更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。
以下为 ByteHouse 技术白皮书作业执行流程版块摘录。
技术白皮书(上)(中)精彩回顾:
https://xie.infoq.cn/article/5c9471c7adb58e4bb43b69c4d
https://xie.infoq.cn/article/086b4e706965a6bd81f6a6ff2
ByteHouse 作业执行流程
ByteHouse 中的作业按照响应优先级分为 3 大类:Read query、Write query 和 Background 的作业。不同类型的作业,按照前面所述,可以运行同一个工作节点上,也可以分离开来。
数据查询流程
服务节点负责响应和接受用户查询请求,并调度到相应的计算组中去执行,并回传结果给服务节点。各个计算节点执行完子查询之后, 很多时候会有相应计算结果要集中处理,如果希望这一层有计算组的隔离,务节点的部分功能例如聚合最终结果需要下放到计算组中的计算节点中去。
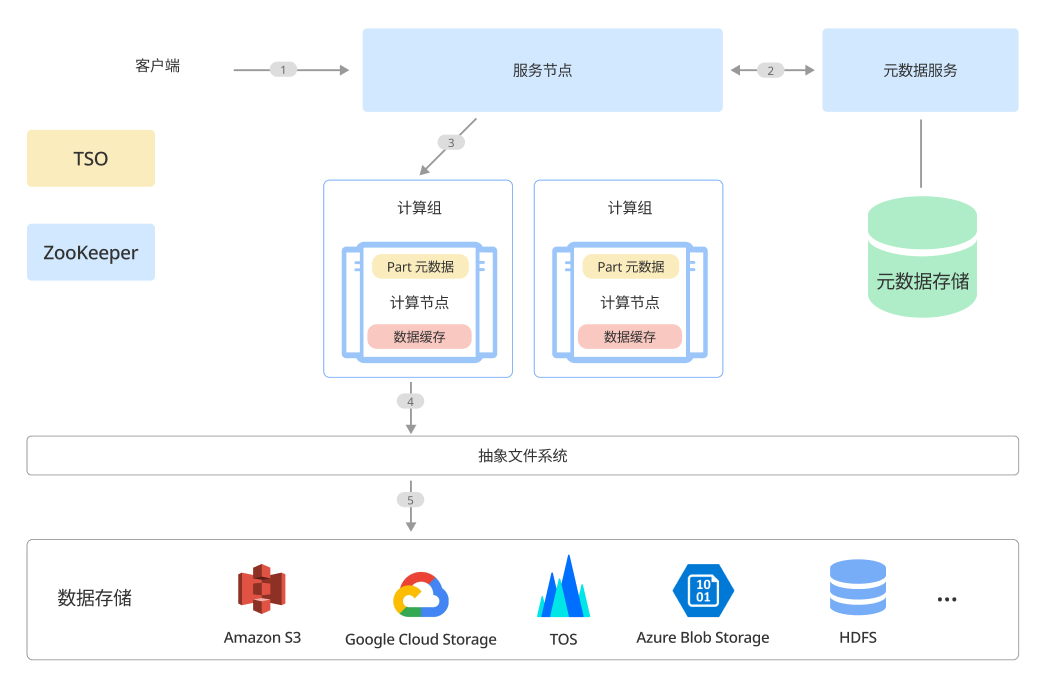
Read Query 模块交互图
Query 的执行过程:
-
用户提交 Query 到服务节点
-
从元数据服务获取需要的元数据信息,对 Query 进行 Parse,Planning,Optimize,生成执行计划
-
服务节点对 Query 进行调度
-
计算节点接收到 Query 子查询
-
Query 从远程文件系统获取原始数据,并根据 Query 的执行计划在计算节点上执行,并发回计算结果给服务节点汇总。
数据写入流程
ByteHouse 实现了读写分离,有单独写入节点来执行写入请求,写入请求分为几类:insert values, insert infile, insert select,insert values 可能包含大量数据集,为避免网络传输开销直接由服务节点本地执行 insert 而无需转发给写入节点来执行。
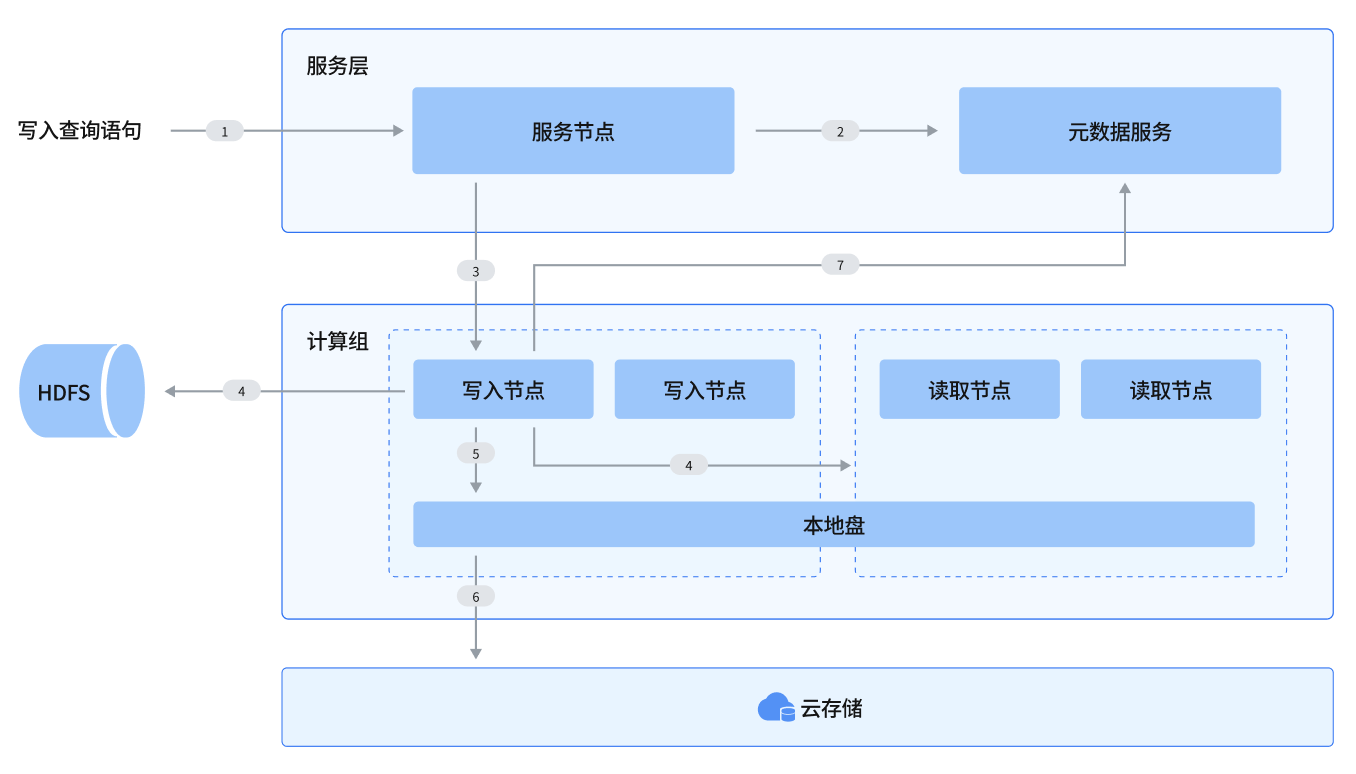
Write Query 模块交互图
Query 的执行过程:
-
用户提交 Write Query 到服务节点
-
服务节点从元数据服务获取需要的元数据信息,对 Query 进行 parse,planning,optimize,生成执行计划,根据写入类型分为以下两种模式来执行:
Local 模式:insert values 操作直接由服务节点跳转到步骤四直接执行
分布式模式:对于 insert infile/select 模式直接将执行计划信息分发给一个写入节点执行
-
服务节点对写入请求根据调度策略选择合适的写入节点执行
-
写入节点从读取节点(insert select)或者外部存储(insert infile hdfs)读取数据流
-
写入节点写入数据到本地盘
-
写入节点 导出 本地盘到云存储
-
写入节点 更新元数据
后台任务
为了更好的查询性能,会有一些作业在后台对写入的数据进行更进一步的处理。ByteHouse 中主要包括如下 3 种后台任务。
-
Merge:将不同的 parts 文件按 Primary Key 做排序合并成一个大的 part 文件。
-
Checkpoint: 对表的任意更新,例如元数据的改变,数据字典等异步构建操作会产生新的增量数据文件,这部分新产生的增量和原有的数据文件会在后台合并成一个新的数据文件。
-
GC:空间回收,当数据文件中的垃圾空间超过一定阈值后,会触发后台作业回收空间.