前言 上一篇介绍了什么是视觉定位,以及视觉定位在各行各业的应用点和目前的研究难点在哪。本篇主要介绍视觉定位领域常用的一些数据集,分为室内定位数据集和室外定位数据集,每个数据集附有数据集获取地址和数据集样例。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
常用数据集
早期视觉定位数据集相对较少,随着研究的人越来越多,出现了很多公开的数据集,下面根据室外环境和室内环境介绍一些应用比较广泛的数据集。
室内数据集
7 Scenes数据集
由RGB-D图像、真实相机位姿和七个室内房间的3D模型组成(共约125平方米),这些图像包含无纹理表面、运动模糊和重复结构等。
数据集相关论文:
Carlevaris-Bianco N, Ushani A K, Eustice R M. University of michigan north campus long-term vision and lidar dataset [J]. The International Journal of Robotics Research, 2016, 35(9): 1023-1035.

Inloc数据集
InLoc数据集是为大规模室内定位而设计的,由于大的视点变化、移动的家具、遮挡、照明变换,待定位的查询图像和数据库图像之间存在显著的外观变化,数据集由RGB-D图像数据库组成,并添加了一组由手持设备拍摄的RGB查询图像,使其适用于室内定位任务。
数据集获取地址:
http://www.ok.sc.e.titech.ac.jp/INLOC/

Gangnam Station and Hyundai Department Store:
数据集是NAVER实验室定位数据集的一部分,由5个室内数据集组成,用于在具有挑战性的现实环境中进行视觉定位,数据集是在韩国首尔的一个大型购物中心和一个大型地铁站拍摄的,使用的是由10个摄像头和2个激光扫描仪组成的专用测绘平台,为了获得准确的地面真实相机姿态,使用激光雷达SLAM提供初始姿态,然后使用SFM优化初始姿态。数据集包含约130k张图像以及用于训练和验证的6DoF相机姿势。此外还为训练图像提供了基于稀疏激光雷达的深度图。
数据集获取地址:
https://github.com/naver/kapture/blob/main/doc/tutorial.adoc#download-a-dataset

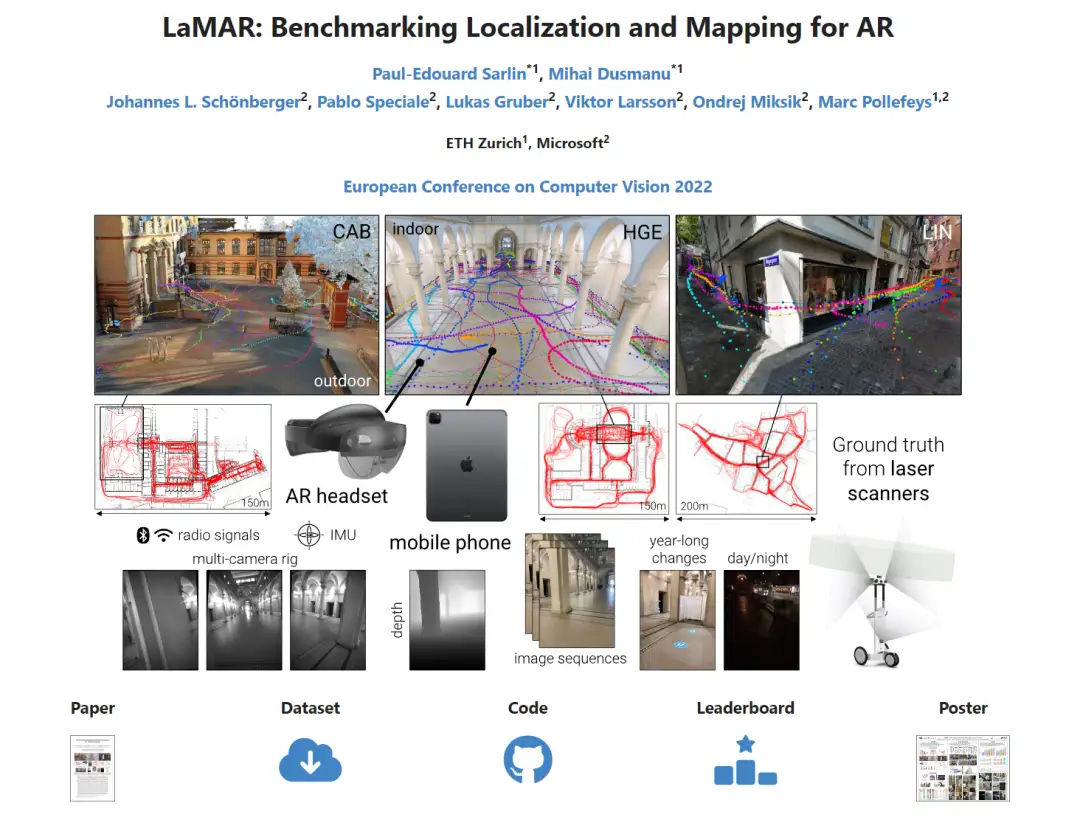
LaMAR数据集:
这是一个专门针对AR/VR应用的数据集,数据集的采集是使用带有定制的原始传感器记录应用程序的Microsoft HoloLens 2和Apple iPad Pro设备收集数据,10名参与者每人获得一台设备,并被要求在一个共同的指定区域行走,即在环境中自由行走、参观、检查和四处寻找,由此产生了不同的相机高度和运动模式,他们的轨迹没有任何计划或限制,在长达一年的时间里,参与者在白天和晚上的不同时间点访问每个地点。总的来说,每个地点都有超过100个5分钟的视频序列,在录制之前不需要以任何方式准备拍摄现场,使得可以收集众包数据,每个位置也被NavVis M6手推车或VLX背包测绘平台捕获两到三次,这些平台使用激光扫描仪和全景相机生成环境密集纹理3D模型。
数据集获取地址:
https://lamar.ethz.ch/
室外数据集
Cambridge:
包含5个场景,此数据集常用于在大规模室外城市环境中训练和测试姿态回归算法
数据集获取地址:
http://mi.eng.cam.ac.uk/projects/relocalisation/
数据集样例:


Aachen Day-Night:
基于原始亚琛数据集,其描绘了德国亚琛的旧内城,数据库图像都是在大约两年的时间里用手持相机在白天拍摄的,提供了在白天和夜间拍摄的查询图像,所有查询图像均使用手机摄像头拍摄,即 Aachen Day-Night数据集考虑了使用移动设备进行定位的场景,例如增强现实或混合现实。夜间查询图像是使用手机HDR 拍摄的,以创建(相对)照明良好的高质量图像。
数据集下载地址:
https://data.ciirc.cvut.cz/public/projects/2020VisualLocalization/Aachen-Day-Night/

RobotCar Seasons
基于RobotCar数据集的子集,描绘了英国牛津室外场景,参考图像和查询图像由安装在汽车上的三个同步摄像头捕获,分别指向左后、后和右后。这些图像是通过在 12 个月内驾驶相同的路线记录下来的。一次遍历用于定义参考条件和参考场景表示。其他遍历涵盖不同的季节和光照条件用于查询。所有图像均按顺序记录。RobotCar Seasons 数据集代表了自动驾驶场景
数据集获取地址:
https://data.ciirc.cvut.cz/public/projects/2020VisualLocalization/RobotCar-Seasons/

CMU Seasons:
描绘了美国匹兹堡地区的城市、郊区和公园场景。参考和查询图像由安装在汽车上的两个前置摄像头捕获,以大约 45 度角指向车辆的左、右。这些图像是在 1 年的时间里记录的。其中一次遍历用于定义参考条件和参考场景表示,其他遍历捕获不同的季节性条件用于查询。所有图像均按顺序记录。CMU Seasons 数据集代表自动驾驶场景
数据集获取地址:
https://data.ciirc.cvut.cz/public/projects/2020VisualLocalization/CMU-Seasons/

SILDA:
使用来自球形相机的原始图像来表示真实世界条件下的定位,涵盖了广泛的高端应用,如虚拟现实,地图和机器人。数据集是在12个月的时间里采集的,覆盖了伦敦帝国理工学院周围1.2公里的街道。条件包括天气(晴、雪、雨)和时间(中午、黄昏、夜晚)的变化。
数据集获取地址:
https://www.visuallocalization.net/datasets/

下篇将对视觉定位常用的评估标准及其公式算法进行总结,并分享几个好的开源项目以供学习研究。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
AAAI 2023 | 轻量级语义分割新范式: Head-Free 的线性 Transformer 结构
标签:难点,场景,定位,领域,专栏,图像,视觉,数据,CV From: https://www.cnblogs.com/wxkang/p/17361801.html