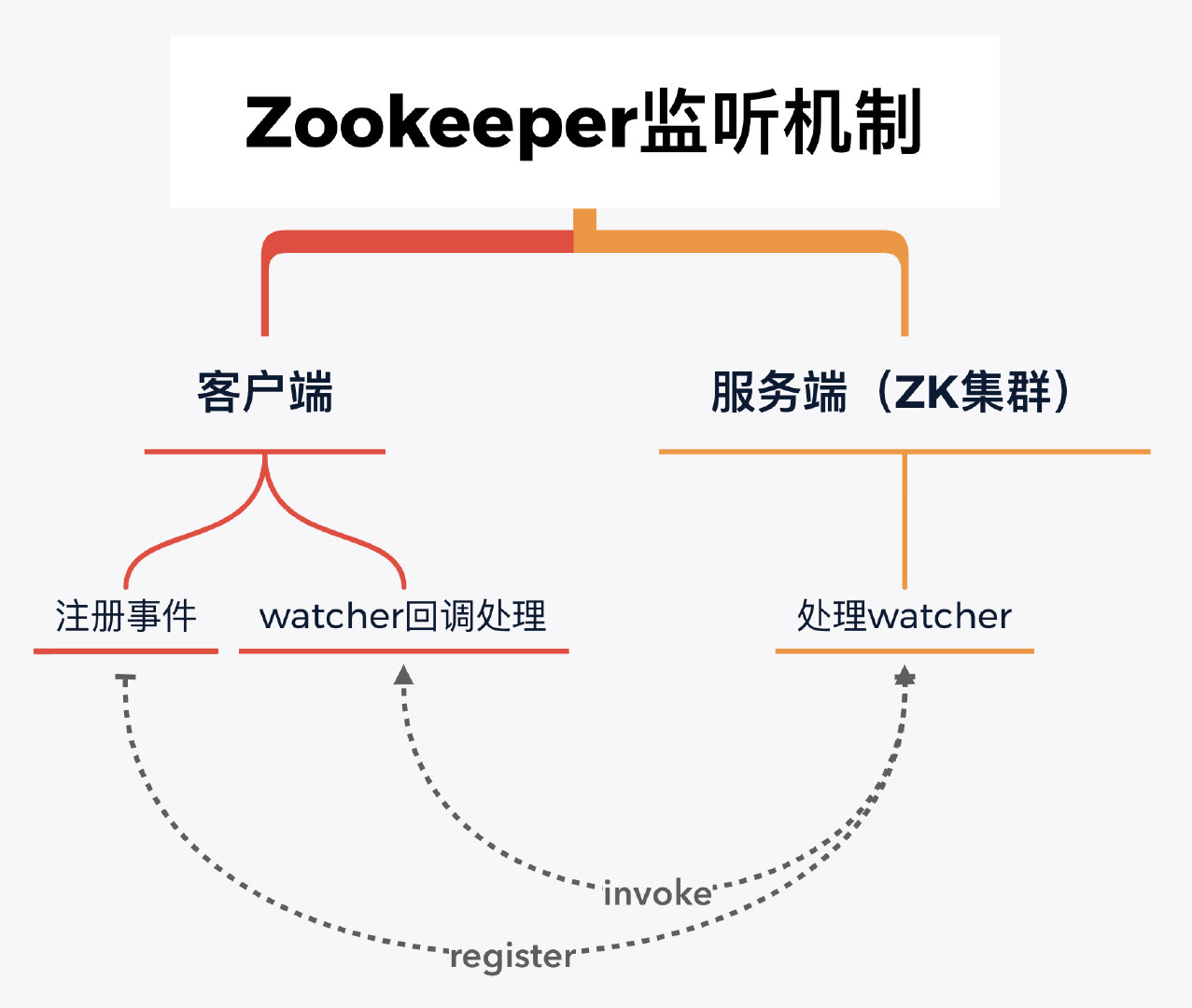
观察者本质上只是客户端,所以它不会在集群中发挥管理角色,也不会影响到Leader的选举过程。
当Zookeeper中某个节点的数据发生变化时,Zookeeper会触发该节点上的所有客户端注册的watchers,并将通知发送给这些客户端,这样客户端就能及时感知数据变化,从而进行相应的处理。
观察者的作用主要有以下几个方面:
-
实现数据的实时监控:Zookeeper的客户端可以在指定节点上注册watcher,一旦该节点的数据发生变化,Zookeeper就会触发watcher,并将通知发送给客户端进行相应的处理,从而实现数据的实时监控。
-
提高Zookeeper的性能:观察者机制可以有效减少客户端的轮询次数,减少网络开销,提高Zookeeper的性能和吞吐量。
-
实现事件驱动:Zookeeper的观察者机制可以将数据变更事件作为触发器,实现事件驱动的编程模型,更加方便程序员进行开发。
总之,观察者(watcher)是Zookeeper中重要的机制之一,通过该机制,可以实现数据变更的通知和事件驱动,提高系统的可用性和性能。
Follower(跟随者)和Candidate(候选者)节点区别
Candidate(候选者)节点是准备参与Leader选举的节点,它们会发起选举请求,并等待集群中的其他节点的确认,其本质上还是Follower(跟随者)节点,只不过两者的节点状态不一样。
Follower节点是Zookeeper集群中的一种常规节点状态,它的主要作用是接收Leader节点的数据更新,并将这些更新通知给其他节点。Follower节点可以参与Leader选举,但它不能直接成为Leader节点。在Zookeeper集群中,大多数节点都是Follower节点。
Candidate节点是Zookeeper集群中的一种特殊节点状态,它是指正在参与Leader选举的节点。在Zookeeper集群中,当一个节点想要成为Leader时,它会将自己的状态从Follower节点切换到Candidate节点,然后开始参与Leader选举。Candidate节点会向其他节点发送选举请求,收到半数以上节点的投票后,它就可以成为Leader节点。
总之,Follower节点是Zookeeper集群中的一种常规节点状态,而Candidate节点是一种特殊的状态,它是指正在参与Leader选举的节点。
Leader节点挂掉期间写操作是否会丢失
如果ZooKeeper的leader节点挂掉并且重新选举新的Leader节点时,尚未完成的写操作可能会丢失;这是因为,当Leader节点挂掉后,ZooKeeper会立即停止处理写操作,直到重新选举出新的Leader节点;在这个过程中,如果其他Follower节点已经复制了未同步的写操作,而这些Follower在重新选举新的Leader之前也因某些原因宕机了,那么这些未同步的写操作可能会因为Follower节点宕机而丢失。
为了避免数据丢失,一些应用程序也会使用ZooKeeper的事务支持来保证多个写操作的原子性。这可以通过在ZooKeeper的JavaScript客户端API中使用事务的方式来实现。
Zookeeper 的使用需要格外注意网络分区、容错处理等问题,但是只要合理地设计代码逻辑和容错机制,依然可以达到高可用、一致性和可靠性的目标。
标签:选举,Zookeeper,Leader,浅尝,Follower,节点,客户端 From: https://www.cnblogs.com/dc-s/p/17501834.html