论文阅读07-MBN:Mutual Boost Network for Attributed Graph Clustering
论文信息
论文地址:https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4195979
代码地址:https://github.com/Xiaoqiang-Yan/MBN
1.存在问题
- 存在问题
- 现有区分表示的方法受到
节点和结构特征之间差异的限制。 - 多个网络生成的不同聚类分配应该是一致的,因为 图数据同时具有节点和结构信息的特征。现有的图聚类方法 经常忽略这种基本的聚类一致性,导致表示空间的分布不一致。如何保证由
节点和结构特征产生的聚类分配的一致性仍然是一个具有挑战性的问题,这往往会导致聚类性能下降
2. MBN 解决问题
- 如何解决
创新点:
- 提出了一种用于属性图聚类的新型双通道网络,称为 Mutual Boost Network (MBN),它由自动编码器和图自动编码器组成,可以相互交互和学习以实现聚类性能的相互提升。
- 提出了一种新的表示增强模块来传播来自节点和结构特征的异构信息,以学习综合表示
- 通过对比聚类分配设计了一致性约束,以提供相互指导,使它们趋于一致
- 表示学习和聚类分配的过程在统一框架下以自我监督的方式同时优化
3.MBN model
1. model structrue
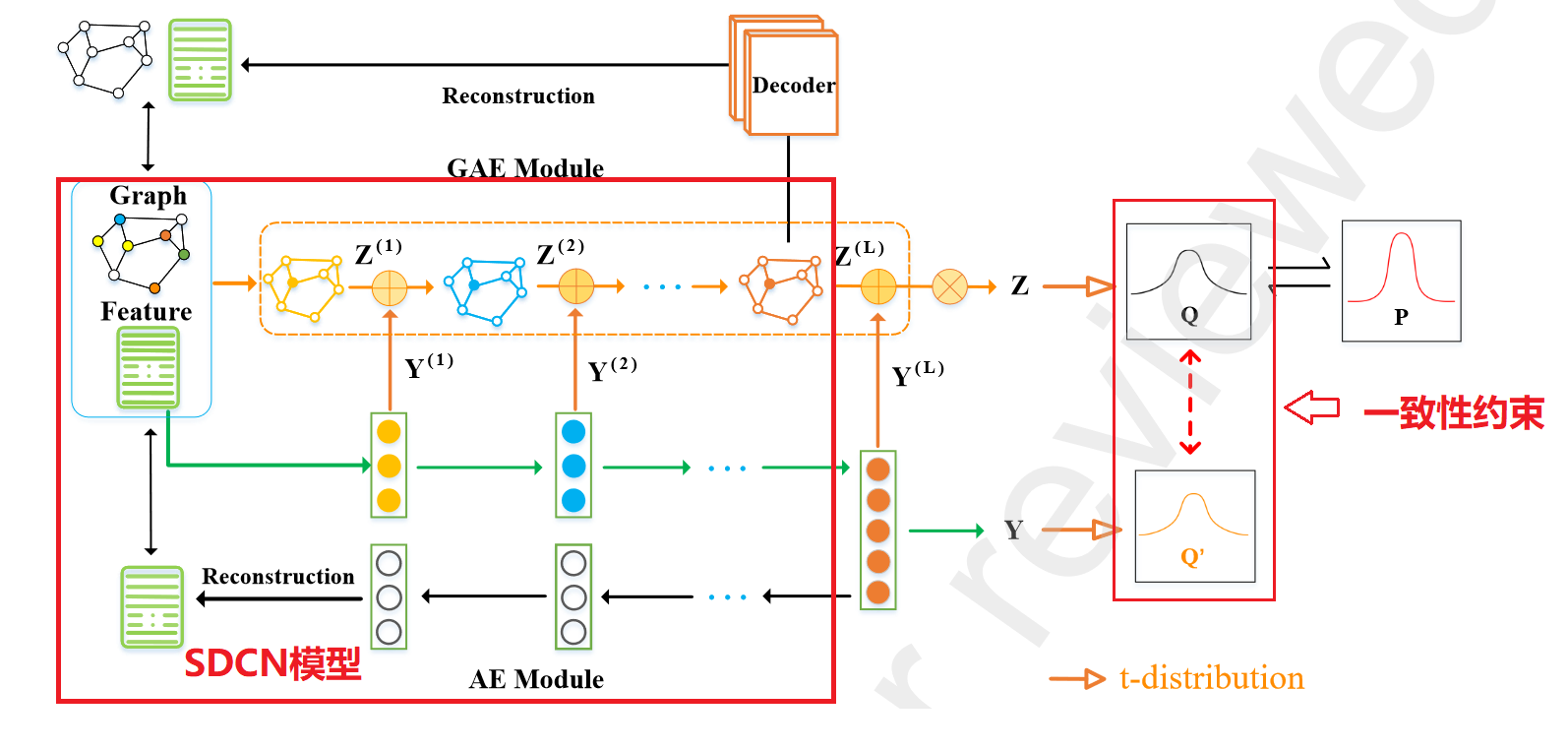
MBN 模型主要由4个模块组成:AE 模块和 GAE 模块、表示增强 (RE) 模块和自监督模块。
- AE 模块: 用于从下游节点 聚类任务的节点属性中学习表示。
- GAE模块:GAE 模块旨在通过聚合具有 逻辑结构的节点属性来学习表示。:类似与DFCN中的IGAE
- RE(表示增强)模块: 旨在传播和融合异构 节点和结构信息,以获得更全面和有判别力的表示
- 自监督模块: 设计对比聚类分配是为了使它们趋于一致
2.AE模块
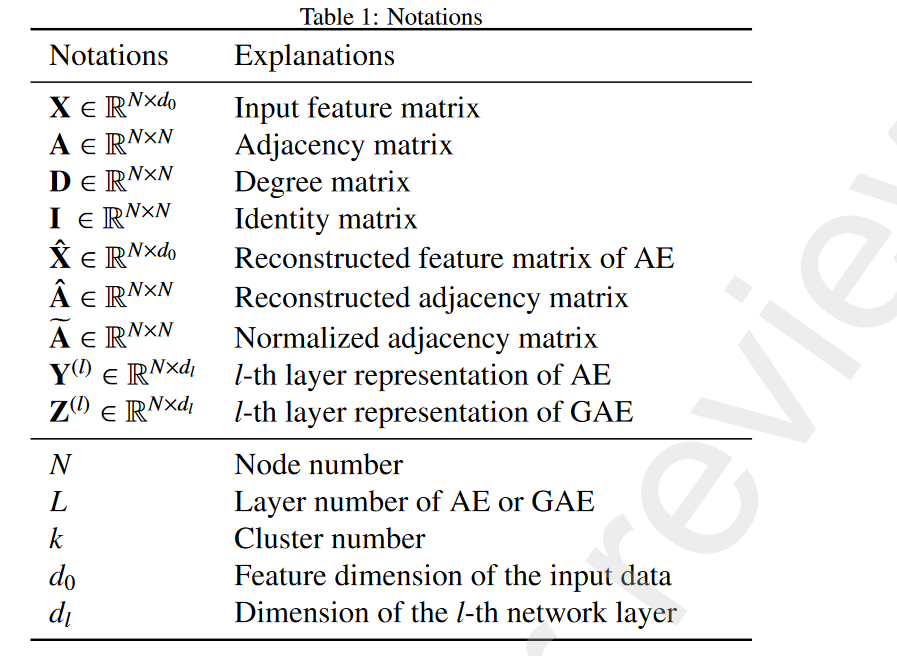
- MBN参数表
具有线性全连接层的基本自动编码器来学习节点属性的表示:

3.GAE模块:对称
利用 GAE 作为表示学习模块来提取结构信息,GAE的结构是对称的,解码器也是图卷积网络

DFCN 中的IGAE模块详解

具有多级网络表示的内积操作生成的重构矩阵A^解释,通过查看DFCN的代码:
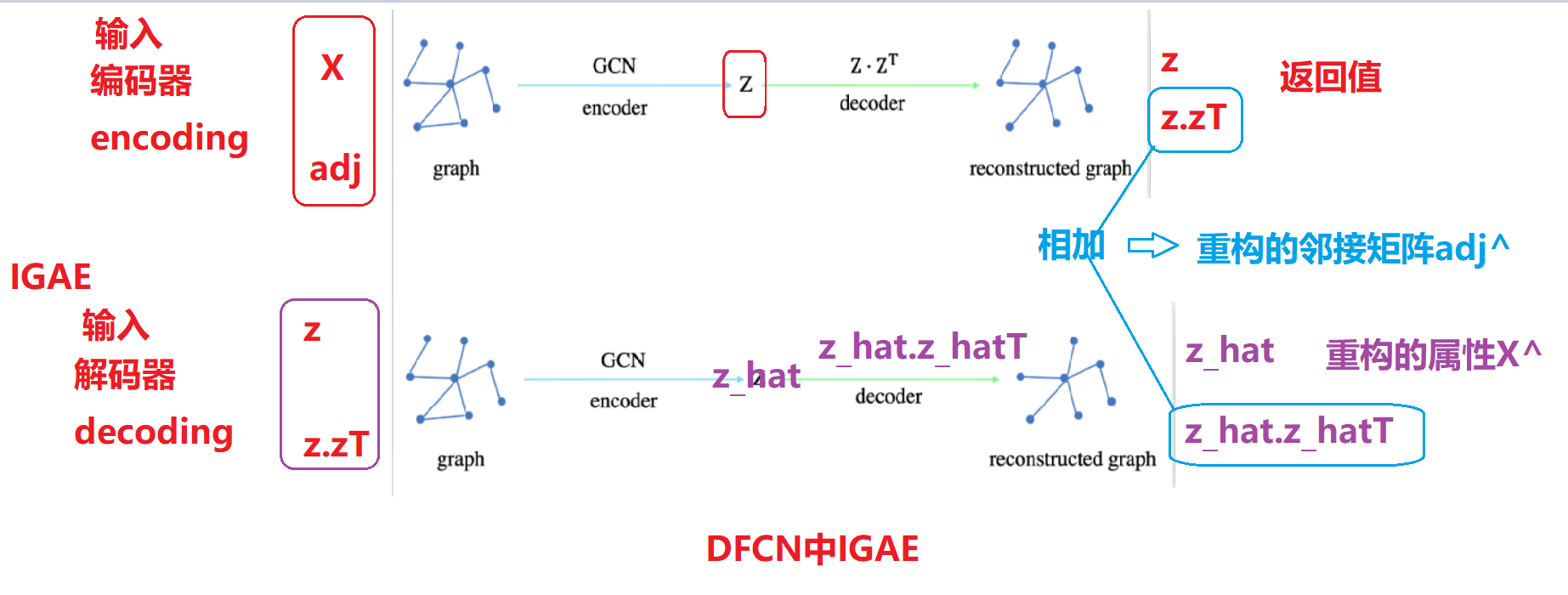
普通的GAE:
编码器: 产生嵌入向量z:相当于重构属性x
解码器: GAE通过嵌入向量z 的内积z.zT生成 重构邻接矩阵adj
IGAE:
编码器:相当于普通GAE 编码器和解码器
输入属性x,邻接矩阵adj ===》产生了上述的z 和z.zT ==adj
z可以表示重构的属性x adj表示普通的GAE产生的重构邻接矩阵adj
解码器 : 相当于又经历一次普通GAE 编码器和解码器
输入 IGAE编码器的z 和adj =》再通过和IGAE编码器一样的操作产生z_hat,
z_hat 通过内积操作产生邻接矩阵z_adj.
z_hat 表示重构的z属性矩阵,z_hat通过内积产生邻接矩阵z_adj
IGAE:
相当于做了两次传统的GAE操作,由于每个传统的GAE 都产生了重构矩阵adj
因此 IGAE 重构的adj=IGAE编码器重构的adj+IGAE解码器重构的adj
IGAE 重构的属性z_hat 表示就是属性x的重构:
z_hat 指的是经历了编码和解码产生的,没有进行加和操作
4.RE增强模块
我们设计了一个表示 增强 (RE) 模块,它包括两个步骤:层间信息传播和结构信息集成。
首先,为了从图数据中提取更多的鉴别信息,将节点的纯属性特征集成到GCN中进行结构表示学习,对具有结构信息的特征信息的传播,通过线性计算将AE中的特征注入到GAE模块对应的层(SDCN中的传递算子进行的操作)
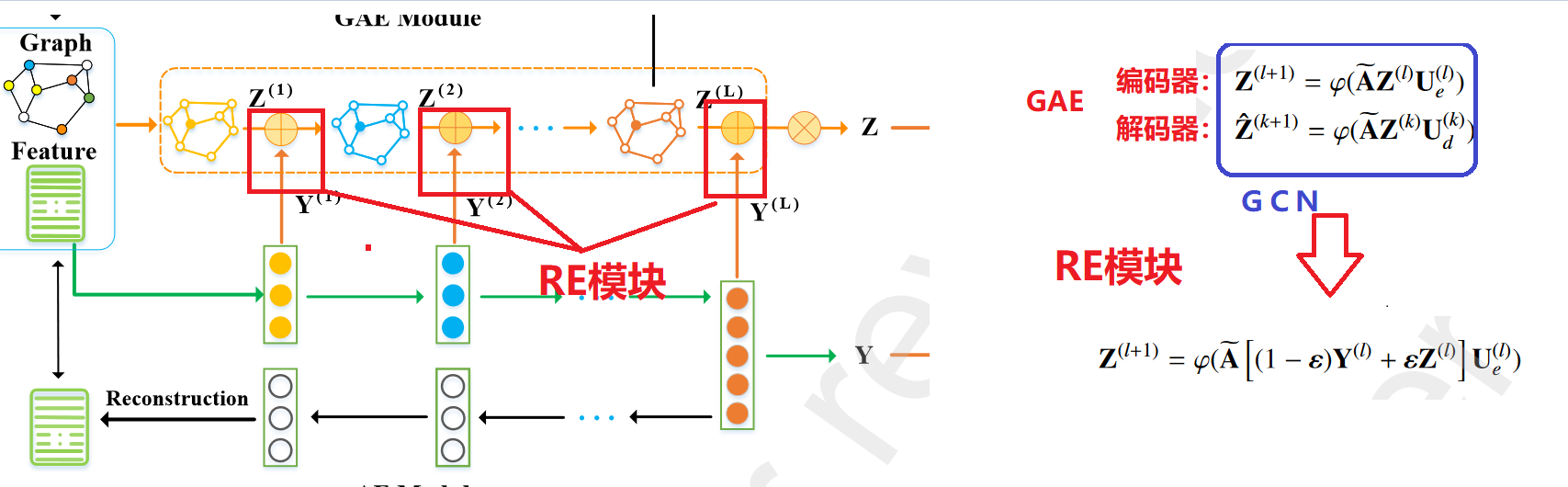
为了进一步提高表示质量,我们利用类似于图卷积的运算符来整合来自邻居的结构信息。
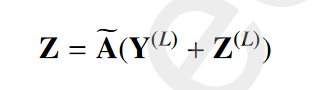
5. 自监督模块
它包括两个步骤:(1)计算软聚类分配Q和Q'。(2) 从Q生成目标分布P。
没有使用自编码器嵌入Y的辅助分布,而是使用图自编码器嵌入Z的目标分布Qz和辅助分布Pz,对应的损失函数为: ****
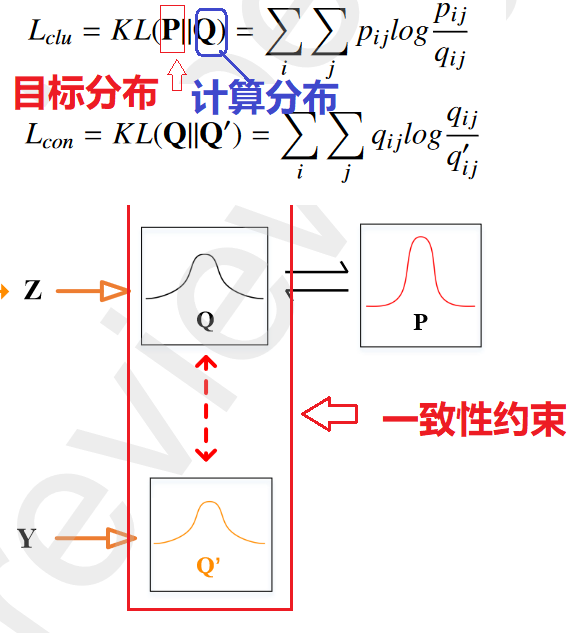
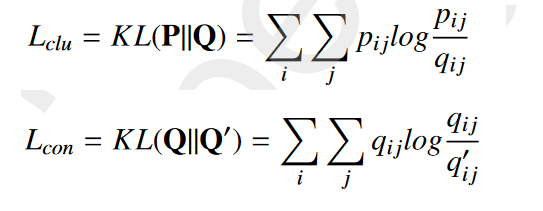
Q:计算出的概率就是实际分布概率 P表示目标分:理想==(最小化 Q 和 P 之间的 KL 距离,使分配 Q 逼近辅助目标 P)
目标函数 Lcon 表示 AE 和 GAE 模块的分配之间的相互一致性约束,可以使它们在训练过程中在同一优化目标下彼此接近
总损失函数:
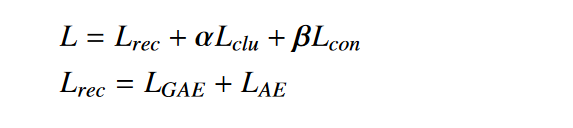
6. MBN算法流程图

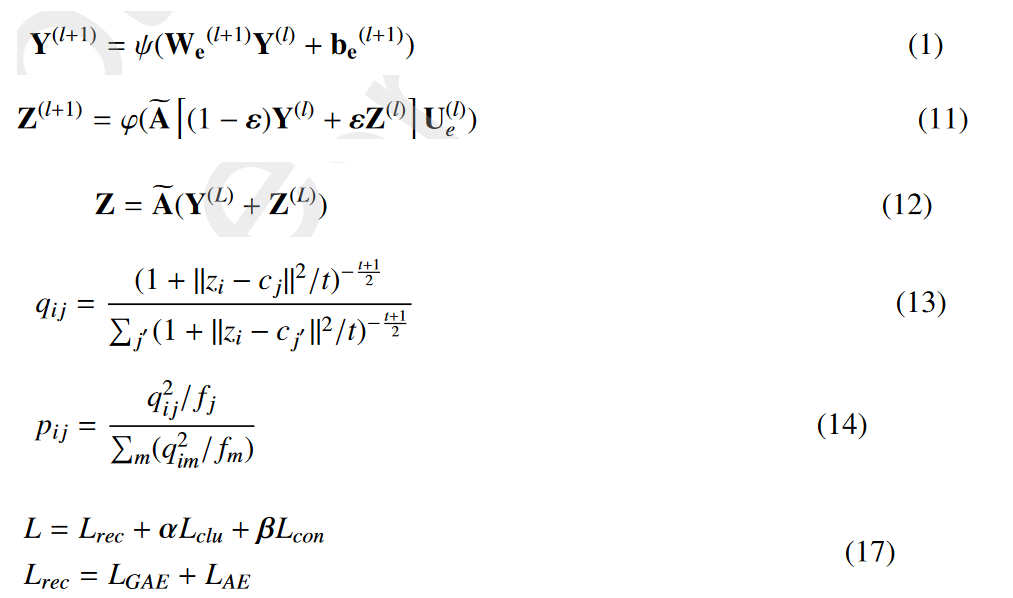
4. result Analysis
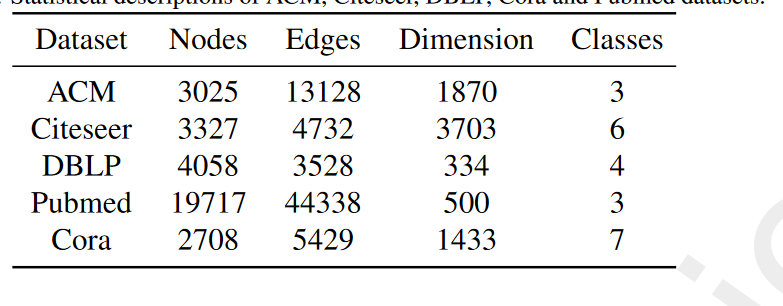
1. 数据集
2. 实验结果
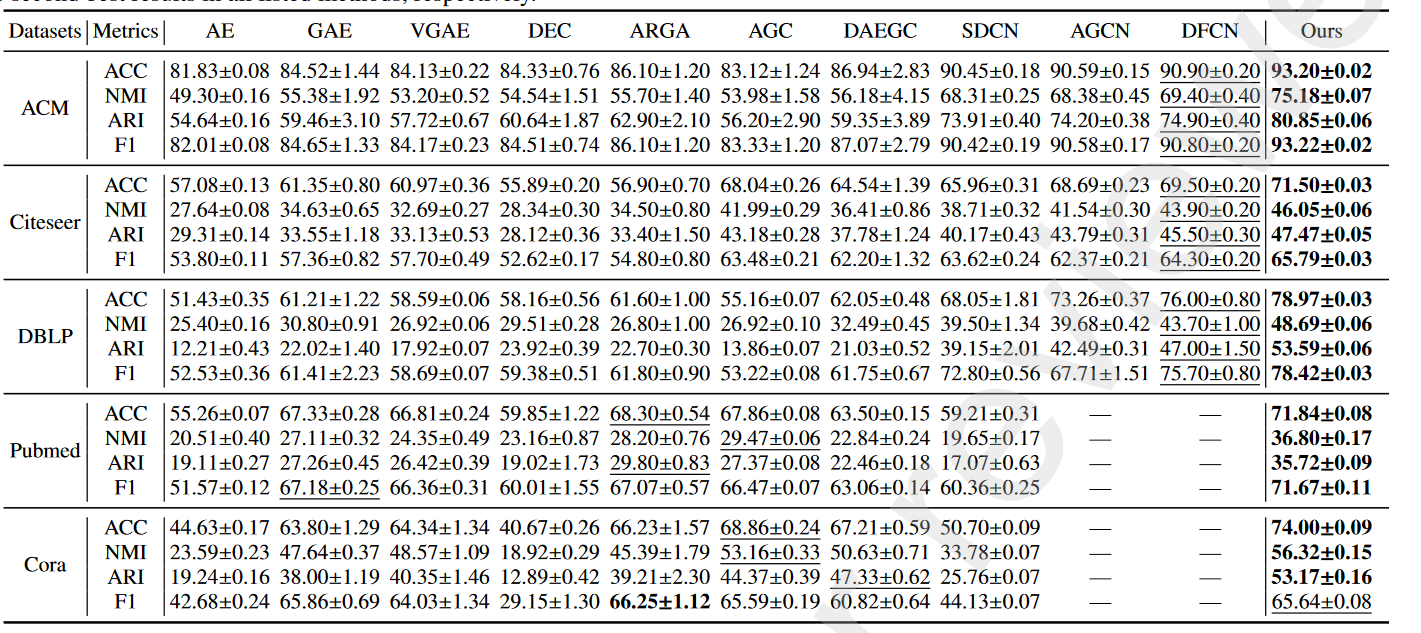
实验数据分析:对于**所有基线,我们直接引用论文 AGCN [24] 中列出的结果。****
由于SDCN没有在Pubmed和Cora数据集上进行ex287实验,AGC也没有在ACM和DBLP数据集上进行实验,所以我们288根据原作者发布的代码实现了SDCN和AGC
3. 实验训练过程
- 对于 MBN,类似于 SDCN [23],在训练之前,我们首先预训练自动编码器模块,学习率为 为 0.001,持续 50 个 epochs。 AE 和 GAE 中每一层的维度都设计为 500、500、2000 和 10。
- 为了初始化聚类中心,我们根据从预训练的 自动编码器获得的表示运行 K-means 20 次并选择最佳解决方案,然后我们在五个数据集:ACM、Citeseer、DBLP、Pubmed 和 Cora 上使用 200 个 epochs 优化和更新网络参数。
- 为了进行统计比较,我们运行模型 10 次,并使用平均值和相应的标准差评估聚类结果。此外,我们 固定相同的随机种子以防止出现意外情况。 ACM 和 Citeseer 的学习率选择为 4e-5,Cora 为 284 1e-4,Pubmed 为 5e-4,DBLP 为 2e-3。
- 我们微调两个平衡系数 α 和 β 以产生最佳的 结果。此外,对于本文的所有情况,我们固定参数 ε = 0.5,并将另一个参数 δ 设置为 0.1。
4.实验结果分析
- GCN 具有从图 数据中捕获结构信息的能力。相比之下,仅基于 AE 的方法只是探索节点的属性信息。
- 基于 GCN 的方法,如 GAE、VGAE、ARGA 和 DAEGC 无法与我们的相提并论,因为这些方法未充分利用数据本身的丰富信息,并且可能仅限于过度平滑现象。所提出的 MBN 将丰富的有价值的属性信息集成到表示学习中,并且表示增强模块可以 通过网络传播不同的信息以帮助学习全面的节点表示,从而 增强目标分布的质量
5. Ablation Analysis 消融实验分析
MBN 3个重点模块结构图
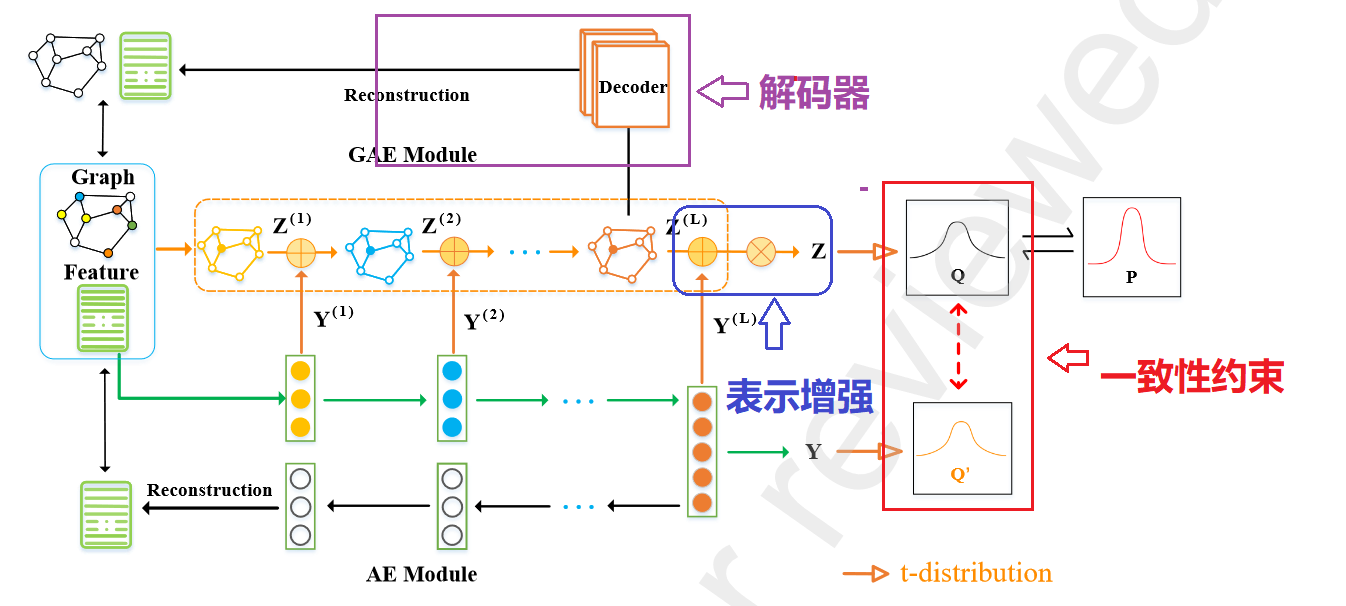
验证每个组件在 MBN 中的贡献,我们进一步设计三个变体进行比较。研究表示增强模块、一致性约束和图形解码器部分的效果。
| 模型名称 | 解释 |
|---|---|
| model | 标准MBN |
| model-f | 缺少表示增强模块MBN |
| model-c | 缺少一致性约束MBN |
| model-d | 缺少图解码器的MBN |
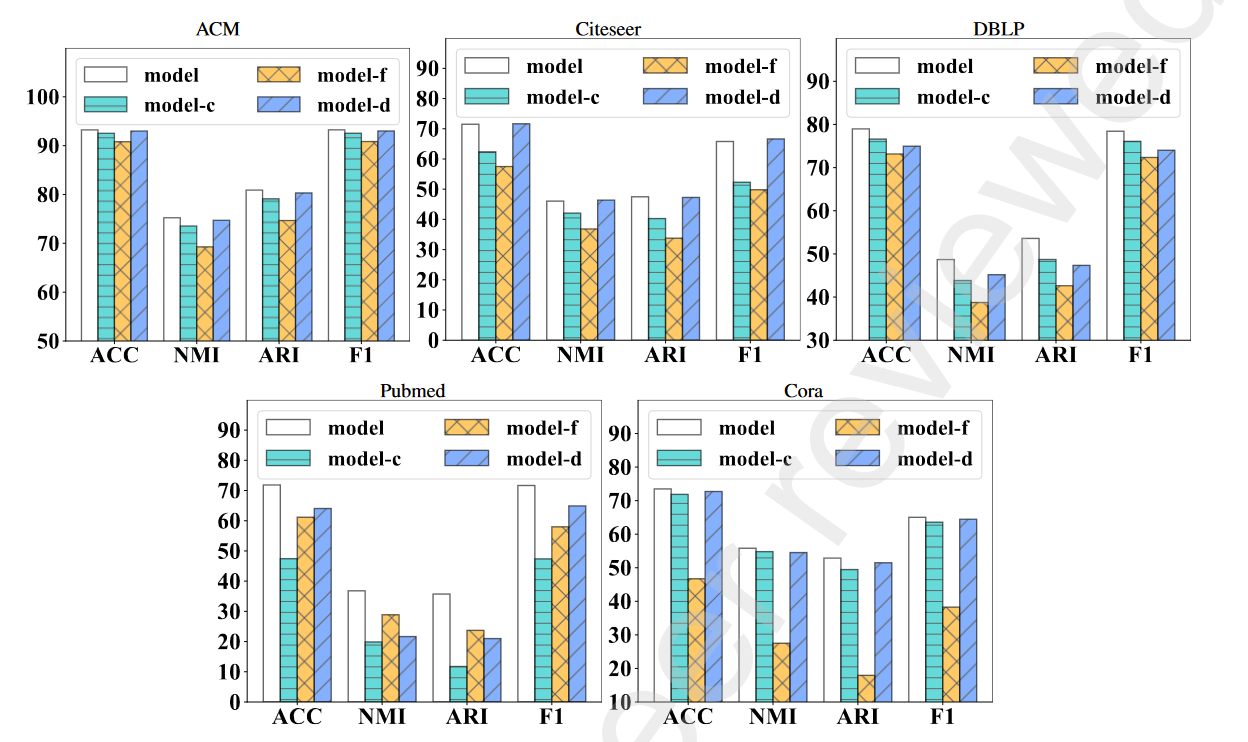
结论分析
-
首先完整模型一致且显着地超过了所有其他不完整变体 model-f、model-c 和 model-d,这显示了 MBN 的优势。
-
model-f 在 个四个数据集上表现最差:ACM、Citeseer、DBLP 和 Cora,验证了在 MBN 中学习到的节点表示更多比model-f全面且具有判别力。我们认为这是因为它可以有效地帮助从节点属性和图形结构中捕获 和传递异构信息,并进一步增强双网络的表示 能力。因此,聚类分配的目标分布可以受益于 学习表示。:证明 表示增强模块学习能力更强
-
完整模型的性能始终优于model-c。它表明一致性约束目标确实起到了相当大的作用。有利于提高聚类结果。原因是它可以对 双网络产生的不同分配施加一致性约束,并为它们提供相互学习和提高的相互指导。:证明一致性约束对于聚类有很大用处。