故障处理troubleshooting是做互联网SRE最心跳的事情,没有之一,也是考验一个SRE是否能够独挡一面的最有效方式。
首先它的发生是随机的,完全未知,尤其是大型互联网系统,海量的用户,故障发生后精神高度紧张,要顶着巨大的压力,用最短的时间协同各方制定方案、恢复业务,尤其考验一个人的综合素质。
其次,处理期间要面临各种老板、质量部门和未知部门未知人员的盘问,各种客服报过来的用户投诉和催促(PS 平时真不知道有这么多人关心着我们),对外信息的同步升级、对内故障的处理都要兼顾,毫不夸张,就是一场必须用最快速度打赢的突击战,需要SRE团队在平时就训练有素,居安思危,同时,它也是一个SRE向高段位修炼的最好道场,我个人曾一度被故障搞的神经衰弱,真的很刺激,艺人常说台上一分钟台下十年功,其实SRE和后端研发何尝不是。
那么,我们如何处理好一个大型互联网系统的突发故障呢,有没有一些方法论在里面呢?让我们捋捋。
一、丰富的业务储备
1、百发百中生死告警
告警是发现故障的最有效途径,其建设要围绕3个点准、少、快,准是告警的信息准,少是告警的数量少都是有效告警,快指的是告警的实效性高速度快。
作为大型互联网系统,服务和指标都是海量的,告警再怎么分级、收敛还是多,所以必须建立一个用户使用角度的生死告警,并且不断修正确保其准确,生死告警代表系统的生死,任何人在任何时候任何地点看到都需要立刻响应。
我刚到小爱时,告警收到崩溃,时常手机烫到死机,告警的短信铃音连成直线,但很多时候发现小爱其实是正常的,沉重的历史包袱要把存量告警梳理一遍成本太大了,绞尽脑汁后,果断的拉齐所有部门,建立了小爱的唯一生死告警,后面对IoT米家也做了同样的操作,搞好后大家面对告警都松了一口气,可以看下我们生死告警的群公告。
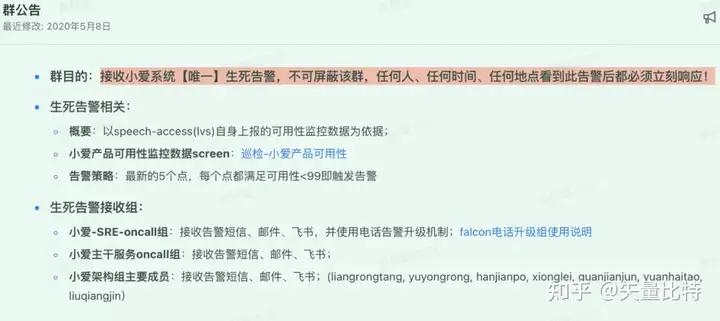
所以你的业务一定要有P0+的生死告警,判断到底是真故障还是假故障。
2、深度理解系统架构
SRE和系统运维的最大区别,我认为SRE得在系统运维的基础上研究业务,研究系统架构、产品架构,SRE面向的是用户稳定性。
大型互联网系统,模块多、依赖关系复杂,运行的资源环境复杂,如果不了解系统架构,在出现问题时基本就是抓瞎的,不知道服务的功能,不知道到故障后对用户的影响,不知道出了问题后查哪些指标,不知道服务依赖了哪些第三方资源,不知道服务间是怎么调度的,等等都会让SRE局限在系统外的狭窄空间,只能被动的接受安排,很难对产品稳定性提出建设性的意见。
所以要高效处理好故障,一定要和研发的架构师一起深入理解系统架构,而不仅仅停留在基础资源iass层。
3、各种预案了然于心
Ops是SRE的本职工作,一定要在日常就勤加练习,对各种原子预案可以“闭着眼”快速操作,详见《心法|一文吃透SRE故障预案6把刀刀》。
4、完备的DevOps工具
从故障发现、故障诊断、故障恢复全过程都离不开工具的支持,一定要想尽办法使用DevOps工具提效,能自动化全部自动化,人肉已经不能很好的处理大型互联网场景下的故障处理,效率太低。
我们团队内部研发了AiFault智能应用运维中台,从故障发现到恢复做了全流程的设计,虽然目前还有很多要做的地方,但已经大大提升了我们在故障发现、分析、诊断、恢复、复盘的效率,上张图。
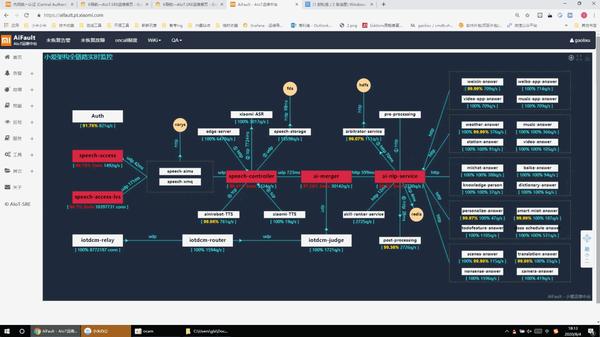 https://vdn6.vzuu.com/SD/d40828d6-4bef-11ec-9d3c-f2abacb611e0.mp4?pkey=AAVROk7lUrSq0TswhZqeEjBsg_oY_eLRyUs03FfkOyHrdXHhw1hSk_NF5Kt1Y3MvvNxbZ1H2aCK3HuFIWfbC6NH0&c=avc.0.0&f=mp4&pu=078babd7&bu=078babd7&expiration=1681966062&v=ks6
https://vdn6.vzuu.com/SD/d40828d6-4bef-11ec-9d3c-f2abacb611e0.mp4?pkey=AAVROk7lUrSq0TswhZqeEjBsg_oY_eLRyUs03FfkOyHrdXHhw1hSk_NF5Kt1Y3MvvNxbZ1H2aCK3HuFIWfbC6NH0&c=avc.0.0&f=mp4&pu=078babd7&bu=078babd7&expiration=1681966062&v=ks6
二、强劲的综合素质
1、临时应变能力
故障的突发性、不可预见性、每次处理的人都不一样注定了很多故障要具体故障具体分析,虽然有一些规律在里面,但更多的需要临时应变,所以要成为一名优秀的SRE要锻炼的是综合素质,不仅仅在技术层面,详见《一个优秀的大型互联网SRE需要具备哪些能力?》。
2、组织协调能力
大多数故障需要跨部门多人协同处理,SRE需要起到组织、协调引导故障快速解决的作用,所以组织协调能力不可或缺。
3、快速的决断力
不善决断对处理故障是个大伤,因为故障期间每分每秒都很珍贵,而且基本上充斥着各种决策,每个决策都需要权衡利弊不能犹豫,所以要独挡一面的处理复杂的故障,一定要锻炼快速的决断力。
4、迅速的执行力
快速决断后,就要快速的执行,执行过程一定不能拖延,快速操作做到闭环。
5、优秀的心理素质
用户量越大的系统、责任心越强的人,处理故障所需要的心理素质就越强大,否则根本就无法在那种高压的环境下从容的处理,期间还要面临故障延长带来的定级压力,所以要做大型互联网系统的SRE,真的要有一颗强大的心。
三、有章法的处理过程
具备了这些储备和素质后,算是有了和故障战斗的能力,但还不够,处理过程还需要遵循一些战术和章法,才能做到有条不紊,快速结束战斗、取得胜利。
收到告警后,SRE首先快速判断影响范围,第一时间通知到Oncall群,并@到相关研发,如果影响严重立刻开启电话会议,并把研发和SRE拉入电话会议。
大型互联网系统模块众多、依赖关系和运行环境复杂,研发和SRE要快速通过各种监控、指标的变化分析定位大概故障点,并将可疑的问题罗列出来,然后将其分发下去分别快速落实,此过程的价值观一定是先恢复业务再排查问题,但往往得排查到能足够支撑预案决策的原因,再由总指挥牵头制定恢复方案,再由SRE和研发去分工执行,验证结果是否符合预期,循环往复直至故障恢复,下面我们从两个角度看一下。
1、故障临时组织——分工协作篇
在这里就引出了一个最重要的点——因故障临时聚在一起的这些人如何快速建立组织、高效协作?谁该干什么该如何分工?一些大的故障会有几十个人、N多部门参与处理,如何保证处理过程有序而不乱?在经过无数次故障后,我认为一般要有5类角色:
总组织(流程专家,发动机角色,组织大家快速分工到位,形成作战室,负责过程纠偏,一般是SRE)
总指挥(对恢复方案负责,带领技术专家们,拿主意做决策,一般默认在场经验最丰富的架构师)
执行官(对各种执行负责,一般是由经验丰富的SRE和研发)
信息官(对故障恢复情况周期性通告,内、外信息的上通下达,一般是SRE)
外部团队(按需参与,一般由执行官负责调度)
生产力决定生产关系,有了好的生产关系,生产力才能上去,所以上面的分工尤其重要,根据故障的大小这5类角色可以复用,但不可裁剪,总组织在里面尤其重要,另外关于角色,也不一定很刻板的言明指定,协作多了后会有默契在里面,每一次doublecheck,每一次分工其实都是对人的授权,不管言明与否,如果要高效快速,不妨按照这种分工试一下。
你会发现,在一些复杂故障的处理过程中,会有源源不断的信息从执行官、信息官反馈到总指挥,总指挥协同他的专家组进行分析决策,再把新的执行指令分发下去,如果大家目标偏了,比如陷入到了问题中,总组织负责识别并纠偏,整个临时组织的执行力、反馈力都是极强的。
我印象最深的一次故障,和小爱架构的负责人梁荣堂约着去温榆河遛弯,结果还没进景区告警了,在公园门口从早晨10点处理到下午6点,全天8个小时一直在电话会中,不停的决策执行反馈、决策执行反馈,那个强度和压力是巨大的,但收获也是巨大的,毫不夸张的讲,一次重大故障,基本能把系统的架构摸得门儿清。
2、故障排查过程——循序渐进篇
故障排查也是要遵循章法的,在《心法|一文吃透SRE故障预案6把刀》里提过,整个过程会从轻到重进行分析操作,比如C3机房的某个实例告警,不会一开始就把所有流量全部切到另一个机房,也不会一开始就找大老板申请机动资源劳民伤财的紧急扩容,而是会尝试重启预案,如果恢复了做下复盘就好。
所以为了杀鸡不用牛刀,故障的排查和操作是循序渐进的从低成本到高成本的方向走的,期间最重要的是要提高每个操作的可预见性,并用最优雅、简洁、快速的方式恢复业务,怎么从根本上解决问题等到故障复盘时再定,总结一下常用的故障判断优先级,从低到高。
P0:是否大面积告警,排查基础资源比如网络、公有云是否有问题,决策是否要执行流量切换预案;
P1:如果是单服务、单实例,常规情况尝试重启预案;
P2:排查是否有时间吻合的变更,尝试回滚预案,常规情况下回滚会在重启预案无效后再执行;
P3:排查是否有流量突增,或服务器压力增大,启动扩容和限流预案;
P4:排查是否有功能无法恢复,并拖垮其他优质服务,启动降级预案;
P5:综合预案、临时预案,具体情况具体制定,但基本是6把刀的组合拳。
制定恢复方案通常要遵循白名单原则,即优先保证不伤害优质服务,比如说C3机房的服务正常,C4已经大面积不可用,考虑要将流量切到C3,一定要保证C3机房的服务不受影响的前提下,再用C3去救C4机房,别本来75%的可用性,切后雪崩变成了0%。
写到这,希望对你有所启发!!
标签:预案,SRE,处理,系统,突发,故障,告警,心法 From: https://www.cnblogs.com/netflix/p/17335980.html