机器学习设计模式
介绍
设计模式是一种将专家的经验和知识记录为可行建议的方法,所有从业者都可以应用这些建议来使用久经考验的方法解决他们的问题。就像我们有传统的软件设计模式、微服务设计模式、API 设计模式、游戏开发设计模式等等;在机器学习中发现和记录设计模式是有意义的。
机器学习中的常见挑战与数据质量、可重复性、数据漂移、重新训练、规模等有关。这些挑战对于这门学科来说是足够具体的,足以证明机器学习模式的出现是合理的。在本文中,我们将探讨什么是设计模式,为什么需要机器学习设计模式,并且我们将探讨一个示例。
什么是设计模式?
Christopher Alexander 等人在建筑领域创造了模式的概念和模式目录。在他的《模式语言》一书中,他记录了 200 多种架构模式。
模式描述了在架构学科中反复出现的问题,然后以给定解决方案可以重复用作“配方”的方式描述该问题的解决方案。
每个模式都有一个名称,以使架构师不必不断解释问题和随附的解决方案细节。每个解决方案都以一般和抽象的方式进行解释,因此每个架构师都可以使用自己的技能以自己的方式解决它,从而使解决方案适应他们所面临的上下文和环境。
什么是软件设计模式?
软件设计模式是针对给定上下文中常见问题的通用可重用解决方案。设计模式不是可以直接在代码中实现的最终设计。它是关于如何解决问题的描述或模板,可以在许多不同的情况下使用。
模式
基于软件开发的最佳实践和原则。从某种意义上说,它们是一个共享词汇表,用于与其他开发人员交流我们的意图。因此,我们表达的不仅仅是一个模式名称,我们隐含地谈论特征、质量、约束、潜在的陷阱,甚至潜在的实现细节。
当我们在描述中使用模式时,其他开发人员准确地知道我们在考虑什么设计。设计模式允许我们在抽象级别讨论问题及其解决方案,而无需担心实现细节。一个熟悉设计模式的团队可以快速达成共识,减少误解。
设计模式是一种紧凑的语言,让我们能够事半功倍。因此,我们获得了可重用性(设计级别)而不是代码可重用性(源代码级别)的经验。
为什么我们需要机器学习 (ML) 设计模式?
与其他计算机科学学科一样,ML 始于可扩展性、可靠性、性能和其他软件质量属性不是主要目标的学术环境。今天,在生产中部署机器学习模型被认为是一门工程学科,因此我们必须利用那些已应用于业务问题的软件和数据工程最佳实践并将其应用于 ML。重要的是 ML 从业者利用现有的经过验证的软件工程方法来解决重复出现的问题并开发新的 ML 特定设计模式。
开发 ML 项目提出了一系列影响解决方案设计的独特挑战(如数据质量、概念漂移、再现性、偏见、可解释性等)。记录这些问题、背景和解决方案是传递知识、交流和使机器学习学科民主化的好方法。
《设计模式:可重用的面向对象软件的元素》2 一书以解释软件设计模式为中心,被认为是本领域的开创性书籍。大多数软件设计模式都是使用本书中解释的模板记录的。机器学习模式仍然是一个正在发展的领域,仍然没有普遍接受的标准来记录它们。在接下来的几年中很有可能会看到一些模板提案。
一个示例 ML 模式:再平衡
有时使用示例更容易理解某些内容。让我们深入研究机器学习中的一个常见问题:分类或回归问题中的类不平衡。这可能会影响训练模型的性能。
问题
面对数据集类不平衡的机器学习问题(分类预测建模)是很常见的。这意味着样本在已知类别中的分布存在严重偏差或偏斜。不平衡的数据集带来了挑战,因为大多数用于分类的机器学习算法都是在假设每个类别的示例数量相等的情况下设计的;因此,经过训练的模型对于少数类的性能可能会很差。此外,少数类通常更“重要”。
机器学习模型在使用数据集中每个类的相似数量的示例进行训练时具有最佳性能。然而,现实世界的机器学习问题很少是平衡的。
让我们考虑与信用卡欺诈检测相关的示例或模型来预测给定图像中黑色素瘤的存在。
不平衡类的问题是“盲目地”相信准确度值。如果我们训练一个黑色素瘤预测模型并且只有 3% 的数据集包含黑色素瘤图像,那么无论选择或不选择机器学习算法(神经网络、支持向量机、决策树等),该模型的准确率都可能在 97% 左右对数据集的任何修改。
尽管 97% 的准确率数字在数学上是合理的,但该模型可能实际上是在猜测每个示例的多数类别(无黑色素瘤)。这意味着即使是始终预测多数类别的模型也将具有良好的性能,这也可以在完全不使用机器学习的情况下完成。
因此,该模型没有学习任何关于如何预测少数类(通常是“重要类”)的知识。在回归建模中,当数据的异常值远低于或高于数据集中的中位数时,就会出现不平衡的数据集。
解决方案
正如我们刚刚讨论的,准确性受不平衡类的影响,因此第一步是选择正确的指标来评估模型。我们可以在数据集或模型级别应用技术。
- 在数据级别,我们可以应用下采样或上采样。
- 在模型级别,我们可以将分类问题转换为回归问题。我们将把最后一个留给读者研究,我们将在本文中提供关于上采样、下采样和选择适当指标的摘要。
选择评估指标
对于不平衡的数据集,我们必须更喜欢精度、召回或 F 度量等指标来评估模型。让我们分析这些指标是如何计算的,以了解为什么它们比不平衡数据集的准确性更好。
定义:
条件正例(P):数据中真实正例的数量。
条件否定(N):数据中真实否定案例的数量。
真阳性(TP):正确表明存在某种状况或特征的测试结果。
真阴性(TN):正确表明不存在某种情况或特征的测试结果。
假阳性(FP):错误地表明存在特定条件或属性的测试结果。
假阴性(FN):测试结果错误地表明特定条件或属性不存在。
精度(或阳性预测值):
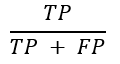
召回率(灵敏度或真阳性率):
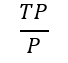
F-测量: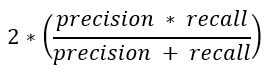
准确性: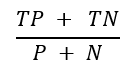
为了帮助我们的直觉,假设我们用不平衡的数据集训练了一个欺诈检测模型。我们使用 1000 个样本的测试数据集来评估我们的模型。该数据集包含 50 笔欺诈交易和 950 笔有效交易,这是一个明显的不平衡数据集。我们的模型产生了以下混淆矩阵(一种易于可视化的方法:TP、TN、FP 和 FN):
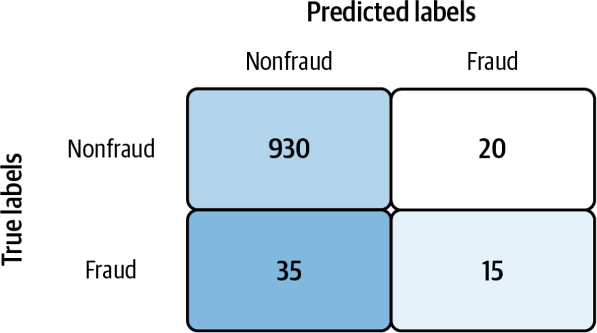
让我们计算一些指标:
如您所见,精度为 42.8%,召回率为 30%,f-measure 为 35.2%。在捕捉模型无法正确识别欺诈交易这一事实方面,它们都优于准确率(94.5%)。在这种情况下,准确性太高、太乐观,显然是一个误导性指标。因此,对于不平衡的数据集,建议使用准确性以外的指标。
如果您检查准确性是如何计算的,您将很容易发现问题。换句话说,准确性衡量的是:“模型正确预测的真阴性(非欺诈)和真阳性(欺诈)的百分比”。鉴于数据集中的几乎所有样本都是真阴性(非欺诈),因此使用不平衡数据集训练的任何模型都极有可能具有高精度。
下采样
下采样包括减少模型训练期间使用的多数类的示例数量。这听起来可能违反直觉,因为我们认为更大的数据集总是更好,但是如前所述,大型不平衡数据集只会让事情变得更糟。要应用下采样,您将来自少数类的所有样本与从多数类中抽取的一个小随机样本组合在一起,重新排列数据并使用此数据集进行训练。您可以猜到,这将创建一个比原始数据集更平衡的数据集,从而提高模型的性能。
加权类
一些机器学习框架和库允许我们明确地告诉我们的模型,在训练期间某些特定标签比其他标签“更重要”。因此,您只需为少数类的样本分配更多权重。设置权重值是一个模型超参数,因此您可以自行试验以找到最佳值。
上采样
这个想法是通过复制少数类示例并生成额外的“合成”样本(有一些算法旨在创建合成示例)来过度代表少数类。例如,通过分析少数类数据集的特征空间,可以使用最近邻方法在该特征空间内生成类似的示例。
使用上采样,我们合并来自少数类的所有样本、所有综合创建的示例、从多数类中抽取的随机子集,然后重新洗牌新创建的数据集进行训练。
这够了吗?
像我们刚才那样记录问题和解决方案就足够了吗?答案是不。
设计模式文档应至少包括应用模式的上下文、模式想要解决的上下文中的力量以及建议的解决方案。
记录设计模式没有单一的标准,但它们通常包括以下内容:
-
模式名称和分类:唯一的描述性名称。
-
意图:模式背后的目标和使用它的原因。
-
动机:解释问题的场景和可以应用该模式的上下文。
-
适用性:使用该模式有意义的情况。
-
结构:模式(图表)的图形表示。
-
后果:使用该模式产生的结果、副作用和权衡。
-
示例代码:如何使用该模式的代码说明。
-
已知用途:模式的实际用途示例。
可能在接下来的几年里,一种记录机器学习模式的标准将会出现,并且会比其他标准更受欢迎。
结论
设计模式将专家的经验和知识编码为所有从业者都可以遵循的建议。机器学习设计模式捕获了设计、构建、训练和部署机器学习系统中常见问题的最佳实践和解决方案。机器学习设计模式是传统软件开发设计模式的自然补充,它们扩展了软件工程的知识体系,并通过使用经过验证的解决方案帮助避免常见的陷阱。
参考:
- A Pattern Language: Towns, Buildings, Construction by Christopher Alexander, Sara Ishikawa, and Murray Silverstein (1977)
- Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson & John Vlissides (1995) )