RCU
RUC是什么?
- RCU(Read-Copy-Update)是一种用于并发编程的技术,旨在提供高效且无锁(lock-free)的读操作,同时保证数据一致性和并发性。
也就是说他并不需要锁的机制来保障数据一致性和并发现.
1.RCU的实现原理
- RCU的实现本质上是为了解决读写锁的问题,因为读者可以多数的问题,而写锁互斥的性质,会导致其他读锁也被阻塞,因此会造成一定上的性能开销.
而RCU的关键就是在更新下拷贝(Copy),因此他的实现机制大致如下:
- 初始阶段: 在初始阶段,所有读取线程可以同时访问共享数据,而不需要任何同步机制。这是因为在此阶段,尚未发生任何写操作,因此读取操作不会访问到不一致或无效的数据。
- 更新阶段: 当需要修改共享数据时,RCU采用一种"写时复制"(copy-on-write)的策略。它首先创建一个新的数据副本,然后将修改应用于该副本,而不是直接修改共享数据。这确保了在更新期间,读取线程仍然可以访问到旧版本的数据,而不会被更新操作所影响。
- 发布阶段: 在更新完成后,RCU使用一种特定的机制来通知读取线程有新的数据副本可用。这个机制可以是类似于发布-订阅的模型,其中读取线程可以订阅通知,并在新的数据副本发布时接收到通知。通过这个发布机制,读取线程可以感知到新的数据副本,并在需要时切换到新版本的数据。
- 回收阶段: 在发布新的数据副本后,旧版本的数据并不立即被回收。RCU采用一种延迟回收的策略,在确认所有读取线程都不再使用旧数据副本之后,才进行回收操作。这通常涉及使用计数器或其他形式的跟踪机制,以确保在旧版本的数据没有被使用时进行回收,从而避免破坏读取线程的正确性。
2.订阅/发布机制
其实订阅/发布机制不光可以用来修改数据,他的本身也是一种通知信息的方式,所以无论是插入,删除还是修改都可以的.
- 而订阅/发布机制其实为我们实现的就是:让读者在写者更新时,要么读的旧的值,要么读到新的值,而不能观察到中间的任何结果.
而这种机制的实现得以于很重要的一点:单拷贝原子性
什么是单拷贝原子性?
意思就是CPU均提供对地址对齐的单一读写操作的原子性保证,其支持的位宽往往与CPU的位宽一致.
什么是地址对齐?
地址对齐是指在访问计算机内存中的数据时,数据的起始地址与数据的长度之间存在特定的对齐关系。
在大多数计算机系统中,数据的存储是以字节为单位的,而不同类型的数据(如整数、浮点数等)可能需要不同长度的存储空间。对齐要求是为了确保数据在内存中的存储和访问的效率以及硬件的正常工作。
最常见的案例就是:C语言中的结构体:
例如:
struct Person {
char name[10]; // 10 字节
int age; // 4 字节
float height; // 4 字节
};
根据常理来说,是18个字节的内存大小,实际上输出的结果是这样的:
20
Process returned 0 (0x0) execution time : 0.014 s
Press any key to continue.
-
先给答案,这里的char类型的数组把他看成一个一个1字节的char类型组和而成,而编译器会根据字长对齐的方式,也就是根据4字节来对齐,因此name数组实际上是12个字节,因此12+4+4 = 20个字节;
实际上地址对齐根据编译器有相对应的规则,但一般来说具备一些规则:
- 结构体总体大小能够被最宽的成员的大小整除,如不能则在后面补充字节
- 每个成员相对于起始地址的偏移能够被其自身大小整除

而之前的那句话含义就是对于单个机器字长的读写操作,即读写操作的数据大小和处理器的位长相同的情况下,CPU会提供一定的原子性保护,这是基于硬件的实现.也就意味着要么完全执行,要么不执行,因此机器的执行只有0和1两个结果,因此不会出现中间态就是这个原因
现在再来看订阅/发布机制:
例如,链表中插入一个新的节点:
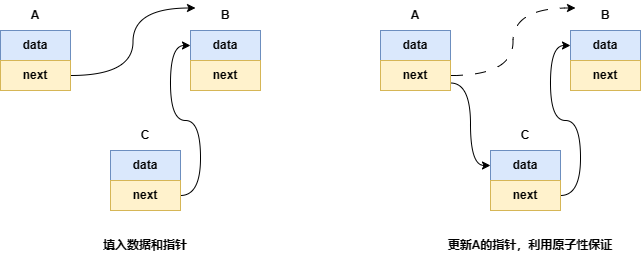
-
第一步就是初始化节点了C,然后让C的指向了B
-
第二步则是通过更新节点A的指针,指向了C,此时因为原子性的保证,即操作的结果被读者读到只可能是读前和读后.
因此如果是读前的状态,则依然是记录了B,读后则记录了新插入的结点可以遍历到C,而当读者去遍历A结点的时候,查找下一个结点这个操作就是
订阅,而发布则是通过更新A的指针操作来实现,因此他们的本质实际上是一种读写操作
3.宽限期
宽限期是什么?
之前我们聊过在回收阶段,RCU会延迟回收,而就是基于这个回收期,因为旧的数据不能排除还有读者在使用的情况,因此为了确定何时能够回收这个资源,RCU引入了一个叫宽限期的概念.
- 而宽限期的长度,是一个应该去权衡的问题:
- 例如读者操作的时间会影响宽限期的长度
- 系统的负载和性能需求,宽限期太长对于系统的负载来说也比较高.
因此,合理的去设置宽限期是一个权衡考虑的结果,根据具体的应用需求,性能要求来真正决定.
为此RCU为读者提供了两个接口rcu_read_lock和,rcu_read_unlock去分别标记读临界区的开始和结束,这里并不是意味着用加锁的方式去保护临界区,其具体的实现由于本人能力不足,而RCU的机制在Linux2.5版本及以上才慢慢出现.
同样RCU也会为写者提供接口synchronize_rcu,用于阻塞写者等到宽限期结束.其RCU的内部具体实现还需要去参考Linux源码理解.