pytorch入门学习
来源: https://www.bilibili.com/video/BV1hE411t7RN
安装
# 1. 已安装nvidia相关驱动
# 2. 安装 python-pytorch-cuda
nsfoxer@ns-pc ~/Temp> yay -Qi python-pytorch-cuda numactl
基础使用
DataSet 数据集加载
继承DataSet类,并实现 get_item_
from torch.utils.data import Dataset
class MyData(Dataset):
def __getitem__(self, index):
return super().__getitem__(index)
def __len__(self):
return len([])
Tensorboard
用于生成loss图的工具
# 安装
yay -S python-setuptools tensorboard
# 代码
from torch.utils.tensorboard.writer import SummaryWriter
writer = SummaryWriter("logs") # 将输出至logs文件夹下
# y = x * 10
for i in range(1000):
writer.add_scalar("y=x", i*10, i)
writer.close()
# 查看
tensorboard --logdir logs
#!/bin/python
# 向 tensorboard添加图片
from torch.utils.tensorboard.writer import SummaryWriter
import numpy as np
from PIL import Image
writer = SummaryWriter("logs")
image_path = "./train/ants_image/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
print(img_array.shape) # 这里的格式 HWC
writer.add_image("test", img_array, 1, dataformats="HWC") # 设置格式为 HWC
# y = x * 10
for i in range(1000):
writer.add_scalar("y=x", i*10, i)
writer.close()
Transform
为torch的一个工具,用于转换数据为tensor类型。
from PIL import Image
from torchvision import transforms
image_path = "./train/ants_image/0013035.jpg"
img = Image.open(image_path)
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
Transvision
#!/bin/python
# transform学习
import torchvision
from torch.utils.tensorboard.writer import SummaryWriter
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./datasets/", train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root="./logs/", train=False, transform=dataset_transform, download=True)
writer = SummaryWriter("./logs/")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set", img, i)
writer.close()
Containers骨架
#!/bin/python
# nn
from torch import nn
import torch
class Base(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, input):
return input + 1
base = Base()
x = torch.tensor(1.0)
output = base(x)
print(output)
Conv2d 卷积
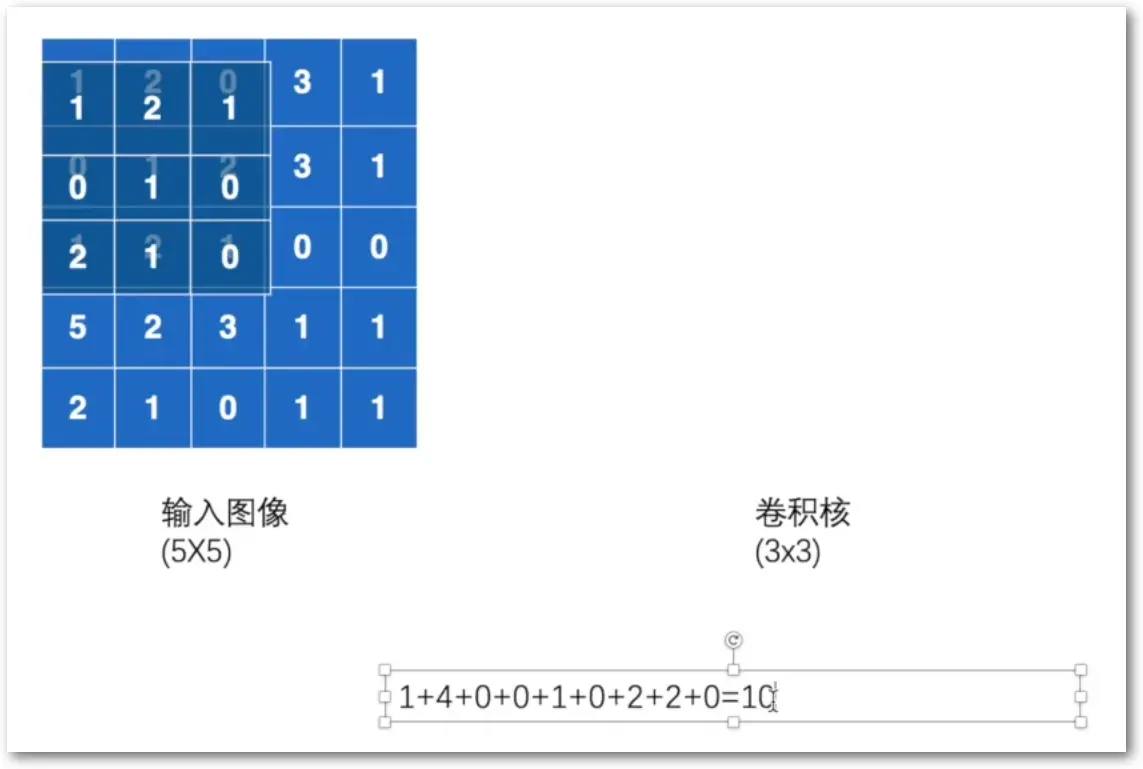
-
stride: 卷积核每次移动的步长,默认为1。(sH, sW)
-
padding: 1 默认值为0
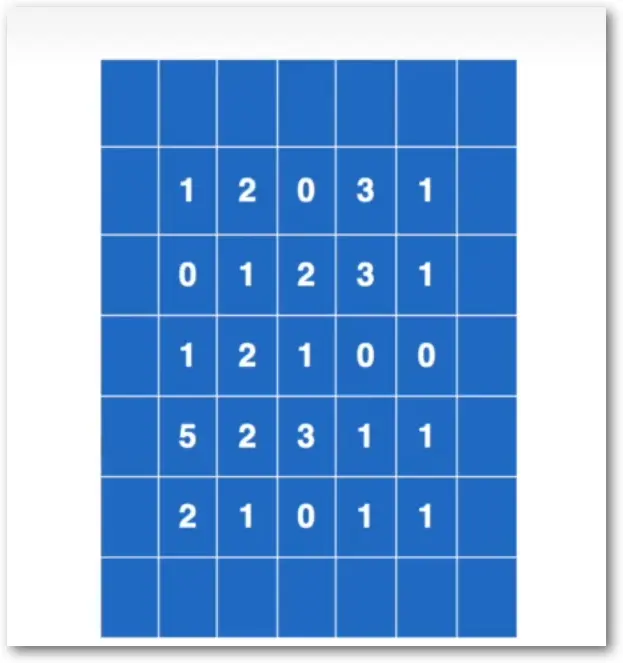
#!/bin/python
# 卷积
import torch
input = torch.tensor([
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
])
# 卷积核
kernel = torch.tensor([
[1, 2, 1],
[0, 1, 0],
[2, 1, 0]
])
# 调整shape
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
output = torch.nn.functional.conv2d(input, kernel, stride=1)
# 3x3
print(output)
output = torch.nn.functional.conv2d(input, kernel, stride=2)
# 2x2
print(output)
output = torch.nn.functional.conv2d(input, kernel, stride=1, padding=1)
# 5x5
print(output)
#!/bin/python
# 卷积
import torch
from torch.nn import Conv2d
from torch.utils.data import DataLoader
import torchvision
from torch.utils.tensorboard.writer import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./datasets/", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Study(torch.nn.Module):
def __init__(self) -> None:
super(Study, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
study = Study()
print(study)
writer = SummaryWriter("./logs/")
step = 0
for data in dataloader:
imgs, targets = data
output = study(imgs)
# torch.Size([64, 3, 32, 32])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step += 1
writer.close()
MaxPool2d 最大池化
目的为压缩数据,同时保证数据特征不丢失
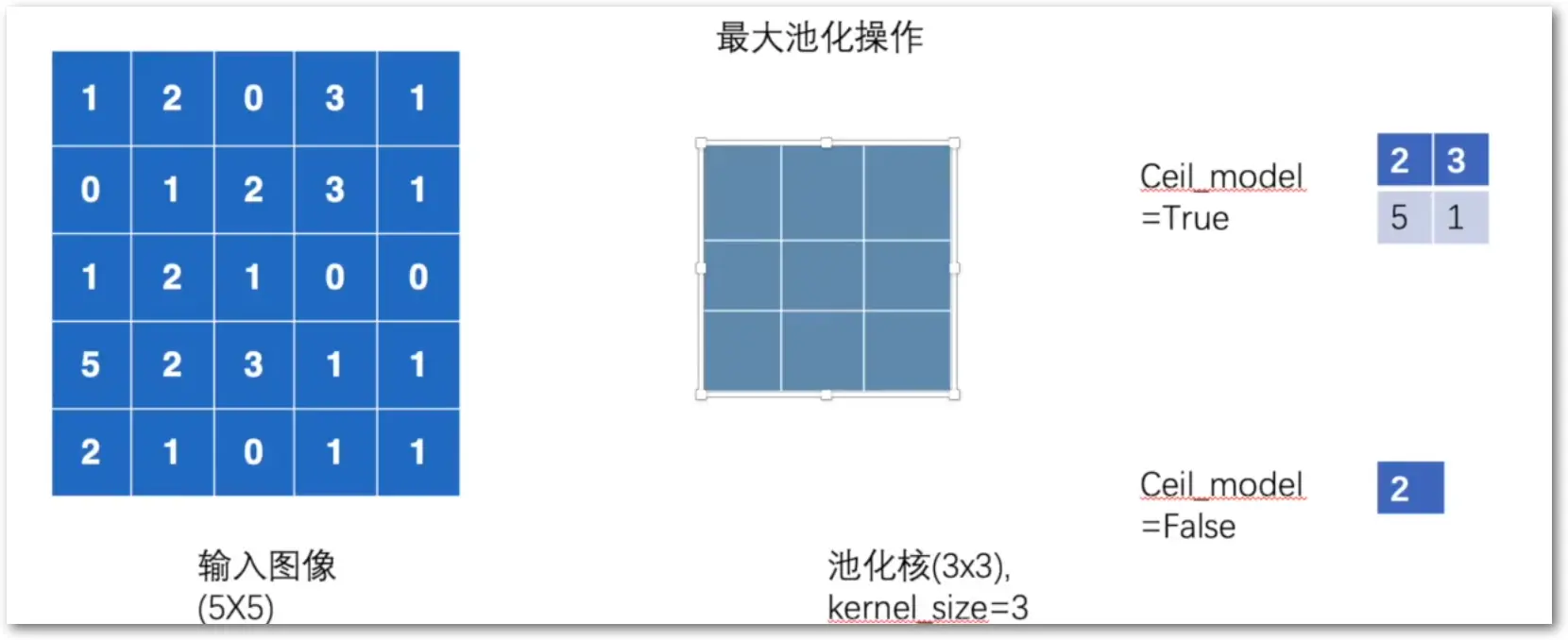
#!/bin/python
# 最大池化操作
import torch
from torch.nn import MaxPool2d
input = torch.tensor([
[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]
], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input.shape)
class Study(torch.nn.Module):
def __init__(self) -> None:
super(Study, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
study = Study()
output = study(input)
print(output)
Linear Layer
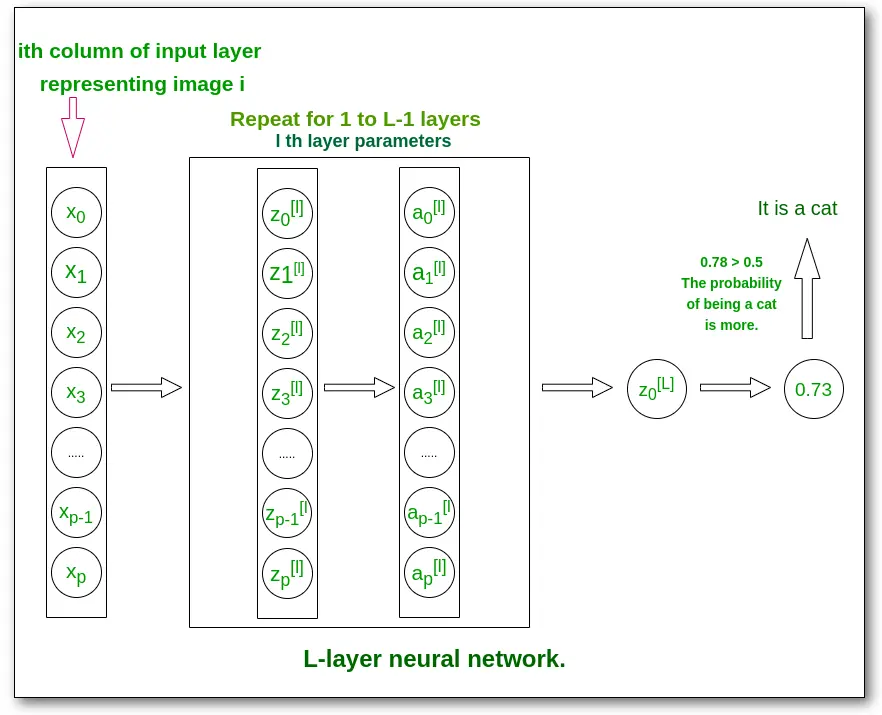
#!/bin/python
# 线性层
import torch
from torch.nn import Linear
from torch.utils.data import DataLoader
import torchvision
dataset = torchvision.datasets.CIFAR10("./datasets/", train=False, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Study(torch.nn.Module):
def __init__(self) -> None:
super(Study, self).__init__()
self.linear = Linear(196608, 10)
def forward(self, input):
return self.linear(input)
study = Study()
for data in dataloader:
imgs, target = data
print(imgs.shape)
output = torch.flatten(imgs) # 转为一维数据
print(output.shape)
output = study(output)
print(output.shape)
CIFAR 10
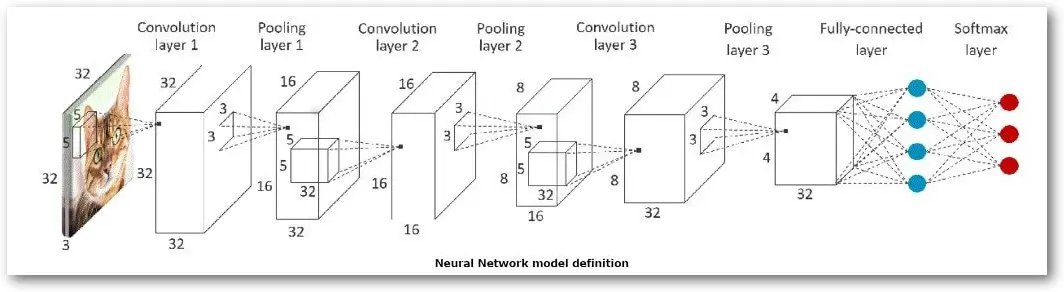
#!/bin/python
# Seq
import torch
from torch.nn import Conv2d, Flatten, Linear, MaxPool2d, Sequential
import torchvision
class Study(torch.nn.Module):
def __init__(self) -> None:
super(Study, self).__init__()
self.modle1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
return self.modle1(input)
study = Study()
input = torch.ones((64, 3, 32, 32))
output = study(input)
print(output.shape)
loss
- L1Loss: 平均误差
- MSELoss: 平方差
- CrossEntropyLoss

优化器
#!/bin/python
# Seq
import torch
from torch.nn import Conv2d, Flatten, Linear, MaxPool2d, Sequential
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
dataset = torchvision.datasets.CIFAR10("./datasets/", train=False, transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=1)
class Study(torch.nn.Module):
def __init__(self) -> None:
super(Study, self).__init__()
self.modle1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
return self.modle1(input)
loss = torch.nn.CrossEntropyLoss()
study = Study()
optim = torch.optim.SGD(study.parameters(), lr=0.01)
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = study(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad()
# 反向传播
result_loss.backward()
optim.step()
running_loss += result_loss
print(running_loss)
模型保存和读取
import torch
import torchvision
# 保存
torch.save(vgg16, "16.pth")
# 读取
model = torch.load("16.pth")
# 保存 (模型参数)
torch.save(vgg16.state_dict(), "16.pth")
# 读取
model = torchvision.models.vgg16()
model.load_state_dict(torch.load("16.pth"))
模型训练套路
#!/usr/bin/env python
# 训练套路
from torch import nn
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torch.utils.tensorboard.writer import SummaryWriter
# 数据记录
writer = SummaryWriter("./logs/")
# 1. 准备数据集
train_data = torchvision.datasets.CIFAR10("./datasets/", train=True, transform=transforms.ToTensor(), download=True)
# 2. 准备测试数据集
test_data = torchvision.datasets.CIFAR10("./datasets/", train=False, transform=transforms.ToTensor(), download=True)
print(f"训练数据集长度:{len(train_data)}\n测试数据集长度:{len(test_data)}")
# 3. 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 4. 搭建神经网络
class Study(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super(Study, self).__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
return self.model(x)
# 测试网络是否正确
def test_study():
study = Study()
x = torch.ones((64, 3, 32, 32))
y = study(x)
print(y.shape)
# 5. 创建网络
study = Study()
# 6. 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 7. 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(study.parameters(), lr=learning_rate)
# 8. 设置训练网络参数
train_step = 0 # 训练的次数
test_step = 0 # 测试的次数
epoch = 10 # 训练的轮数
for i in range(epoch):
print(f"第{i+1}次训练")
# 训练开始
study.train() # 设定为训练模式
for (imgs, targets) in train_dataloader:
# 训练
outputs = study(imgs)
# 损失
loss = loss_fn(outputs, targets)
# 清理梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 优化
optimizer.step()
train_step += 1
if train_step % 100 == 0:
print(f"训练次数:{train_step}, loss={loss.item()}")
writer.add_scalar("train_loss", loss.item(), train_step)
# 本轮测试
study.eval() # 设定为测试模式
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for (imgs, targets) in test_dataloader:
outputs = study(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
total_accuracy += (outputs.argmax(1) == targets).sum()
print("整体测试集的loss: ", total_test_loss)
print("整体测试集的正确率: ", total_accuracy/len(test_data))
test_step += 1
writer.add_scalar("test_loss", total_test_loss, test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), test_step)
# 保存本轮的训练模型
torch.save(study.state_dict(), f"study_{i}.pth")
print("模型已保存")
writer.close()
GPU训练
第一种
- 网络模型
- 数据(输入、 标注)
- 损失函数
调用.cuda()即可
#!/usr/bin/env python
# 训练套路
from torch import nn
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torch.utils.tensorboard.writer import SummaryWriter
import time
# 数据记录
writer = SummaryWriter("./logs/")
# 1. 准备数据集
train_data = torchvision.datasets.CIFAR10("./datasets/", train=True, transform=transforms.ToTensor(), download=True)
# 2. 准备测试数据集
test_data = torchvision.datasets.CIFAR10("./datasets/", train=False, transform=transforms.ToTensor(), download=True)
print(f"训练数据集长度:{len(train_data)}\n测试数据集长度:{len(test_data)}")
# 3. 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 4. 搭建神经网络
class Study(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super(Study, self).__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
return self.model(x)
# 测试网络是否正确
def test_study():
study = Study()
x = torch.ones((64, 3, 32, 32))
y = study(x)
print(y.shape)
# 5. 创建网络
study = Study().cuda()
# 6. 创建损失函数
loss_fn = nn.CrossEntropyLoss().cuda()
# 7. 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(study.parameters(), lr=learning_rate)
# 8. 设置训练网络参数
train_step = 0 # 训练的次数
test_step = 0 # 测试的次数
epoch = 10 # 训练的轮数
start_time = time.time()
for i in range(epoch):
print(f"第{i+1}次训练")
# 训练开始
study.train() # 设定为训练模式
for (imgs, targets) in train_dataloader:
(imgs, targets) = (imgs.cuda(), targets.cuda())
# 训练
outputs = study(imgs)
# 损失
loss = loss_fn(outputs, targets)
# 清理梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 优化
optimizer.step()
train_step += 1
if train_step % 100 == 0:
end_time = time.time()
print("耗时: {}", end_time-start_time)
print(f"训练次数:{train_step}, loss={loss.item()}")
writer.add_scalar("train_loss", loss.item(), train_step)
# 本轮测试
study.eval() # 设定为测试模式
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for (imgs, targets) in test_dataloader:
(imgs, targets) = (imgs.cuda(), targets.cuda())
outputs = study(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
total_accuracy += (outputs.argmax(1) == targets).sum()
print("整体测试集的loss: ", total_test_loss)
print("整体测试集的正确率: ", total_accuracy/len(test_data))
test_step += 1
writer.add_scalar("test_loss", total_test_loss, test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), test_step)
# 保存本轮的训练模型
torch.save(study.state_dict(), f"study_{i}.pth")
print("模型已保存")
writer.close()
第二种:直接调用
#!/usr/bin/env python
# 训练套路
from torch import nn
import torch
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torch.utils.tensorboard.writer import SummaryWriter
import time
device = torch.device("cuda:0")
# 数据记录
writer = SummaryWriter("./logs/")
# 1. 准备数据集
train_data = torchvision.datasets.CIFAR10("./datasets/", train=True, transform=transforms.ToTensor(), download=True)
# 2. 准备测试数据集
test_data = torchvision.datasets.CIFAR10("./datasets/", train=False, transform=transforms.ToTensor(), download=True)
print(test_data.class_to_idx)
print(f"训练数据集长度:{len(train_data)}\n测试数据集长度:{len(test_data)}")
# 3. 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 4. 搭建神经网络
class Study(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super(Study, self).__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
return self.model(x)
# 测试网络是否正确
def test_study():
study = Study()
x = torch.ones((64, 3, 32, 32))
y = study(x)
print(y.shape)
# 5. 创建网络
study = Study().to(device)
# 6. 创建损失函数
loss_fn = nn.CrossEntropyLoss().to(device)
# 7. 优化器
learning_rate = 0.01
optimizer = torch.optim.SGD(study.parameters(), lr=learning_rate)
# 8. 设置训练网络参数
train_step = 0 # 训练的次数
test_step = 0 # 测试的次数
epoch = 10 # 训练的轮数
start_time = time.time()
for i in range(epoch):
print(f"第{i+1}次训练")
# 训练开始
study.train() # 设定为训练模式
for (imgs, targets) in train_dataloader:
(imgs, targets) = (imgs.to(device), targets.to(device))
# 训练
outputs = study(imgs)
# 损失
loss = loss_fn(outputs, targets)
# 清理梯度
optimizer.zero_grad()
# 反向传播
loss.backward()
# 优化
optimizer.step()
train_step += 1
if train_step % 100 == 0:
end_time = time.time()
print("耗时: {}", end_time-start_time)
print(f"训练次数:{train_step}, loss={loss.item()}")
writer.add_scalar("train_loss", loss.item(), train_step)
# 本轮测试
study.eval() # 设定为测试模式
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for (imgs, targets) in test_dataloader:
(imgs, targets) = (imgs.to(device), targets.to(device))
outputs = study(imgs)
loss = loss_fn(outputs, targets)
total_test_loss += loss.item()
total_accuracy += (outputs.argmax(1) == targets).sum()
print("整体测试集的loss: ", total_test_loss)
print("整体测试集的正确率: ", total_accuracy/len(test_data))
test_step += 1
writer.add_scalar("test_loss", total_test_loss, test_step)
writer.add_scalar("test_accuracy", total_accuracy/len(test_data), test_step)
# 保存本轮的训练模型
torch.save(study.state_dict(), f"study_{i}.pth")
print("模型已保存")
writer.close()
使用已有的训练集
# 获取目标
print(test_data.class_to_idx)
{'airplane': 0, 'automobile': 1, 'bird': 2, 'cat': 3, 'deer': 4, 'dog': 5, 'frog': 6, 'horse': 7, 'ship': 8, 'truck': 9}
#!/usr/bin/env python
# 使用训练好的模型
from PIL import Image
from torch import nn
import torch
from torchvision.transforms import transforms
img_path = "./air.png"
img = Image.open(img_path)
img = img.convert("RGB")
transform = transforms.Compose([transforms.Resize((32, 32)),
transforms.ToTensor()])
img = transform(img)
class Study(nn.Module):
def __init__(self, *args, **kwargs) -> None:
super(Study, self).__init__(*args, **kwargs)
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10),
)
def forward(self, x):
return self.model(x)
model = Study()
model.load_state_dict(torch.load("./study.pth"))
img = torch.reshape(img, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(img)
print(output)
print(output.argmax(1))
动手深度学习
视频:https://www.bilibili.com/video/BV1J54y187f9/
- 图片分类
- 物体检测和分割
- 样式迁移
- 人脸合成
- 文字生成图片
- 文字生成 gpt3
- 无人驾驶
- 广告点击
数据操作和数据预处理
N维数组样例
N维数组是机器学习和神经网络的主要数据结构。
| 维度 | 数学? | 表示 | 例子 |
|---|---|---|---|
| 0维数组 | 标量 | 1.0 | 一个类别 |
| 一维数组 | 向量 | [1.0, 2,3, 3.7] | 一个特征向量 |
| 二维数组 | 矩阵 | [[1.0, 2.0,3.0],[4.0,5.0,6.0]] | 一个样本-特征矩阵 |
| 三维数组 | [[[1.,2.],[3.,4.]]] | RGB图片(宽x高x通道) | |
| 四维数组 | [[[[ ]]]] | 一个RGB图片批量(批量x宽x高x通道) | |
| 五维数组 | [[[[[ ..... ]]]]] | 一个视频批量 (批量x时间x宽x高x通道) |
创建数组:
- 形状: 如 3x4的矩阵
- 每个元素的类型: 如float32
- 每个元素的值
访问元素:
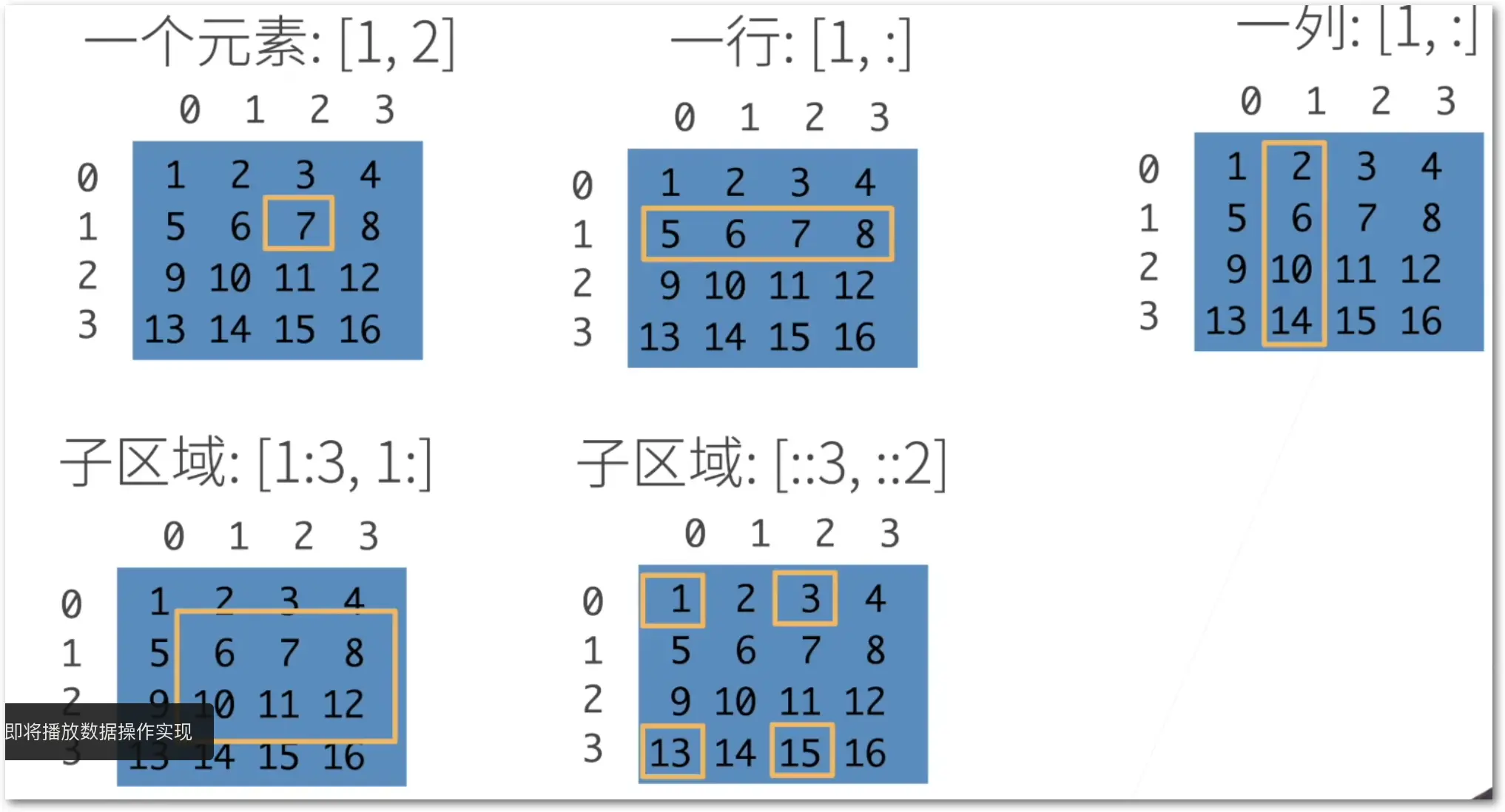
数组操作实现:
- 张量:
tersor。可以通过shape访问张量的形状和元素总数。通过reshape()改变形状。zeros()创建全0。 广播机制: (已取消此操作,num不同会报错)- 转换为
numpy:X.numpy() - 将大小为1的张量(
tensor)转换为python基本格式:a.item()、float(a)
数据预处理:
# 读取csv
import pandas as pd
data = pd.read_csv("./test.csv")
print(data)
- 缺失数据处理。可以插值或去除