原文:Mastering Exploratory Analysis with Pandas
译者:飞龙
一、处理不同种类的数据集
在本章中,我们将学习如何在 Pandas 中使用不同种类的数据集格式。 我们将学习如何使用 Pandas 导入的 CSV 文件提供的高级选项。 我们还将研究如何在 Pandas 中使用 Excel 文件,以及如何使用read_excel方法的高级选项。 我们将探讨其他一些使用流行数据格式的 Pandas 方法,例如 HTML,JSON,PKL 文件,SQL 等。
从 CSV 文件读取数据时使用高级选项
在本部分中,我们将 CSV 和 Pandas 结合使用,并学习如何使用read_csv方法读取 CSV 数据集以及高级选项。
导入模块
首先,我们将使用以下命令导入pandas模块:
import pandas as pd
要读取 CSV 文件,我们使用read_csv方法,如下所示:
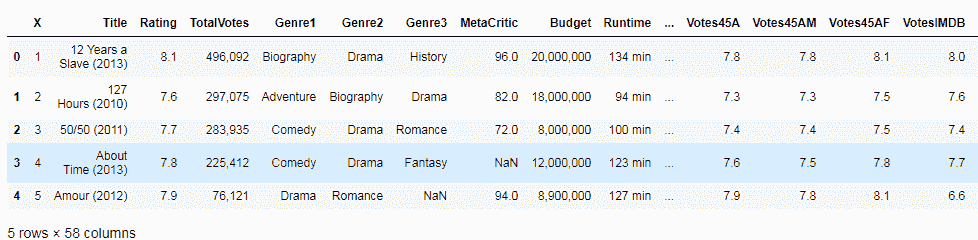
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1")
df.head()
为了执行基本导入,请将数据集的文件名传递给read_csv,并将结果数据帧分配给变量。 在以下屏幕截图中,我们可以看到 Pandas 已将数据集转换为表格格式:
高级读取选项
在 Python 中,pandas 具有read_csv方法的许多高级选项,您可以在其中控制如何从 CSV 文件读取数据。
处理列,索引位置和名称
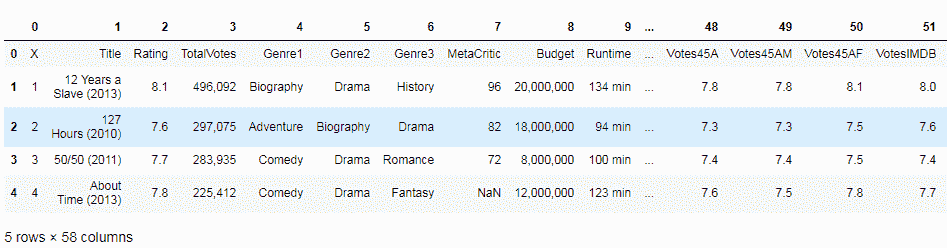
默认情况下,read_csv将 CSV 文件第一行中的条目视为列名。 我们可以通过将header设置为None来关闭此功能,如以下代码块所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", header=None)
df.head()
输出如下:
指定另一行作为标题
您还可以通过将行号传递给header选项,从而从其他行(而不是默认的第一行)设置列名,如下所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", header=2)
df.head()
输出如下:

将列指定为索引
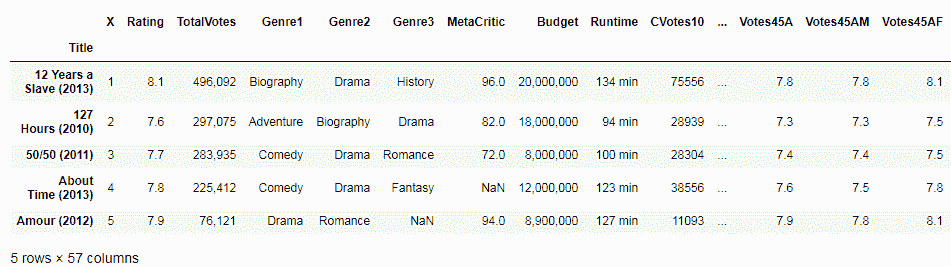
默认情况下,read_csv在读取数据时分配一个默认的数字索引,该索引从零开始。 但是,您可以通过将列名传递给索引列选项来更改此行为。 然后,Pandas 会将索引设置为此列,如以下代码所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", index_col='Title')
df.head()
在这里,我们传递了电影标题作为索引名称。 现在,索引名称为Title,而不是默认的数字索引,如以下屏幕截图所示:
选择要读取的列的子集
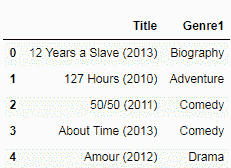
我们还可以选择读取 CSV 文件中特定列的子集。 为此,我们将列名作为列表传递,以使用columns选项,如下所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", usecols=['Title', 'Genre1'])
df.head()
前面的代码段的输出如下:
处理缺失和不适用的数据
接下来,我们将看到如何通过读取 CSV 文件来处理丢失的数据。 默认情况下,read_csv认为缺少以下值并将其标记为NaN:

但是,您可以添加到此列表。 为此,只需将要视为NaN的值列表传递给,如以下代码所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", na_values=[''])
选择是否跳过空白行
有时整行没有值; 因此,我们可以在读取数据时选择处理这些行。 默认情况下,read_csv会忽略空白行,但是我们可以通过将skip_blank_lines设置为False来关闭此行,如下所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", skip_blank_lines=False)
数据解析选项
我们可以通过读取 CSV 文件来选择跳过哪些行。 我们可以将行号作为列表传递给skiprows选项。 第一行的索引为零,如下所示:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", skiprows = [1,3,7])
df.head()
输出如下:

从文件的页脚或结尾跳过行
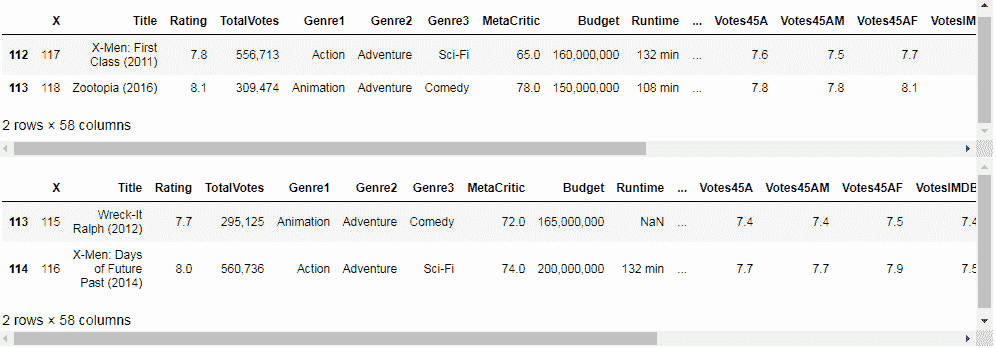
要从页脚或文件末尾跳过行,请使用skipfooter选项并传递一个数字,该数字指定要跳过的行数。 在以下代码中,我们通过了2。 如我们所见,在跳过最后两行之后,我们创建的上一个数据帧与我们创建的数据帧之间存在差异:
df.tail(2)
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", skipfooter=2, engine='python')
df.tail(2)
以下屏幕截图显示了输出:
读取文件的子集或一定数量的行
有时数据文件太大,我们只想看一下前几行。 我们可以通过将要导入的行数传递到nrows选项来做到这一点,如以下代码所示。 在这里,我们将100传递给nrows,然后nrows仅读取数据集中的前一百行:
df = pd.read_csv('IMDB.csv', encoding = "ISO-8859-1", nrows=100)
df.shape
从 Excel 文件读取数据
在本节中,我们将学习如何使用 Pandas 使用 Excel 数据来处理表格,以及如何使用 Pandas 的read_excel方法从 Excel 文件中读取数据。 我们将阅读并探索一个真实的 Excel 数据集,并使用 xplore 解析一些可用于解析 Excel 数据的高级选项。
熊猫内部使用 Python Excel 库rd从 Excel 文件中提取数据。 我们可以通过执行conda install xlrd来安装它。
首先,请确保命令行程序在安装前以管理员模式运行,如以下屏幕截图所示:

以下屏幕截图显示了我们将使用 Pandas 阅读和探索的 Excel 数据集:
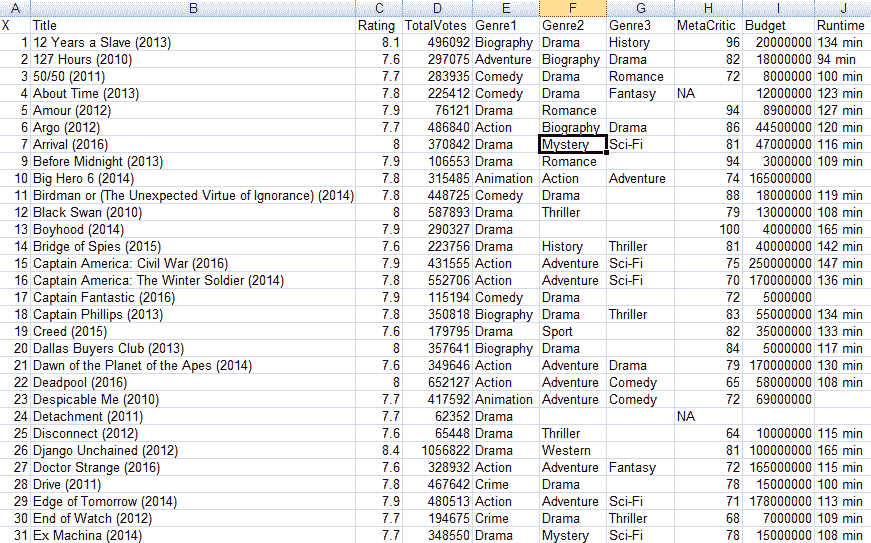
上一个屏幕截图是电影分级的集合,可以在这里找到它。
基本的 Excel 读取
我们正在使用 Pandas 的read_excel方法读取此数据。 以最简单的格式,我们只是将想要的 Excel 数据集的文件名传递给read_excel方法。 pandas 将 Excel 文件中的数据转换为 Pandas 数据帧。 Pandas 内部为此使用 Excel rd库。 在这里,Pandas 已读取数据并在内存中创建了表格数据对象,我们可以在我们的代码中访问,浏览和操作,如以下代码所示:
df = pd.read_excel('IMDB.xlsx')
df.head()
前一个代码块的输出如下:

pandas 有很多高级选项,我们可以使用它们来控制应如何读取数据。如以下屏幕截图所示:

指定应读取的工作表
要指定应读取的纸张,请将值传递给sheetname选项。 如下面的屏幕快照所示,我们只是传递0,它是 Excel 工作表中第一张工作表的索引值。 这非常方便,尤其是当我们不知道确切的工作表名称时:
df = pd.read_excel('IMDB.xlsx', sheetname=0)
df.head()
输出如下:

从多张表读取数据
Excel 数据集文件附带数据和多个工作表。 实际上,这是许多用户更喜欢 Excel 而不是 CSV 的主要原因之一。 幸运的是,Pandas 支持从多张纸中读取数据。
查找工作表名称
要找出工作表的名称,请将 Excel 文件传递到ExcelFile类,然后在结果对象上调用sheet_names属性。 该类将 Excel 文件中的图纸名称打印为列表。 如果我们想从名为data-movies的工作表中读取数据,它将类似于以下代码片段:
xls_file = pd.ExcelFile('IMDB.xlsx')
xls_file.sheet_names
接下来,我们在之前创建的 Excel 文件对象上调用parse方法,并传入我们想要读取的工作表名称。 然后我们将结果分配给两个单独的数据帧对象,如下所示:
df1 = xls_file.parse('movies')
df2 = xls_file.parse('by genre')
df1.head()
现在,我们从两个单独的数据帧,中的两个工作表中获取数据,如以下屏幕截图所示:

选择标题或列标签
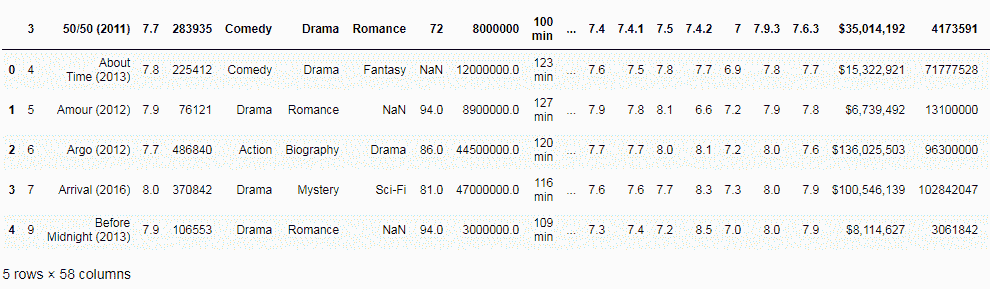
默认情况下,pandas 会将列名称或标题设置为 Excel 文件中第一个非空白行的值。 但是,我们可以更改此行为。 在以下屏幕截图中,我们将值3传递给header选项,该选项告诉read_excel方法设置索引行3中的标题名称:
df = pd.read_excel('IMDB.xlsx', sheetname=1, header=3)
df.head()
前面代码的输出如下:
没有标题
我们还可以告诉read_excel忽略标题并将所有行都视为记录。 只要 Excel 没有标题行,就很方便。 为此,我们将header设置为None和,如以下代码所示:
df = pd.read_excel('IMDB.xlsx', sheetname=1, header=None)
df.head()
输出如下:

在开头跳过行
要跳过文件开头的行,只需将skiprows设置为要跳过的行数,如以下代码所示:
df = pd.read_excel('IMDB.xlsx', sheetname=1, skiprows=7)
在末尾跳过行
为此,我们使用skip_footer选项,如下所示:
df = pd.read_excel('IMDB.xlsx', sheetname=1, ski_footer=10)
选择列
我们还可以选择只读取列的子集。 这是通过将parse_cols选项设置为数值来完成的,这将导致将列从0读取到我们设置解析列值的任何索引。 我们在这种情况下设置了parse_cols=2,它将读取 Excel 文件中的前三列,如以下代码片段所示:
df = pd.read_excel('IMDB.xlsx', sheetname= 0, parse_cols=2)
df.head()
以下是输出:
列名
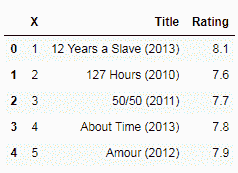
我们可以选择给列使用不同的名称,而不是标题行中提供的默认名称。 为此,我们将列名列表传递给names参数,如下所示:
df = pd.read_excel('IMDB.xlsx', sheetname=0, parse_cols = 2, names=['X','Title',
'Rating'], )
df.head()
在下面的屏幕截图中,我们将列名设置为读取时传递的名称:
读取数据时设置索引
默认情况下,read_excel用数字索引标记零,从0开始。 我们可以将索引或行标签设置为更高的值或我们的选择。 为此,我们将数据集的列名传递给index_col选项。 在以下代码中,我们将索引设置为Title列:
df = pd.read_excel('IMDB.xlsx', sheetname=0, index_col='Title')
df.head()
输出如下:

读取时处理丢失的数据
read_excel方法有一个值列表,它将被视为丢失,然后将其设置为NaN。 我们可以在使用na_values参数传递值列表时添加此代码,如以下代码所示:
df = pd.read_excel('IMDB.xlsx', sheetname= 0, na_values=[' '])
读取其他流行格式的数据
在本节中,我们将探索 Pandas 的功能,以读取和使用各种流行的数据格式。 我们还将学习如何从 JSON 格式,HTML 文件和 PICKLE 数据集中读取数据,并且可以从基于 SQL 的数据库中读取数据。
读取 JSON 文件
JSON 是用于结构化数据的最小可读格式。 它主要用于在服务器和 Web 应用之间传输数据,以替代 XML,如以下屏幕快照所示:

将 JSON 数据读入 Pandas
为了读取 JSON 数据,pandas 提供了一种名为read_json的方法,其中我们传递了要读取的 JSON 数据文件的文件名和位置。 文件位置可以是本地文件,甚至可以是具有有效 URL 方案的互联网。 我们将结果数据帧分配给变量DF。
read_json方法读取 JSON 数据并将其转换为 Pandas 数据帧对象,即表格数据格式,如以下代码所示。 JSON 数据现在可以以数据帧格式轻松访问,可以更轻松地进行操作和浏览:
movies_json = pd.read_json('IMDB.json')
movies_json.head()
上一个代码块将产生以下输出:

读取 HTML 数据
pandas 内部使用lxml Python 模块读取 HTML 数据。 您可以通过执行conda install lxml,从命令行程序安装它,如以下屏幕截图所示:

我们还可以从本地文件甚至直接从互联网导入 HTML 数据:

在这里,我们将 HTML 文件或 URL 的位置传递给read_html方法。read_html从 HTML 提取表格数据,然后将其转换为 Pandas 数据帧。 在以下代码中,我们以表格格式获取了从 HTML 文件提取的数据:
pd.read_html('IMDB.html')
输出如下:

读取 PICKLE 文件
酸洗是将任何类型的 Python 对象(包括列表,字典等)转换为字符串的一种方式。 这个想法是,该字符串包含在另一个 Python 脚本中重构对象所需的所有信息。
我们使用read_pickle方法读取我们的 PICKLE 文件,如以下代码所示。 与其他数据格式一样,Pandas 根据读取的数据创建数据帧:
df = pd.read_pickle('IMDB.p')
df.head()
输出如下:

读取 SQL 数据
在这里,我们将从流行的数据库浏览器 SQLite 中读取 SQL 数据,可以通过执行以下命令进行安装:
conda install sqlite
然后,我们将导入 SQLite Python 模块,如下所示:
import sqlite3
然后,创建与您要从中读取数据的 SQLite DB 的连接,如下所示:
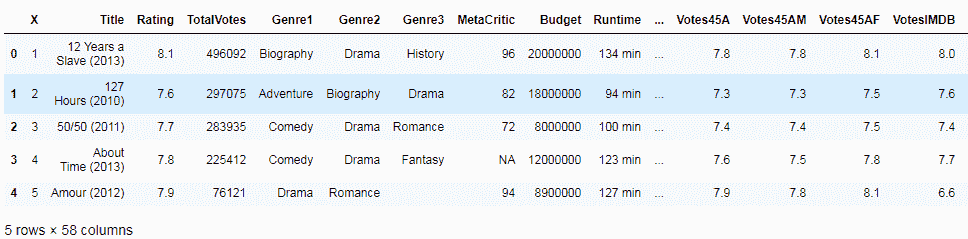
conn = sqlite3.connect("IMDB.sqlite")
df = pd.read_sql_query("SELECT * FROM IMDB;", conn)
df.head()
接下来,使用read_sql_query方法将您想要数据来自的 SQL 查询传递给 Pandas。 该方法读取数据并创建一个数据帧对象,如以下屏幕快照所示:
此演示使用了 SQLite 数据库,但您也可以从其他数据库读取数据。 为此,只需调用适当的 DB Python 模块即可。
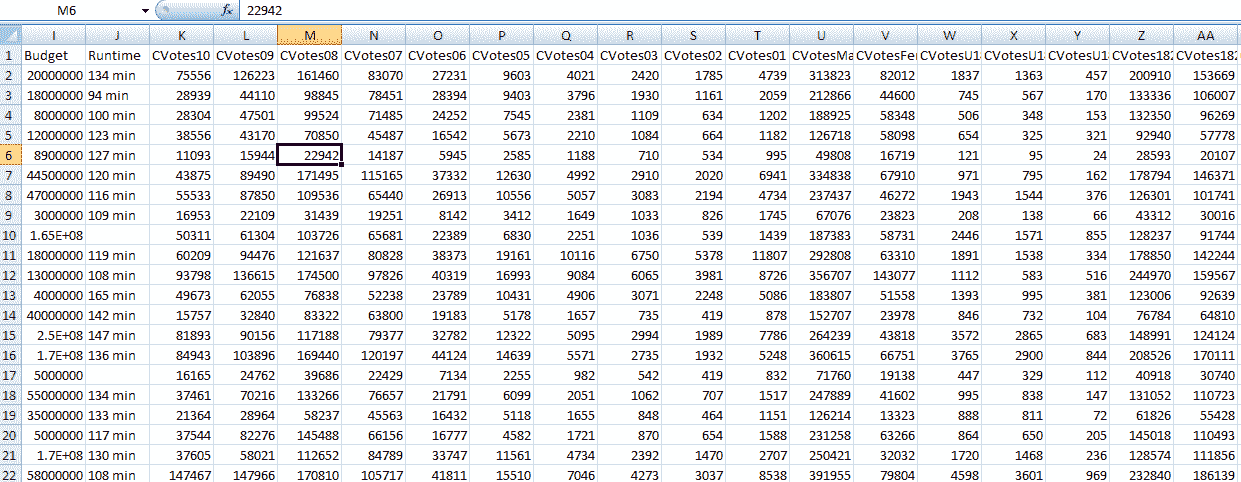
从剪贴板读取数据
要从剪贴板读取数据,请先复制一些数据。 在以下示例中,我们从电影数据集中复制了一个表:
接下来,使用 pandas 的read_clipboard方法读取数据并创建一个数据帧,如下所示:
df = pd.read_clipboard()
df.head()
从网页复制的数据现在作为数据帧存储在内存中,如以下屏幕截图所示。 在将数据快速导入 Pandas 时,此方法非常方便:

总结
在本章中,我们学习了如何在 Pandas 中使用不同种类的数据集格式。 我们学习了在导入 CSV 文件时如何使用 Pandas 提供的高级选项。 我们还看到了如何使用 Excel 数据集,并且探讨了可用于处理各种数据格式(例如 HTML,JSON,PICKLE 文件,SQL 等)的方法。
在下一章中,我们将学习如何在高级数据选择中使用 Pandas 技术。
二、数据选择
在本章中,我们将学习使用 Pandas 进行数据选择的高级技术,如何选择数据子集,如何从数据集中选择多个行和列,如何对 Pandas 数据帧或一序列数据进行排序,如何过滤 Pandas 数据帧的角色,还学习如何将多个过滤器应用于 Pandas 数据帧。 我们还将研究如何在 Pandas 中使用axis参数以及在 Pandas 中使用字符串方法。 最后,我们将学习如何更改 Pandas 序列的数据类型。
首先,我们将学习如何从 Pandas 数据帧中选择数据子集并创建序列对象。 我们将从导入真实数据集开始。 我们将介绍一些 Pandas 数据选择方法,并将这些方法应用于实际数据集,以演示数据子集的选择。
在本章中,我们将讨论以下主题:
- 从数据集中选择数据
- 排序数据集
- 使用 Pandas 数据帧过滤行
- 使用多个条件(例如 AND,OR 和 ISIN)过滤数据
- 在 Pandas 中使用
axis参数 - 更改 Pandas 序列的数据类型
数据集简介
我们将使用 zillow.com 的真实数据集,这是一个在线房地产市场,其发布房价数据集是他们研究工作的一部分。 这些数据集可在公共领域获得,并在归属于 zillow.com 后可免费使用。 我们将使用有关美国地区平均房价的最新数据。 它是 CSV 数据集,或带有 CSV 的文本文件。 让我们首先将 pandas 模块导入到 Jupyter 笔记本中,如下所示:
import pandas as pd
然后,我们将读取数据集。 由于它是 CSV 文件,因此我们正在使用 Pandas 的read_csv方法。 我们将文件名(以逗号作为分隔符)传递给read_csv方法,并从此数据中创建一个数据帧,我们将其命名为data。
我们收到的数据集是 CSV 文件的形式; 因此,我们将使用普通 Pandasread_csv方法。 我们需要传递文件名和逗号作为分隔符。 以下代码块将创建一个名称为data的数据帧:
data = pd.read_csv('data-zillow.csv', sep=',')
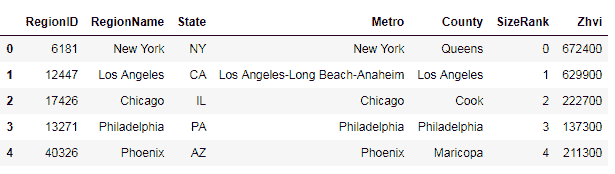
创建了数据帧之后,现在我们将从数据集中读取一些记录。 这可以通过在数据帧上调用head方法(data.head())来完成。 这将为输出提供列,例如Date和一些位置字段,例如RegionName,State,Metro和County。 最后一列标题Zhvi是 Zillow 术语,是该特定区域的平均房价,如以下屏幕截图所示:

从数据集中选择数据
我们将从数据帧中选择作为 Pandas 序列的列,这可以通过两种方式完成。 第一种方法是对此选择使用方括号表示法,如以下代码块所示:
regions = data['RegionName']
通过传递RegionName列,我们将获得一个series对象。 此series对象将仅包含来自此特定列的值。 我们如何确定这是series对象? 我们可以通过传递为type函数创建的series对象进行检查,如下所示:
type(regions)
现在,让我们看一下刚刚创建的series对象中的数据:

让我们找出 Pandas 数据帧和 Pandas 序列之间的区别。 Pandas 数据帧是带有标签行和列的多维表格数据结构。 序列是包含单列值的数据结构。 Pandas 的数据帧可以视为一个或多个序列对象的容器。
多列选择
要从一个数据帧中选择多个列,我们需要将这些列作为列表传递给数据帧,如下所示:
region_n_state = data[['RegionName', 'State']]
region_n_state.head()
现在,让我们使用type函数确认生成的对象是序列对象还是数据帧,如下所示:
type(region_n_state)
以下是输出:

从前面的屏幕快照中可以看出,选择多个列将创建另一个数据帧,而仅选择一个列将创建series对象。
点表示法
还有另一种方法可以根据从数据帧中选择的数据子集来创建新序列。 此方法称为点表示法。 在此方法中,列名将像传递属性时一样传递给数据帧,而不是作为参数传递:
data.State
以下是输出:

我们可以选择多个序列,然后从中创建新序列。 我们将使用三列County,Metro和State创建一个新序列。 然后我们将这些序列连接起来,并在数据帧中创建一列称为Address。 让我们看一下刚刚创建的新创建的列或序列:
data['Address'] = data.County + ', ' + data.Metro + ', ' + data.State
输出如下:

从 Pandas 数据帧中选择多个行和列
在本节中,我们将学习更多有关从读取到 Pandas 的数据集中选择多个行和列的方法的信息。 我们还将介绍一些 Pandas 数据选择方法,并将这些方法应用于实际数据集,以演示数据子集的选择。
首先,我们导入 Pandas 并以与上一节相同的方式从 zillow.com 读取数据。 这样做如下:
import pandas as pd
zillow = pd.read_table('data-zillow.csv', sep=',')
zillow.head()
输出如下:

接下来,让我们看一些使用此数据集选择行和列的技术。 Pandas 有一种选择行和列的方法,称为loc。 我们将使用loc方法从之前创建的数据集中调用数据帧。loc要求两个参数之间用逗号分隔,其中第一个参数是要选择的行,第二个参数是要选择的列,如以下代码块所示:
zillow.loc[7, 'Metro']
如前面的命令所示,我们将7作为要选择的行的索引,并且将名称为Metro的列作为要选择的列。 这为我们提供了索引为7的行和列为Metro的值。
我们还可以通过按索引而不是列名来引用列来实现此选择。 为此,我们将使用iloc方法。 在iloc方法中,我们需要将行和列都作为索引号传递。 如以下屏幕截图所示,两种方法的结果相同:
zillow.iloc[7,4]
以下是前一个代码块的输出:

选择单行和多列
在本节中,我们将查看单行和多列的记录,其中我们将多列作为列表传递:
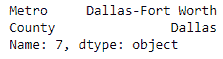
zillow.loc[7, ['Metro', 'County']]
我们从具有索引7以及Metro和County列的行中获取值。 如果我们选择一行,则这些值将垂直显示,而不是水平显示。 我们可以使用iloc方法而不是loc将此调用转换为使用列索引而不是列名,如下所示:
zillow.iloc[7, [4,5]]
输出如下:
现在,我们将学习如何选择一个单行,但要选择所有列中的值。 对于参数的列部分,我们使用冒号(:)。 这告诉loc方法选择所有列:
zillow.loc[11, :]
输出如下:

接下来,我们将学习如何从多行和单列中选择值。 在这里,我们需要将行作为行的序列来传递。 我们将索引号从101到105(包括两端)的行传递。 我们将列名作为参数列表的第二部分传递,如下所示:
zillow.loc[101:105, 'Metro']
在这里,我们具有来自多行和一列的值。 接下来,我们从多个行和多个连续的列中选择数据; 就像行索引范围一样,我们将列名作为范围传递,如下所示:
zillow.loc[201:204, "State":"County"]
如果要传递列索引而不是列名,我们还可以使用iloc方法来实现此目的,如下所示:
zillow.iloc[201:205, 3:6]
我们得到的结果与以前相同。 现在,我们将研究选择多个不连续的值,我们只需要将列名作为列表传递,如下面的代码所示:
zillow.loc[201:205, ['RegionName', 'State']]
输出如下:
从行和所有列的范围中选择值
在这里,我们将使用loc方法查看行和列序列中的值。 为此,loc方法的第一个参数是要选择的行的范围索引。 由于我们需要所有列中的值,因此我们将冒号(:)作为第二个参数,如下所示:
zillow.loc[201:205, :]
在以下屏幕截图中可以看到输出:

选择不连续的行也可以类似的方式工作。 在非连续行方法中,我们将行索引作为列表传递给loc方法,如以下代码所示:
zillow.loc[[0,5,10], :]
输出结果如下:

假设我们要基于某个列的值选择行和列。 以下代码行显示我们正在选择County列的值为Queens的行:
zillow.loc[zillow.County=="Queens"]
现在,让我们根据不同列的值选择特定列的所有行。 在以下代码块中,我们从County列中为Metro为New York的行选择值:
zillow.loc[zillow.Metro=="New York", "County"]
在以下屏幕截图中,我们可以从数据集中查看New York的所有县:
对 Pandas 数据帧排序
在本节中,我们将学习 Pandas sort_values方法。 我们还将使用各种方法对 Pandas 数据帧进行排序,并学习如何对 Pandas series对象进行排序。
我们将首先导入 pandas 模块,然后从 zillow.com 将房价数据集读取到 Jupyter 笔记本中。 首先,让我们从简单的排序类型开始。 我们将使用 Pandas 的sort_values方法。 例如,假设我们要按Metro列对数据进行排序。 我们需要将Metro作为参数传递给sort_values方法,并在数据帧上调用该方法,如下所示:
zillow.sort_values('Metro')
这表明数据已按Metro列排序,如以下屏幕截图所示:
如果您发现默认情况下,Date列按升序排序。 我们可以更改排序顺序,为ascending参数赋予False的值,如以下代码块所示:
sorted = zillow.sort_values('Metro', ascending=False)
ascending参数是可选的,当不传递时,默认情况下将其设置为True。 现在,我们将研究如何按不止一列对数据进行排序。 为此,我们需要将要对数据进行排序的列列表传递给sort_values方法的参数列,如下所示:
sorted = zillow.sort_values(by=['Metro','County'])
现在已按Metro首先对数据进行排序,然后按County列进行排序; 也就是说,按照我们将它们传递给sort_values方法的顺序。 我们可以进一步对多列进行排序,并引入混合的升序。 例如,我们可以按三列排序:Metro,County和Price列,如下所示:
sorted = zillow.sort_values(by=['Metro','County', 'Zhvi'], ascending=[True, True, False])
sorted.head()
您必须已经注意到,我们在递增参数中传递了三个布尔值的列表。 这将对Metro和County的排序顺序设置为升序,对于最后一列Zhvi的降序设置为:
接下来,我们了解如何对series对象进行排序。 首先,让我们创建一个序列。 让我们从数据集中选择RegionID列,然后创建一个序列,如下所示:
regions = zillow.RegionID
type(regions)
在对它进行排序之前,让我们使用regions.head()查看原始序列。 输出如下:
现在,让我们通过调用sort_values方法对其进行排序。 由于数据集仅包含一列,因此我们无需传递任何列名。 因此,用于对数据进行排序的代码将为regions.sort_values().head(),并且输出将如下所示:
过滤 Pandas 数据帧的行
在本节中,我们将学习从 Pandas 数据帧过滤行和列的方法,并将介绍几种方法来实现此目的。 我们还将学习 Pandas 的filter方法以及如何在实际数据集中使用它,以及基于将根据数据创建的布尔序列保护数据的方法。 我们还将学习如何将条件直接传递给数据帧进行数据过滤。
我们将首先导入 pandas 模块,然后从 zillow.com 中将房价数据集读取到 Jupyter 笔记本中。 首先,我们探索 Pandas 的filter方法来过滤数据。 我们可以使用filter方法过滤列。 为此,我们需要将列作为列表传递给filter方法的items参数,如下所示:
filtered_data = data.filter(items=['State', 'Metro'])
filtered_data.head()
输出如下:

如您在前面的屏幕快照中所见,我们按State和Metro过滤了列,并使用过滤器列中的值创建了一个新的数据帧。 然后我们使用head方法显示过滤器数据。 接下来,我们使用filter方法使用正则表达式过滤列名称。 通过将正则表达式传递给regex参数来完成此操作,如下所示:
filtered_data = data.filter(regex='Region', axis=1)
filtered_data.head()
当我们打印出过滤数据时,我们可以看到它选择了名称为Region的两列,如以下屏幕截图所示:
filter方法不是过滤数据的唯一方法。 为了过滤行,我们可以使用一些有趣的技术-首先,我们创建布尔值序列。 布尔值序列基于我们数据集中的价格值列。 我们选择选择值大于500000的行,如下所示:
price_filter_series = data['Zhvi'] > 500000
price_filter_series.head()
我们通过从顶部打印一些值来确认创建了序列,如以下屏幕截图所示:

如前面的屏幕快照所示,True值是与我们的条件匹配的值,即,它们表示价格高于500000的行。 接下来,我们使用该布尔序列来过滤完整数据集中的行,并仅获取价格高于500000的值。 为此,我们将方括号将布尔序列传递给数据集数据帧,如下所示:
data[price_filter_series].head()
在不显式创建布尔序列的情况下筛选数据集的另一种方法是将所需值的条件直接传递给数据帧。 例如,假设我们只想过滤并选择房价高于或等于1000000的行。 我们将条件传递给数据帧如下:
data[data.Zhvi >= 1000000].head()
以下屏幕快照显示了值大于1000000的记录:
将多个过滤条件应用于 Pandas 数据帧
在本节中,我们将学习将多个过滤条件应用于 Pandas 数据帧的方法。 我们将使用逻辑 AND/OR 条件运算符从真实数据集中选择记录。 我们还将看到如何使用isin()方法来过滤记录。 我们将在真实数据集上演示isin方法用于单列和多列过滤。
我们将首先导入 pandas 模块并从 zillow.com 中将房价数据集读取到 Jupyter 笔记本中,如下所示:
data = pd.read_table('data-zillow.csv', sep=',')
data.head()
输出如下:

根据多种条件进行过滤 – AND
现在,让我们看一些使用多个条件或条件过滤数据的技术。 首先,我们选择价格高于 1,000,000 且State参数为纽约(NY)的行,如下所示:
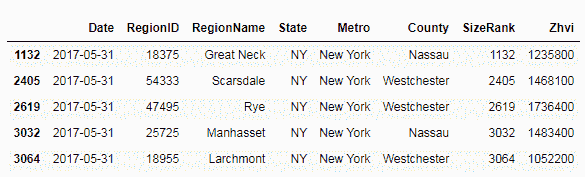
data[(data['Zhvi'] > 1000000) & (data['State'] == 'NY')].head()
将前面的多条件传递给数据库的数据帧。 在下面的屏幕快照中,此技术仅选择价格值大于 1,000,000 且State为New York的行,并过滤掉了所有其他记录:
根据多种条件进行过滤 – OR
当我们使用逻辑运算符 OR 传递这些条件时,我们使用相同的技术来过滤数据。 在这里,我们从New York或California中选择那些记录。 为此,我们使用逻辑运算符 OR 合并条件,并将此组合条件传递给数据集。 结果子数据集仅来自这两个状态,如下所示:
data[((data['State'] == 'CA') | (data['State'] == 'NY'))].head()
输出如下:

使用isin方法进行过滤
筛选数据的另一种方法是使用isin方法。 我们可以使用isin方法通过一个或多个特定列的值列表来过滤数据集。 在这里,我们仅从Metro列中选择值New York或San Francisco的那些记录。
我们在Metro列上调用isin方法,并将其传递给包含我们要选择的城市的列表。 这将创建一个布尔序列。 然后,我们将布尔序列传递给数据集数据帧进行必要的过滤和选择,如下所示:
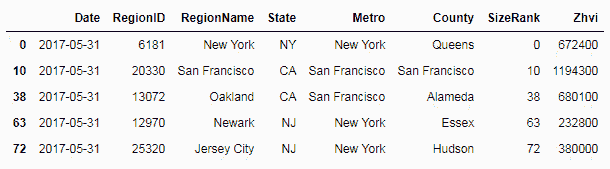
filter = data['Metro'].isin(['New York', 'San Francisco'])
data[filter].head()
以下屏幕截图显示了仅来自New York和San Francisco这两个城市的记录的过滤数据:
在多个条件下使用isin方法
我们还可以使用isin方法根据来自多列的值过滤行。 为了执行此操作,我们传递了一个字典对象,其中的键是列名,而值是我们要从中选择记录的那些列的值的列表。
举个例子,让我们选择State参数为California和Metro参数为San Francisco的值。 我们使用包含要选择的值的这两列创建一个字典对象,然后将该字典项传递给isin方法,并在数据集上调用isin方法。 然后,将过滤器传递给数据帧并选择我们的记录,如下所示:
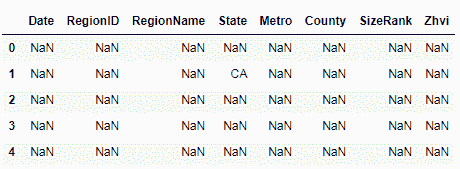
filter = data.isin({'State': ['CA'], 'Metro': ['San Francisco']})
data[filter].head()
这将显示NaN,或者对于那些不符合我们先前指定的多个条件的记录不可用:
在 Pandas 中使用axis参数
在本节中,我们将学习在 Pandas 中进行数据分析时何时何地使用axis参数或关键字。 我们将介绍axis参数,并逐步介绍可以将axis关键字设置为的各种值。 我们将演示如何将axis设置为行或列来改变方法的行为。 我们还将展示一些使用axis关键字的代码示例。
我们将首先导入 pandas 模块,然后从 zillow.com 中将房价数据集读取到 Jupyter 笔记本中:
data = pd.read_table('data-zillow.csv', sep=',')
data.head()
输出如下:

axis参数的用法
axis参数告诉您一个特定的方法,以及应该执行该方法的数据帧的哪个轴。 以下代码描述了axis参数的输入数据类型:
data.head()
可以沿行或列垂直或水平指定轴,换句话说,沿行或列指定轴:对行使用axis0,对列使用axis1,如以下屏幕截图所示:

以下是命令:
data.axes
以下是上述命令的输出:

axis用法示例
在axis用法示例中,我们计算数据集中值的平均值。 我们已将axis传递为0。 这意味着将沿着行axis计算平均值,如下所示:
data.mean(axis=0)
输出如下:

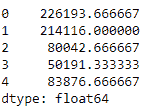
接下来,我们将axis设置为1。 我们在同一数据集上使用完全相同的方法; 但是,我们正在将axis从0更改为1。 由于我们将axis设置为1,因此mean的计算如下:
data.mean(axis=1).head()
输出如下:
有时很难记住0或1是用于行还是用于列。 因此,您可以将axis设置为rows而不是使用axis0:
data.mean(axis='rows')
输出为以下内容:

对于列,您可以将axis设置为columns。 与使用0或1具有相同的效果:
data.mean(axis='columns').head()
输出如下:

axis关键字的更多示例
在这里,我们使用drop方法删除行或记录。 我们通过将关键字axis传递为0来告诉drop方法将记录删除到0的索引处:
data.drop(0, axis=0).head()
输出如下:

在以下示例中,我们将axis设置为1,这告诉drop方法删除带有Date标签的列:
data.drop('Date', axis=1).head
输出如下:
axis关键字
我们也可以在过滤方法中使用axis关键字。 在这里,我们通过regex Region进行过滤,并将axis设置为列:
data.filter(regex='Region', axis=1).head()
输出如下:
在 Pandas 中使用字符串方法
在本节中,我们将学习在 Pandas 序列中使用各种字符串方法。 我们将把真实的数据集读入 Pandas。 我们将探索一些字符串方法,并将使用这些字符串方法从数据集中选择和更改值。
我们将首先导入 pandas 模块并从 zillow.com 中读取房价数据集到 Jupyter 笔记本中:
data = pd.read_table('data-zillow.csv', sep=',')
data.head()
输出如下:

检查子串
为了学习如何使用字符串方法检查 Pandas 序列的子字符串,我们使用str包中的contains方法。
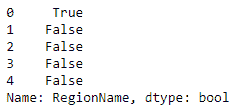
在这里,我们从数据集中调用RegionName序列上的str.contains方法。 我们正在寻找包含New子字符串的记录。 它打印出一个布尔序列,打印True找到一个子字符串,而False找到一个子字符串:
data.RegionName.str.contains('New').head()
输出如下:
将序列或列值更改为大写
有一种非常常见的字符串方法可以将 Python 字符串转换为大写。 我们可以使用它来将列中的所有值转换为大写。 我们通过在序列中调用str.upper来实现。 在这里,我们将其称为RegionName列:
data.RegionName.str.upper().head()
输出如下:

将值更改为小写
为此,我们使用lower字符串方法:
data.County.str.lower().head()
输出如下:

查找列中每个值的长度
为此,我们在其中一列上调用str.len方法:
data.County.str.len().head()
输出如下:
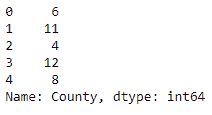
删除空格
我们还可以使用字符串方法进行一些数据清理。 例如,在这里,我们使用lstrip方法从列的值中删除所有前导空格:
data.RegionName.str.lstrip().head()
输出如下:

替换列值的一部分
我们还可以使用字符串方法更改数据。 在这里,我们使用replace方法将数据集中RegionName列中的空格替换为无空格:
data.RegionName.str.replace(' ', '').head()
输出如下:

更改 Pandas 序列的数据类型
在本节中,我们将学习如何更改 Pandas 序列的数据类型。 我们将看到读取其中的数据后如何更改数据类型。 我们还将学习在读取 Pandas 数据时如何更改数据类型。 我们将通过一个示例将int列更改为float。 我们还将看到如何将字符串值列转换为datetime数据类型。
我们将首先导入 pandas 模块,然后从 zillow.com 中读取房价数据集到 Jupyter 笔记本中:
data = pd.read_table('data-zillow.csv', sep=',')
data.head()
输出如下:

将int数据类型列更改为float
为此,我们首先检查真实数据集中的列的数据类型:
data.dtypes
输出如下:
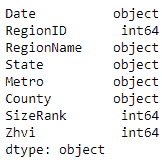
然后我们使用astype方法更改数据类型。 我们将float传递给astype方法,并在要更改其数据类型的列上调用此方法。
我们将更改分配回原始列,如下所示:
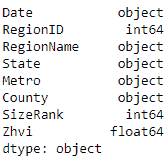
data['Zhvi'] = data.Zhvi.astype(float)
data.dtypes
在下面的屏幕截图中,我们可以看到已经进行了更改-我们列的数据类型已从int64更改为float64:
读取数据时更改数据类型
在将数据读入 pandas 之后,我们只是更改了列的数据类型。 另外,我们可以在读取数据时更改数据类型。 为此,我们将列名和数据类型传递到要更改为read数据方法的列中。 我们想要的float列已导入为float64:
data2 = pd.read_csv('data-zillow.csv', sep=',', dtype={'Zhvi':float})
data2.dtypes
输出如下:

将字符串转换为日期时间
这里最主要的是我们的数据集有一个日期列,但它显示为对象或字符串数据类型。 我们将其转换为适当的datetime列。
我们将为此使用 pandas 的to_datetime方法,该方法可以解析几种不同的datetime格式:
pd.to_datetime(data2.Date,infer_datetime_format=True).head()
我们可以看到Date字段已从对象更改为datetime64,如以下屏幕截图所示:

总结
在本章中,我们学习了从 Pandas 数据帧中选择数据子集的方法。 我们还了解了如何将这些方法应用于真实数据集。 我们还了解了从已读入 Pandas 的数据集中选择多个行和列的方法,并将这些方法应用于实际数据集以演示选择数据子集的方法。 我们了解了 Pandas sort_values方法。 我们看到了使用sort_values方法对 Pandas 数据帧中的数据进行排序的各种方法。 我们还学习了如何对 Pandas 序列对象进行排序。 我们了解了用于从 Pandas 数据帧过滤行和列的方法。 我们介绍了几种方法来实现此目的。 我们了解了 Pandas 的filter方法以及如何在实际数据集中使用它。 我们还学习了根据从数据创建的布尔序列过滤数据的方法,并且学习了如何将过滤数据的条件直接传递给数据帧。 我们学习了 Pandas 数据选择的各种技术,以及如何选择数据子集。 我们还学习了如何从数据集中选择多个角色和列。 我们学习了如何对 Pandas 数据帧或序列进行排序。 我们逐步介绍了如何过滤 Pandas 数据帧的行,如何对此类数据帧应用多个过滤器以及如何在 Pandas 中使用axis参数。 我们还研究了字符串方法在 Pandas 中的使用,最后,我们学习了如何更改 Pandas 序列的数据类型。
在下一章中,我们将学习处理,转换和重塑数据的技术。
三、处理,转换和重塑数据
在本章中,我们将学习以下主题:
- 使用
inplace参数修改 Pandas 数据帧 - 使用
groupby方法的场景 - 如何处理 Pandas 中的缺失值
- 探索 Pandas 数据帧中的索引
- 重命名和删除 Pandas 数据帧中的列
- 处理和转换日期和时间数据
- 处理
SettingWithCopyWarning - 将函数应用于 Pandas 序列或数据帧
- 将多个数据帧合并并连接成一个
使用 inplace 参数修改 Pandas 数据帧
在本节中,我们将学习如何使用inplace参数修改数据帧。 我们首先将一个真实的数据集读入 Pandas。 然后我们将介绍 pandas 的inplace参数,并查看它如何影响方法的执行最终结果。 我们还将执行带有和不带有inplace参数的方法,以演示inplace的效果。
我们首先将pandas模块导入 Jupyter 笔记本中,如下所示:
import pandas as pd
然后我们将读取我们的数据集:
top_movies = pd.read_table('data-movies-top-grossing.csv', sep=',')
由于它是 CSV 文件,因此我们正在使用 Pandas 的read_csv函数。 现在我们已经将数据集读入了数据帧中,让我们看一些记录:
top_movies

我们正在使用的数据来自维基百科; 这是迄今为止全球顶级电影的交叉附件数据。 大多数 Pandas 数据帧方法都返回一个新的数据帧。 但是,您可能想使用一种方法来修改原始数据帧本身。 这是inplace参数有用的地方。 让我们在不带inplace参数的数据帧上调用方法以查看其在代码中的工作方式:
top_movies.set_index('Rank').head()
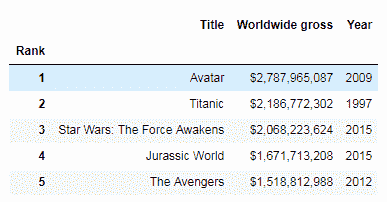
在这里,我们将其中一列设置为数据帧的索引。 我们可以看到索引已在内存中设置。 现在,让我们检查一下它是否已修改原始数据帧:
top_movies.head()
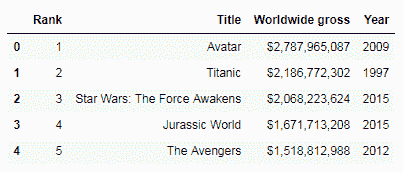
我们可以看到在原始数据帧中没有任何变化。set_index方法仅在内存中全新的数据帧中创建了更改,我们可以将其保存在新的数据帧中。 现在让我们看看如果传递inplace参数,它将如何工作:
top_movies.set_index('Rank', inplace=True)
我们将inplace=True传递给该方法。 现在让我们检查原始的数据帧:
top_movies.head()
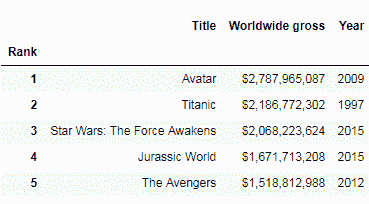
我们可以看到传递inplace=True确实修改了原始数据帧。 并非所有方法都需要使用inplace参数来修改原始数据帧。 例如,rename(columns)方法修改原始的数据帧,而不需要inplace参数:
top_movies.rename(columns = {'Year': 'Release Year'}).head()

熟悉哪些方法需要inplace,哪些不需要inplace,这是一个好主意。 在本节中,我们学习了如何使用inplace参数修改数据帧。 我们介绍了 Pandas inplace参数,以及它如何影响方法的执行最终结果。 我们探讨了带有inplace参数和不带有inplace参数的方法的执行情况,以证明结果的差异。 在下一节中,我们将学习如何使用groupby方法。
使用groupby方法
在本节中,我们将学习如何使用groupby方法将数据拆分和聚合为组。 我们将通过分成几部分来探讨groupby方法的工作方式。 我们将用统计方法和其他方法演示groupby。 我们还将学习groupby方法迭代组数据的能力如何做有趣的事情。
我们将像上一节中一样将pandas模块导入 Jupyter 笔记本中:
import pandas as pd
然后,我们将读取 CSV 数据集:
data = pd.read_table('data-zillow.csv', sep=',')
data.head()

让我们先问一个问题,看看 Pandas 的groupby方法是否可以帮助我们获得答案。 我们想要获取每个State的平均值Price值:
grouped_data = data[['State', 'Price']].groupby('State').mean()
grouped_data.head()
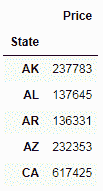
在这里,我们使用groupby方法按状态汇总数据,并获得每个State的平均值Price。 在后台,groupby方法将数据分成几组,然后我们然后将函数应用于拆分后的数据,然后将结果放在一起并显示出来。
让我们将这段代码分成几部分,看看它是如何发生的。 首先,按以下步骤进行分组:
grouped_data = data[['State', 'Price']].groupby('State')
我们选择了仅具有State和Price列的数据子集。 然后,我们对该数据调用groupby方法,并将其传递到State列中,因为这是我们希望对数据进行分组的列。 然后,我们将数据存储在一个对象中。 让我们使用list方法打印出这些数据:
list(grouped_data)
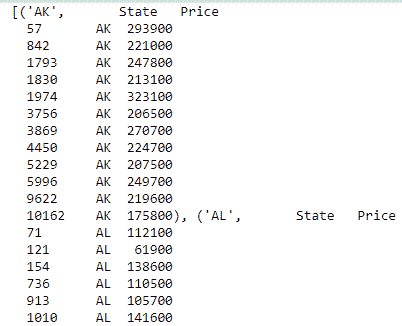
现在,我们有了基于日期的数据组。 接下来,我们对显示的数据应用一个函数,并显示合并的结果:
grouped_data.mean().head()
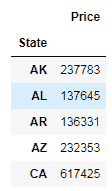
我们正在使用mean方法来获取价格的平均值。 将数据分为几组后,我们可以使用 Pandas 方法来获取有关这些组的一些有趣信息。 例如,在这里,我们分别获得有关每个州的描述性统计信息:
grouped_data.describe()
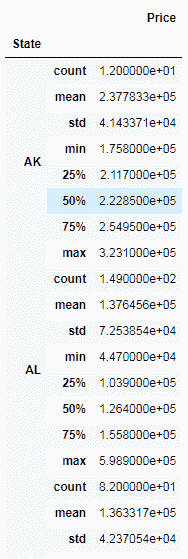
我们也可以在多列上使用groupby。 例如,在这里,我们按State和RegionName列进行分组,如下所示:
grouped_data = data[['State',
'RegionName',
'Price']].groupby(['State', 'RegionName']).mean()

我们还可以通过groupby和size方法获取每个State的记录数,如下所示:
grouped_data = data.groupby(['State']).size()

到目前为止,在本节中我们演示的所有代码中,我们都是按行分组的。 但是,我们也可以按列分组。 在下面的示例中,我们通过将axis参数集传递给1来实现此目的:
grouped_data = data.groupby(data.dtypes, axis=1)
list(grouped_data)

我们还可以遍历拆分组,并对其进行有趣的操作,如下所示:
for state, grouped_data in data.groupby('State'):
print(state, '\n', grouped_data)
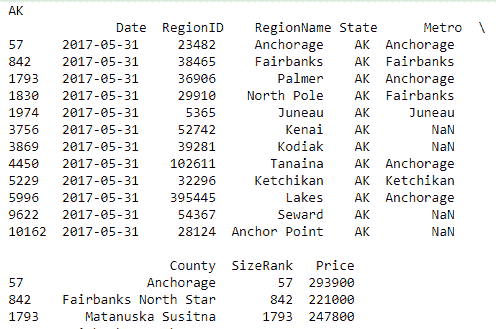
在这里,我们通过State迭代组数据,并以State作为标题发布结果,然后是该State的所有记录的表。
在本节中,我们学习了如何使用groupby方法将数据拆分和聚合为组。 我们将groupby方法分解为多个部分,以探讨其工作方式。 我们用统计方法和其他方法演示了groupby,并且还通过遍历组数据学习了如何通过groupby做有趣的事情。 在下一节中,我们将学习如何使用 Pandas 处理数据中的缺失值。
处理 Pandas 中的缺失值
在本节中,我们将探索如何使用各种 Pandas 技术来处理数据集中的缺失数据。 我们将学习如何找出缺少的数据以及从哪些列中找出数据。 我们将看到如何删除所有或大量记录丢失数据的行或列。 我们还将学习如何(而不是删除数据)如何用零或剩余值的平均值填充丢失的记录。
首先,将pandas模块导入 Jupyter 笔记本:
import pandas as pd
我们将读取我们的 CSV 数据集:
data = pd.read_csv('data-titanic.csv')
data.head()

该数据集是泰坦尼克号的乘客生存数据集,可从 Kaggle 下载。
让我们看看首先丢失了多少条记录。 为此,我们首先需要找出数据集中的总记录数。 我们通过在数据帧上调用shape属性来做到这一点:
data.shape

我们可以看到记录总数为891,总列数为12。
然后,我们找出每一列中的记录数。 我们可以通过在数据帧上调用count方法来做到这一点:
data.count()
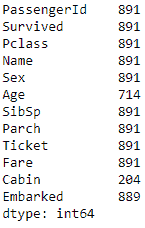
总记录与每列计数之间的差表示该列中缺少的记录数。 在12列中,我们有 3 列缺少值。 例如,Age的891行总数中只有714值;Cabin仅具有204记录的值;Embarked具有889记录的值。 我们可以使用不同的方法来处理这些缺失的值。 一种方法是删除缺少值的任何行,即使是单列也是如此,如下所示:
data_missing_dropped = data.dropna()
data_missing_dropped.shape
当运行此放置行方法时,我们将结果分配回新的数据帧中。 在891.总数中,仅剩下183记录,但是,这可能会导致丢失大量数据,并且可能无法接受。
另一种方法是只删除那些缺少所有值的行。 这是一个例子:
data_all_missing_dropped = data.dropna(how="all")
data_all_missing_dropped.shape
为此,我们将dropna方法的how参数设置为all。
代替删除行,另一种方法是用一些数据填充缺少的值。 例如,我们可以使用0填写缺失值,如以下屏幕截图所示:
data_filled_zeros = data.fillna(0)
data_filled_zeros.count()
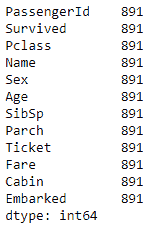
在这里,我们使用 pandas 的fillna方法,并将0的数值传递到应填充数据的列。您可以看到,现在我们已经用0填充了所有缺少的值,并且因此,所有列的计数已增加到数据集中记录总数。
另外,除了用0填充缺失值外,我们还可以用剩余的现有值的平均值填充它们。 为此,我们在要填充值的列上调用fillna方法,然后将列的平均值作为参数传递:
data_filled_in_mean = data.copy()
data_filled_in_mean.Age.fillna(data.Age.mean(), inplace=True) data_filled_in_mean.count()
例如,在这里,我们用现有值的平均值填充Age的缺失值。
在本节中,我们探讨了如何使用各种 Pandas 技术来处理数据集中的缺失数据。 我们学习了如何找出丢失的数据量以及从哪几列中查找。 我们看到了如何删除所有或很多记录丢失数据的行或列。 我们还看到了如何代替删除,也可以用0或剩余值的平均值来填写缺失的记录。 在下一节中,我们将学习如何在 Pandas 数据帧中进行数据集索引。
在 Pandas 数据帧中建立索引
在本节中,我们将探讨如何设置索引并将其用于 Pandas 中的数据分析。 我们将学习如何在读取数据后以及读取数据时在DataFrame上设置索引。 我们还将看到如何使用该索引进行数据选择。
与往常一样,我们首先将pandas模块导入 Jupyter 笔记本:
import pandas as pd
然后,我们读取数据集:
data = pd.read_csv('data-titanic.csv')
以下是我们的默认索引现在的样子,它是一个从0开始的数字索引:
data.head()

让我们将其设置为我们选择的列。 在这里,我们使用set_index方法根据我们的数据将索引设置为乘客的姓名:
data.set_index('Name')
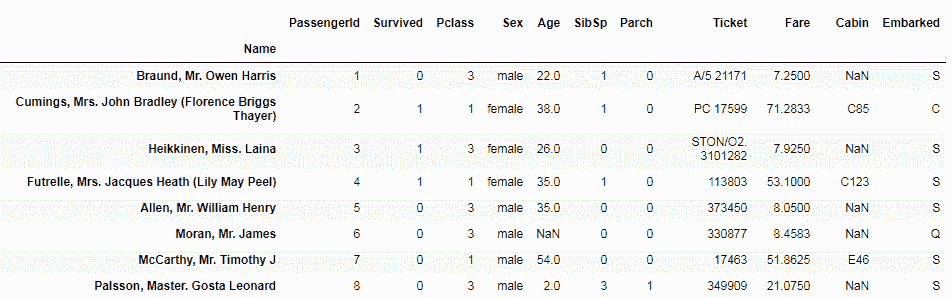
如您所见,索引已从0的简单数值更改为数据集中乘客的姓名。
接下来,我们将看到在读取数据时如何设置索引。 为此,我们将一个额外的参数index_col传递给read方法:
data = pd.read_table('data-titanic.csv', sep=',', index_col=3)

index_col参数采用单个数字值或值的序列。 在这里,我们传递Name列的索引。
接下来,让我们看看如何使用索引进行数据选择。 在以下屏幕截图中,我们在数据帧上调用loc方法,并传入我们要选择的记录的索引级别:
dta.loc['Braund, Mr.Owen Harris',:]

在这种情况下,它是数据集中一位乘客的名字。 之所以可以这样做,是因为我们先前将名称设置为数据集的索引。
最后,我们可以将索引重置为更改之前的值。 我们为此使用reset_index方法:
data.reset_index(inplace=True)
我们正在传递inplace=True,因为我们想在原始数据帧本身中将其重置。
在本节中,我们探讨了如何设置索引并将其用于 Pandas 中的数据分析。 我们还学习了在读取数据后如何在数据帧上设置索引。 我们还看到了如何在从 CSV 文件读取数据时设置索引。 最后,我们看到了一些使我们可以使用索引进行数据选择的方法。 在下一节中,我们将学习如何重命名 Pandas 数据帧中的列。
重命名 Pandas 数据帧中的列
在本节中,我们将学习在 Pandas 中重命名列标签的各种方法。 我们将学习如何在读取数据后和读取数据时重命名列,并且还将看到如何重命名所有列或特定列。 首先,将pandas模块导入 Jupyter 笔记本:
import pandas as pd
我们可以通过几种方法来重命名 Pandas 数据帧中的列。 一种方法是在从数据集中读取数据时重命名列。 为此,我们需要将列名作为列表传递给read_csv方法的names参数:
list_columns= ['Date', 'Region ID', Region Name', 'State', 'City', 'County', 'Size Rank', 'Price']
data = pd.read_csv('data-zillow.csv', names = list_columns)
data.head()

在前面的示例中,我们首先创建了所需列名称的列表; 此数字应与实际数据集中的列数相同。 然后,将列表传递给read_csv方法中的names参数。 然后,我们看到我们拥有所需的列名,因此read_csv方法已将列名从默认情况下的文本文件更改为我们提供的名称。
读取数据后,我们还可以重命名列名称。 让我们再次从 CSV 文件中读取数据集,但是这次不提供任何列名。 我们可以使用rename方法重命名列。 让我们首先看一下数据集中的列:
data.columns

现在,我们在数据帧上调用rename方法,并将列名(旧值和新值)传递给columns参数:
data.rename(columns={'RegionName':'Region', 'Metro':'City'}, inplace=True)
在前面的代码块中,我们仅更改了一些列名,而不是全部。 让我们再次调用columns属性,以查看是否确实更改了列名 , :
data.columns

现在,我们在数据集中有了新的列名。
读取数据后,我们还可以重命名所有列,如下所示:
data.columns = ['Date', 'Region ID', 'Region Name', 'State', 'City', 'County', 'Size Rank','Price']
我们已经将columns属性设置为一个名称列表,我们希望将所有列都重命名为该名称。
在本节中,我们了解了重命名 Pandas 中列级别的各种方法。 我们学习了在读取数据后如何重命名列,并学习了在从 CSV 文件读取数据时如何重命名列。 我们还看到了如何重命名所有列或特定列。
从 Pandas 数据帧中删除列
在本节中,我们将研究如何从 Pandas 的数据集中删除列或行。 我们将详细了解drop()方法及其参数的功能。
首先,我们首先将pandas模块导入 Jupyter 笔记本:
import pandas as pd
之后,我们使用以下代码读取 CSV 数据集:
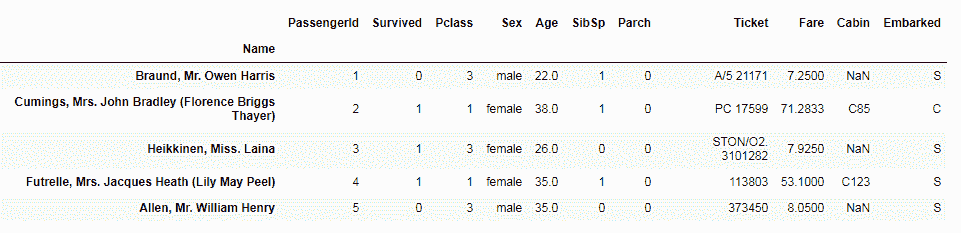
data = pd.read_csv('data-titanic.csv', index_col=3)
data.head()
数据集应类似于以下内容:
要从我们的数据集中删除单个列,请使用 pandas drop()方法。drop()方法由两个参数组成。 第一个参数是需要删除的列的名称; 第二个参数是axis。 此参数告诉drop方法是否应该删除行或列,并将inplace设置为True,这告诉该方法将其从原始数据帧本身删除。
在此示例中,我们考虑删除Ticket或列。 的代码如下:
data.drop('Ticket', axis=1, inplace=True)
执行此操作后,我们的数据集应类似于以下内容:
data.head()
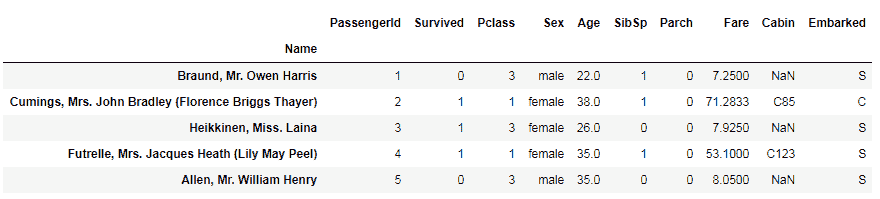
如果我们仔细观察,很明显Ticket列已从我们的数据集中删除或删除。
要删除多个列,我们将需要删除的列作为列表传递给drop()方法。drop()方法的所有其他参数将保持不变。
让我们看一个如何使用drop()方法消除行的示例。
在此示例中,我们将删除多行。 因此,与其传递列名,不如传递一个列表形式的行索引标签。 以下代码将用于执行此操作:
data.drop(['Parch', 'Fare'], axis=1, inplace=True)
data.head()

结果,传递给drop()方法的对应于乘客姓名的两行将从数据集中删除。
现在,我们将继续仔细研究如何处理日期和时间数据。
处理日期和时间序列数据
在本节中,我们将仔细研究如何处理 Pandas 中的日期和时间序列数据。 我们还将看到如何:
- 将字符串转换为
datetime类型,以进行高级datetime序列操作 - 选择并过滤
datetime序列数据 - 探索序列数据的属性
我们首先将pandas模块导入到我们的 Jupyter 笔记本中:
import pandas as pd
对于此示例,让我们创建自己的数据帧数据集。 我们可以使用以下代码来做到这一点:
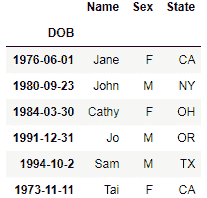
dataset = pd.DataFrame({'DOB': ['1976-06-01', '1980-09-23', '1984-03-30', '1991-12-31', '1994-10-2', '1973-11-11'],
'Sex': ['F', 'M', 'F', 'M', 'M', 'F'],
'State': ['CA', 'NY', 'OH', 'OR', 'TX', 'CA'],
'Name': ['Jane', 'John', 'Cathy', 'Jo', 'Sam', 'Tai']}))
该数据集包含对应于五个虚构人物的四列和五行。 我们的数据集中存在的行之一是DOB,其中包含五个人的出生日期。
必须检查,,,,DOB,, 列中的数据是否正确。 为此,我们使用以下代码:
dataset.dtypes

从输出中可以看出,在创建过程中DOB列可能设置为object或string数据类型。 要将其更改为datetime数据类型,我们使用to_datetime()方法并将DOB列传递给它,如下所示:
dataset.DOB = pd.to_datetime(dataset.DOB)
再次,我们可以使用以下代码来验证是否已将DOB设置为datetime数据类型:
dataset.dtypes

在继续选择和过滤datetime序列之前,我们需要确保为DOB列设置了索引。 为此,我们使用以下代码:
dataset.set_index('DOB', inplace=True)
之后,我们的DOB列已准备好进行探索。 如果要查看数据集,可以使用代码字dataset如下所示:
dataset
在开始过滤之前,我们需要了解有四种可能的方法可以过滤DOB列中的数据。 它们如下:
- 一年的记录:要显示一年的记录,我们使用以下代码:
dataset['1980']

此代码表示将显示当年1980存在的所有记录。 Pandas 不需要我们提及整个日期,因为即使是日期的一部分也会帮助我们产生结果。
- 特定年份和之后的记录:要显示特定年份和之后的所有记录,我们使用以下代码:
dataset['1980':]

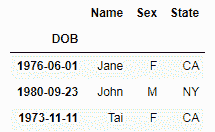
- 直到特定年份的记录:要显示直到特定年份(包括该年份)的所有记录,我们需要使用以下代码:
dataset[':1980']
- 几年范围内的记录:要显示给定年份范围内的记录,我们可以使用以下代码:
dataset['1980':'1984']

我们还可以使用时间序列属性来最有效地利用datetime序列数据。 使用此功能的缺点是datetime字段必须是列,而不是行。
这可以通过将DOB重置为索引来完成。 这样做如下:
dataset.reset_index(inplace=True)
我们还需要为datetime列中的每个值获取一年中的相应日期。 可以通过调用dayofyear属性来完成此操作,如下所示:
dataset.DOB.dt.dayofyear

我们还可以通过调用weekday_name属性来显示星期几,如下所示:
dataset.DOB.dt.weekday_name

这些是datetime序列数据的方法和属性的一些示例。 在 Pandas 的参考文档中可以找到更多内容,网址为。
处理SettingWithCopyWarning
在本节中,我们将学习SettingWithCopyWarning警告以及解决方法。
我们还将看一下可能遇到SettingWithCopyWarning的一些情况,以便我们了解如何摆脱它。
Pandas 的狂热用户肯定会遇到SettingWithCopyWarning。 各种网站,例如 Stack Overflow 和其他论坛,都充斥着有关处理此警告的查询。 它看起来像以下内容:

要了解如何摆脱它,我们需要了解SettingWithCopyWarning实际代表什么。
我们都知道,Pandas 中的不同数据操作会返回数据视图或副本。 修改数据时,这可能会引起问题。SettingWithCopyWarning的目的是警告我们,当我们想修改副本时,我们可能正在尝试修改原始数据,反之亦然。 这种情况通常在链接分配期间发生。
解决方案是使用block方法将患者链合并为一个手术。 这可以帮助 Pandas 知道必须修改哪个数据帧。
为了更好地理解这一点,让我们看下面的示例。
与往常一样,我们首先将pandas模块导入到 Jupyter 笔记本中,如下所示:
import pandas as pd
然后,我们读取 CSV 数据集:
data = pd.read_csv('data-titanic.csv')
data.head()

此后,我们继续创建一个可能遇到SettingWithCopyWarning的场景。 对于此示例,我们选择Age列为空的记录,并将它们设置为等于Age列中值的平均值。 以下是生成的错误:
data[data.Age.isnull()].Age = data.Age.mean()

为了确认我们的代码不起作用,我们需要检查是否还有Age为空的记录。 这是通过使用以下代码完成的:
data[data.Age.isnull()].Age.head()

很明显,存在这样的记录。 为了处理这种情况,我们使用loc方法,如下所示:
data.loc[data.Age.isnull(), 'Age'] = data.Age.mean
此时,我们需要返回以确认该方法是否已解决SettingWithCopyWarning,我们通过使用以下代码行来完成此操作:
data[data.Age.isnull()]
我们可以看到,问题尚未解决,因此处理警告的另一种方法是将其关闭。 我们需要记住,我们能够并且应该将其关闭的唯一原因是因为它是警告,而不是错误。 为此,我们将mode.chained_assignment选项设置为None:
pd.set_option('mode.chained_assignment', None)
不建议使用此解决方案,因为这可能会影响我们的运营结果。 解决此警告的另一种方法是使用is_copy方法。 在这里,我们创建数据帧的新副本并将is_copy设置为None,如下所示:
data1 = data.loc[data.Age.isnull()]
data1.is_copy = None
现在让我们看一下如何将函数应用于 Pandas 序列或数据帧。
将函数应用于 Pandas 序列或数据帧
在本节中,我们将学习如何将 Python 的预构建函数和自构建函数应用于 pandas 数据对象。 我们还将学习有关将函数应用于 Pandas 序列和 Pandas 数据帧的知识。
首先,将pandas模块导入 Jupyter 笔记本:
import pandas as pd
import numpy as np
我们将读取我们的 CSV 数据集:
data = pd.read_csv('data-titanic.csv')
data.head()

让我们继续使用 Pandas 的apply方法来应用函数。 在此示例中,我们将使用lambda创建一个函数,如下所示:
func_lower = lambda x: x.lower()
在这里,我们传递一个值x并将其转换为小写。 然后,我们使用apply()方法将此函数应用于数据集中的Name字段,如下所示:
data.Name.apply(func_lower)

如果仔细观察,Name字段中的值已转换为小写。 接下来,我们了解如何将函数应用于多个列或整个数据帧中的值。 我们可以使用applymap()方法。 它以类似于apply()方法的方式工作,但是在多列或整个数据帧上。 以下代码描述了如何将applymap()方法应用于Age和Pclass列:
data[['Age', 'Pclass']].applymap(np.square)
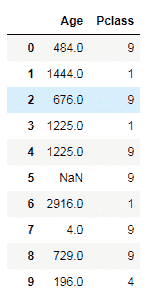
我们还将 Numpy 的secure方法应用于这两个列。
前面的步骤用于预定义函数。 现在,让我们继续创建自己的函数,然后将其应用于值,如下所示:
def my_func(i):
return i + 20
创建的函数是一个简单的函数,它带有一个值,将20添加到其中,然后返回结果。 我们使用applymap()将此函数应用于Age和Pclass列中的每个值,如下所示:
data[['Age', 'Pclass']].applymap(my_func)

让我们继续学习有关将多个数据帧合并和连接在一起的知识。
将多个数据帧合并并连接成一个
本节重点介绍如何使用 Pandas merge()和concat()方法组合两个或多个数据帧。 我们还将探讨merge()方法以各种方式加入数据帧的用法。
我们将从导入pandas模块开始。 让我们创建两个数据帧,其中两个都包含具有相同数据但具有不同记录的相同参数:
dataset1 = pd.DataFrame({'Age': ['32', '26', '29'],
'Sex': ['F', 'M', 'F'],
'State': ['CA', 'NY', 'OH']},
index=['Jane', 'John', 'Cathy'])
dataset2 = pd.DataFrame({'Age': ['34', '23', '24', '21'],
'Sex': ['M', 'F', 'F', 'F'],
State': ['AZ', 'OR', 'CA', 'WA']},
index=['Dave', 'Kris', 'Xi', 'Jo'])
dataset1
dataset2

在此示例中,让我们将这两个数据帧垂直放置在一起。 使用 pandas concat()方法通过传递两个数据帧作为其参数来执行此操作:
pd.concat([dataset1, dataset2])
我们可以看到dataset2已垂直附加到dataset1。
连接数据集的另一种方法是使用append()方法。 使用此方法获得的结果将与以前的方法相同:
dataset1.append(dataset2)
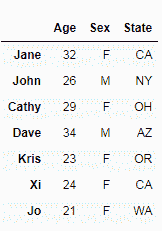
到目前为止,我们已经连接了数据集中的行,但是也可以连接列。 对于此示例,让我们创建两个新的数据集,它们具有相同的行级别但具有不同的列,如下所示:
dataset1 = pd.DataFrame({'Age': ['32', '26', '29'],
'Sex': ['F', 'M', 'F'],
'State': ['CA', 'NY', 'OH']},
index=['Jane', 'John', 'Cathy'])
dataset2 = pd.DataFrame({'City': ['SF', 'NY', 'Columbus'],
'Work Status': ['No', 'Yes', 'Yes']},
index=['Jane', 'John', 'Cathy'])
在这种情况下,我们将水平连接。 要按列连接,我们需要将axis参数传递为1:
pd.concat([dataset1, dataset2], axis=1)

数据集连接的第三个变体是连接具有不同行和列的数据集。 我们首先创建两个具有不同参数的数据集,如下所示:
dataset1 = pd.DataFrame({'Age': ['32', '26', '29'],
'Sex': ['F', 'M', 'F'],
'State': ['CA', 'NY', 'OH']},
index=['Jane', 'John', 'Cathy'])
dataset2 = pd.DataFrame({'City': ['SF', 'NY', 'Columbus'],
'Work Status': ['No', 'Yes', 'Yes']},
index=['Jane', 'John', 'Cathy'])
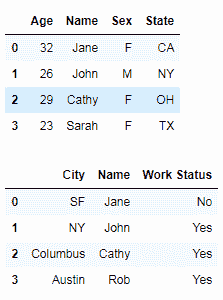
为了对这些数据集执行内部合并,我们将数据帧传递给merge()方法。 我们还指定必须在其上进行合并的列,同时确保我们指定它是内部合并。 您的数据集应类似于下表:
pd.merge(dataset1, dataset2, on='Name', how='inner')

现在,这意味着我们将两个数据集中的数据放在一起。 它仅包含在两个数据帧中具有通用标签的那些行。 接下来,我们进行外部合并。 这是通过将how参数作为left传递给merge()方法来完成的:
pd.merge(dataset1, dataset2, on='Name', how='left')
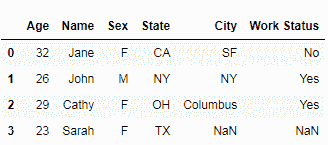
此操作的结果是将保留两个数据集中的行以及仅在第一个数据集中存在的行。 第二个数据集中仅存在的行将被丢弃。 为了进行右合并,我们将how参数设置为right:
pd.merge(dataset1, dataset2, on='name', how='right')

为了保留所有内容,我们进行了完整的外部合并。 通过将how参数传递为outer来完成完整的外部合并:
现在,即使对于没有值并标记为NaN的列,它也包含所有行,而不管它们是否存在于一个或另一个数据集中,或存在于两个数据集中。
总结
在本章中,我们学习了各种 Pandas 技术来操纵和重塑数据。 我们学习了如何使用inplace参数修改 Pandas 数据帧。 我们还学习了可以使用groupby方法的方案。 我们看到了如何处理 Pandas 中缺失的值。 我们探索了 Pandas 数据帧中的索引,以及重命名和删除 Pandas 数据帧中的列。 我们学习了如何处理和转换日期和时间数据。 我们学习了如何处理SettingWithCopyWarning,还了解了如何将函数应用于 Pandas 序列或数据帧。 最后,我们学习了如何合并和连接多个数据帧。
在下一章中,我们将学习使用seaborn Python 库将数据可视化的技术,像一个专家一样。
四、像专业人士一样可视化数据
在本章中,我们将学习使用 seaborn 数据可视化库的数据可视化的高级技术。
特别是,我们将涵盖以下主题:
- 如何启用 Seaborn
- Seaborn 的特性
- 绘制不同类型的绘图
- 用 seaborn 绘制分类图
- 使用数据感知网格进行绘图
控制绘图美学
在本节中,我们将学习如何使用 seaborn 绘图库来控制绘图美学。 我们将学习如何安装 seaborn 并开始使用 seaborn,以及我们需要导入的模型。 我们将探索一些海洋绘图方法来绘制几种不同类型的绘图。 我们还将看到如何使用各种 seaborn 方法和属性来控制和更改绘图美观性。
在开始用 seaborn 创建绘图之前,我们需要先安装它。 在本书中,我们一直在使用 Anaconda 来安装各种 Python 库,因此我们将继续进行下去。 要安装 seaborn,请执行以下命令:
conda install seaborn
执行命令之前,请确保在管理员模式下运行命令行程序。 现在,我们需要导入本节所需的 Python 模块,如下所示:
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
我们需要导入 Pandas 的 Matplotlib 和 seaborn 模块。 我们正在使用 Matplotlib 的 inline magic 命令来确保我们的绘图连同代码一起正确显示在 Jupyter 笔记本中。
接下来,我们使用 pandas 和以下命令读取数据集:
df = pd.read_csv('data-alcohol.csv')
df.head()
我们的数据集是 CSV 文件。 它由各个国家的酒精消费数据组成。 该数据可通过这里获得。
我们的第一个 seaborn 绘图
在本节中,我们将仅使用一个变量来创建分布图,如下所示:
sns.distplot(df.beer_servings)
在这里,sns指的是 seaborn,我们之前将其导入为sns。 现在我们需要将 seaborn 方法称为distplot,并从我们之前阅读的数据中传入列名。 如下面的屏幕快照所示,这应该可以使我们通过一行代码就能得到一个不错的分布图:

此单行显示了 seaborn 库的强大功能和简单性。
使用set_style更改绘图样式
现在是时候让 Seaborn 改变绘图美学了。 在此过程中,我们还将探索许多不同的绘图类型,可以使用 seaborn 进行绘制。
将绘图背景设置为白色网格
默认的打印样式是蓝色网格。 我们可以使用以下命令将其更改为whitegrid:
sns.set()
sns.set_style("whitegrid")
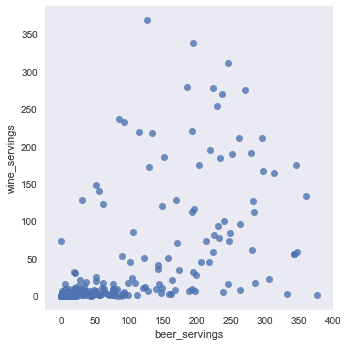
sns.lmplot(x='beer_servings', y='wine_servings', data=df);
Seaborn 提供了一种称为set_style的方法,我们将其称为whitegrid作为参数。 然后,我们调用绘图方法来绘制散点图。 我们正在使用 seaborn 的lmplot方法。 然后,我们从数据集中传递两个列名称为x和y,并将 data 参数设置为我们的 Pandas 数据帧。 现在,我们应该有一个带有白色网格背景的散点图,如以下屏幕截图所示:

将绘图背景设置为黑色
现在我们将研究如何将绘图背景设置为dark并且没有网格。 为此,我们使用以下命令将样式设置为dark:
sns.set()
sns.set_style("dark")
sns.lmplot(x='beer_servings', y='wine_servings', data=df, fit_reg=False);
您可能已经注意到,我们在开始时还有另一行代码sns.set()。 通过调用此命令,我们在进行任何更改之前将绘图美感重置为默认值。 我们这样做是为了确保我们之前所做的更改不会影响我们的总体规划,如下所示:
将背景设置为白色
我们还可以使用以下代码将图的背景设置为实心white且没有网格。
sns.set()
sns.set_style("white")
sns.swarmplot(x='country', y='wine_servings', data=df);
输出如下:

添加刻度
我们可以通过将style设置为ticks来添加刻度线,如以下代码所示:
sns.set()
sns.set_style("ticks")
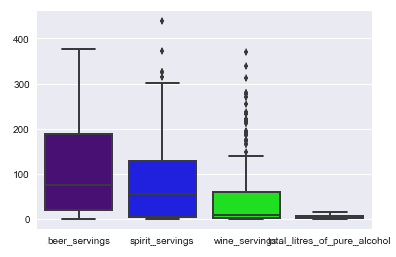
sns.boxplot(data=df);
前面的代码应为我们提供以下输出:

在这里,我们还演示了如何通过从 seaborn 调用boxplot方法来创建箱形图。
自定义样式
在 seaborn 中,我们可以自定义预设样式,甚至比以前讨论的更多。 让我们向您展示我们可以做什么!
样式参数
首先让我们看一下这些样式组成的所有参数。 我们可以通过在 seaborn 上调用axes_style方法来获取参数,如下所示:
sns.axes_style()
前面代码的输出如下:

可以进一步自定义上述每个参数。 让我们尝试自定义其中之一,如以下代码片段所示:
sns.set()
sns.set_style("ticks", {"axes.facecolor": ".1"})
sns.boxplot(data=df);
在前面的代码中,我们将style设置为ticks,背景为纯白色,但是我们可以通过分别设置facecolor来进一步自定义。 对于前面的代码,我们将获得以下输出:

请注意,我们可以向此字典添加更多参数,然后继续自定义绘图。
绘图的预定的上下文
Seaborn 还提供了一些预设样式上下文。 例如,到目前为止,我们一直在使用的默认样式上下文称为notebook。 但是,还有更多,包括一个叫做paper的。 使用称为set_context的方法设置此上下文,我们将paper作为参数传递,如下所示:
sns.set()
sns.set_context("paper")
sns.lmplot(x='beer_servings', y='wine_servings', data=df);
先前代码的输出如下:

还有更多可用的上下文。 例如,称为talk的一个。 我们可以使用talk设置该上下文,如下所示:
sns.set()
sns.set_context("talk")
plt.figure(figsize=(8, 6))
sns.lmplot(x='beer_servings', y='wine_servings', data=df);
前面代码的输出如下:
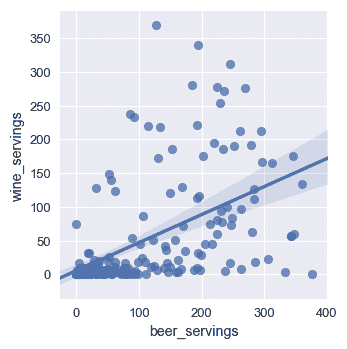
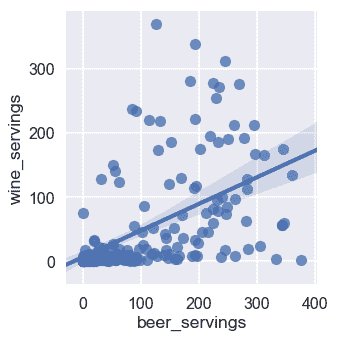
我们可以使用的另一个上下文称为poster,它使用以下代码设置:
sns.set()
sns.set_context("poster")
plt.figure(figsize=(8, 6))
sns.lmplot(x='beer_servings', y='wine_servings', data=df);
输出如下:
选择绘图的颜色
在本节中,我们将学习使用调色板自定义 seaborn 中的绘图颜色。 我们将探索 seaborn 和 Matplotlib 提供的一些调色板。 我们将学习如何通过设置不同的调色板来更改绘图的颜色,并且还将学习如何使用自定义颜色创建自己的调色板。
首先,使用以下代码导入 Jupyter 笔记本中所需的模块:
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
我们需要导入 Pandas,Matplotlib 和 seaborn。 然后,我们需要读取 CSV 数据集; 我们使用read_csv方法执行此操作,如下所示:
df = pd.read_csv('data-alcohol.csv')
df.head()
前面代码的输出如下:

现在我们需要使用 seaborn 来调用color_palette方法来获取当前的调色板,该调色板是默认设置的。 然后我们使用palplot方法显示这些颜色,如下所示:
sns.palplot(sns.color_palette())
前面代码的输出如下:

现在让我们看一下该调色板在绘图中的外观:
sns.set()
sns.boxplot(data=df);
前面代码的输出应类似于以下屏幕截图:

在这里,我们在数据集上绘制了箱形图。 您可能会注意到,配色方案看上去与我们在打印默认调色板时看到的相似。
更改调色板
让我们继续并更改调色板,以了解它如何影响绘图的颜色。 以下代码将调色板设置为bright(seaborn 的预定义调色板之一):
sns.set_palette("bright")
让我们看看如何使用以下命令来改变绘图的颜色:
sns.boxplot(data=df);
现在,输出应类似于以下屏幕截图:

如您所见,由于我们设置了新的调色板,我们图的配色方案已经完全改变。bright不是 seaborn 中唯一的预定义调色板; 还有其他一些,包括deep,muted,pastel,bright,dark和colorblind,如下所示:
sns.palplot(sns.color_palette("deep", 7))
sns.palplot(sns.color_palette("muted", 7))
sns.palplot(sns.color_palette("pastel", 7))
sns.palplot(sns.color_palette("bright", 7))
sns.palplot(sns.color_palette("dark", 7))
sns.palplot(sns.color_palette("colorblind", 7))
每个调色板的输出如下:

Seaborn 还可以将 Matplotlib 的颜色图设置为调色板。 例如:
sns.palplot(sns.color_palette("RdBu", 7))
sns.palplot(sns.color_palette("Blues_d", 7))
上一条命令的输出如下:

现在让我们使用 Matplotlib 颜色图之一作为调色板。 我们使用以下命令执行此操作:
sns.set_palette("Blues_d")
在这里,我们将调色板设置为Blues_d,这是 Matplotlib 颜色图。 现在,让我们使用以下代码重绘图以查看其影响:
sns.boxplot(data=df);
前面命令的输出应类似于以下屏幕截图:

如您所见,我们的绘图现在具有来自蓝色色图的调色板。
建立自定义调色板
要构建自定义调色板,我们首先需要创建一个列表并为其分配所需的颜色,如下所示:
my_palette = ['#4B0082', '#0000FF', '#00FF00', '#FFFF00', '#FF7F00',
'#FF0000']
sns.set_palette(my_palette)
sns.palplot(sns.color_palette())
输出如下:
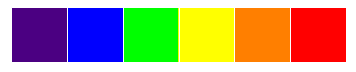
在前面的屏幕截图中,我们创建了一个名为my_palette的新调色板,具有七种颜色。 然后,我们将调色板设置为新创建的调色板,该调色板向我们展示颜色的外观。
让我们使用以下命令,通过新的自定义调色板查看绘图的外观:
sns.boxplot(data=df);
前面命令的输出应类似于以下屏幕截图:
绘制分类数据
在本节中,我们将了解 seaborn 支持的各种分类图以及如何绘制它们。 我们将演示如何绘制包括散点图,实线图,箱形图,条形图等的图。 我们还将学习如何绘制宽形的分类图。
让我们开始使用以下代码在 Jupyter 笔记本中导入我们的 pandas 模块:
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
除了 Pandas,我们还需要导入 Matplotlib 和 Seaborn Python 库。 然后,我们读取 CSV 数据集,如下所示:
df = pd.read_csv('data_simpsons_episodes.csv')
df.head()
本节中的数据集用于著名的动画电视连续剧《辛普森一家》:
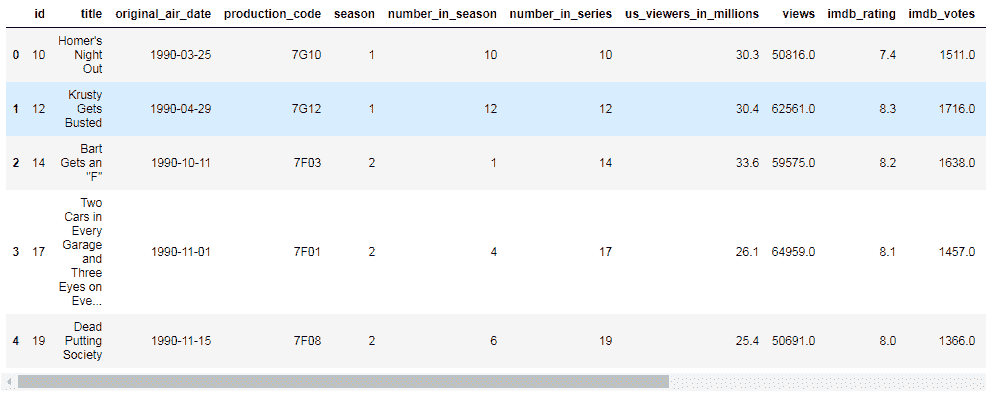
前面的数据集包含每个《辛普森一家》绘图的发行日期,收视率数字,评分以及其他观察结果的序列。
散点图
让我们从绘制散点图开始; 我们使用以下命令执行此操作:
sns.stripplot(x="season", y="us_viewers_in_millions", data=df);
输出应如下所示:
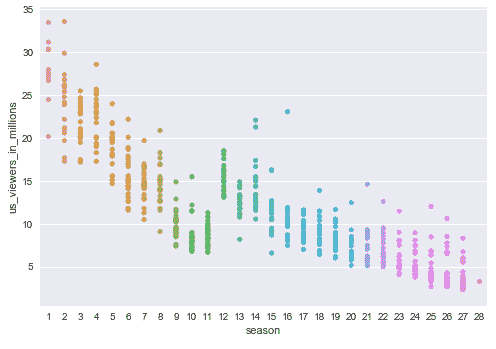
在这里,我们使用了 Seaborn 的stripplot方法。 我们在 x 轴上绘制了季节编号,并在 y 轴上绘制了以百万计的美国观众。 我们还指定了使用的数据帧的名称。
群图
现在让我们绘制swarmplot。 为此,我们使用 seaborn 的swarmplot方法:
sns.swarmplot(x="season", y="us_viewers_in_millions", data=df);
输出如下:

在这里,我们还通过了 x 轴上的季节编号,并在 y 轴上使用了数百万的观众。
箱形图
现在,我们使用相同的数据并使用boxplot方法创建箱形图,如下所示:
sns.boxplot(x="season", y="us_viewers_in_millions", data=df);
上一条命令的输出如下:

提琴图
使用violinplot()方法创建小提琴图,如下所示:
sns.violinplot(x="season", y="us_viewers_in_millions", data=df);
前面代码的输出如下:
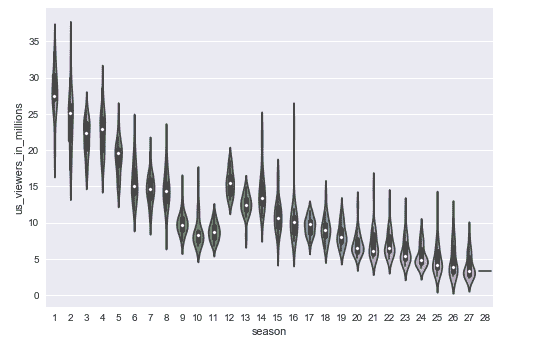
条形图
要绘制条形图,我们使用以下barplot方法:
sns.barplot(x="season", y="us_viewers_in_millions", data=df);
输出如下:
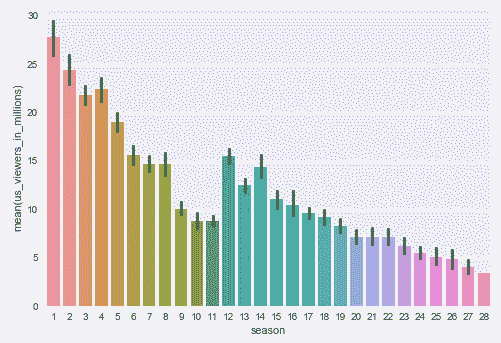
请注意,还有另一种条形图可用,这些条形图是使用countplot方法绘制的,如下所示:
sns.countplot(x="season", data=df);
前面代码的输出如下:
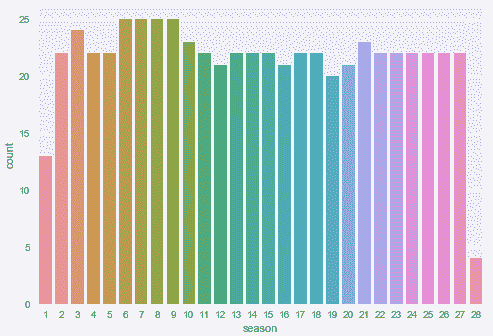
当您要显示每个类别中的观察次数而不是计算第二个变量的状态时,可以使用这种样式的图。
宽形图
Seaborn 还支持宽格式的数据图。 让我们阅读以下数据集来演示一个:
df = pd.read_csv('data-alcohol.csv')
df.head()
输出如下:

我们可以使用以下命令创建宽形箱形图:
sns.boxplot(data=df, orient="h");
前面代码的输出如下:

在这里,我们通过传入数据集并将方向作为h来创建宽幅箱形图。
使用数据感知网格进行绘图
在本节中,我们将学习在数据集的不同子集上绘制同一图的多个实例。 我们将学习使用 seaborn 的FacetGrid方法进行网格绘图。 我们还将探索 seaborn 的PairGrid和PairPlot方法进行网格绘图。
让我们从下面的代码在 Jupyter 笔记本中导入 Python 模块开始:
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
现在,我们需要使用以下代码读取第一个 CSV 数据集:
df = pd.read_csv('data-titanic.csv')
df.head()
The output from the preceding command is as follows:

使用FacetGrid()方法进行绘图
让我们开始研究如何使用FacetGrid方法绘制多维图,如以下代码所示:
g = sns.FacetGrid(df, col="Sex", hue='Survived')
g.map(plt.hist, "Age");
g.add_legend();
前面代码的输出应类似于以下屏幕截图:
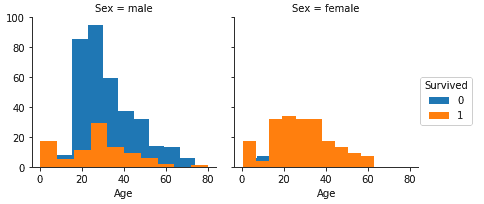
在这里,我们已经使用FacetGrid方法绘制了男性和女性乘客的两个并排直方图。 这种并排显示有助于我们比较按年龄划分的男女乘客的存活率。 为了进行绘制,我们首先使用FacetGrid方法创建了一个网格。 然后,我们将数据集的数据帧列传递为Sex,将hue传递为Survived。 色相代表绘图的深度。 然后,这创建了带有两个分别用于男性和女性乘客的绘图的网格。 然后我们在网格上调用map方法并传递了plt.hist和Age参数,它们绘制了我们的两个直方图。 最后,我们使用add_legend方法添加了图例。
使用PairGrid()方法进行绘图
现在让我们看看如何使用PairGrid方法绘制可识别网格的图。 我们正在为此使用 MLB 球员数据集,如以下代码所示:
mlb = pd.read_csv('data-mlb-players.csv')
mlb.head()
输出如下:

(Source: http://wiki.stat.ucla.edu/socr/index.php/SOCR_Data_MLB_HeightsWeights)
让我们用以下代码创建一个图:
g = sns.PairGrid(mlb, vars=["Height", "Weight"], hue="Position")
g.map(plt.scatter);
g.add_legend();
在这里,我们已经传递了 MLB 球员的数据集,并将vars设置为包含球员的Height和Weight的列表。 然后我们将hue设置为Position。 然后我们在此网格上使用scatterplot方法调用map。 最后,我们添加了图例,该图例提供了一个2 x 2网格,其中包括身高和体重曲线的所有组合,如以下屏幕截图所示:

这些位置的深度由玩家位置列提供。
使用PairPlot()方法进行绘图
通过传递数据集可以直接调用PairPlot,如下所示。 深度由hue和size参数组成:
sns.pairplot(mlb, hue="Position", size=2.5);
前面的命令为我们提供了3 x 3网格中的多图。 这是因为我们对每个位置都有三个观察值或列,如以下屏幕截图所示:
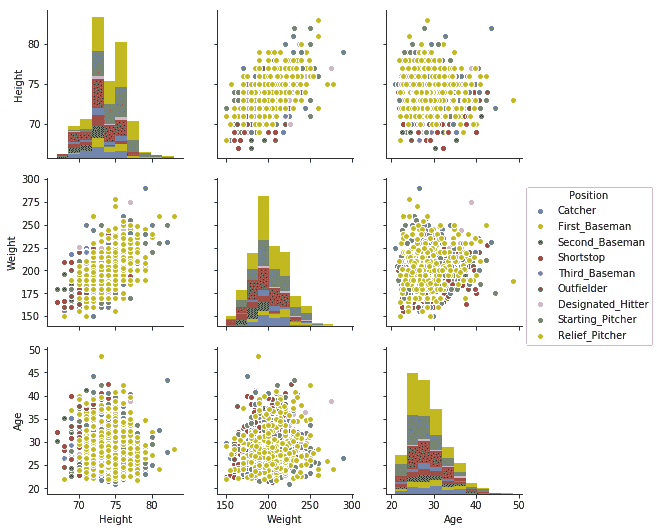
当前观察到的是Height,Weight和Age。
总结
在本章中,我们了解了使用 Seaborn 的数据可视化库进行数据可视化的高级技术。 我们学习了如何开始 seaborn,然后探索了其中的一些功能,包括如何控制绘图的美感,如何选择绘图的颜色等等。 我们学习了如何绘制几种不同类型的图,以及如何使用 seaborn 绘制分类数据。 最后,我们学习了如何使用数据感知网格来创建图。
标签:精通,方法,探索性,data,我们,所示,数据,Pandas From: https://www.cnblogs.com/apachecn/p/17314621.html