前言 CVPR 2023 开幕在即,官方公布了12篇最佳论文候选,快来看看都是什么内容吧!
本文转载自我爱计算机视觉
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
1.OmniObject3D: Large Vocabulary 3D Object Dataset for Realistic Perception, Reconstruction and Generation
1)方向:基于真实扫描的大规模三维物体数据库构建。
2)应用:应用领域包括三维感知、重建和生成等领域,旨在促进真实世界中的三维物体识别、重建和生成等方面的发展。
3)背景:目前,建模三维物体的最新进展主要依赖于合成数据集,因为缺乏大规模的真实扫描的三维数据库。为了促进在真实世界中的三维感知、重建和生成等方面的发展,作者提出 OmniObject3D,这是一个具有大规模词汇的三维物体数据集,包含大量高质量的真实扫描的三维物体。
4)方法:OmniObject3D具有几个吸引人的特点:①Large Vocabulary:它包括190个日常类别中的6,000个扫描物体,与流行的二维数据集(如ImageNet和LVIS)共享常见类别,有利于追求具有泛化能力的三维表示。2)Rich Annotations:每个三维物体都通过2D和3D传感器进行捕捉,提供有纹理的网格、点云、多视角渲染图像和多个真实捕捉的视频。3)Realistic Scans:专业扫描仪支持具有精确形状和逼真外观的高质量物体扫描。
5)结果:通过在四个基准测试的广泛研究,发现了现实的三维视觉研究中的新观察、挑战和机遇,为未来研究提供了借鉴和指导,并展示了OmniObject3D在鲁棒三维感知、新视角合成、神经表面重建和三维物体生成等方面的潜力和优越性能。

2.DynIBaR: Neural Dynamic Image-Based Rendering
1)方向:从单目视频中合成新视角。
2)应用:应用领域包括合成复杂动态场景的新视角,以及在真实世界应用中的图像渲染和视角合成。
3)背景:现有的基于动态神经辐射场(即动态NeRF)的方法在合成新视角的任务上取得了令人印象深刻的结果。然而,对于具有复杂物体运动和不受控制的摄像机轨迹的长视频,这些方法可能会产生模糊或不准确的渲染结果,限制了它们在真实世界应用中的使用。
4)方法:本文提出一种新的方法,通过采用基于 volumetric 的图像渲染框架,在场景运动感知的方式下,通过聚合附近视角的特征来合成新视角,从而解决了上述限制。该系统保留了之前方法的优点,能够模拟复杂场景和视角相关效果,同时能够从具有复杂场景动态和自由摄像机轨迹的长视频中合成逼真的新视角。
5)结果:在动态场景数据集上,所提出方法在比现有方法上取得了显著的改进。此外,该方法还应用于具有挑战性的摄像机和物体运动的自然视频,而之前的方法无法产生高质量的渲染结果。这表明该方法在处理复杂动态场景和非受限摄像机轨迹的长视频方面具有优势,并能够产生高质量的渲染结果。

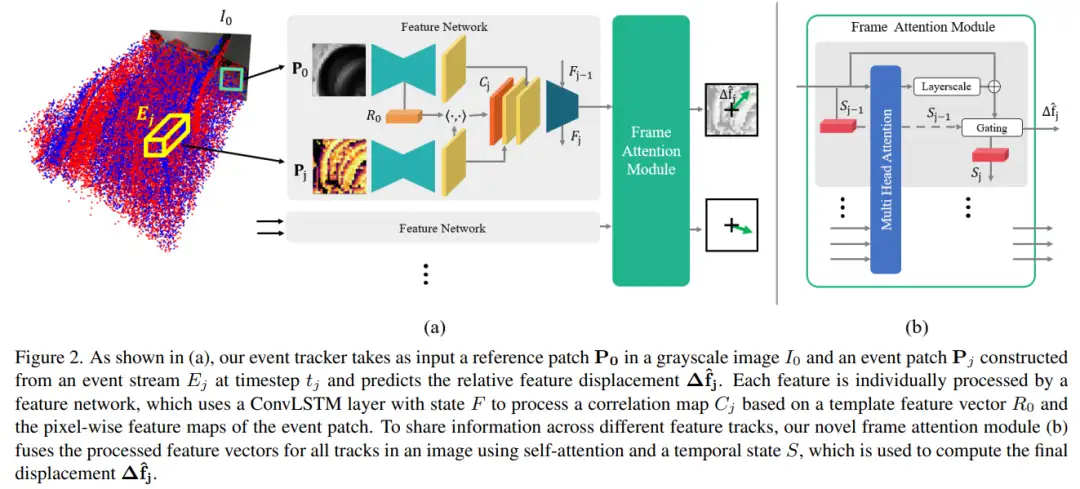
3.Data-driven Feature Tracking for Event Cameras
1)方向:基于事件相机的数据驱动特征跟踪。
2)应用:应用领域包括低延迟和低带宽特征跟踪。
3)背景:现有的事件相机特征跟踪方法要么是手工设计的,要么是基于第一原理推导的,但需要进行大量参数调整,对噪声敏感,并且由于未建模的效应,无法适用于不同的场景。
4)方法:为了解决这些问题,本文介绍了第一个基于数据驱动的事件相机特征跟踪器,利用低延迟事件来跟踪在灰度帧中检测到的特征。通过引入一种新的帧注意力模块,在特征跟踪之间共享信息,实现了鲁棒的性能。
5)结果:实验结果表明,该数据驱动跟踪器在特征跟踪方面的相对性能较现有方法提高了120%,并实现了最低的延迟。通过采用自监督策略将跟踪器适应于真实数据,这种性能差距进一步增加到130%。这些结果显示了该方法在事件相机特征跟踪方面的优势和潜力。
4.On Distillation of Guided Diffusion Models
1)方向:无分类器引导的扩散模型的提取和加速。
2)应用:应用领域包括高分辨率图像生成,特别是在大规模扩散框架(如DALLE-2、Stable Diffusion和Imagen)中被广泛应用。
3)背景:无分类器引导的扩散模型在高分辨率图像生成方面已被证明非常有效,但其在推断时计算成本较高,因为需要多次评估两个扩散模型,即条件模型和无条件模型。
4)方法:为了解决这个限制,本文提出一种将无分类器引导的扩散模型转化为快速采样模型的方法:首先,给定一个预训练的无分类器引导模型,学习一个单一模型来匹配条件和无条件模型的输出,然后逐步将该模型精简为一个只需要更少采样步骤的扩散模型。
5)结果:对于在像素空间训练的标准扩散模型,在ImageNet 64x64和CIFAR-10数据集上,所提出方法只需4个采样步骤就能生成与原始模型视觉上相当的图像,同时在FID/IS得分上与原始模型相当,但采样速度提高了多达256倍。对于在隐空间训练的扩散模型(如Stable Diffusion),所提出方法能够仅使用1到4个去噪步骤生成高保真度的图像,在ImageNet 256x256和LAION数据集上相较于现有方法至少加速10倍的推断。文章进一步展示了所提出方法在文本引导的图像编辑和修复上的有效性,其中精简模型能够在仅使用2-4个去噪步骤的情况下生成高质量的结果。

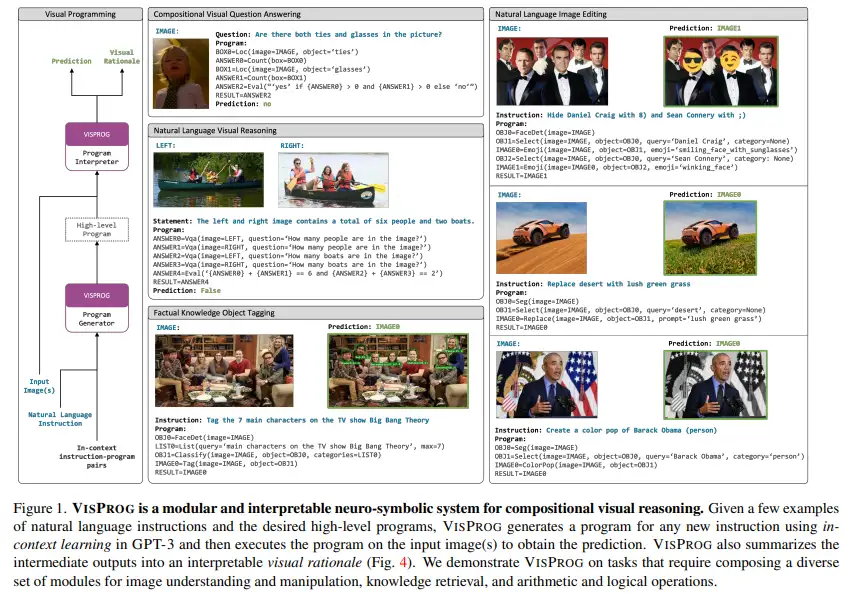
5.Visual Programming: Compositional visual reasoning without training
1)方向:基于神经符号方法解决复杂和组合式的视觉任务,并结合自然语言指令进行处理。
2)应用:应用领域是在给定自然语言指令的情况下解决复杂和组合式的视觉任务。包括复合视觉问答、图像对的零样本推理、事实知识对象标记和语言引导的图像编辑等任务。
3)背景:VISPROG,一种神经符号方法,用于解决给定自然语言指令的复杂和组合视觉任务。VISPROG 避免了需要针对特定任务进行训练的需求。
4)方法:VISPROG 使用大型语言模型的上下文学习能力来生成类似python的模块化程序,然后执行这些程序以获得解决方案和全面且可解释的基本原理。生成的程序的每一行都可以调用几个现成的计算机视觉模型、图像处理例程或 python 函数之一,以产生可能被程序的后续部分使用的中间输出。
5)结果:文章展示了VISPROG在四个不同的任务上的灵活性,包括复合视觉问答、图像对的零样本推理、事实知识对象标记和语言引导的图像编辑。表明像VISPROG这样的神经符号方法是扩展人工智能系统范围以服务于人们可能希望执行的复杂任务的有趣途径。
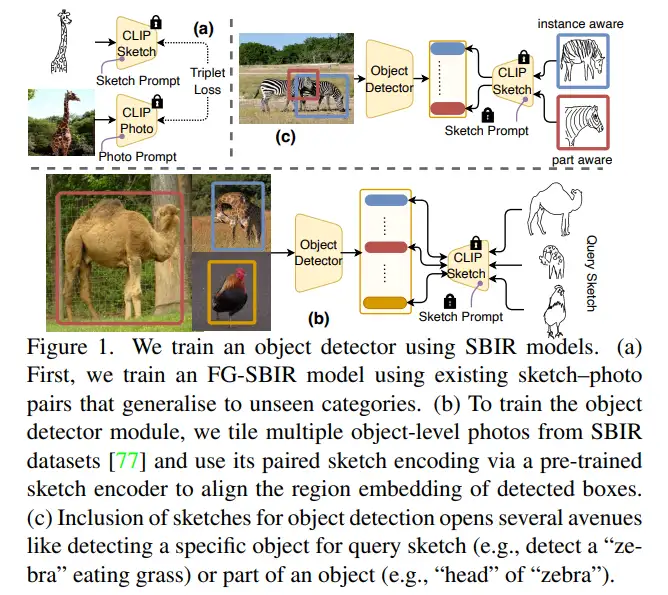
6.What Can Human Sketches Do for Object Detection?
1)方向:基于草图的目标检测
2)应用:应用领域是目标检测。
3)背景:传统上,人们对草图的研究主要集中在图像检索领域。本文首次将草图的表达力应用于目标检测任务,旨在发掘草图固有的主观性和细粒度视觉线索。
4)方法:本次工作通过将基于草图的图像检索模型(SBIR)与基础模型(如CLIP)相结合,构建一个草图辅助的目标检测框架。首先,在SBIR模型的草图和图像分支上进行独立的提示,构建了高度通用的草图和图像编码器。然后,设计了一种训练范式,使得检测到的边界框的区域嵌入与SBIR中的草图和图像嵌入对齐。
5)结果:在PASCAL-VOC和MS-COCO等标准目标检测数据集上评估,该框架在零样本设置下优于有监督的目标检测器和弱监督的目标检测器。结果表明,利用草图的表达力进行目标检测是可行的,并且取得了良好的性能。
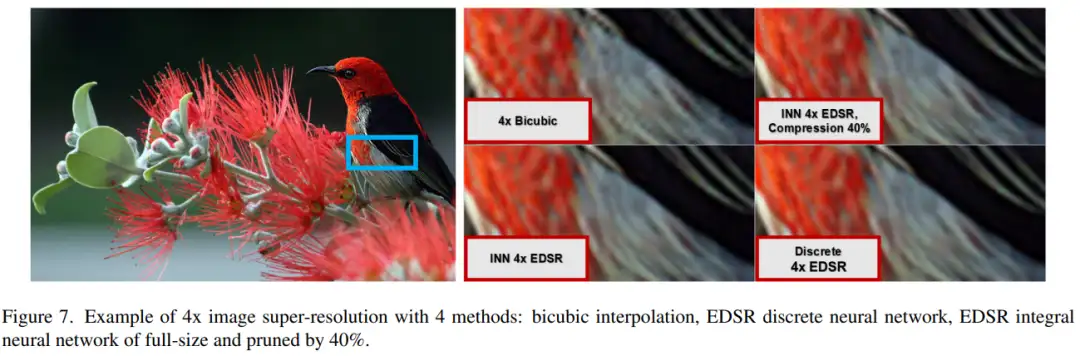
7.Integral Neural Networks
1)方向:积分神经网络
2)应用:神经网络模型表示、加速与部署。
3)背景:传统的神经网络模型使用离散权重张量表示网络层的权重,而本文提出的INN模型使用连续函数表示权重,并通过连续积分操作替换输入层的离散变换。
4)方法:INN模型将网络层的权重表示为定义在N维超立方体上的连续函数,并通过数值积分求解将连续层转化为传统的张量表示。这种表示方法允许在任意大小的离散化网络上进行操作,并可以使用不同的离散化间隔进行积分核操作。
5)结果:在多个神经网络结构和多个任务上进行的实验证明,所提出的INN模型在与传统离散表示模型相比的性能上基本相同,并且在高速率结构剪枝(30%)的情况下,相较于传统剪枝方法的65%的准确率损失,仍能保持大致相同的性能(例如在Imagenet数据集上,对于ResNet18模型的准确率损失约为2%)。因此,所提出的INN模型具有实际应用的潜力,并且在模型剪枝方面具有优势。
8.MobileNeRF: Exploiting the Polygon Rasterization Pipeline for Efficient Neural Field Rendering on Mobile Architectures
1)方向:基于纹理多边形的神经辐射场(Neural Radiance Fields,NeRF)表示,旨在通过标准渲染管线高效地合成新视角下的图像。
2)应用:应用领域是图像合成和渲染。
3)背景:传统的NeRF方法使用基于光线行进(ray marching)的体素渲染算法合成3D场景的图像,但这种方法与广泛部署的图形硬件的能力不匹配。
4)方法:本文提出一种基于纹理多边形的NeRF表示方法,其中NeRF被表示为一组具有纹理的多边形,纹理表示二值不透明度和特征向量。通过传统的多边形渲染和z-buffer技术,可以在每个像素点上生成带有特征的图像,然后通过片段着色器中运行的小型视角相关多层感知机(MLP)解释这些特征,并产生最终的像素颜色。
5)结果:通过使用基于纹理多边形的NeRF表示,并利用传统的多边形光栅化渲染管线,使得NeRF可以在包括移动手机在内的各种计算平台上实现交互式帧率。这种方法充分利用了大规模的像素级并行计算,为用户提供了高效的图像合成和渲染体验。

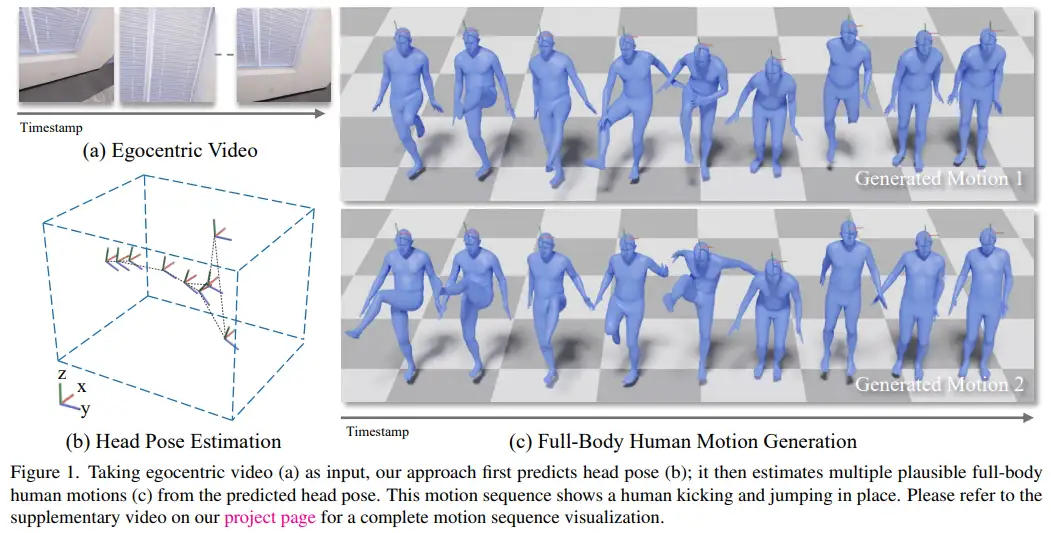
9.Ego-Body Pose Estimation via Ego-Head Pose Estimation
1)方向:从自我中心视角的视频序列中估计三维人体动作
2)应用:领域是人类行为理解、虚拟现实和增强现实等。
3)背景:由于摄像头位于用户头部,前向摄像头通常无法观察到用户的身体,因此在自我中心视角的视频和人体动作之间建立映射是具有挑战性的。此外,收集具有配对自我中心视频和三维人体动作的大规模高质量数据集需要准确的运动捕捉设备,这通常会限制视频中场景的多样性。
4)方法:为了消除自我中心视频和人体动作之间的配对需求,本文提出了一种新方法,名为“EgoEgo”,它将问题分解为两个阶段,中间通过头部运动作为中间表示进行连接。首先,EgoEgo结合了SLAM和学习方法来估计准确的头部运动。然后,利用估计的头部姿态作为输入,EgoEgo利用条件扩散生成多个合理的全身动作。通过头部和身体姿态的解耦,消除了训练数据集中配对自我中心视频和三维人体动作的需求,能够分别利用大规模的自我中心视频数据集和动作捕捉数据集。
5)结果:为了进行系统性的基准测试,作者还开发了一个合成数据集“AMASS-Replica-Ego-Syn (ARES)”,其中包含配对的自我中心视频和人体动作。在ARES和真实数据上,EgoEgo模型的性能显著优于当前最先进的方法。通过提出的EgoEgo方法,可以有效地从自我中心视角的视频序列中估计三维人体动作,并在多个数据集上取得了良好的结果。
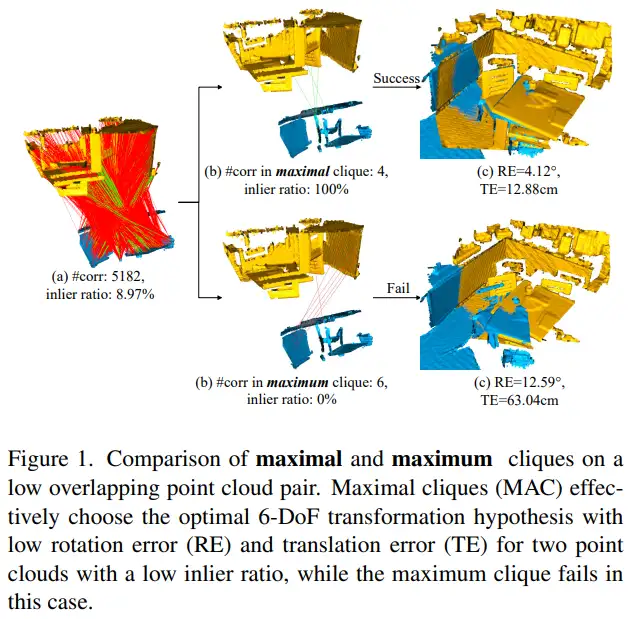
10.3D Registration with Maximal Cliques
1)方向:三维点云配准(PCR)
2)应用:应用领域是计算机视觉中的三维点云配准。
3)背景:在计算机视觉中,三维点云配准是一个基本问题,它涉及将两个点云对齐以找到最佳的姿态。现有方法通常使用最大团约束来寻找一致性信息,但存在一些限制。
4)方法:本文提出一种基于最大团的三维配准方法(MAC)。该方法通过放宽先前的最大团约束,在图形中挖掘更多的局部一致性信息以生成准确的姿态假设。具体方法包括:1)构建兼容性图,以呈现初始对应关系之间的亲和关系;2)在图中搜索最大团,每个最大团表示一个一致性集合,然后进行节点引导的最大团选择,每个节点对应于具有最大图权重的最大团;3)使用奇异值分解(SVD)算法计算所选最大团的变换假设,并使用最佳假设进行配准。
5)结果:在U3M、3DMatch、3DLoMatch和KITTI等数据集上的大量实验证明,MAC方法有效提高了配准的准确性,优于各种最先进的方法,并提升了深度学习方法的性能。MAC与深度学习方法相结合,在3DMatch和3DLoMatch上实现了95.7% / 78.9%的最新配准召回率,达到了最先进的水平。
- 论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Zhang_3D_Registration_With_Maximal_Cliques_CVPR_2023_paper.pdf
- 主页链接:https://github.com/zhangxy0517/3D-Registration-with-Maximal-Cliques
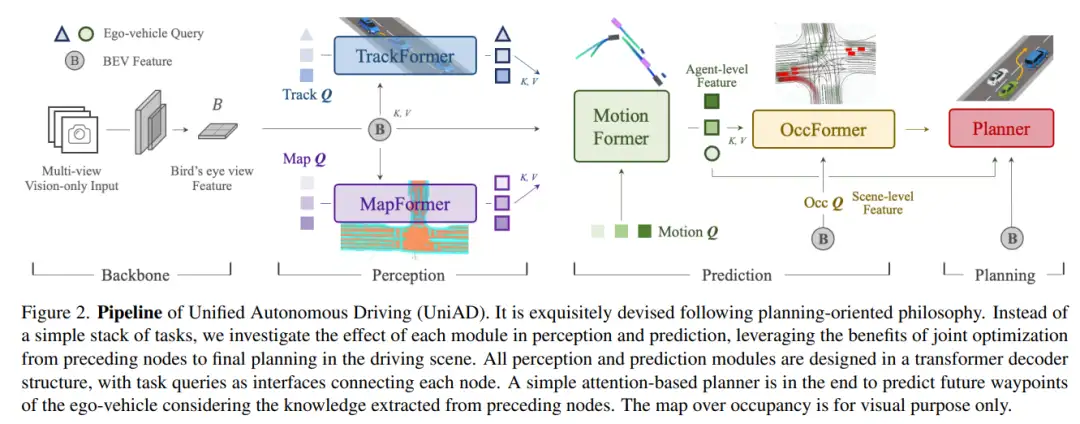
11.Planning-oriented Autonomous Driving
1)方向:现代自动驾驶系统中的综合框架设计
2)应用:应用领域是自动驾驶系统。
3)背景:现代自动驾驶系统中,任务通常按照感知、预测和规划的顺序进行模块化处理。然而,现有方法要么为每个任务部署独立的模型,要么设计一个带有独立头部的多任务范式。然而,它们可能受到累积误差或任务协调不足的影响。因此,需要开发一种旨在实现自动驾驶车辆规划这一终极目标的优化框架。
4)方法:本文提出统一自动驾驶(UniAD)综合框架,将感知和预测等关键组件重新审视,并优先考虑这些任务对规划的贡献。UniAD框架巧妙地设计,以充分利用每个模块的优势,并从整体的视角提供互补的特征抽象,以促进智能体的交互。任务通过统一的查询接口进行通信,以便相互协作实现规划。作者在具有挑战性的nuScenes基准上实例化了UniAD框架,并通过大量的实验验证了这一理念的有效性,显著优于以往的最先进方法。
5)结果:通过在nuScenes基准上的广泛对比实验,证明了采用该综合框架设计的有效性,在各个方面明显优于以往的最先进方法。该研究提供了公开的代码和模型。
12.DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
1)方向:Subject驱动的图像合成。
2)应用:应用领域是文本到图像的合成。
3)背景:大型文本到图像模型在人工智能的发展中取得了显著的进展,可以根据给定的文本提示高质量、多样化地合成图像。然而,这些模型缺乏模仿给定参考集中主体外观并在不同环境中合成新的表现形式的能力。
4)方法:本文提出一种新的方法,用于对文本到图像扩散模型进行个性化。仅提供少量主体图像作为输入,对预训练的文本到图像模型进行微调,使其学习将唯一标识符与特定主体绑定。一旦主体被嵌入模型的输出领域,该唯一标识符可以用于合成在不同场景中上下文化的主体的新颖逼真图像。通过利用模型中嵌入的语义先验和新的自生类别特定先验保持损失,该技术使得能够在参考图像中没有出现的多样场景、姿势、视角和光照条件下合成主体。
5)结果:通过该方法,可以实现对特定主体的个性化合成,并在不同场景下生成多样化的照片级真实图像,包括主体重上下文化、文本引导视图合成和艺术渲染等任务。文中还提供了用于Subject驱动生成的新任务的新数据集和评估协议。

欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
ICLR2023 | 扩散生成模型新方法:极度简化,一步生成
小内存有救了!Reversible ViT:显存减少15倍,大模型普及曙光初现!
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
CVPR 2023 | 即插即用!SQR:对于训练DETR-family目标检测的探索和思考
CVPR 2023 Highlight | 西湖大学提出一种全新的对比多模态变换范式
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:12,模型,2023,三维,CVPR,https,图像,方法,链接 From: https://www.cnblogs.com/wxkang/p/17483155.html