更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。
以下为 ByteHouse 技术白皮书【数据导入导出】版块摘录。
技术白皮书(Ⅰ)(Ⅱ)(Ⅲ)精彩回顾:
https://xie.infoq.cn/article/5c9471c7adb58e4bb43b69c4d
https://xie.infoq.cn/article/086b4e706965a6bd81f6a6ff2
https://xie.infoq.cn/article/a0dceef1588fe6c58247d3b37
ByteHouse 数据导入导出
ByteHouse 包括一个数据导入导出(Data Express)模块,负责数据的导入导出工作。
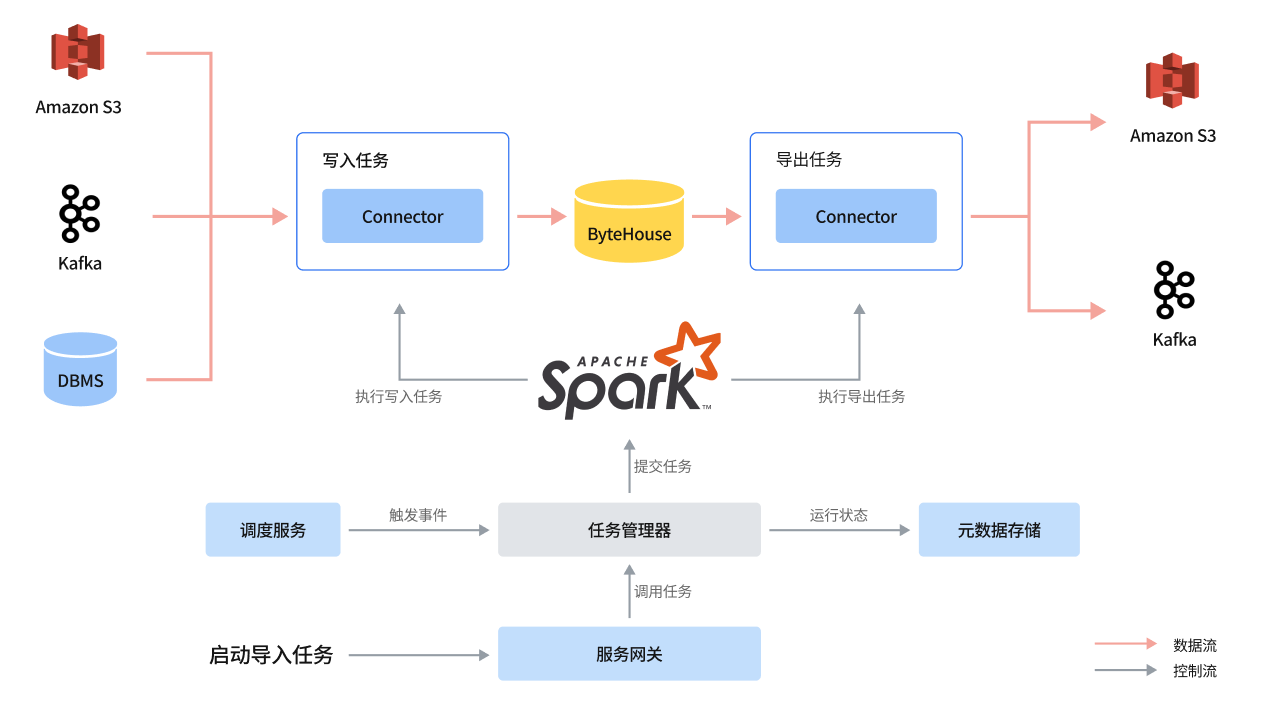
Data Express 模块架构图
Data Express 为数据导入/导出作业提供工作流服务和快速配置模板,用户可以从提供的快速模板创建数据加载作业。
DataExpress 利用 Spark 来执行数据迁移任务。
主要模块:
-
JobServer
-
导入模板
-
导出模板
JobServer 管理所有用户创建的数据迁移作业,同时运行外部事件触发数据迁移任务。
启动任务时,JobServer 将相应的作业提交给 Spark 集群,并监控其执行情况。作业执行状态将保存在我们的元存储中,以供 Bytehouse 进一步分析。
ByteHouse 支持离线数据导入和实时数据导入。
离线导入
离线导入数据源:
-
Object Storage:S3、OSS、Minio
-
Hive (1.0+)
-
Apache Kafka /Confluent Cloud/AWS Kinesis
-
本地文件
-
RDS
离线导入适用于希望将已准备好的数据一次性加载到 ByteHouse 的场景,根据是否对目标数据表进行分区,ByteHouse 提供了不同的加载模式:
-
全量加载:全量将用最新的数据替换全表数据。
-
增量加载:增量加载将根据其分区将新的数据添加到现有的目标数据表。ByteHouse 将替换现有分区,而非进行合并。
支持的文件类型
ByteHouse 的离线导入支持以下文件格式:
-
Delimited files (CSV, TSV, etc.)
-
Json (multiline)
-
Avro
-
Parquet
-
Excel (xls)
实时导入
ByteHouse 能够连接到 Kafka,并将数据持续传输到目标数据表中。与离线导入不同,Kafka 任务一旦启动将持续运行。ByteHouse 的 Kafka 导入任务能够提供 exactly-once 语义。您可以停止/恢复消费任务,ByteHouse 将记录 offset 信息,确保数据不会丢失。
支持的消息格式
ByteHouse 在流式导入中支持以下消息格式:
-
Protobuf
-
JSON
更多的导入数据源以及导出功能正在不断完善中。