
前言
上一篇文章我们介绍了pandas读写CSV文件的有关方法,本篇文章我们介绍pandas读取JSON文件的方法。pandas同样可以很方便地处理JSON文件。
获取更多免费资料,请点击!
关于json
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML,但是JSON 比 XML 更小、更快,更易解析。
数据准备
我们根据部分省份2022年的经济社会发展数据创建了一个名为data.json文件,文件内容如下:
[
{
"省份": "广东",
"人口": 12684,
"地区": "中南",
"GDP": 129118.58
},
{
"省份": "江苏",
"人口": 8505.4,
"地区": "华东",
"GDP": 122875.6
},
{
"省份": "山东",
"人口": 10169.99,
"地区": "华东",
"GDP": 87435
},
{
"省份": "浙江",
"人口": 6540,
"地区": "华东",
"GDP": 77715
},
{
"省份": "河南",
"人口": 9883,
"地区": "中南",
"GDP": 61345.05
},
{
"省份": "四川",
"人口": 8372,
"地区": "西南",
"GDP": 56749.8
},
{
"省份": "湖北",
"人口": 5844,
"地区": "中南",
"GDP": 53734.92
},
{
"省份": "福建",
"人口": 4188,
"地区": "华东",
"GDP": 53109.85
},
{
"省份": "湖南",
"人口": 6604,
"地区": "中南",
"GDP": 48670.37
},
{
"省份": "安徽",
"人口": 6127,
"地区": "华东",
"GDP": 45045
},
{
"省份": "上海",
"人口": 2489.43,
"地区": "华东",
"GDP": 44652.8
},
{
"省份": "河北",
"人口": 7420,
"地区": "华北",
"GDP": 42370.4
},
{
"省份": "北京",
"人口": 2188.6,
"地区": "华北",
"GDP": 41610.9
},
{
"省份": "陕西",
"人口": 3954,
"地区": "西北",
"GDP": 32772.68
},
{
"省份": "江西",
"人口": 4517.4,
"地区": "华东",
"GDP": 32074.7
}
]
pandas读取json文件
与读取csv文件类似,pandas提供了read_json()方法读取json文件内容,示例如下:
import pandas as pd
df = pd.read_json('data.json')
print(df.to_string())
----------------------------
输出结果如下:
省份 人口 地区 GDP
0 广东 12684.00 中南 129118.58
1 江苏 8505.40 华东 122875.60
2 山东 10169.99 华东 87435.00
3 浙江 6540.00 华东 77715.00
4 河南 9883.00 中南 61345.05
5 四川 8372.00 西南 56749.80
6 湖北 5844.00 中南 53734.92
7 福建 4188.00 华东 53109.85
8 湖南 6604.00 中南 48670.37
9 安徽 6127.00 华东 45045.00
10 上海 2489.43 华东 44652.80
11 河北 7420.00 华北 42370.40
12 北京 2188.60 华北 41610.90
13 陕西 3954.00 西北 32772.68
14 江西 4517.40 华东 32074.70
和读取csv文件相似,我们加上to_string()即可返回DataFrame。
除了处理json文件,同样也可以读取json字符串,示例如下:
import pandas as pd
data = [
{
"省份": "广东",
"人口": 12684,
"地区": "中南",
"GDP": 129118.58
},
{
"省份": "江苏",
"人口": 8505.4,
"地区": "华东",
"GDP": 122875.6
},
{
"省份": "山东",
"人口": 10169.99,
"地区": "华东",
"GDP": 87435
},
{
"省份": "浙江",
"人口": 6540,
"地区": "华东",
"GDP": 77715
},
{
"省份": "河南",
"人口": 9883,
"地区": "中南",
"GDP": 61345.05
},
{
"省份": "四川",
"人口": 8372,
"地区": "西南",
"GDP": 56749.8
},
{
"省份": "湖北",
"人口": 5844,
"地区": "中南",
"GDP": 53734.92
},
{
"省份": "福建",
"人口": 4188,
"地区": "华东",
"GDP": 53109.85
},
{
"省份": "湖南",
"人口": 6604,
"地区": "中南",
"GDP": 48670.37
},
{
"省份": "安徽",
"人口": 6127,
"地区": "华东",
"GDP": 45045
},
{
"省份": "上海",
"人口": 2489.43,
"地区": "华东",
"GDP": 44652.8
},
{
"省份": "河北",
"人口": 7420,
"地区": "华北",
"GDP": 42370.4
},
{
"省份": "北京",
"人口": 2188.6,
"地区": "华北",
"GDP": 41610.9
},
{
"省份": "陕西",
"人口": 3954,
"地区": "西北",
"GDP": 32772.68
},
{
"省份": "江西",
"人口": 4517.4,
"地区": "华东",
"GDP": 32074.7
}
]
df = pd.DataFrame(data)
print(df)
--------------------------
输出结果如下:
省份 人口 地区 GDP
0 广东 12684.00 中南 129118.58
1 江苏 8505.40 华东 122875.60
2 山东 10169.99 华东 87435.00
3 浙江 6540.00 华东 77715.00
4 河南 9883.00 中南 61345.05
5 四川 8372.00 西南 56749.80
6 湖北 5844.00 中南 53734.92
7 福建 4188.00 华东 53109.85
8 湖南 6604.00 中南 48670.37
9 安徽 6127.00 华东 45045.00
10 上海 2489.43 华东 44652.80
11 河北 7420.00 华北 42370.40
12 北京 2188.60 华北 41610.90
13 陕西 3954.00 西北 32772.68
14 江西 4517.40 华东 32074.70
注:我们也可以从url中读取json
pandas读取内嵌json数据
很多时候,我们获取到的json数据并不是直接被我们读取成我们想要的DataFrame,示例如下:
import pandas as pd
data ={
"conuntry": "中国",
"year": 2022,
"provice":[{
"省份": "广东",
"人口": 12684,
"地区": "中南",
"GDP": 129118.58
},
{
"省份": "江苏",
"人口": 8505.4,
"地区": "华东",
"GDP": 122875.6
},
{
"省份": "山东",
"人口": 10169.99,
"地区": "华东",
"GDP": 87435
},
{
"省份": "浙江",
"人口": 6540,
"地区": "华东",
"GDP": 77715
},
{
"省份": "河南",
"人口": 9883,
"地区": "中南",
"GDP": 61345.05
},
{
"省份": "四川",
"人口": 8372,
"地区": "西南",
"GDP": 56749.8
},
{
"省份": "湖北",
"人口": 5844,
"地区": "中南",
"GDP": 53734.92
},
{
"省份": "福建",
"人口": 4188,
"地区": "华东",
"GDP": 53109.85
},
{
"省份": "湖南",
"人口": 6604,
"地区": "中南",
"GDP": 48670.37
},
{
"省份": "安徽",
"人口": 6127,
"地区": "华东",
"GDP": 45045
},
{
"省份": "上海",
"人口": 2489.43,
"地区": "华东",
"GDP": 44652.8
},
{
"省份": "河北",
"人口": 7420,
"地区": "华北",
"GDP": 42370.4
},
{
"省份": "北京",
"人口": 2188.6,
"地区": "华北",
"GDP": 41610.9
},
{
"省份": "陕西",
"人口": 3954,
"地区": "西北",
"GDP": 32772.68
},
{
"省份": "江西",
"人口": 4517.4,
"地区": "华东",
"GDP": 32074.7
}
]}
df = pd.DataFrame(data)
print(df)
输出结果如下图:
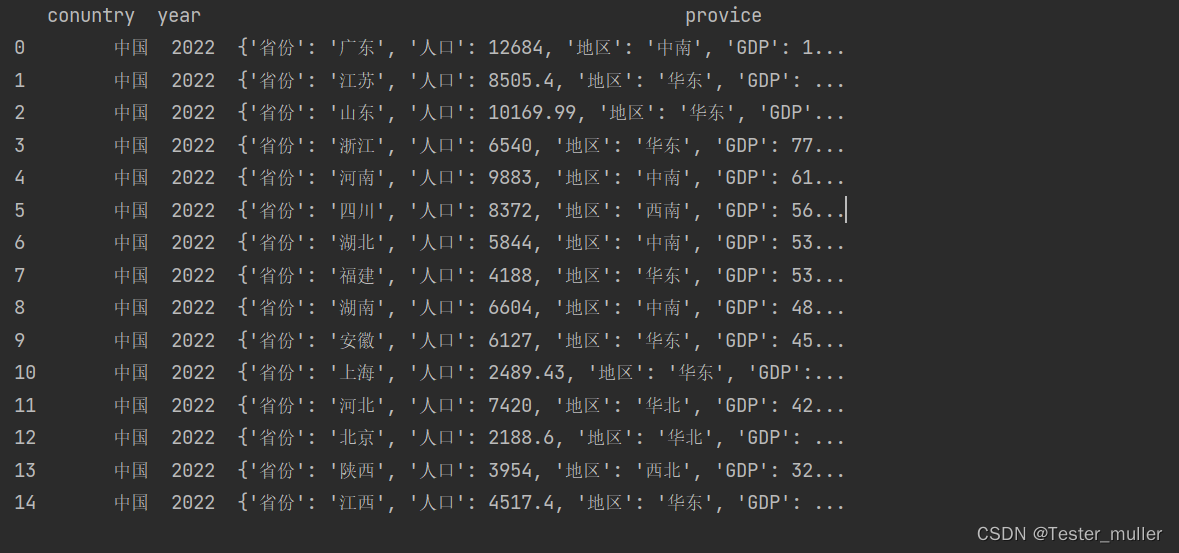
输出的DataFrame很显然不符合我们的要求,我们想要读到的是每一个省份的数据,那我们应该怎么办呢,pandas提供了一个json_normalize() 帮助我们将内嵌的数据完整的解析出来,以下是我们的代码示例:
import pandas as pd
data ={
"conuntry": "中国",
"year": 2022,
"provice":[{
"省份": "广东",
"人口": 12684,
"地区": "中南",
"GDP": 129118.58
},
{
"省份": "江苏",
"人口": 8505.4,
"地区": "华东",
"GDP": 122875.6
},
{
"省份": "山东",
"人口": 10169.99,
"地区": "华东",
"GDP": 87435
},
{
"省份": "浙江",
"人口": 6540,
"地区": "华东",
"GDP": 77715
},
{
"省份": "河南",
"人口": 9883,
"地区": "中南",
"GDP": 61345.05
},
{
"省份": "四川",
"人口": 8372,
"地区": "西南",
"GDP": 56749.8
},
{
"省份": "湖北",
"人口": 5844,
"地区": "中南",
"GDP": 53734.92
},
{
"省份": "福建",
"人口": 4188,
"地区": "华东",
"GDP": 53109.85
},
{
"省份": "湖南",
"人口": 6604,
"地区": "中南",
"GDP": 48670.37
},
{
"省份": "安徽",
"人口": 6127,
"地区": "华东",
"GDP": 45045
},
{
"省份": "上海",
"人口": 2489.43,
"地区": "华东",
"GDP": 44652.8
},
{
"省份": "河北",
"人口": 7420,
"地区": "华北",
"GDP": 42370.4
},
{
"省份": "北京",
"人口": 2188.6,
"地区": "华北",
"GDP": 41610.9
},
{
"省份": "陕西",
"人口": 3954,
"地区": "西北",
"GDP": 32772.68
},
{
"省份": "江西",
"人口": 4517.4,
"地区": "华东",
"GDP": 32074.7
}
]}
df = pd.json_normalize(data, record_path=['provice'])
print(df)
------------------------------
输出结果如下:
省份 人口 地区 GDP
0 广东 12684.00 中南 129118.58
1 江苏 8505.40 华东 122875.60
2 山东 10169.99 华东 87435.00
3 浙江 6540.00 华东 77715.00
4 河南 9883.00 中南 61345.05
5 四川 8372.00 西南 56749.80
6 湖北 5844.00 中南 53734.92
7 福建 4188.00 华东 53109.85
8 湖南 6604.00 中南 48670.37
9 安徽 6127.00 华东 45045.00
10 上海 2489.43 华东 44652.80
11 河北 7420.00 华北 42370.40
12 北京 2188.60 华北 41610.90
13 陕西 3954.00 西北 32772.68
14 江西 4517.40 华东 32074.70
当然,数据可能会更加复杂一些,我们仍然可以读到我们想要的数据,示例数据如下:
{
"club_name": "拜仁慕尼黑",
"season": "2022-2023",
"info": {
"coach": "纳格尔斯曼",
"主场": "慕尼黑安联球场",
"赞助商": {
"球衣": "阿迪达斯",
"胸前广告": "德国电信"
}
},
"player": [
{
"number": 25,
"name": "Muller",
"位置": "前腰",
"进球": 20,
"助攻": 21
},
{
"number": 10,
"name": "萨内",
"位置": "前锋",
"进球": 21,
"助攻": 10
},
{
"number": 6,
"name": "基米希",
"位置": "中场",
"进球": 6,
"助攻": 12
}]
}
代码如下:
import pandas as pd
import json
with open('data2.json', encoding='utf-8') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path=['player'],
meta = [
'season',
['info', 'coach'],
['info', '主场']
]
)
print(df)
------------------------------------
输出结果如下:
number name 位置 进球 助攻 season info.coach info.主场
0 25 穆勒 前腰 20 21 2022-2023 纳格尔斯曼 慕尼黑安联球场
1 10 萨内 前锋 21 10 2022-2023 纳格尔斯曼 慕尼黑安联球场
2 6 基米希 中场 6 12 2022-2023 纳格尔斯曼 慕尼黑安联球场
总结
本文主要介绍了pandas读取json数据的方法,除了直接读取json数据外,还可以读取嵌套的json数据,后续我们将介绍pandas处理Excel数据的方法。