更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
随着数据的应用场景越来越丰富,企业对数据价值反馈到业务中的时效性要求也越来越高,很早就有人提出过一个概念:
数据的价值在于数据的在线化。实时计算起源于对数据加工时效性的严苛需求:数据的业务价值随着时间的流逝会迅速降低,因此在数据产生后必须尽快对其进行计算和处理,从而最大效率实现数据价值转化,对实时数仓的建设需求自然而然的诞生了。而建设好实时数仓需要解决如下几个问题:
一、稳定性:实时数仓对数据的实时处理必须是可靠的、稳定的;
二、高效数据集成:流式数据的集成必须方便高效,要求能进行高并发、大数据量的写入;
三、极致性能要求:实时数仓不能仅限于简单查询,需要支持复杂计算能力,且计算结果可秒级返回;
四、灵活查询:需要具备自助分析的能力,为业务分析提供灵活的、自助式的汇总和明细查询服务;
五、弹性扩缩:需要具备良好的扩展性, 必须架构统一具备扩展性,可为 IT 建设提供灵活性。
针对以上问题,火山引擎不断在业务中摸索,总结了基于 ByteHouse 建设实时数仓的经验。
选择 ByteHouse 构建实时数仓的原因
ByteHouse 是火山引擎在 ClickHouse 的基础上自研并大规模实践的一款高性能、高可用企业级分析性数据库,支持用户交互式分析 PB 级别数据。其自研的表引擎,灵活支持各类数据分析和保证实时数据高效落盘,实现了热数据按生命周自动冷存,缓解存储空间压力;同时引擎内置了图形化运维界面,可轻松对集群服务状态进行运维;整体架构采用多主对等架构设计,架构安全可靠稳定,可确保单点无故障瓶颈。
ByteHouse 的架构简洁,采用了全面向量化引擎,并配备全新设计的优化器,查询速度有数量级提升(尤其是多表关联查询)。
用户使用 ByteHouse 可以灵活构建包括大宽表、星型模型、雪花模型在内的各类模型。
ByteHouse 可以满足企业级用户的多种分析需求,包括 OLAP 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等各种应用场景。
ByteHouse 优势一:实时数据高吞吐的接入能力
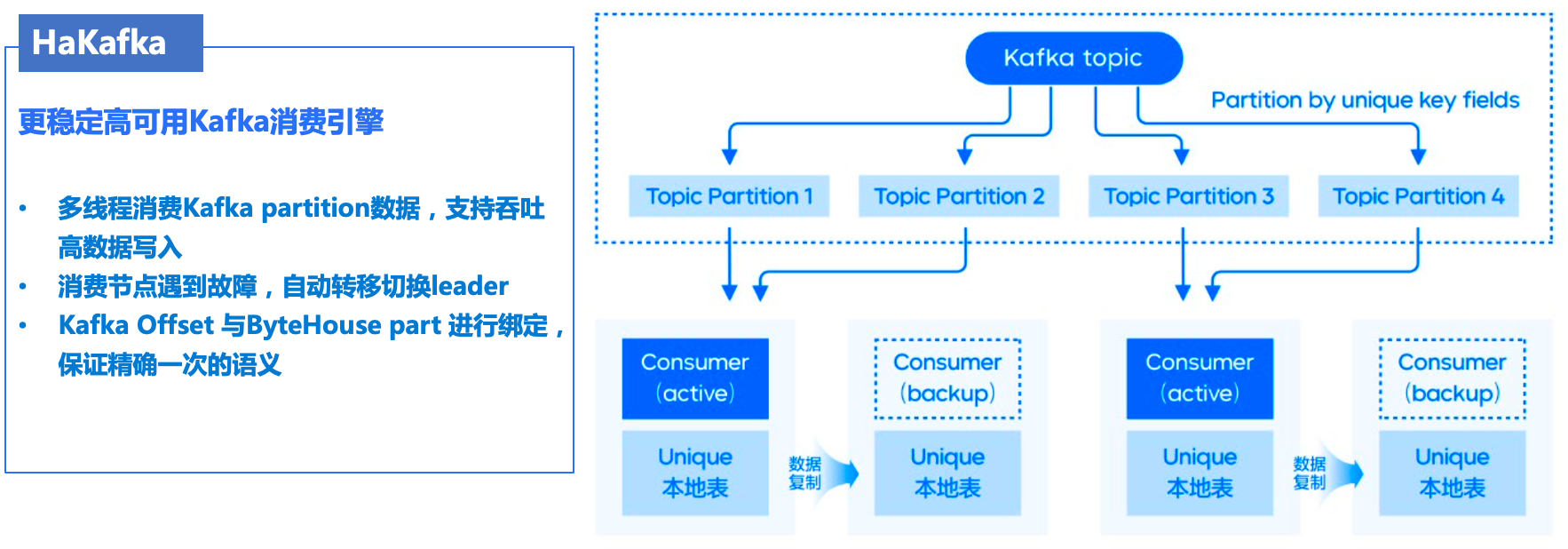
面对业务大数据量的产生,需要高效可靠实时数据的接入能力,为此我们自研了 Kafka 数据源接入表引擎 HaKafka ,该表引擎可高效的将 Kafka 的数据接入 ByteHouse ,具有有如下特性:
-
数据接入高吞吐性,支持了多线消费 Kafka topic 对应 Partition 的数据,满足大数据量实时数据接入的需求。
-
数据接入高可靠性,通过 Zookeeper 来实现主备消费节点管理,比如,当线上出现某个节点出现故障或无法提供服务时,可以通过 Zookeeper 心跳感知机制自动切换到另一个节点提供服务,以此来保障业务的稳定性。
-
数据接入原子性,引擎自行管理 Kafka offset ,将 offset 和 parts 进行绑定在一起,来实现单批次消费写入的原子性,当中途消费写入失败,会自动将绑定的 parts 撤销,从而实现数据消费的稳定性。
具体流程原理如下图所示
ByteHouse 优势二:基于主键高频数据更新能力
随着实时数据分析场景的发展,对实时数据更新的分析需求也越来越多,比如在如下的业务场景就需要实时更新数据能力:
-
第一类是业务需要对它的交易类数据进行实时分析,需要把数据流同步到 ByteHouse 这类 OLAP 数据库中。大家知道,业务数据诸如订单数据天生是存在更新的,所以需要 OLAP 数据库去支持实时更新。
-
第二个场景和第一类比较类似,业务希望把 TP 数据库的表实时同步到 ByteHouse,然后借助 ByteHouse 强大的分析能力进行实时分析,这就需要支持实时的更新和删除。
-
最后一类场景的数据虽然不存在更新,但需要去重。大家知道在开发实时数据的时候,很难保证数据流里没有重复数据,因此通常需要存储系统支持数据的幂等写入。
基于以上业务场景的需求,我们自研了基于主键更新数据的表引擎 HaUniqueMergeTree,该表引擎即满足高效查询性能要求,又支持基于主键更新数据的表引擎,有如下特性:
-
通过定义 Unique Key 唯一键,来提供数据实时更新的语义,唯一键的选择支持多字段和表达式的模式;
-
支持分区级别数据唯一和表级别数据唯一两种模式;
-
支持多副本高可靠部署,实测数据去重写入吞吐达每秒 10 万行以上(10w+/s),很好的解决了社区版 ReplacingMergreTree 不能高效更新数据的痛点。
具体流程原理如下图所示

具体的原理细节可查阅之前发布的文章 干货 | ClickHouse增强计划之“Upsert”
ByteHouse 优势三:多表 Join 查询能力
在构建实时数据分析的场景中,我们常在数据加工的过程中,将多张表通过一些关联字段打平成一张宽表,通过一张表对外提供分析能力,即大宽表模型。其实大宽表依然有它的局限性,一是,生成每一张大宽表都需要数据开发人员不小的工作量,而且生成过程也需要一定的时间;二是,生成宽表会产生大量的数据冗余。
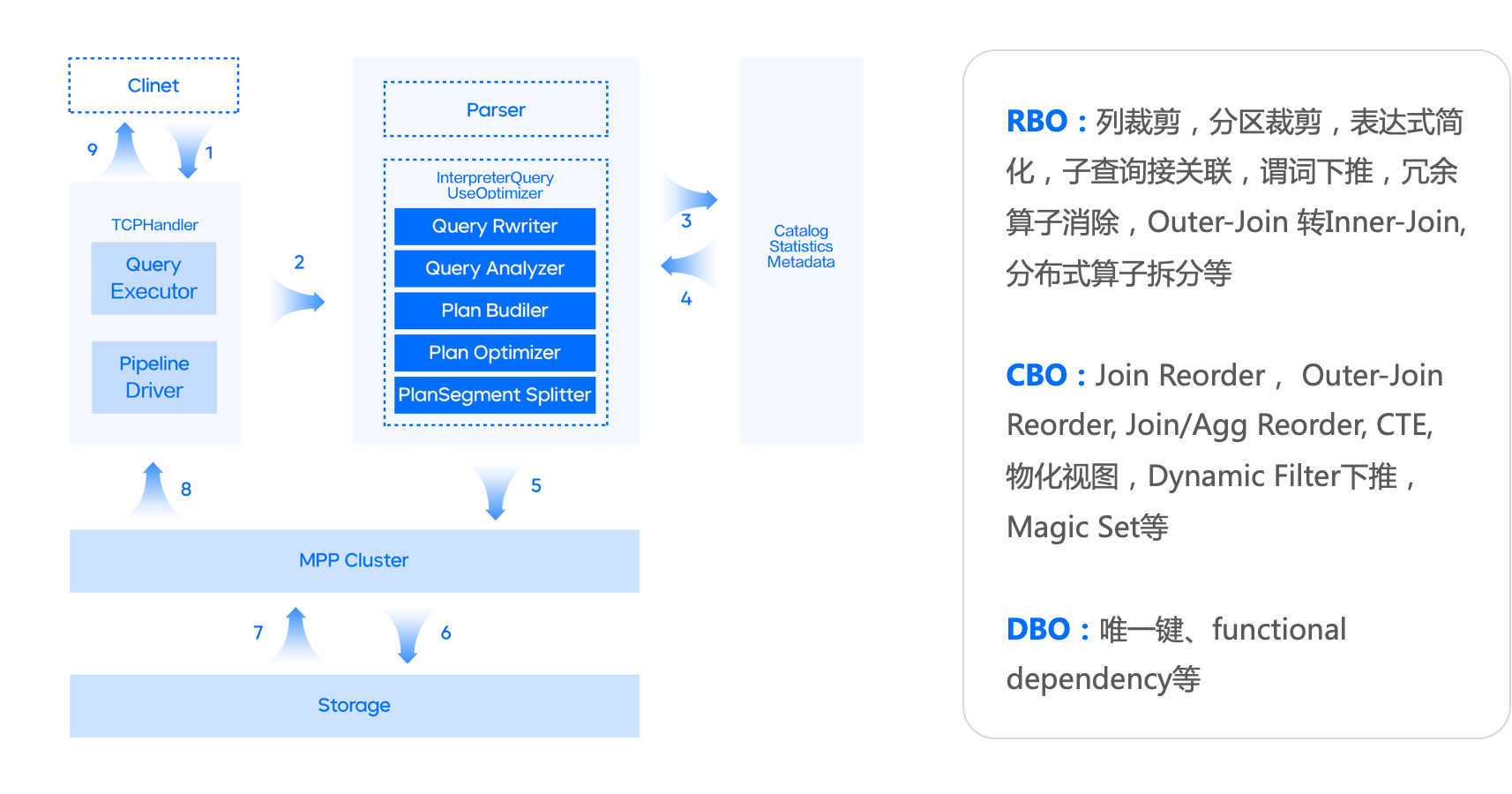
针对宽表模型的局限性,我们从 0 到 1 自研实现了查询优化器,非常好的支持复杂查询的需求,有如下特性:
-
兼容两种 SQL 语法,支持 ANSI SQL 和原生 CLICKHOUSE SQL ;
-
支持基于 RBO 优化能力,即支持:列裁剪、分区裁剪、表达式简化、子查询解关联、谓词下推、冗余算子消除、Outer-JOIN 转 INNER-JOIN、算子下推存储、分布式算子拆分等常见的启发式优化能力;
-
支持基于 CBO 优化能力,基于 Cascade 搜索框架,实现了高效的 Join 枚举算法,以及基于 Histogram 的代价估算,对 10 表全连接级别规模的 Join Reorder 问题,能够全量枚举并寻求最优解,同时针对大于 10 表规模的 Join Reorder 支持启发式枚举并寻求最优解。CBO 支持基于规则扩展搜索空间,除了常见的 Join Reorder 问题以外,还支持 Outer-Join/Join Reorder,Magic Set Placement 等相关优化能力;
-
分布式计划优化,面向分布式 MPP 数据库,生成分布式查询计划,并且和 CBO 结合在一起。相对业界主流实现:分为两个阶段,首先寻求最优的单机版计划,然后将其分布式化。我们的方案则是将这两个阶段融合在一起,在整个 CBO 寻求最优解的过程中,会结合分布式计划的诉求,从代价的角度选择最优的分布式计划。对于 Join/Aggregate 的还支持 Partition 属性展开。
-
高阶优化能力,实现了 Dynamic Filter pushdown、单表物化视图改写、基于代价的 CTE (公共表达式共享)。
具体的原理细节可查阅之前发布的文章 干货 | ClickHouse增强计划之“查询优化器”
实时数仓建设方案
借助 Flink 出色流批一体的能力,ByteHouse 极致的查询性能,为用户构建实时数仓,满足业务实时分析需求。
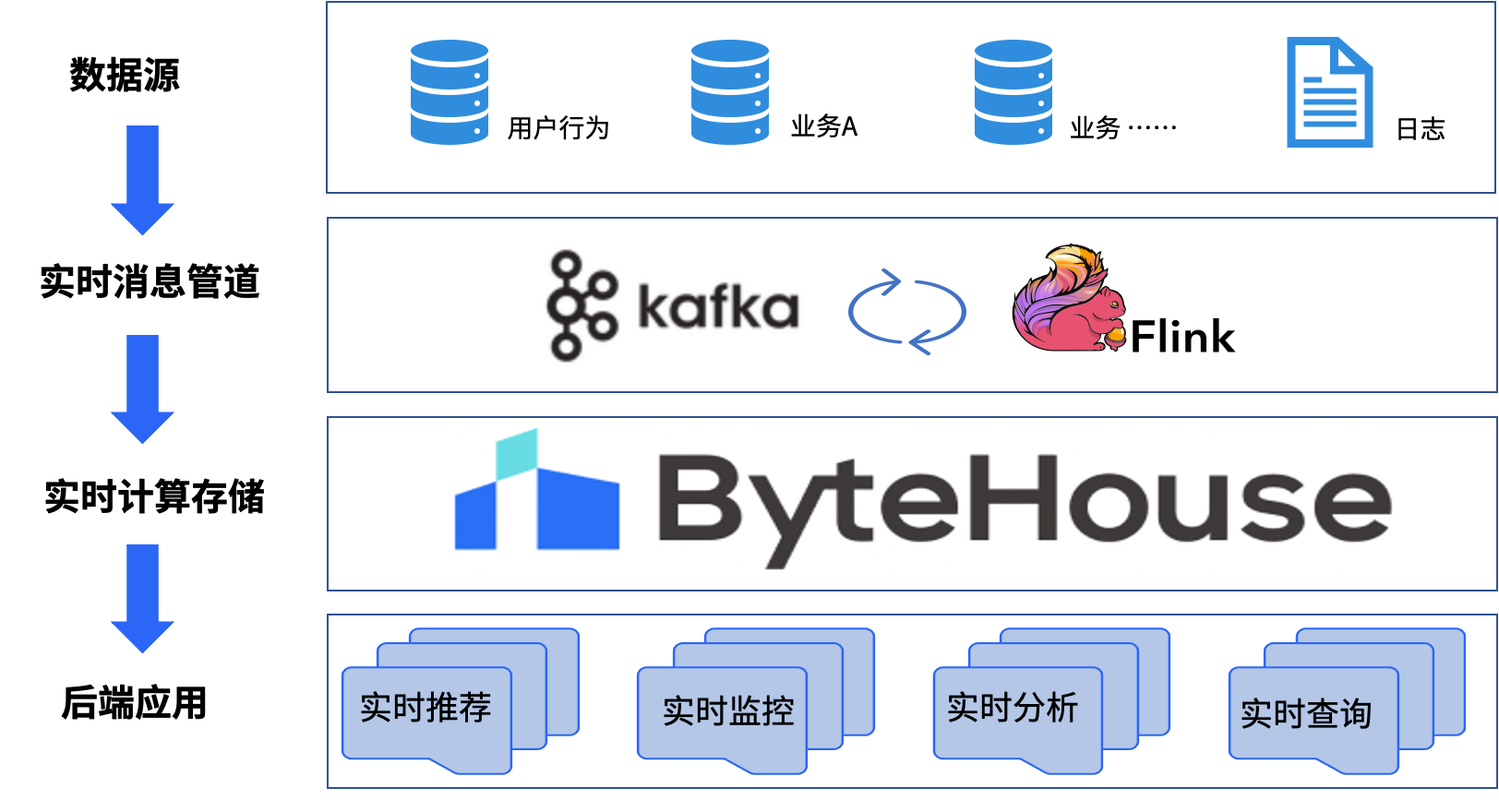
Flink 作为流式数据处理引擎,使用 Flink SQL 为整个实时数仓数据提供数据转化与清洗;
Kafka 作为流式数据临时存储层,同时为 Flink SQL 数据转化与清洗提供缓冲作用,提高数据稳定性;
ByteHouse 作为流式数据持久化存储层,使用 ByteHouse HaKafka 、HaUniqueMergeTree 表引擎可将 Kafka 临时数据高效稳定接入储存到 ByteHouse ,为后端应用提供极速统一的数据集市查询服务。具体的数据链路如下图所示
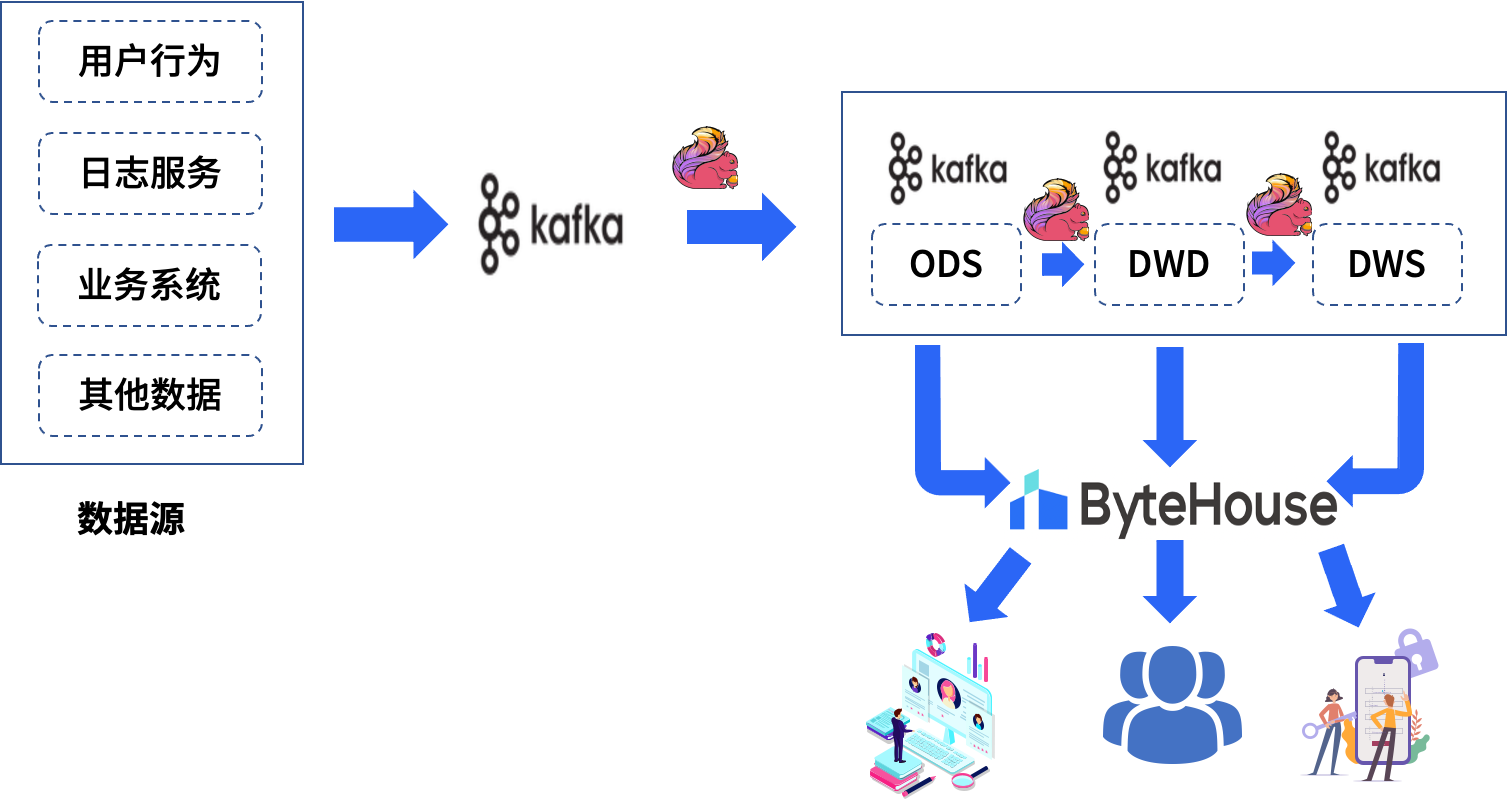
实时数仓各逻辑层功能职责如下:
ODS 层(Operational Data Store)
把生产系统的数据导入消息队列,原则上不做任何清洗操作,字段信息跟数据源保持一致。目的是为了对数据源做收敛管理,数据排查上也好做溯源回查。
DWD 层(Data Warehouse Detail)
DWD 层采用维度建模理论,针对业务内容梳理业务实体的维表信息和事实表信息,设计 DWD 明细宽表模型,根据设计好的逻辑模型对 ODS 层的数据进行数据清洗,重定义和整合,整合主要包含多流 join 和维度扩充两部分内容, 建设能表达该业务主题下具体业务过程的多维明细宽表流。每一份 DWD 表从业务梳理->模型设计->数据流图->任务开发链接->数据校验结果->数据落地信息->常用使用场景归纳。
DWS 层(Data Warehouse Summary)
该层级主要在 DWD 层明细数据的基础上针对业务实体跨业务主题域建设汇总指标,根据统计场景,设计汇总指标模型。
APP 层(Application)
作为对接具体应用的数仓层级,由 ByteHouse 提供统一的数据服务,是基于 DWD 和 DWS 层对外提供一些定制化实时流。
点击跳转 ByteHouse云原生数据仓库 了解更多
标签:数仓,实时,查询,引擎,ByteHouse,数据 From: https://www.cnblogs.com/bytedata/p/17247374.html