SQL试题一
现在有以下一个数据表
| 字段名称 | 备注 |
|---|---|
| id | 唯一ID |
| date | 日期(分区字段) |
| reg_time | 注册时间(时间戳) |
| leave_time | 注销时间(时间戳) |
请用一个sql计算2022年1月-2022年2月期间每天注册用户次日留存率?
举个例子:
0101注册用户20人,0101注册用户在0102注销用户10人,次日留存率=10/20
0102注册用户30人,0102注册用户在0103注销用户20人,次日留存率=10/30
数据举例:
1 20220101 1641016622 1641130749
2 20220101 1641016622 1641343149
3 20220101 1641016622 1641130749
4 20220101 1641016622 1641343149
5 20220101 1641016622 1641130749
6 20220101 1641016622 1641170349
7 20200102 1641083949 1641170349
8 20200102 1641083949 1641515949
9 20200102 1641083949 1641170349
10 20200102 1641083949 1641515949
11 20220101 1641016622 1641515949
select `date` , cast(sum(if(datediff(from_unixtime(cast (leave_time as bigint) ,"yyyy-MM-dd"),from_unixtime(cast (reg_time as bigint) ,"yyyy-MM-dd"))>1,1,0))/count(*) as decimal(5,2)) as rt from temp group by `date`;
1.2 SQL试题二
使用SQL选出下表中6个指标中至少4个指标大于等于50的城市。
| local | oc | sc | pc | hc | gc | ghc |
|---|---|---|---|---|---|---|
| 青岛 | 96 | 50 | 56 | 55 | 43 | 21 |
| 北京 | 74 | 16 | 96 | 29 | 54 | 4 |
| 南京 | 5 | 52 | 18 | 82 | 18 | 83 |
SQL: select local from temp where if(oc >=50,1,0) + if(sc>=50,1,0)+if....... >=4;
1.3 SQL试题三
目前爬虫拿到的数据形成两张表,一张是行业表,另一张是商品表,需要清洗出每个行业对应的(月销售额子行业的销售额需要加总到对应的父行业)。
行业表 category:(json格式数据)
| 行业id | 父行业pid | 行业名称cg_name |
|---|---|---|
| 1 | 服装 | |
| 2 | 1 | 女装 |
| 3 | 2 | 时尚女装 |
| 4 | 1 | 男装 |
| 5 | 4 | 商务男装 |
商品表item:(json格式数据)
| 商品item_id | 商品行业item_cg_id | 销售日期sale_dt | 销售额sale |
|---|---|---|---|
| id1 | 3 | 20220102 | 100 |
| id2 | 2 | 20220104 | 200 |
| id3 | 5 | 20220201 | 3000 |
请使用Spark进行数据处理,java,scala都可以。最终得到各行业的月销售表(注意行业有层级关系,子行业的数据需要汇总到父行业)
| 行业名称 | 行业id | 月份 | 销售额 |
|---|---|---|---|
| 女装 | 2 | 202201 | 300 |
| 服装 | 1 | 202201 | 300 |
| 时尚女装 | 3 | 202201 | 100 |
| 商务男装 | 5 | 202202 | 3000 |
| 男装 | 4 | 202202 | 3000 |
| 服装 | 1 | 202202 | 3000 |
category.txt
{"id":1,"pid":"","cg_name":"服装"}
{"id":2,"pid":1,"cg_name":"女装"}
{"id":3,"pid":2,"cg_name":"时尚女装"}
{"id":4,"pid":1,"cg_name":"男装"}
{"id":5,"pid":4,"cg_name":"商务男装"}
item.txt
{"item_id":1,"item_cg_id":3,"sale_dt":"20220102","sale":100}
{"item_id":2,"item_cg_id":2,"sale_dt":"20220104","sale":200}
{"item_id":3,"item_cg_id":5,"sale_dt":"20220201","sale":3000}
实现代码:
package com.lw.scalaspark
import org.apache.spark.sql.{DataFrame, SparkSession}
import scala.collection.mutable.ListBuffer
object temp {
def main(args: Array[String]): Unit = {
val spark: SparkSession = SparkSession.builder().master("local")
.appName("test")
.getOrCreate()
spark.sparkContext.setLogLevel("Error")
val categroyDF: DataFrame = spark.read.json("./data/tempdata/category.txt")
val itemDF: DataFrame = spark.read.json("./data/tempdata/item.txt")
categroyDF.printSchema()
itemDF.printSchema()
import spark.implicits._
categroyDF.createTempView("categroy")
itemDF.createTempView("item")
//准备父id及子ID Map
val categoryMap: Map[String, String] = categroyDF.select("id","pid").as[(String,String)].collect().toMap
categoryMap.foreach(println)
spark.udf.register("myudf",(cgId:String)=>{
//根据cgId 找出所有的父cgid
val pidsList: ListBuffer[String] = ListBuffer[String]()
pidsList.append(cgId)
//遍历寻找父cgid
def getPid(currentCgId:String): ListBuffer[String] ={
val pid: String = categoryMap.get(currentCgId).get
if(pid == null){
pidsList
}else{
pidsList.append(pid)
getPid(pid)
}
}
getPid(cgId)
})
//最终SQL
spark.sql(
"""
| select
| item_id,sale_dt,sale,explode(myudf(item_cg_id)) as new_item_cgid
| from item
""".stripMargin).createTempView("new_item_tbl")
spark.sql(
"""
| select
| a.new_item_cgid,b.cg_name,from_unixtime(unix_timestamp(a.sale_dt,"yyyyMMdd"),"yyyy-MM") as dt,
| sum(sale) as totalSum
| from new_item_tbl a join categroy b on a.new_item_cgid = b.id
| group by a.new_item_cgid,b.cg_name,dt
""".stripMargin).show()
}
}
1.4 MR&Spark&Flink区别
1.4.1 MR、Spark介绍
MapReduce编程模型只包含Map和Reduce两个过程,map的主要输入是一对<Key, Value>值,经过map计算后输出一对<Key, Value>值;然后将相同Key合并,形成<Key, Value集合>,再将这个<Key, Value集合>输入reduce,经过计算输出零个或多个<Key, Value>对。
MapReduce运行的时候,会通过Mapper运行的任务读取数据文件,然后调用自己的方法,处理数据,最后输出。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法,最后输出到相应的文件中。
MR具体处理数据流程是:Input Data -> MR -> Output Data ->MR ->Output Data。在MapReduce流程里,第一个MR的输出要先落地,然后第二个MR才能把第一个MR的输出当做输入,进行第二次MR。如果有多个MR流式作业,消耗的时间也就会随之增加。这是MapReduce执行较其他框架慢的重要原因之一。
Apache Spark的高性能一定程度上取决于它采用的异步并发模型(这里指server/driver 端采用的模型),这与Hadoop 2.0(包括YARN和MapReduce)是一致的。Hadoop MapReduce采用了多进程模型,而Spark采用了多线程模型。
Spark采用了经典的scheduler/workers模式,每个Spark应用程序运行的第一步是构建一个可重用的资源池,然后在这个资源池里运行所有的ShuffleMapTask和ReduceTask。而MapReduce应用程序则不同,它不会构建一个可重用的资源池,而是让每个Task动态申请资源,且运行完后马上释放资源。
1.4.2 MR&Spark&Flink比较
- MR基于磁盘迭代处理数据,Spark可以基于内存处理数据,可以对数据进行持久化,对迭代或者多次重复处理同一数据源非常高效。
- Spark 中持久化默认的数据只有一份,MR中数据处理基于HDFS,默认副本有3个
- Spark中支持批数据处理,支持流式数据处理,支持SQL处理数据,MR只支持批数据处理
- Spark中封装了各种高级的算子,代码编写方便,MR中需要自己实现复杂逻辑
- Spark是粗粒度资源申请,MR是细粒度资源申请
Flink和Spark有很多相似点,也有很多不同点,相似点如下:
- 都基于内存计算,Spark数据可以持久化,Flink状态可以基于内存计算
- 都可以处理批和流数据,都支持SQL处理数据。
- 都有很多转换操作。Flink支持底层 api操作,Spark不支持。
- 都有完善的错误恢复机制。
- 读取Kafka都支持Exactly once语义一致性。
不同点主要是针对流式数据处理上不同,具体如下:
一、设计理念
- Spark的技术理念是使用微批来模拟流的计算,基于Micro-batch,数据流以时间为单位被切分成一个个批次,通过分布式数据集RDD进行批量处理,是一种伪实时。
- Flink是基于事件驱动的,是面向流的处理框架,Flink基于每个事件一行一行地进行流式处理,是真正的流式计算,也可以基于流来进行批计算,实现批处理。
Spark流处理划分成微批处理,Flink批是流的特例,Spark流式数据处理延迟只能做到秒级,Flink基于每个事件处理,每当有新数据进来都会立刻处理,是真正的实时计算,延迟毫秒级别。
二、吞吐量与延迟
- SparkStreaming是基于微批的,吞吐量大,延迟高,一般是秒级
- Flink基于事件,消息逐条处理,兼顾吞吐量的同时有很低的延迟,延迟可以达到毫秒级。
三、架构方面:
- Spark在运行时主要角色包括:Master、Worker、Driver、Executor
- Flink在运行时主要包含:JobManager、TaskManger和Slot
四、任务调度
- SparkStreaming,连续不断的生成微批构建有向无环图DAG,根据DAG中的action操作形成job,每个job有根据宽窄依赖生成多个stage。
- Flink根据用户提交的代码生成StreamGraph,经过优化生成JobGraph,然后提交给JobManager进行处理,JobManager会根据JobGraph生成ExecutionGraph,ExecutionGraph是Flink调度最核心的数据结构,JobManager根据ExecutionGraph对job进行调度。
五、时间机制
- SparkStreaming支持的时间机制有限、只支持处理时间,StructuredStreaming支持事件时间,支持watermark。
- Flink支持三种时间机制:事件时间、注入时间、处理时间,同时支持watermark机制处理迟到数据。
六、窗口方面
Spark只支持基于时间的窗口操作(处理时间或者事件时间),而Flink支持的窗口非常灵活(time,count,session),支持时间窗口,还支持基于数据本身的窗口,也可以自定义窗口。
七、状态
Flink比Spark支持更多的状态操作。
Flink中状态更丰富,基于每个key都可以灵活维护状态,也可以针对业务自定义状态等,编码时可以自己操作状态。处理流式数据时,在Flink中可以设置checkpoint,当Flink任务失败后,重启的Flink任务可以基于checkpoint来恢复任务。
Spark利用checkpoint来实现Spark处理内部的状态管理。处理流式数据时,SparkStreaming不支持任务重启后从checkpoint中回复状态,StructuredStreaming可以支持。
八、容错机制
Flink基于轻量级分布式快照(Snapshot)实现容错,Spark容错机制基于RDD的容错机制,Spark内部可以使用持久化算子和checkpoint来实现数据容错和保存状态。
实时消费Kafka数据时,想要做到精准消费一次数据(exactly-once),Flink基于两阶段提交实现,SparkStreaming需要手动维护offset来保证,StructuredStreaming只支持at-least-once语义。
1.5 Spark读取Kafka中数据如何保证数据消费一致性?
1.5.1 Receiver模式(了解)
在早期Spark消费Kafka中数据只支持Receiver模式。
Receiver模式中,SparkStreaming使用Receiver接收器模式来接收kafka中的数据,即会将每批次数据都存储在Spark端,默认的存储级别为MEMORY_AND_DISK_SER_2,从Kafka接收过来数据之后,还会将数据备份到其他Executor节点上,当完成备份之后,再将消费者offset数据写往zookeeper中,然后再向Driver汇报数据位置,Driver发送task到数据所在节点处理数据。
这种模式使用zookeeper来保存消费者offset,等到SparkStreaming重启后,从zookeeper中获取offset继续消费。
当Driver挂掉时,同时消费数据的offset已经更新到zookeeper中时,SparkStreaming重启后,接着zookeeper存储的offset继续处理数据,这样就存在丢失数据的问题。
为了解决以上丢失数据的问题,可以开启WAL(write ahead log)预写日志机制,将从kafka中接收来的数据备份完成之后,向指定的checkpoint中也保存一份,这样当SparkStreaming挂掉,重新启动再处理数据时,会处理Checkpoint中最近批次的数据,将消费者offset继续更新保存到zookeeper中。
开启WAL机制,需要设置checpoint,由于一般checkpoint路径都会设置到HDFS中,HDFS本身会有副本,所以这里如果开启WAL机制之后,可以将接收数据的存储级别降级,去掉“_2”级别。
开启WAL机制之后带来了新的问题:
- 数据重复处理问题
由于开启WAL机制,会处理checkpoint中最近一段时间批次数据,这样会造成重复处理数据问题。所以对于数据需要精准消费的场景,不能使用receiver模式。如果不开启WAL机制Receiver模式有丢失数据的问题,开启WAL机制之后有重复处理数据的问题,对于精准消费数据的场景,只能人为保存offset来保证数据消费的准确性。
- 数据处理延迟加大问题
数据在节点之间备份完成后再向checkpoint中备份,之后再向Zookeeper汇报数据offset,向Driver汇报数据位置,然后Driver发送task处理数据。这样加大了数据处理过程中的延迟。
对于精准消费数据的问题,需要我们从每批次中获取offset然后保存到外部的数据库来实现来实现仅一次消费数据。但是Receiver模式底层读取Kafka数据的实现使用的是High Level Consumer Api,这种Api不支持获取每批次消费数据的offset。所以对于精准消费数据的场景不能使用这种模式。
Receiver模式总结
- Receiver模式采用了Receiver接收器的模式接收数据。会将每批次的数据存储在Executor内存或者磁盘中。
- Receiver模式有丢失数据问题,开启WAL机制解决,但是带来新的问题。
- receiver模式依赖zookeeper管理消费者offset。
- SparkStreaming读取Kafka数据,相当于Kafka的消费者,底层读取Kafka采用了“High Level Consumer API”实现,这种api没有提供操作每批次数据offset的接口,所以对于精准消费数据的场景想要人为控制offset是不可能的。
1.5.2 Direct模式
在Spark1.6版本引入了Dircet模式。
Driect模式就是将kafka看成存数据的一方,这种模式没有采用Receiver接收器模式,而是采用直连的方式,不是被动接收数据,而是主动去取数据,当任务失败后代码中如果设置了checkpoint目录,那么最近消费Kafka批次信息也会保存在checkpoint中。当SparkStreaming停止后,我们可以使用val ssc = StreamFactory.getOrCreate(checkpointDir,Fun)来恢复停止之前SparkStreaming处理数据的进度,当然,这种方式存在重复消费数据和逻辑改变之后不可执行的问题。
Direct模式底层读取Kafka数据实现是Simple Consumer api实现,这种api提供了从每批次数据中获取offset的接口,所以对于精准消费数据的场景,可以使用Direct 模式手动维护offset方式来实现数据精准消费。
此外,Direct模式的并行度与当前读取的topic的partition个数一致,所以Direct模式并行度由读取的kafka中topic的partition数决定的。
如何保证消费Kafka数据offset精准性?
- checkpoint管理
如果设置了checkpoint ,那么最近消费批次数据会存储在checkpoint中。这种有缺点: 第一,当从checkpoint中恢复数据时,有可能造成重复的消费。第二,当代码逻辑改变时,无法从checkpoint中来恢复offset.
- 依赖Kafka存储
依靠kafka 来存储消费者offset,kafka 中有一个特殊的topic 来存储消费者offset。新的消费者api中,会定期自动提交offset。这种情况有可能也不是我们想要的,因为有可能消费者自动提交了offset,但是后期SparkStreaming 没有将接收来的数据及时处理保存。这里也就是为什么会在配置中将enable.auto.commit 设置成false的原因。这种消费模式也称最多消费一次(at-most-once),默认sparkStreaming 拉取到数据之后就可以更新offset,无论是否消费成功,自动提交offset的频率由参数auto.commit.interval.ms 决定,默认5s。
如果我们能保证完全处理完业务之后,可以后期异步的手动提交消费者offset。但是这种将offset存储在kafka中由参数offsets.retention.minutes=1440控制是否过期删除,默认是保存一天,如果停机没有消费达到时长,存储在kafka中的消费者组会被清空,offset也就被清除了。
- 手动维护
自己存储offset,这样在处理逻辑时,保证数据处理的事务,如果处理数据失败,就不保存offset,处理数据成功则保存offset.这样可以做到精准的处理一次处理数据。
1.6 Flink两阶段提交原理?
1.6.1 Flink消费Kafka 数据offset维护方式
Flink提供了消费kafka数据的offset如何提交给Kafka或者zookeeper(kafka0.8之前)的配置。注意,Flink并不依赖提交给Kafka或者zookeeper中的offset来保证容错。提交的offset只是为了外部来查询监视kafka数据消费的情况。
配置offset的提交方式取决于是否为job设置开启checkpoint。可以使用env.enableCheckpointing(5000)来设置开启checkpoint。
- 关闭checkpoint:
如果何禁用了checkpoint,那么offset位置的提交取决于Flink读取kafka客户端的配置,enable.auto.commit ( auto.commit.enable【Kafka 0.8】)配置是否开启自动提交offset, auto.commit.interval.ms决定自动提交offset的周期。
- 开启checkpoint:
如果开启了checkpoint,那么当checkpoint保存状态完成后,将checkpoint中保存的offset位置提交到kafka。这样保证了Kafka中保存的offset和checkpoint中保存的offset一致,可以通过配置setCommitOffsetsOnCheckpoints(boolean)来配置是否将checkpoint中的offset提交到kafka中(默认是true)。如果使用这种方式,那么properties中配置的kafka offset自动提交参数enable.auto.commit和周期提交参数auto.commit.interval.ms参数将被忽略。
1.6.2 使用checkpoint+两阶提交保证仅一次消费Kafka中数据
当谈及“exactly-once semantics”仅一次处理数据时,指的是每条数据只会影响最终结果一次。Flink可以保证当机器出现故障或者程序出现错误时,也没有重复的数据或者未被处理的数据出现,实现仅一次处理的语义。Flink开发出了checkpointing机制,这种机制是在Flink应用内部实现仅一次处理数据的基础。
checkpoint中包含:
- 当前应用的状态
- 当前消费流数据的位置
在Flink1.4版本之前,Flink仅一次处理数据只限于Flink应用内部(可以使用checkpoint机制实现仅一次数据数据语义),当Flink处理完的数据需要写入外部系统时,不保证仅一次处理数据。为了提供端到端的仅一次处理数据,在将数据写入外部系统时也要保证仅一次处理数据,这些外部系统必须提供一种手段来允许程序提交或者回滚写入操作,同时还要保证与Flink的checkpoint机制协调使用。
在分布式系统中协调提交和回滚的常见方法就是两阶段提交协议。下面给出一个实例了解Flink如何使用两阶段提交协议来实现数据仅一次处理语义。
该实例是从kafka中读取数据,经过处理数据之后将结果再写回kafka。kafka0.11版本之后支持事务,这也是Flink与kafka交互时仅一次处理的必要条件。【注意:当Flink处理完的数据写入kafka时,即当sink为kafka时,自动封装了两阶段提交协议】。Flink支持仅一次处理数据不仅仅限于和Kafka的结合,只要sink提供了必要的两阶段协调实现,可以对任何sink都能实现仅一次处理数据语义。
其原理如下:
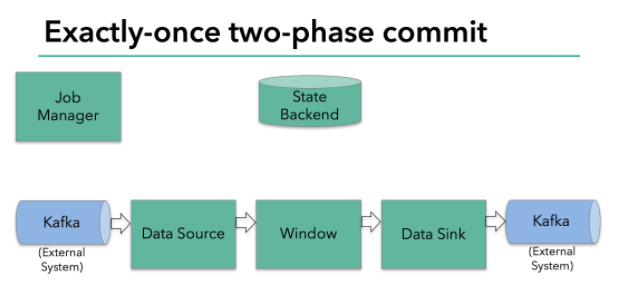
上图Flink程序包含以下组件:
- 一个从kafka中读取数据的source
- 一个窗口聚合操作
- 一个将结果写往kafka的sink。
要使sink支持仅一次处理数据语义,必须以事务的方式将数据写往kafka,将两次checkpoint之间的操作当做一个事务提交,确保出现故障时操作能够被回滚。假设出现故障,在分布式多并发执行sink的应用程序中,仅仅执行单次提交或回滚事务是不够的,因为分布式中的各个sink程序都必须对这些提交或者回滚达成共识,这样才能保证两次checkpoint之间的数据得到一个一致性的结果。Flink使用两阶段提交协议(pre-commit+commit)来实现这个问题。
Filnk checkpointing开始时就进入到pre-commit阶段 ,具体来说,一旦checkpoint开始,Flink的JobManager向输入流中写入一个checkpoint barrier将流中所有消息分隔成属于本次checkpoint的消息以及属于下次checkpoint的消息,barrier也会在操作算子间流转,对于每个operator来说,该barrier会触发operator的State Backend来为当前的operator来打快照。如下图示:
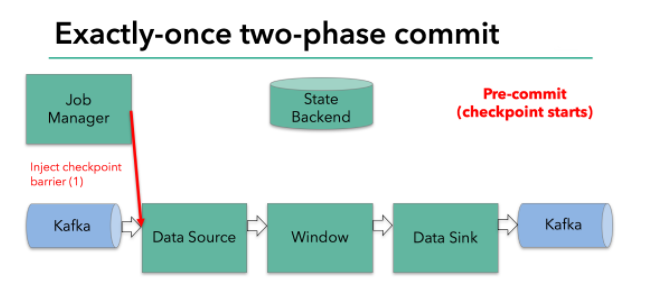
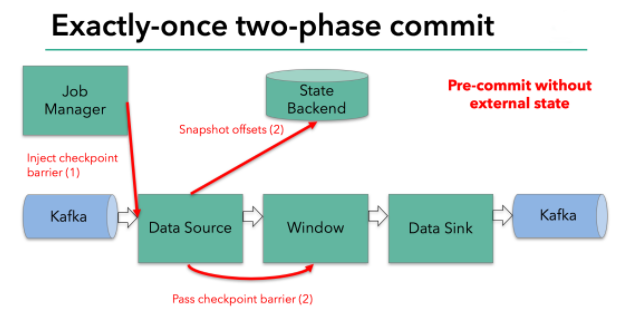
Flink DataSource中存储着Kafka消费的offset,当完成快照保存后,将chechkpoint barrier传递给下一个operator。这种方式只有在Flink内部状态的场景是可行的,内部状态指的是由Flink的State Backend管理状态,例如上面的window的状态就是内部状态管理。只有当内部状态时,pre-commit阶段无需执行额外的操作,仅仅是写入一些定义好的状态变量即可,checkpoint成功时Flink负责提交这些状态写入,否则就不写入当前状态。
但是,一旦operator操作包含外部状态,事情就不一样了。我们不能像处理内部状态一样处理外部状态,因为外部状态涉及到与外部系统的交互。这种情况下,外部系统必须要支持可以与两阶段提交协议绑定的事务才能保证仅一次处理数据。
本例中的data sink是将数据写往kafka,因为写往kafka是有外部状态的,这种情况下,pre-commit阶段下data sink 在保存状态到State Backend的同时,还必须pre-commit外部的事务。如下图:
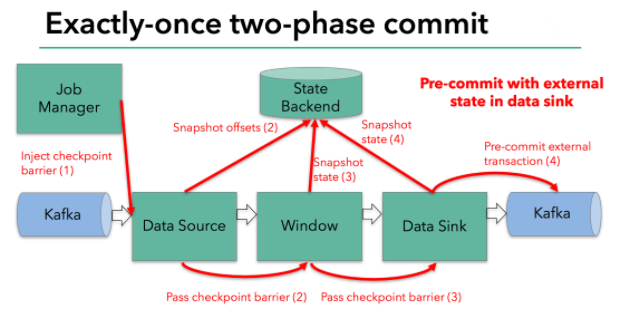
当checkpoint barrier在所有的operator都传递一遍切对应的快照都成功完成之后,pre-commit阶段才算完成。这个过程中所有创建的快照都被视为checkpoint的一部分,checkpoint中保存着整个应用的全局状态,当然也包含pre-commit阶段提交的外部状态。当程序出现崩溃时,我们可以回滚状态到最新已经完成快照的时间点。
下一步就是通知所有的operator,告诉它们checkpoint已经完成,这便是两阶段提交的第二个阶段:commit阶段。这个阶段中JobManager会为应用中的每个operator发起checkpoint已经完成的回调逻辑。本例中,DataSource和Winow操作都没有外部状态,因此在该阶段,这两个operator无需执行任何逻辑,但是Data Sink是有外部状态的,因此此时我们需要提交外部事务。如下图示:
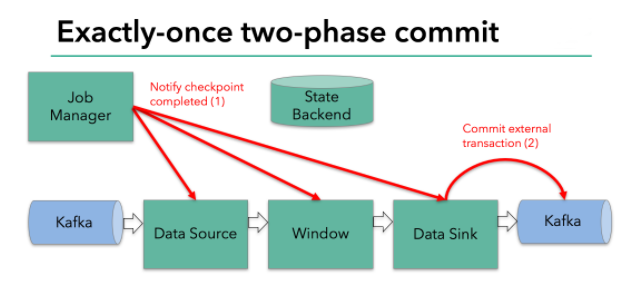
汇总以上信息,总结得出:
l 一旦所有的operator完成各自的pre-commit,他们会发起一个commit操作。
l 如果一个operator的pre-commit失败,所有其他的operator 的pre-commit必须被终止,并且Flink会回滚到最近成功完成的checkpoint位置。
l 一旦pre-commit完成,必须要确保commit也要成功,内部的operator和外部的系统都要对此进行保证。假设commit失败【网络故障原因】,Flink程序就会崩溃,然后根据用户重启策略执行重启逻辑,重启之后会再次commit。
因此,所有的operator必须对checkpoint最终结果达成共识,即所有的operator都必须认定数据提交要么成功执行,要么被终止然后回滚。
标签:24,处理,老师,Flink,checkpoint,面试,offset,Spark,数据 From: https://www.cnblogs.com/shan13936/p/17468196.html