更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
Notebook 是一种支持 REPL 模式的开发环境。所谓「REPL」,即「读取-求值-输出」循环:输入一段代码,立刻得到相应的结果,并继续等待下一次输入。Notebook 通常使得探索性的开发和调试更加便捷,在 Notebook 环境,用户可以交互式地在其中编写代码、运行代码、查看输出、可视化数据并查看结果,使用起来非常灵活。
在数据开发领域,Notebook 广泛应用于数据清理和转换、数值模拟、统计建模、数据可视化、构建和训练机器学习模型等方面。
但是显然,做数据开发,只有 Notebook 是不够的。目前火山引擎 DataLeap 数据研发平台提供了任务开发、发布调度、监控运维等一系列能力。研发团队将 Notebook 作为一种任务类型,加入了火山引擎 DataLeap 数据研发平台,使用户既能拥有 Notebook 交互式的开发体验,又能享受一站式大数据研发治理套件提供的便利。
如果还不够直观的话,试想以下场景:
在交互式运行和可视化图表的加持下,用户很快就调试完成了一份 Notebook。简单整理了下代码,根据使用到的数据配置了上游任务依赖,上线了周期调度,并顺手挂了报警。之后,基本上就不用管这个任务了:不需要每天手动检查上游数据是否就绪;不需要每天来点击运行,因为调度系统会自动帮用户执行这个 Notebook;执行失败了有报警,可以直接上平台来处理;上游数据出错了,可以请系统发起深度回溯,统一修数。
2019 年末,基于业务需求决定支持 Notebook 任务的时候,火山引擎 DataLeap 研发团队调研了许多 Notebook 的实现,包括 Jupyter、Polynote、Zeppelin、Deepnote 等。Jupyter Notebook 是 Notebook 的传统实现,它有着极其丰富的生态以及庞大的用户群体,相信许多人都用过这个软件。
事实上,在字节跳动数据平台发展早期,就有了在物理机集群上统一部署的 Jupyter(基于多用户方案 JupyterHub),供内部的用户使用。考虑到用户习惯和其强大的生态,Jupyter 最终成为了火山引擎 DataLeap 研发团队的选择。
(图:Jupyter Notebook 界面)
Jupyter Notebook 是一个 Web 应用。通常认为其有两个核心的概念:Notebook 和 Kernel。
-
Notebook 指的是代码文件,一般在文件系统中存储,后缀名为
ipynb。Jupyter Notebook 后端提供了管理这些文件的能力,用户可以通过 Jupyter Notebook 的页面创建、打开、编辑、保存 Notebook。在 Notebook 中,用户以一个一个 Cell 的形式编写代码,并按 Cell 运行代码。Notebook 文件的具体内容格式,可参考 The Notebook file format(https://nbformat.readthedocs.io/en/latest/format_description.html)。 -
Kernel 是 Notebook 中的代码实际的运行环境,它是一个独立的进程。每一次「运行」动作,产生的效果是单个 Cell 的代码被运行。具体来讲,「运行」就是把 Cell 内的代码片段,通过 Jupyter Notebook 后端以特定格式发送给 Kernel 进程,再从 Kernel 接受特定格式的返回,并反馈到页面上。这里所说的「特定格式」,可参考 Messaging in Jupyter(https://jupyter-client.readthedocs.io/en/stable/messaging.html)。
在火山引擎 DataLeap 数据研发平台,开发过程围绕的核心是任务。用户可以在项目下的任务开发目录创建子目录和任务,像 IDE 一样通过目录树管理其任务。Notebook 也是一种任务类型,用户可以启动一个独立的任务 Kernel 环境,像开发其他普通任务一样使用 Notebook。
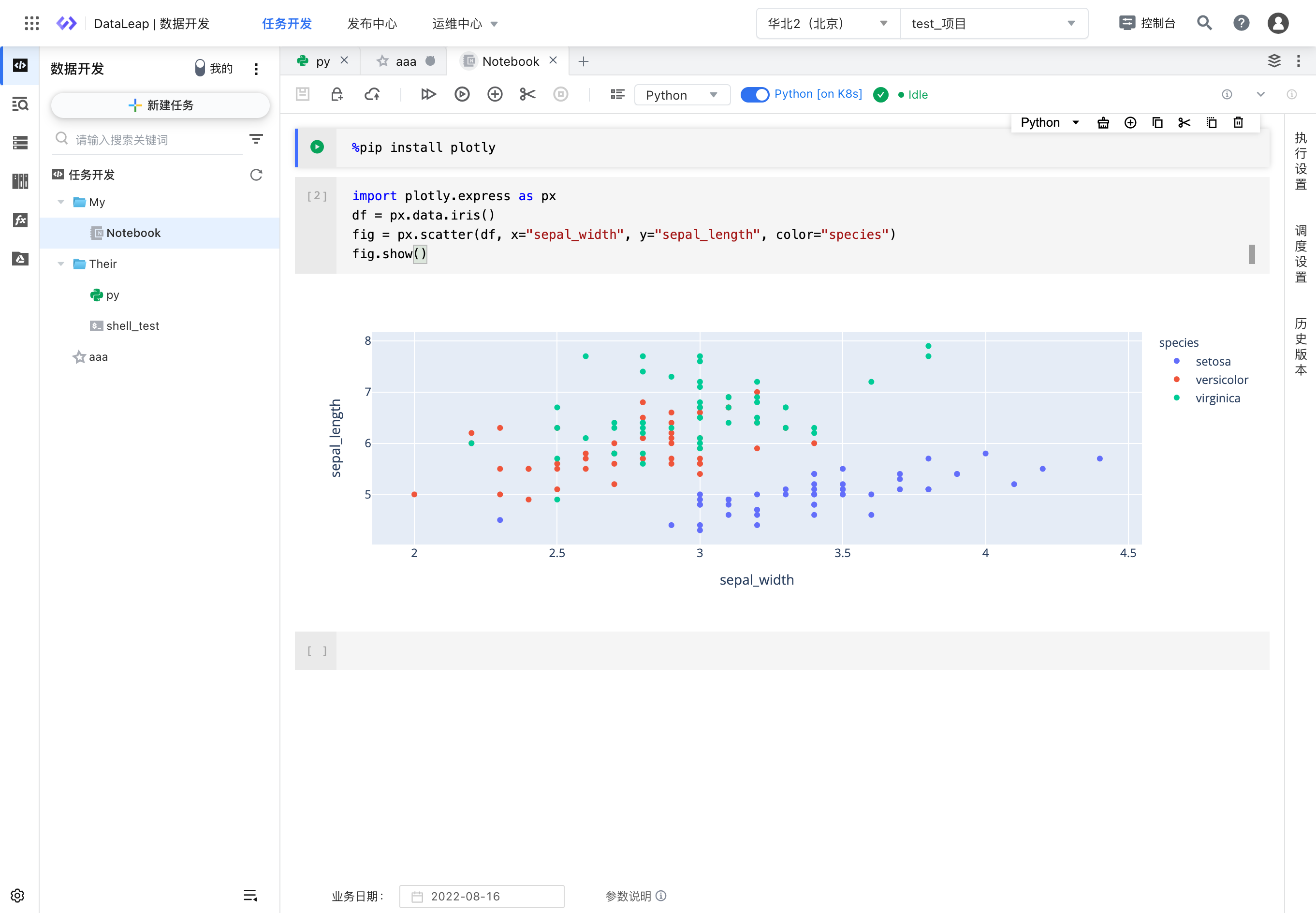
(图:火山引擎 DataLeap 数据开发 Notebook 任务界面)
目前 Notebook 任务已成为字节跳动内部使用较为高频的任务类型,用户可以在火山引擎 DataLeap 官网开通交互式分析的版本,使用到 DataLeap 的 Notebook 任务。
点击跳转 火山引擎大数据研发治理DataLeap 了解更多
标签:Jupyter,任务,用户,选型,引擎,DataLeap,Notebook From: https://www.cnblogs.com/bytedata/p/17329298.html