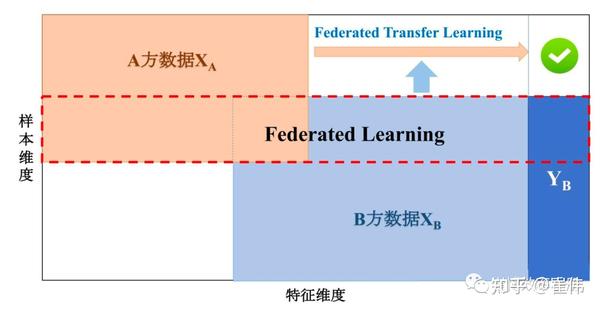
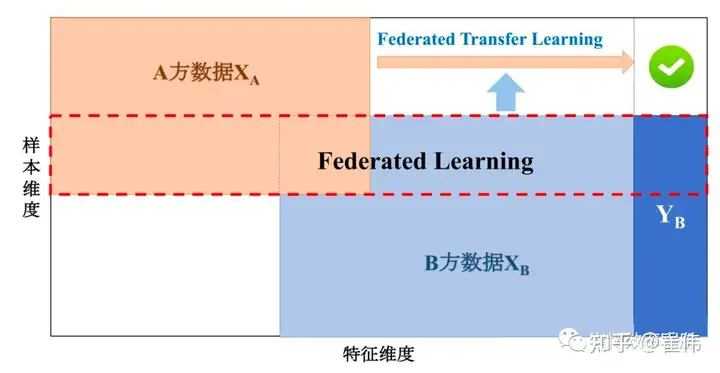
大家可能知道,我们目前常用的人工智能应用(例如人脸识别、语音识别、图像识别、智能推荐等)已经相当成熟,它们通常都依赖于大量的训练样本。也就是说,已知一个X(“样本”),要判别它是否具备Y(“特征”),我们需要大量已知的X、Y来反复训练我们的模型(这个过程叫做“学习”)。 很多企业、组织,通过各种方式采集到了这样的数据样本,在内部进行训练,不断优化自己的模型(常见的如神经网络)。样本越多,预测就可能越精确,这是很多互联网公司都非常热衷于获取用户数据的原因。 但是在很多时候,这些数据样本是分散在多个地方,由不同机构持有的。 譬如一家银行,希望分析自己客户的贷款能力,它希望和保险公司(有客户的保险数据)、互联网公司(有客户的上网行为数据)等合作,汇聚更多的样本和特征信息,这样自己的模型就会更加精确。但是,因为法律规定和商业竞争的要求,这些保险公司、互联网公司显然不希望把自己的数据交出去(这就叫做“数据孤岛”),但是它们可能也都希望通过汇总更多的数据来优化自己的模型。 这时候怎么办呢? “联邦学习”(Federated Learning, FL)就是为了解决这个问题,即让互相不信任的各方,可以把样本和特征汇聚到一起,共同获得更好的预测模型。或者说白了,就是大家联起手来学习。 二、“联邦学习” 是怎么实现的? “联邦学习”主要分为三种,下面概要讲讲它们的实现方法。 1、横向联邦学习 如果是几家业务类似的机构进行合作,也就是它们需要学习、预测的特征是类似的,但是用户、样本是不同的,例如一个地区的不同银行之间,他们各有各的客户,但是需要分析的数据特征都是存款额度、贷款额度等,那么它们之间的合作,就叫做“横向联邦学习”(HFL)。 它的实现方法如下图所示,简单来说就是五个步骤: 你看,就是这么简单。通过这种方式,实现了几个目的: 这就叫做“数据可用不可见,数据不跑模型跑”。 这种方式适用于同类机构之间的合作,例如银行之间联合建立风控模型,医院之间联合开发诊断模型,政府部门之间联合开发政务管理模型等。 2、纵向联邦学习 另外一种情况,则是组织的客户群体是类似的,但是特征并不相同。譬如有一家银行和一家保险公司同在一个城市,它们的客户群体很多是重合的,但是银行的数据是用户的资产信息,而保险公司的数据是用户的保险信息,如果它们想要在不互相披露数据的情况下,联合开发一个风控模型。这时候采用的方法叫做“纵向联邦学习”(VFL)。 纵向联邦学习主要分为两步: 这里面最难的部分,是如何在双方都看不到对方用户的情况下,实现“对齐”,即找到共同的用户。这里的算法是非对称加密的RSA算法和哈希机制的结合。 训练步骤为: 这种方式适用于客户群体类似的不同机构之间的合作,例如一个城市的银行和保险公司之间,医院和保险公司之间等等。 3、联邦迁移学习(FTL) 迁移学习是机器学习中的一种特殊门类,即用户样本和特征都不同,类似于骑摩托车和自行车完全不同,我们希望通过学习,将骑自行车的技能迁移到骑摩托车上。 联邦迁移学习针对的是两家机构之间,样本数据不同,特征也不同的情况,例如两个城市的银行和保险公司。它们如何想要合作开发一个风控模型,就需要采用联邦迁移学习。 联邦迁移学习的架构类似于纵向联邦学习,但是采用的梯度计算方法、损失函数、交换结果有所不同。这个领域目前相对较不成熟,不赘述。 三、“联邦学习” 可以用于哪些领域? 根据上面的介绍可以知道,它可以起到下列作用: 四、“联邦学习” 和隐私计算是什么关系? “隐私计算”是指在处理、分析数据的过程中保持数据的不透明、不泄露。联邦学习是隐私计算的一种实现方法,另外还有多方安全计算(MPC)、差分隐私等方法。 五、“联邦学习”有哪些优点和缺点? 优点: 以上,就是我对“联邦学习”的原理和现状的一些汇总。因为简略需要,肯定有不足甚至错误之处,敬请谅解,欢迎拍砖。
1)每个参与方从中央聚合器下载最新模型,然后在本地计算模型参数(又称“梯度”);
2)每个参与方将经过加密的梯度信息发送到位于聚合器;
3)聚合器进行聚合操作(“安全聚合”,常见算法为FedAvg),更新模型;
4)聚合器把综合更新后的模型分发到各个参与方;
5)参与方更新自己的模型。
6)经过若干次迭代,直到模型精确度(“损失函数”)达到设定值,模型就大功告成。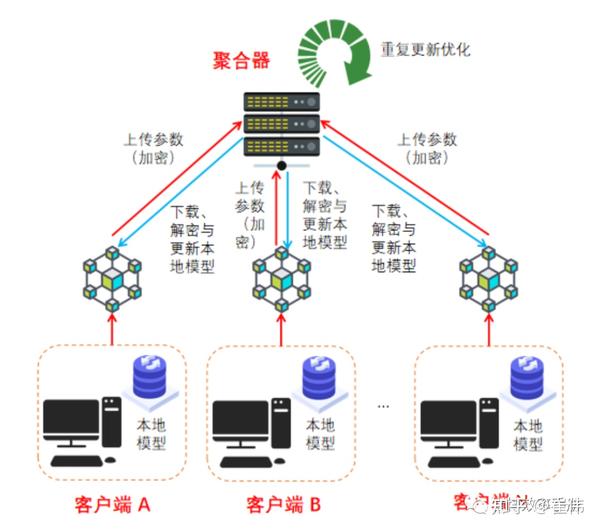

1)虽然每家的数据量有限,但是通过聚合,实现了数据样本的共享。
2)每家看不到别家的数据;聚合器也看不到各家的样本数据;
3)因为聚合器有可能被攻击(“DLG攻击”),所以客户端发给聚合器的梯度信息需要用同态加密(即加密后操作可以还原为样本操作,这个以后细说)或者差分隐私(例如加一个随机数)的方法进行加密。
1) 对齐不同参与方的相同用户样本(“加密实体对齐”);
2)对这些样本进行加密的模型训练(即下图中右侧部分)。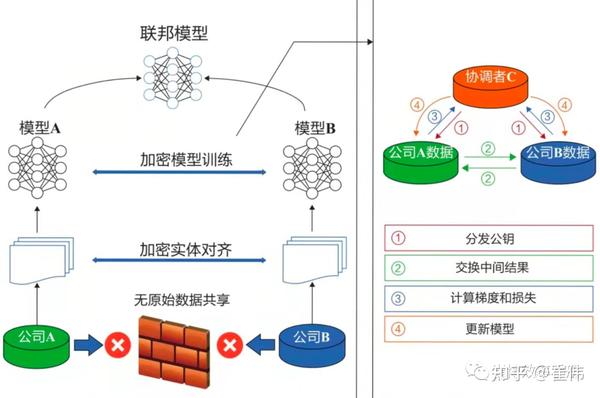
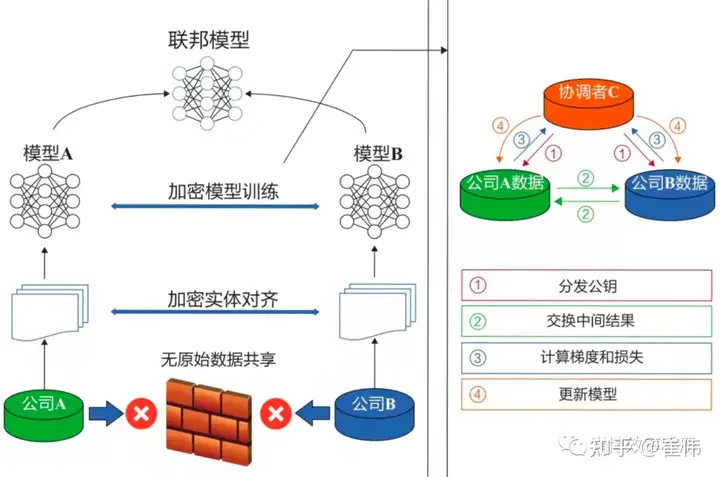
1)协调方负责分发公钥,私钥不发,这样只有C可以解密(关于公私钥机制,以后也会单独写篇文章)。
2) A、B将对齐后的样本进行同态加密和交互,分别计算各自的梯度和损失值。
3)A、B算好以后,发给C(这时会加上掩码或者噪声,避免C泄密)。
4)C进行解密,再发回给A、B。A、B解除掩码,更新自己的模型。

1)金融机构可以结合多方数据,建立更加全面的风控模型,对贷款人的信用进行评估;
2)医疗机构可以整合不同医院的数据,开发疾病检测模型、影像分析模型或者疫情防控模型;
3)监管机构可以通过组合不同部门、机构的数据,对洗钱、欺诈等行为建立更加精确的预警模型。
缺点:
这些不足,也正是各个院校、企业的计算机研发人员正在努力优化的方向。这些方面的成果可谓层出不穷,如Google方案、微众银行FATE方案、PATE方法、SecureBooster等等,都试图在安全性、训练性能、网络效率等方面取得一定的平衡和突破。