问卷中的非量表数据应该怎么分析?
- 样本特征分析
对于非量表题的描述可以使用频数分析或者可视化图形进行描述,比如单选题也可以使用柱形图等进行展示,通过结果展示了解样本的基本情况,最后结合分析结果提出建议等。 - 差异分析
除此之外还可以研究样本之间的差异关系,此步可以结合人口变量学进行研究,比如年龄、性别以及学历等等。一般非量表分析使用的差异方法为卡方检验。卡方分析又成交叉表分析,他一般通过分析不同类别数据的相对选择频数和占比情况进行差异判断,单选题和多选题也可以使用卡方分析进行对比差异分析。如果从选择题角度来看一般卡方分析可以分为两类一类是单选题卡方分析和多选题卡方分析。下面进行说明。 - 影响关系分析
非量表数据还可能设计影响关系的研究,比如研究相关因素对样本群体对购买课程影响情况,可以考虑使用回归分析,但是如果因变量为定类(分类)变量,那么可以使用logit回归分析。一般logit回归分析会分为三种,二元logit回归分析,多分类logit回归分析以及有序logit回归分析。
一、样本特征分析
对于非量表数据进行基本描述,得到相应结论,举个例子进行下面的说明,本案例为研究某在线英语学习网站上各种因素对课程购买意愿的影响情况,初步拟定研究产品、促销、渠道推广、价格、个性化服务以及隐私保护这六个因素对消费者购买意愿的影响情况。其中包括量表题以及人口变量等(文末有问卷说明以及案例数据)。比如想研究被调查者的月收入水平的分布情况,结果如下:
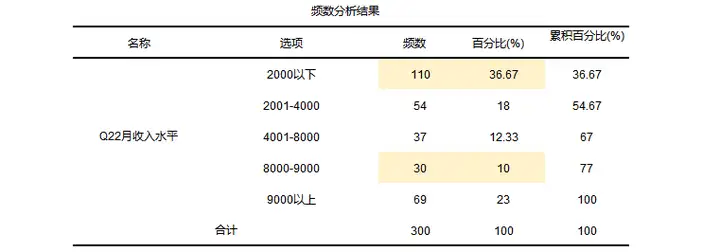
从结果总可以得到被调查者一共有300人,其中月收入在2000元以下的共有110人,占总数的36.67%,被调查者中月收入为8000-9000的人最少,共有30人占总人数的30%,由此可见收入还是有差距的,后续分析时可以进行深入分析。
二、差异分析
如果针对选择题类型,卡方分析可以分为两类一类是单选题卡方检验一类是多选题卡方分析,一般多选题进行卡方分析比较复杂。
1.单选题卡方分析
卡方分析是研究两个定类变量的差异对比,是在交叉的基础上加上统计检验(卡方值和p值),对于分析结果进行p值判断,然后说明两个定类变量是否有联系,比如性别和月收入是否有联系等等。在分析中首先对p值进行判断,如果p值小于显著水平,则说明在显著水平下呈现出显著性,比如想要研究“性别和职业是否有差异关系”。
结果如下:
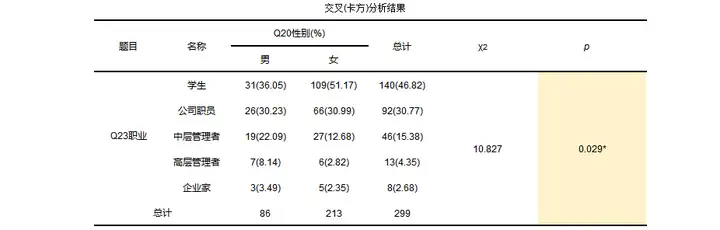
从结果可以看出被调查者中女性比男性多,不论男性还是女性学生占比多占总数的46.82%,企业家均占比最少,模型的卡方值为10.827,p值约为0.029小于0.05,所以说明不同性别的被调查者的职业有差别。
2.多选题卡方分析
多选题的卡方分析理论上也是研究两个定类数据之间的关系,区别在于这里的自变量为单选题数据,因变量为多选题数据。可以使用SPSSAU【单选-多选】进行分析。比如想研究“不同收入和更关注网络课程的方面进行交叉分析”操作如下:
结果如下:
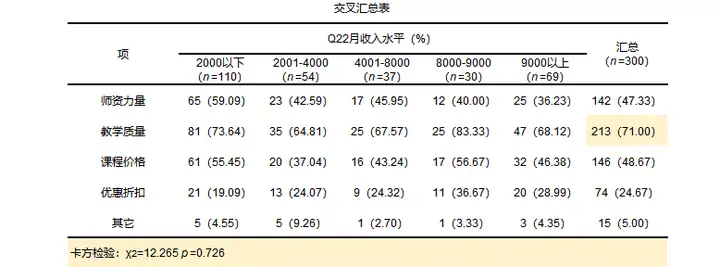
从结果来看不管是什么收入水平多数人更在乎网络课程的教学质量,共有213个人选择此项,所以想要更好经营网络课程这一项,需要提升教学质量可能效果更好,最后发现卡方检验的卡方值为12.265,p值为0.726大于0.05,所以不同的收入水平对关注网络课程的点没有差异。接下来研究影响关系。
三、影响关系分析
Logit回归分析也是研究自变量对因变量影响的分析,但是logit回归的因变量需要为定类变量,一般logit回归分析包括二元logit回归分析,多分类logit回归分析,有序logit回归分析,三者区别如下:

1.二元logit回归分析
这类问题的特点是因变量(Y)是定类数据,并且只使用两个数字去表示,规定为 1和0,并且 只能是1或0,比如1代表愿意0代表不愿意;1代表会0代表不会;1代表可以0代表不可以;1代表喜欢0代表不喜欢。
如果想研究某些因素(X)对于因变量(Y)的影响关系,并且因变量(Y)只有两个取值时(并且 只能是0和1),此时则应该使用二元Logistic回归分析。
2.多分类logit回归
多分类logit回归分析用于研究X对于Y的影响关系,其中X,也可以是定类数据(如果X为定类数据,需要做虚拟(哑)变量设置),Y为多分类定类数据。针对多分类logit回归分析时,可分为三个步骤。
第一:模型的基本背景情况说明;比如模型研究X对于Y的影响,X分别是那些,Y具体情况如何等。
第二:针对模型的构建和比较过程进行描述,包括分析p 值来检测模型构建是否有意义,以及模型构建时的重复选择过程,使用AIC和BIC准则对比,选出最优模型等;
第三:针对模型的具体情况进行分析,首先分析p 值,如果此值小于0.05,说明X对于Y有影响关系,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出回归模型构建公式,以及模型的预测准确率情况等。分析例子可以参考:
3.有序logit回归
有序Logit回归分析用于研究X对于Y的影响关系,如果X为定类数据,一般需要做虚拟(哑)变量设置,Y为有序定类数据。有序Logit回归分析时,首先进行模型平行性检验,如果p值大于0.05,说明满足平行性检验,如果p值小于0.05,说明不满足平行性检验,此时SPSSAU建议使用多分类Logit回归分析;满足平行性检验后,接着再具体研究影响关系情况即可,比如是正向影响还是负向影响关系等;除此之外,还可以写出有序Logit回归分析的模型构建公式,以及模型的预测准确率情况等。
标签:分析,logit,量表,回归,定类,卡方,数据,模型 From: https://www.cnblogs.com/spssau/p/17356022.html