前言 Meta的大语言模型LLaMA 13B,现在用2060就能跑了~
本文转载自量子位
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
羊驼家族的Alpaca和Vicuna也都能运行,显存最低只需要6G,简直是低VRAM用户的福音有木有。
GitHub上的搭建教程火了之后,网友们纷纷跑来问苹果M2是不是也能跑。

这通操作的大致原理是利用最新版CUDA,可以将Transformer中任意数量的层放在GPU上运行。
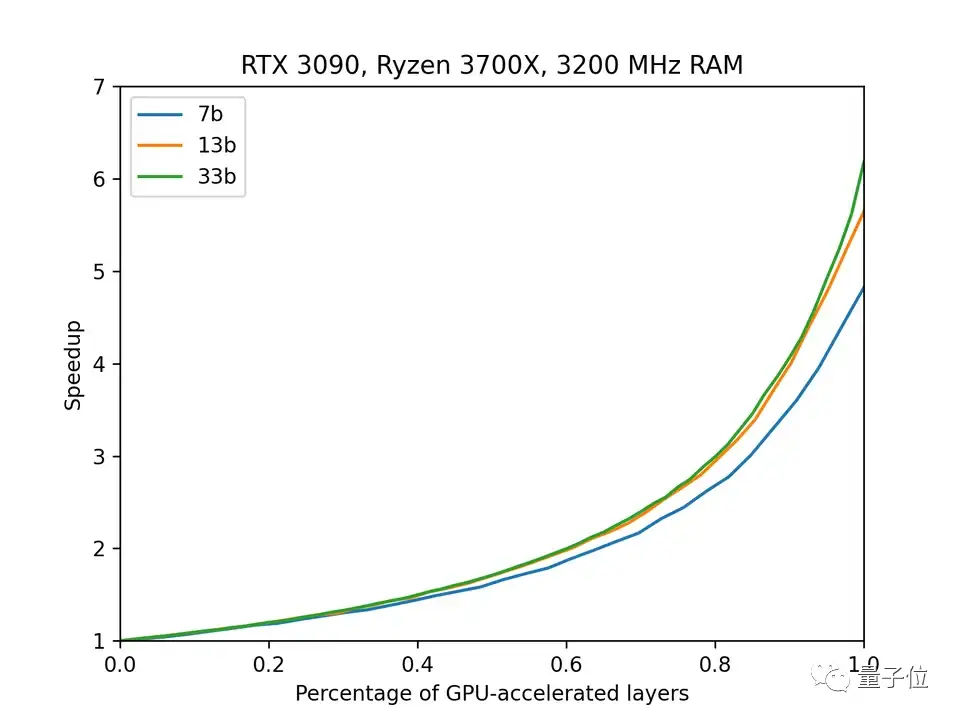
与此前llama.cpp项目完全运行在CPU相比,用GPU替代一半的CPU可以将效率提高将近2倍。
而如果纯用GPU,这一数字将变成6倍。
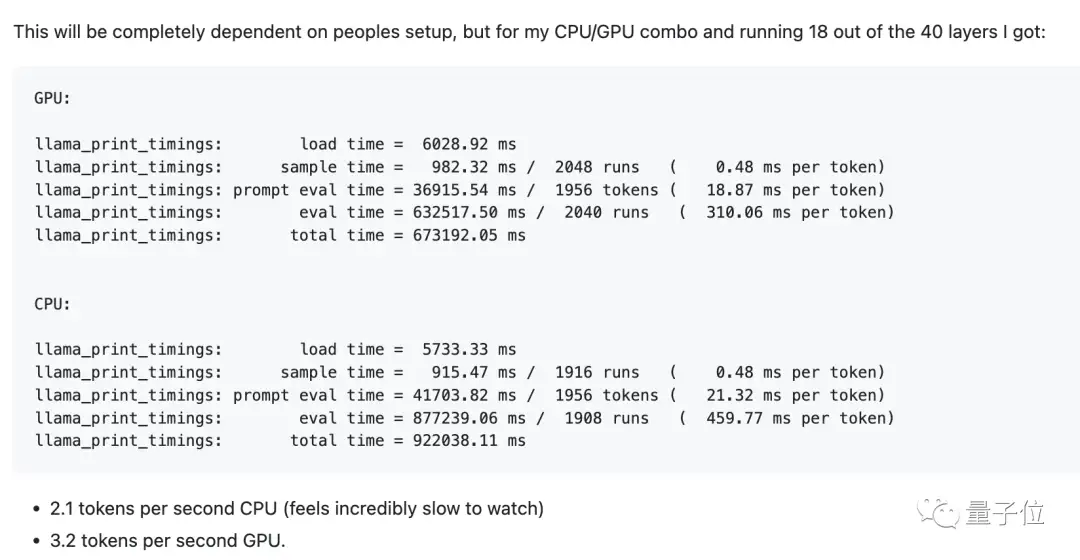
网友实测的结果中,使用CPU每秒能跑2.1个token,而用GPU能跑3.2个。
生成的内容上,开发者成功用它跑出了“尼采文学”。

如何操作
在开始搭建之前,我们需要先申请获得LLaMA的访问权限。
传送门:https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
此外还需要有一个Linux环境。(Windows用户可以用WSL2)
准备工作完成之后,第一步是将llama.cpp克隆到本地。
1git clone https://github.com/ggerganov/llama.cpp.git
2cd llama.cpp
3pacman -S cuda //make sure you have CUDA installed
4make LLAMA_CUBLAS=1
如果没有安装CUDA,可以参考下面的步骤:
1wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
2sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
3wget https://developer.download.nvidia.com/compute/cuda/12.1.1/local_installers/cuda-repo-wsl-ubuntu-12-1-local_12.1.1-1_amd64.deb
4sudo dpkg -i cuda-repo-wsl-ubuntu-12-1-local_12.1.1-1_amd64.deb
5sudo cp /var/cuda-repo-wsl-ubuntu-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
6sudo apt-get update
7sudo apt-get -y install cuda
然后是建立micromamba环境,安装Python和PyTorch等工具。
接着需要在micromamba环境下安装一些包:
1export MAMBA_ROOT_PREFIX=(自定义安装路径)
2eval "$(micromamba shell hook --shell=bash)"
3micromamba create -n mymamba
4micromamba activate mymamba
5micromamba install -c conda-forge -n mymamba pytorch transformers sentencepiece
然后运行Python脚本以执行转换过程:
1python convert.py ~/ai/Safe-LLaMA-HF-v2\ \(4-04-23\)/llama-13b/
之后将其量化为4bit模式。
1./quantize ~/ai/Safe-LLaMA-HF-v2\ \(4-04-23\)/llama-13b/ggml-model-f16.bin ~/ai/Safe-LLaMA-HF-v2\ \(4-04-23\)/llama-13b/ggml-model-13b-q4_0-2023_14_5.bin q4_0 8
接着是新建一个txt文本文档,把提示词输入进去,然后就可以运行了。
1./main -ngl 18 -m ~/ai/Safe-LLaMA-HF-v2\ \(4-04-23\)/llama-13b/ggml-model-13b-q4_0-2023_14_5.bin -f 文档名称.txt -n 2048q4_0 8
这步当中-ngl后面的数字是可以修改的,它代表了转换层的数量。
当该值为18时,运行中消耗的VRAM为5.5GB,根据显存的大小最高可以调至40。
网友:AMD不配吗
这一教程出现之后,网友们的新玩具又增加了。
“苦OpenAI久矣”的网友更是感觉仿佛找到了光。
这位网友就表示自己太期待在自己的设备上运行LLM了,宁愿花5千美元购置设备也不想给OpenAI交一分钱。

但AMD用户可能就不那么兴奋了,甚至透露出了嫉妒之情。
这套方法要用到CUDA(英伟达专用),所以AMD是不配了吗?
那么,你期待用自己的设备跑大语言模型吗?
参考链接:
[1].https://gist.github.com/rain-1/8cc12b4b334052a21af8029aa9c4fafc
[2].https://twitter.com/_akhaliq/status/1657779996247588865
[3].https://news.ycombinator.com/item?id=35937505
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR'23|泛化到任意分割类别?FreeSeg:统一、通用的开放词汇图像分割新框架
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
通用AI大型模型Segment Anything在医学图像分割领域的最新成果!
可复现、自动化、低成本、高评估水平,首个自动化评估大模型的大模型PandaLM来了
实例:手写 CUDA 算子,让 Pytorch 提速 20 倍
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:显存,13,https,教程,cuda,llama,贺电,com,CV From: https://www.cnblogs.com/wxkang/p/17417424.html