摘要:本文主要为大家讲解基于模型的元学习中的Learning to Learn优化策略和Meta-Learner LSTM。
本文分享自华为云社区《深度学习应用篇-元学习[16]:基于模型的元学习-Learning to Learn优化策略、Meta-Learner LSTM》,作者:汀丶 。
1.Learning to Learn
Learning to Learn by Gradient Descent by Gradient Descent
提出了一种全新的优化策略,
用 LSTM 替代传统优化方法学习一个针对特定任务的优化器。
在机器学习中,通常把优化目标 f(θ) 表示成
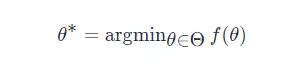
其中,参数 θ 的优化方式为
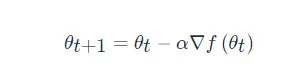
上式是一种针对特定问题类别的、人为设定的更新规则,
常见于深度学习中,主要解决高维、非凸优化问题。
根据 No Free Lunch Theorems for Optimization 理论,
[1] 提出了一种 基于学习的更新策略 代替 人为设定的更新策略,即,用一个可学习的梯度更新规则,替代人为设计的梯度更新规则。
其中,
optimizer 为 g 由 ϕ 参数化;
optimizee 为 ff 由 θθ 参数化。
此时, optimizee 的参数更新方式为
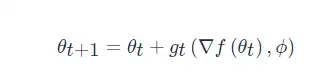
optimizer g 的更新则由 ff, ∇f 及 ϕ 决定。
1.1 学习机制
图1是 Learning to Learn 中 optimizer 和 optimizee 的工作原理。
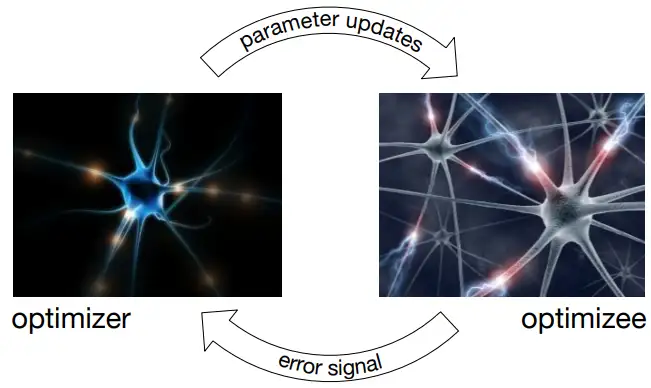
图1 Learning to Learn 中 optimizer 和 optimizee 工作原理。
optimizer 为 optimizee 提供更新策略,
optimizee 将损失信息反馈给 optimizer,协助 optimizer 更新。
给定目标函数 ff 的分布,那么经过 TT 次优化的 optimizer 的损失定义为整个优化过程损失的加权和:
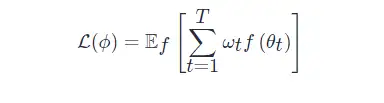
其中,
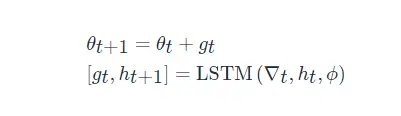
ωt∈R≥0 是各个优化时刻的任意权重,
∇t=∇θf(θt) 。
图2是 Learning to Learn 计算图。
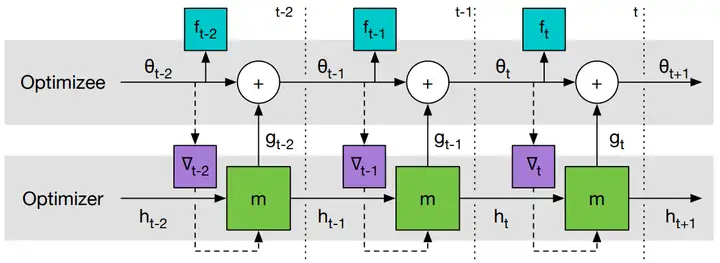
图1 Learning to Learn 计算图。
梯度只沿实线传递,不沿虚线传递(因为 optimizee 的梯度不依赖于 optimizer 的参数,即 ∂∇t/∂ϕ=0 ),这样可以避免计算 ff 的二阶导。
[1] 中 optimizer 选用了 LSTM 。
从 LSTM 优化器的设计来看,
几乎没有加入任何先验的人为经验。
优化器本身的参数 ϕ 即 LSTM 的参数,
这个优化器的参数代表了更新策略。
1.2 Coordinatewise LSTM optimizer
LSTM 需要优化的参数相对较多。
因此,[1] 设计了一个优化器 mm,它可以对目标函数的每个参数分量进行操作。
具体而言,每次只对 optimizee 的一个参数分量 θi 进行优化,
这样只需要维持一个很小的 optimizer 就可以完成工作。
对于每个参数分量 θi ,
optimizer 的参数 ϕ 共享,隐层状态 hihi 不共享。
由于每个维度上的 optimizer 输入的 hi 和 ∇f(θi) 是不同的,
所以即使它们的 ϕ 相同,它们的输出也不一样。
这样设计的 LSTM 变相实现了优化与维度无关,
这与 RMSprop 和 ADAM 的优化方式类似(为每个维度的参数施行同样的梯度更新规则)。
图3是 LSTM 优化器的一步更新过程。
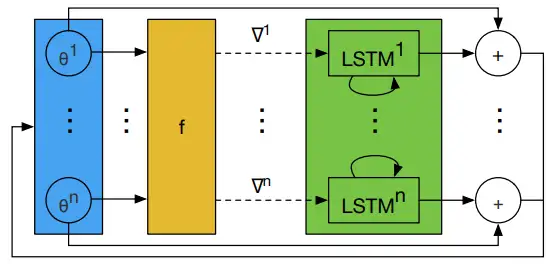
图3 LSTM 优化器的一步更新过程。所有 LSTM 的 ϕ 共享,hi 不共享。
1.3 预处理和后处理
由于 optimizer 的输入是梯度,梯度的幅值变化相对较大,而神经网络一般只对小范围的输入输出鲁棒,因此在实践中需要对 LSTM 的输入输出进行处理。
[1] 采用如下的方式:
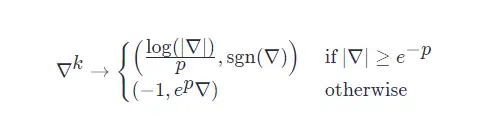
其中, p>0 为任意一个参数([1] 取 p=10),用来裁剪梯度。
如果第一个参数的取值大于 −1−1 ,
那么它就代表梯度的 log ,第二个参数则是它的符号。
如果第一个参数的取值等于 −1−1 ,
那么它将作为一个标记指引神经网络寻找第二个参数,此时第二个参数就是对梯度的缩放。
- 参考文献
[1] Learning to Learn by Gradient Descent by Gradient Descent
2. Meta-Learner LSTM
元学习在处理 few-shot 问题时的学习机制如下:
- 基学习器在元学习器的引导下处理特定任务,发现任务特性;
- 元学习器总结所有任务共性。
基于小样本的梯度下降存在以下问题:
- 小样本意味着梯度下降的次数有限,在非凸的情况下,得到的模型必然性能很差;
- 对于每个单独的数据集,神经网络每次都是随机初始化,若干次迭代后也很难收敛到最佳性能。
因此,元学习可以为基于小样本的梯度下降提供一种提高模型泛化性能的策略。
Meta-Learner LSTM 使用单元状态表示 Learner 参数的更新。
训练 Meta-Learner 既能发现一个良好的 Learner 初始化参数,
又能将 Learner 的参数更新到一个给定的小训练集,以完成一些新任务。
2.1 Meta-Learner LSTM
2.1.1 梯度下降更新规则和 LSTM 单元状态更新规则的等价性
一般的梯度下降更新规则
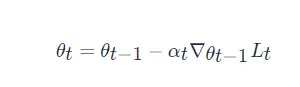
其中,θt 是第 t 次迭代更新时的参数值,αt 是第 t 次迭代更新时的学习率,∇θt−1Lt 是损失函数在 θt−1 处的梯度值。
LSTM 单元状态更新规则
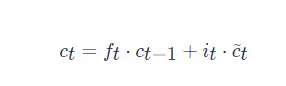
其中,ct 是 t 时刻的细胞状态,]ft∈[0,1] 是遗忘门,it∈[0,1] 是输入门。
当 ft=1, ct−1=θt−1, it=αt, c~t=−∇θt−1Lt 时,Eq. (1)=Eq. (2)Eq. (1)=Eq. (2)。
经过这样的替换,利用 LSTM 的状态更新替换学习器参数 θ。
2.1.2 Meta-Learner LSTM 设计思路
Meta-Learner 的目标是学习 LSTM 的更新规则,并将其应用于更新 Learner 的参数上。
(1) 输入门
\begin{align} i_{t}=\sigma\left({W}_{I} \cdot\left[\nabla_{\theta_{t-1}} L_{t}, L_{t}, {\theta}_{t-1}, i_{t-1}\right]+{b}_{I}\right) \end{align}
其中,W 是权重矩阵;b 是偏差向量;σ 是 Sigmoid 函数;Eq. (1)=Eq. (2)Eq. (1)=Eq. (2)和 Lt 由 Learner 输入 Meta-Learner。
对于输入门参数 it ,它的作用相当于学习率 α ,
在此学习率是一个关于∇θt−1Lt , Lt ,θt−1 ,it−1 的函数。
(2) 遗忘门
\begin{align} f_{t}=\sigma\left(W_{F} \cdot\left[\nabla_{\theta_{t-1}} L_{t}, L_{t}, \theta_{t-1}, f_{t-1}\right]+b_{F}\right) \end{align}
对于遗忘门参数 ft ,它代表着 θt−1 所占的权重,这里将其固定为 1 ,但 1 不一定是它的最优值。
(3) 将学习单元初始状态 c0 视为 Meta-Learner 的一个参数,
正对应于 learner 的参数初始值。
这样当来一个新任务时, Meta-Learner 能给出一个较好的初始化值,从而进行快速学习。
(4) 参数共享
为了避免 Meta-Learner 发生参数爆炸,在 Learner 梯度的每一个 coordinate 上进行参数共享。
每一个 coordinate 都有自己的单元状态,但是所有 coordinate 在 LSTM 上的参数都是一样的。
每一个 coordinate 就相当于 Learner 中的每一层,
即对于相同一层的参数 θi ,
它们的更新规则是一样的,即WI ,bI ,WI ,bI 是相同的。
2.2 Meta-Learner LSTM 单元状态更新过程
将 LSTM 单元状态更新过程作为随机梯度下降法的近似,实现 Meta-Learner 对 Leraner 参数更新的指导。
(1) 候选单元状态: c~t=−∇θt−1Lt,是 Meta-Learner 从 Leraner 得到的损失函数梯度值,直接输入 Meta-Learner ,作为 t 时刻的候选单元状态。
(2) 上一时刻的单元状态:ct−1=θt−1,是 Learner 用第 t−1 个批次训练数据更新后的参数。每个批次的数据训练完后,Leraner 将损失函数值和损失函数梯度值输入 Meta-Learner,Meta-Learner 更新一次参数,将更新后的参数回馈给 Leraner,Leraner 继续处理下一个批次的训练数据。
(3) 更新的单元状态:ct=θt,是 Learner 用第 t 个批次训练数据更新后的参数。
(4) 输出门:不考虑。
(5) 初始单元状态:c0=θ,是 Learner 最早的参数初始值。LSTM 模型需要找到最好的初始细胞状态,使得每轮更新后的参数初始值更好地反映任务的共性,在 Learner 上只需要少量更新,就可以达到不错的精度。
2.3 Meta-Learner LSTM 算法流程
Meta-Learner LSTM 前向传递计算如图1所示,其中,
基学习器 MM,包含可训练参数 θ;元学习器 RR,包含可训练参数 ΘΘ。
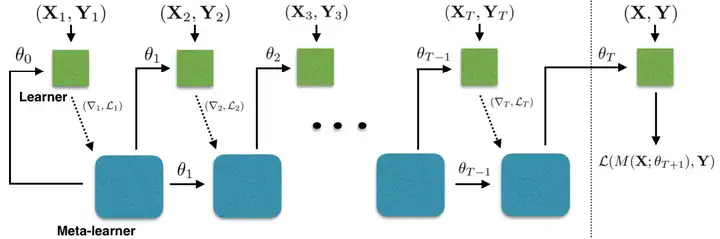
图1 Meta-Learner LSTM 前向传递计算图。 Learner 计算损失函数值和损失函数梯度值, Meta-Learner 使用 Learner 提供的信息,更新 Learner 中的参数和自身参数。 在任务中,每个批次的训练数据处理完成后,Meta-Learner 为 Learner 更新一次参数, 任务中所有批次的训练数据处理完成后,Meta-Learner 进行一次更新。
Meta-Learner LSTM 算法流程
- Θ0Θ0 ←← random initialization
- for d=1,...,nd=1,...,n do:
- DtrainDtrain, DtestDtest ←← random dataset from Dmeta−trainDmeta−train
- intialize learner parameters: θ0←c0θ0←c0
- for t=1,...,Tt=1,...,T do:
- XtXt, YtYt ←← random batch from DtrainDtrain
- get loss of learner on train batch: Lt←L(M(Xt;θt−1),Yt)Lt←L(M(Xt;θt−1),Yt)
- get output of meta-learner using Eq. (2): ct←R((∇θt−1Lt,Lt);Θd−1)ct←R((∇θt−1Lt,Lt);Θd−1)
- update learner parameters: θt←ctθt←ct
- end for
- X,Y←DtestX,Y←Dtest
- get loss of learner on test batch: Ltest←L(M(X;θT),Y)Ltest←L(M(X;θT),Y)
- update ΘdΘd using ∇Θd−1Ltest∇Θd−1Ltest
- end for
- 对于第 dd 个任务,在训练集中随机抽取 TT 个批次的数据,记为 (X1,Y1),⋯ ,(XT,YT)(X1,Y1),⋯,(XT,YT)。
- 对于第 tt 个批次的数据 (Xt,Yt)(Xt,Yt),计算 learner 的损失函数值 Lt=L[M(Xt;θt−1),Yt]Lt=L[M(Xt;θt−1),Yt] 和损失函数梯度值 ∇θt−1Lt∇θt−1Lt,将损失函数和损失函数梯度输入 meta-learner ,更新细胞状态:ct=R[(∇θt−1Lt,Lt);Θd−1]ct=R[(∇θt−1Lt,Lt);Θd−1],更新的参数值等于更新的细胞状态 θt=ctθt=ct。
- 处理完第 dd 个任务中所有 TT 个批次的训练数据后,使用第 dd 个任务的验证集 (X,Y)(X,Y), 计算验证集上的损失函数值 Ltest=L[M(X;θT),Y]Ltest=L[M(X;θT),Y] 和损失函数梯度值 ∇θd−1Ltest∇θd−1Ltest ,更新 meta-learner 参数 ΘdΘd 。
2.4 Meta-Learner LSTM 模型结构
Meta-Learner LSTM 是一个两层的 LSTM 网络,第一层是正常的 LSTM 模型,第二层是近似随机梯度的 LSTM 模型。
所有的损失函数值和损失函数梯度值经过预处理,输入第一层 LSTM 中,
计算学习率和遗忘门等参数,损失函数梯度值还要输入第二层 LSTM 中用于参数更新。
2.5 Meta-Learner LSTM 和 MAML 的区别
- 在 MAML 中,元学习器给基学习器提供参数初始值,基学习器给元学习器提供损失函数值;
在 Meta-Learner LSTM 中,元学习器给基学习器提供更新的参数,基学习器给元学习器提供每个批次数据上的损失函数值和损失函数梯度值。 - 在 MAML 中,基学习器的参数更新在基学习器中进行,元学习器的参数更新在元学习器中进行;
在 Meta-Learner LSTM 中,基学习器和元学习器的参数更新都在元学习器中进行。 - 在 MAML 中,元学习器使用 SGD 更新参数初始值,使得损失函数中存在高阶导数;
在 Meta-Learner LSTM 中,元学习器给基学习器提供修改的 LSTM 更新参数,元学习器自身的参数并不是基学习器中的参数初始值,元学习器自身的参数使用 SGD 进行更新,并不会出现损失函数高阶导数的计算。 - 在 MAML 中,元学习器和基学习器只在每个任务训练完成后才进行信息交流;
在 Meta-Learner LSTM 中,元学习器和基学习器在每个任务的每个批次训练数据完成后就进行信息交流。 - MAML 适用于任意模型结构;
Meta-Learner LSTM 中的元学习器只能是 LSTM 结构,基学习器可以适用于任意模型结构。
2.6 Meta-Learner LSTM 分类结果
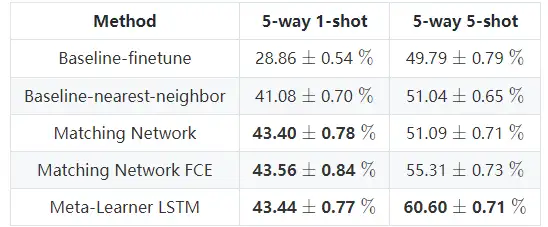
表1 Meta-Learner LSTM 在 miniImageNet 上的分类结果。
- 参考文献
[1] Optimization as a Model for Few-Shot Learning
[2] 长短时记忆网络 LSTM
标签:Learner,更新,学习,Meta,参数,Learning,LSTM From: https://www.cnblogs.com/huaweiyun/p/17485021.html