6.Eclipse 连接 Hadoop
任务目的
- 掌握在 Linux 下 Eclipse 连接 Hadoop 的详细步骤
- 掌握获取 fs 对象的两种方式
任务清单
- 任务1:Linux 下 Eclipse 连接 Hadoop
- 任务2:FileSystem 实例获取
详细任务步骤
任务1:Linux 下 Eclipse 连接 Hadoop
1. 首先启动 Hadoop 集群;
2. 下载并安装 Eclipse 开发工具,此平台在 /root/software 目录下已经为大家安装好了 Eclipse,所以无需再重复安装;
3. 下载 hadoop-eclipse-plugin-2.7.7.jar 包,将其放入到 eclipse 安装目录下的 plugins 文件夹下,即放在/root/software/eclipse/plugins 文件夹下,此步骤在平台上也已经做好,无需再做;
4. 双击桌面的“Eclipse”图标启动 Eclipse,首次启动 Eclipse 时,会弹出“Eclipse IDE Launcher”的对话框,提示设置 Workspace 的路径,设定好路径后,倘若勾选了“Use this as the default and do not ask again”,那么以后再启动时就不会有提示,直接进入默认工作空间:
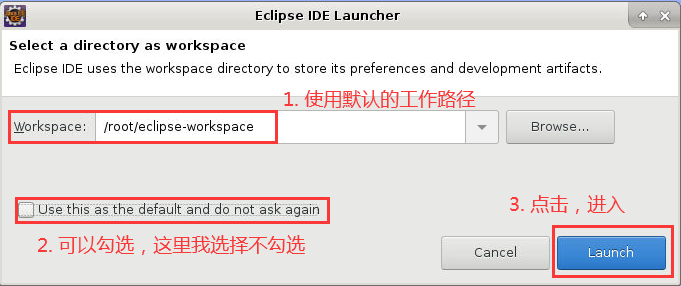
图1
5. 进入 Eclipse 后,因为是首次打开,所以会看到一个“Welcome”欢迎页,将其关掉即可:
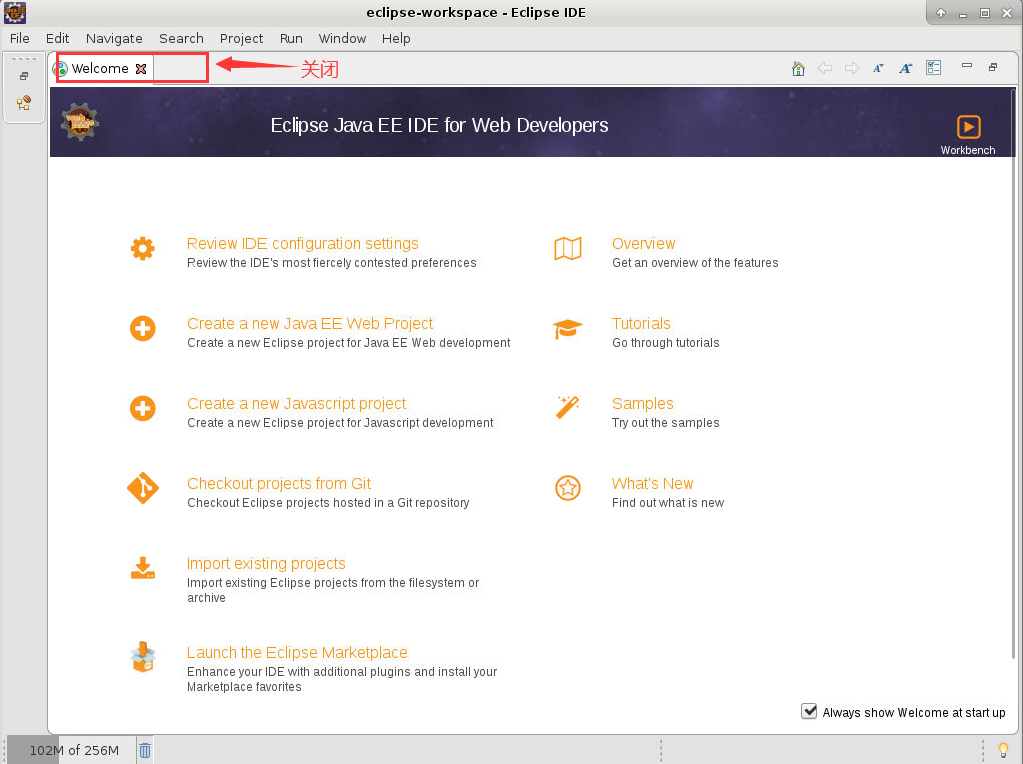
图2
6. 之后点击“Window”->“Preferences”,此时会弹出如下对话框:
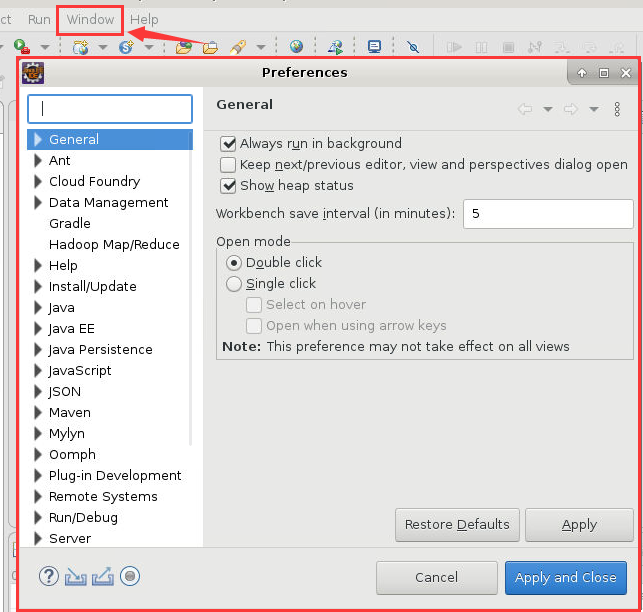
图3
7. 在对话框的左侧找到“Hadoop Map/Reduce”选项,hadoop-2.7.7 的安装路径配置在此选项中,然后依次单击“Apply”->“Apply and Close”,如下图所示:
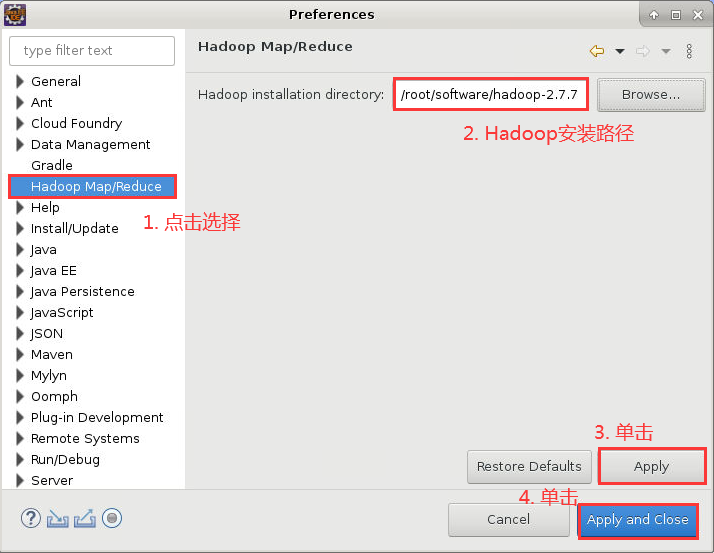
图4
8. 之后点击“Window”->“Show View”->“Other”,弹出“Show View”对话框,选中“MapReduce Tools”下的“Map/Reduce Locations”,然后点击“Open”,关闭对话框:
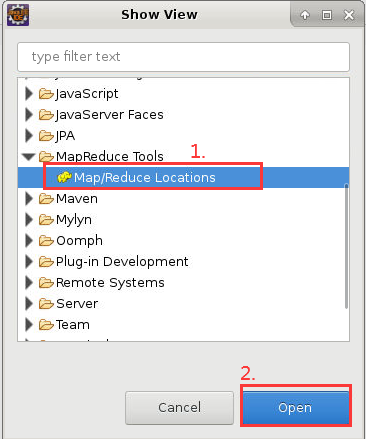
图5
9. 此时在 Eclipse 底部出现“Map/Reduce Locations”窗口,选择其右边的蓝色小象图标,如下所示:
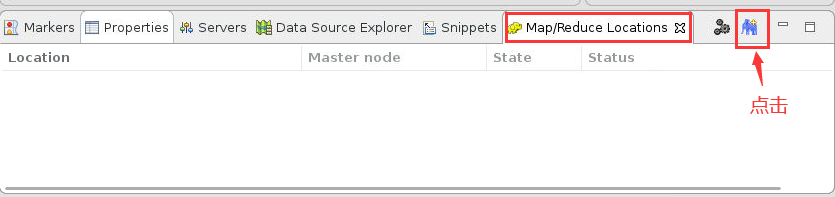
图6
10. 点击蓝色小象图标后,弹出“New Hadoop locaiton...”对话框,其中,“Location name”可以随意命名,这里我写成“myhadoop”;之后是“Map/Reduce(V2)Master”,将“Host”修改为YARN集群主节点的IP地址或主机名,这里我填写“localhost”;之后再看“DFS Master”,将“Host”修改为HDFS集群主节点的IP地址或主机名,将“Port”修改为9000,与我们在core-site.xml中设置fs.defaultFS选项的一致;最后是“User name”,此处的用户名为搭建Hadoop集群的用户,即root。设置完成,点击“Finish”即可。
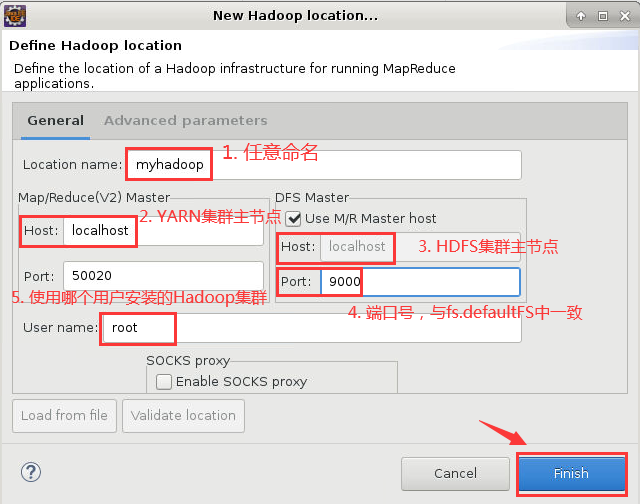
图7
11. 此时在 Eclipse 底部“Map/Reduce Locations”窗口中会出现如下信息:
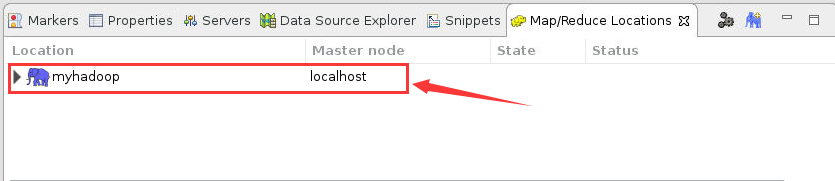
图8
12. 之后选择“File”->“New”->“Project”->“Map/Reduce Project”->“Next”,弹出“New MapReduce Project Wizard”对话框,为“Project name”起个名字,可以任意取名:
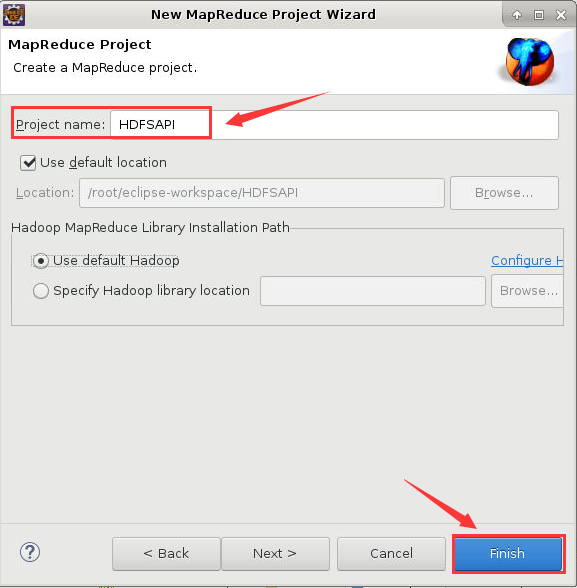
图9
13. 之后弹出“Open Associated Perspective”对话框,直接点击“No”即可:
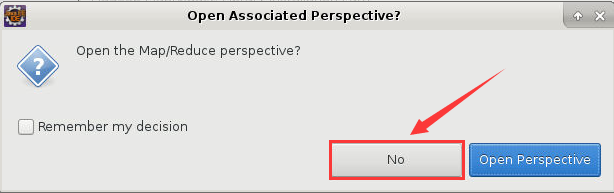
图10
14. 此时在Eclipse 的左侧“Project Explorer”下看到我们新创建的项目和“DFS Locations”列表栏,打开此列表栏,验证 Eclipse 是否连接成功 Hadoop,如果能正确显示 HDFS 上的文件和目录说明配置成功:
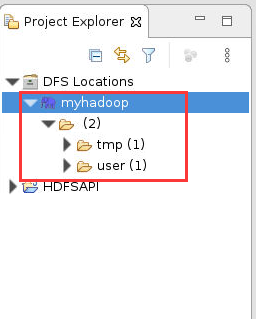
图11
任务2:FileSystem 实例获取
2.1 Configuration类简介
1. Configuration 是什么?
Configuration 作为 Hadoop 的一个基础功能承担着重要的责任,为 YARN、HDFS、MapReduce 等提供参数的配置、配置文件的分布式传输(实现了 Writable 接口)等重要功能。
2. 为什么使用它?
Hadoop 没有使用 java.util.Properties(Java 中的)管理配置文件,而是使用了一套独有的配置文件管理系统,并提供自己的 API,即使用 org.apache.hadoop.conf.Configuration 处理配置信息。
Configuration 是 Hadoop 的公用类,所以放在了 core 下,org.apache.hadoop.conf.Configruration。这个类是作业的配置信息类,任何作用的配置信息必须通过 Configuration 传递,因为通过 Configuration 可以实现在多个 mapper 和多个 reducer 任务之间共享信息。
3. 如何使用它?
使用 Configuration 类的一般过程是:构造 Configuration 对象,并通过类的addResource()方法添加需要加载的资源;然后就可以使用get()或set()方法访问或设置配置项,资源会在第一次使用的时候自动加载到对象中。
Configuration conf=new Configuration();
conf.addResource("core-default.xml");
conf.addResource("core-site.xml");
conf.set("fs.defaultFS", "hdfs://localhost:9000");
上述示例中,我们加载了两个配置资源,这两个配置资源包含了相同的配置项,此时,后面的配置将覆盖前面的配置,即 core-site.xml 中的配置将覆盖 core-default.xml 中的同名配置。
之后我们使用set()方法设置了“fs.defaultFS”配置项,此项将覆盖 core-site.xml 或 core-default.xml 配置项中的同名配置。
2.2 FileSystem 实例
为了为不同的文件系统提供一个统一的接口,Hadoop 提供了一个抽象的文件系统,而 Hadoop 分布式文件系统(Hadoop Distributed File System, HDFS)只是这个抽象文件系统的一个具体实现。Hadoop 抽象文件系统接口主要由抽象类 org.apache.hadoop.fs.FileSystem 提供,其继承的层次结构如下图所示:
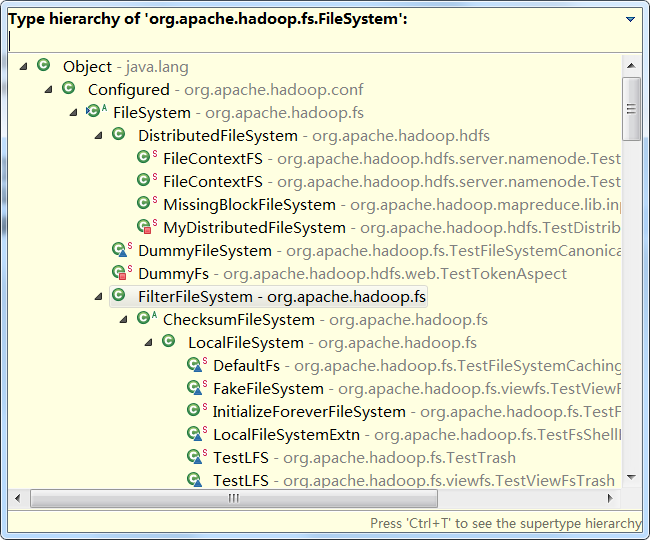
图12
从上图可以看出,Hadoop 发行包中包含了不同的 FileSystem 子类,以满足不同得到数据访问需求。
其主要提供的方法可以分为两部分:一部分用于处理文件和目录相关的事务;另一部分用于读写文件数据。其中处理文件和目录主要是指创建文件,创建目录,删除文件,删除目录等操作,读写数据文件主要是指读文件数据,写入文件数据等操作。
2.3 获取 FileSystem 实例
客户端获取 FileSystem 的 DistributedFileSystem 对象,客户端要构造 FileSystem 对象可以使用 FileSystem.get() 方法,该方法有3个重载方法:

图13
方式一:通过配置来获取fs对象
在 Java 中要想操作 HDFS,首先要获取一个客户端实例:
Configuration conf=new Configuration();
FileSystem fs=FileSystem.get(conf);
因为我们的操作目标是 HDFS,所以这里获取到的 fs 对象应该是 DistributedFileSystem 的实例。
那么,get 方法是从何处判断具体实例化哪种客户端类呢?
--从 conf 中的一个参数 fs.defaultFS 的配置值判断。
如果我们的代码中没有指定 fs.defaultFS,并且工程 classpath 下也没有给定相应的配置,conf 中的默认值就来自于 hadoop 的 jar 包中的 core-default.xml,默认值为file:///,此时获取的将不是一个 DistributedFileSystem 的实例,而是一个本地文件系统的客户端对象。
完整示例如下所示:
package com.hongyaa.hdfs;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class HDFSDemo {
public static void main(String[] args) throws IOException {
Configuration conf=new Configuration();
//如果我们没有给 conf 设置文件系统,那么 fileSystem 默认获取的是本地文件系统的一个实例
//若是我们设置了“fs.defaultFS”参数,这表示获取的是该 URI 的文件系统的实例,就是我们需要的 HDFS 集群的一个 fs 对象
conf.set("fs.defaultFS", "hdfs://localhost:9000");
FileSystem fs=FileSystem.get(conf);
System.out.println(fs.getUri());
}
}
执行结果如下:

图14
方式二:直接获取fs对象
package com.hongyaa.hdfs;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
public class HDFSDemo {
public static void main(String[] args) throws InterruptedException, URISyntaxException, IOException {
Configuration conf = new Configuration();
// 不需要配置“fs.defaultFS”参数,直接传入URI和用户身份,最后一个参数是安装Hadoop集群的用户,我的是“root”
FileSystem fs = FileSystem.get(new URI("hdfs://localhost:9000"), conf, "root");
System.out.println(fs.getUri());
}
}
执行结果如下:
图15
标签:,fs,Eclipse,Hadoop,conf,FileSystem,Configuration From: https://www.cnblogs.com/Cuckoo123456/p/17470434.html