译者:飞龙
十一、合并,连接和重塑数据
数据通常被建模为一组实体,相关值的逻辑结构由名称(属性/变量)引用,并具有按行组织的多个样本或实例。 实体往往代表现实世界中的事物,例如一个人,或者在物联网中,是一个传感器。 然后,使用单个数据帧对每个特定实体及其度量进行建模。
通常需要在模型中的实体上和实体之间执行各种任务。 可能需要将来自多个位置的多个客户实体的数据组合到单个 Pandas 对象中。 客户和订单实体通常与查找订单的送货地址有关。 仅仅因为不同的源对相同类型的实体进行不同的建模,可能还需要将存储在一个模型中的数据重塑为另一个模型。
在本章中,我们将研究这些操作,这些操作使我们可以在模型中合并,关联和重塑数据。 具体而言,在本章中,我们将研究以下概念:
- 连接多个 Pandas 对象中的数据
- 合并多个 Pandas 对象中的数据
- 如何控制合并中使用的连接类型
- 在值和索引之间转换数据
- 堆叠和解除堆叠数据
- 在宽和长格式之间融合数据
配置 Pandas
我们使用以下导入和配置语句开始本章中的示例:

连接多个对象中的数据
连接是将来自两个或多个 Pandas 对象的数据组合到一个新对象中的过程。 Series对象的连接只会产生一个新的Series,并按顺序复制值。
连接DataFrame对象的过程更加复杂。 连接可以应用于指定对象的任一轴,并且 Pandas 沿着该轴对索引标签执行关系连接逻辑。 然后,Pandas 沿着相反的轴对标签进行对齐并填充缺失值。
由于有许多因素需要考虑,因此我们将分解示例分为以下主题:
- 了解连接的默认语义
- 切换对齐的轴
- 指定连接类型
- 附加而不是连接数据
- 忽略索引标签
了解连接的默认语义
使用 Pandas 函数pd.concat()进行连接。 连接数据的一般语法是传递要连接的对象列表。 下面演示了两个Series对象s1和s2的简单连接:



这将s2的索引标签和值连接到s1的索引标签和值的末尾。 由于在此过程中未执行对齐,因此导致索引标签重复。
两个DataFrame对象也可以以类似的方式连接:



默认功能导致按顺序附加行,并且可能导致沿行索引出现重复的索引标签。
列标签的结果集由指定DataFrame对象中的索引标签的并集定义。 这是应用于所有源对象的对齐方式(可以有两个以上)。 如果结果中的列在当前正在处理的DataFrame对象中不存在,则 Pandas 将插入NaN值。
以下内容演示了在连接过程中两个DataFrame对象的对齐方式,其中有共同的列(a和c)和不同的列(df1中的b和df2中的d) :


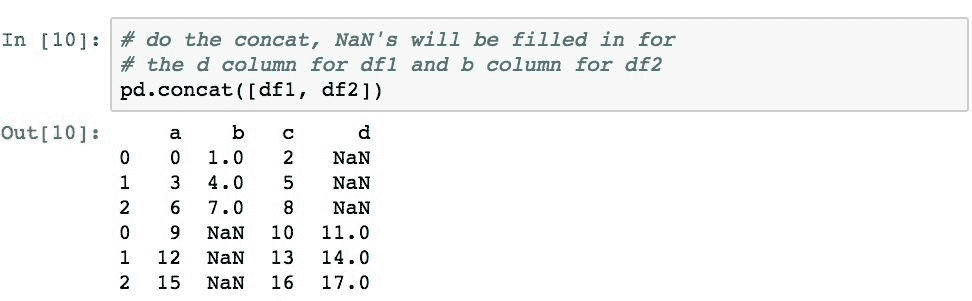
df1不包含列d,因此结果那部分中的值为NaN。 df2和列b也会发生相同的情况。
可以使用keys参数为结果中的每组数据赋予其自己的名称。 这将在DataFrame对象上创建层次结构索引,该索引使您可以通过DataFrame对象的.loc属性独立地引用每组数据。 如果以后需要确定结果DataFrame对象中的数据的来源,这将很方便。
下面通过为每个原始DataFrame对象分配名称,然后检索源自df2对象(现在已标记为'df2'标签)的行来演示此概念:
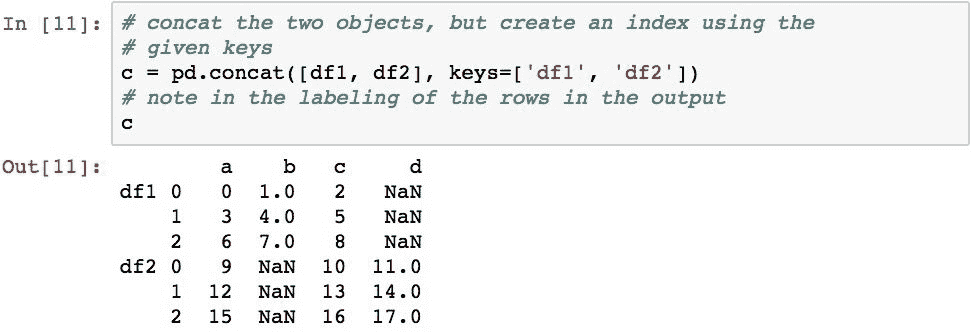
然后,这些键可用于子选择特定的数据集:

切换对齐的轴
pd.concat()函数允许您指定级联期间在其上应用对齐的轴。 以下内容将两个DataFrame对象沿列轴连接在一起,将对齐方式更改为沿行索引:

现在,此结果包含重复的列。 这是因为连接首先按每个DataFrame对象的行索引标签对齐,然后从第一个DataFrame对象然后是第二个对象填充列,而不考虑行索引标签。
以下内容演示了沿着列轴与两个DataFrame对象(具有多个共同的行索引标签)(2和3)以及不相交的行(df1和df3中的4)。 另外,df3中的几列与df1(a)重叠并且不相交(d):


由于对齐是沿着行标签进行的,因此列最终会重复。 然后,行具有NaN值,其中源对象中不存在列。
指定连接类型
默认连接实际上沿着与连接相反的轴(行索引)上的索引标签执行外连接操作。 这使得标签的结果集类似于执行那些标签的并集。
通过将join='inner'指定为参数,可以将连接的类型更改为内连接。 然后,内连接在逻辑上执行标签的交集而不是并集。 下面的示例对此进行了演示并得出了单行的结果,因为2是唯一的共同行索引标签:

当沿axis=1应用连接时,还可以使用keys参数沿列标记数据组:
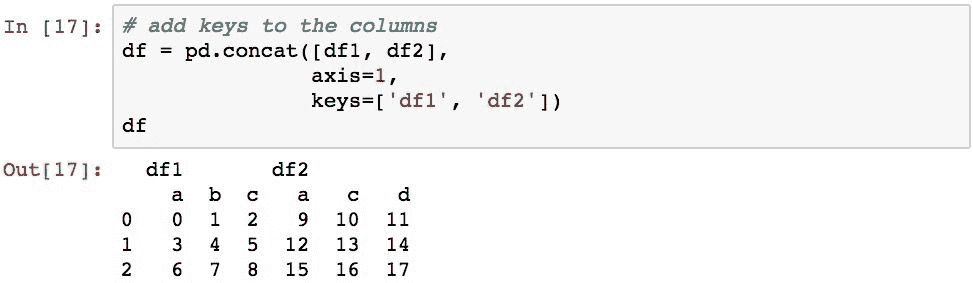
可以使用.loc属性和切片来访问不同的组:

追加与连接
DataFrame(和Series)对象还包含.append()方法,该方法将两个指定的DataFrame对象沿着行索引标签连接起来:

与在axis=1上进行连接连接一样,在不考虑创建重复项的情况下复制行中的索引标签,并且以确保在结果中不包含重复的列名的方式连接列标签。
忽略索引标签
如果要确保结果索引没有重复项并保留所有行,则可以使用ignore_index=True参数。 除了新的Int64Index之外,这基本上返回相同的结果:

此操作也可以在连接上使用。
合并和连接数据
Pandas 允许使用pd.merge()函数和DataFrame对象的.merge()方法,将 pandas 对象与类似数据库的连接操作合并。 合并通过在一个或多个列或行索引中查找匹配值来合并两个 Pandas 对象的数据。 然后,基于应用于这些值的类似关系数据库的连接语义,它返回一个新对象,该对象代表来自两者的数据的组合。
合并非常有用,因为它们允许我们为每种类型的数据(拥有整洁数据的规则之一)建模单个DataFrame,但能够使用两组数据中都存在的值来关联不同DataFrame对象中的数据。
合并来自多个 Pandas 对象的数据
合并的一个实际示例是从订单中查找客户名称。 为了在 Pandas 中证明这一点,我们将使用以下两个DataFrame对象。 一个代表客户详细信息列表,另一个代表客户所下的订单以及订单的生成日期。 它们将通过各自的CustomerID列相互关联。

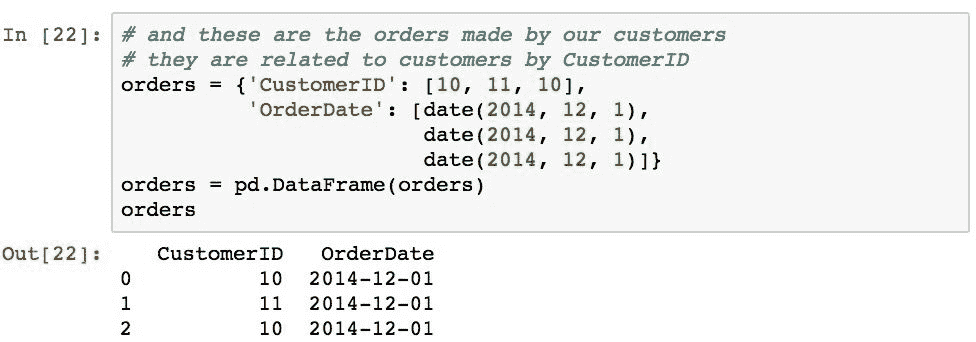
现在假设我们想将订单运送给客户。 我们需要将orders数据与customers详细数据合并,以确定每个订单的地址。 可以使用以下语句轻松执行此操作:

Pandas 能够通过如此简单的代码来完成这项工作,从而为我们做了神奇的事情。 已经意识到,我们的customers和orders对象都有一个名为CustomerID的列,并且已经了解了这一点。 它使用在两个DataFrame对象的该列中找到的公共值来关联两个数据,并基于内连接语义形成合并的数据。
为了更详细地说明发生的情况,以下是 Pandas 的具体工作:
- 它确定
customers和orders中带有公共标签的列。 这些列被视为执行连接的键。 - 它创建一个新的
DataFrame,其列是在步骤 1 中标识的键的标签,然后是两个对象中的所有非键标签。 - 它与两个
DataFrame对象的键列中的值匹配。 - 然后,它为每组匹配的标签在结果中创建一行。
- 然后,它将来自每个源对象的那些匹配行中的数据复制到结果的相应行和列中。
- 它将新的
Int64Index分配给结果。
合并中的连接可以使用多个列中的值。 为了演示,下面创建两个DataFrame对象,并使用两个对象的key1和key2列中的值执行合并:



此合并标识key1和key2列在两个DataFrame对象中是公用的。 这些列的两个DataFrame对象中值的匹配元组分别为[a,x和(c,z),因此,这将导致两行值。
要显式指定用于关联对象的列,可以使用on参数。 下面通过仅使用两个DataFrame对象的key1列中的值执行合并来演示此操作:

将该结果与前面的示例进行比较,该结果现在具有三个
行,因为在两个对象的该单个列中都有匹配的a,b和c值。
还可以为on参数提供列名列表。 以下内容恢复为同时使用key1和key2列,其结果与前面的示例相同,在前一个示例中,这两列被 Pandas 隐式标识:

在两个DataFrame对象中都必须存在用on指定的列。 如果要基于每个对象中具有不同名称的列进行合并,则可以使用left_on和right_on参数,将列的名称传递给每个参数。
要与两个DataFrame对象的行索引的标签执行合并,可以使用left_index=True和right_index=True参数(均需要指定):

这已确定共同的索引标签为1和2,因此生成的DataFrame具有两行,其中包含这些值和索引中的标签。 然后,Pandas 在结果中为两个对象中的每一列创建一列,然后复制值。
由于两个DataFrame对象都有一个具有相同名称key的列,结果中的这些列将附加_x和_y后缀以标识它们源自的DataFrame对象。 _x用于左侧,_y用于右侧。 您可以使用suffixes参数并传递两个项目的序列来指定这些后缀。
指定合并操作的连接语义
pd.merge()执行的默认连接类型是内连接。 要使用另一种连接方法,请使用pd.merge()函数的how参数(或.merge()方法)指定连接类型。 有效选项是:
inner:这是两个DataFrame对象的键的交集outer:这是来自两个DataFrame对象的键的并集left:仅使用左侧DataFrame的键right:仅使用右侧DataFrame的键
如我们所见,内连接是默认的,它仅在值匹配的情况下才从两个DataFrame对象返回数据合并。
相比之下,外部连接从左侧和右侧DataFrame对象返回匹配的行的合并和不匹配的值,但是在不匹配的部分填充NaN。 以下代码演示了外部连接:

左连接将返回满足指定列中值连接的行的合并,并且仅返回left中不匹配的行:

右连接将返回满足指定列中值连接的行的合并,并且仅返回right中不匹配的行:

pandas 库还提供了.join()方法,该方法可用于使用两个DataFrame对象的索引标签(而不是列中的值)执行连接。 请注意,如果两个DataFrame对象中的列没有唯一的列名,则必须使用lsuffix和rsuffix参数指定后缀(与合并一样,不执行自动后缀)。 以下代码演示了后缀的连接和规范:

执行的默认连接类型是外部连接。 请注意,这与.merge()方法的默认值不同,该方法的默认值为inner。 要更改为内连接,请指定how='inner',如以下示例所示:

请注意,这与Out [29]的早期结果大致相同,除了结果的列名称稍有不同。
也可以执行左右连接,但是它们导致的结果与前面的示例相似,因此为简洁起见,将省略它们。
在值和索引之间转换数据
数据通常以堆积格式存储,也称为记录格式。 这在数据库,.csv文件和 Excel 电子表格中很常见。 在堆叠格式中,数据通常不规范化,并且在许多列中具有重复的值,或者在逻辑上应存在于其他表中的值(违反了整洁数据的另一个概念)。
取得以下数据,这些数据代表来自加速度计上的数据流。

这种数据的组织问题是:如何确定特定轴的读数? 这可以通过布尔选择天真地完成:
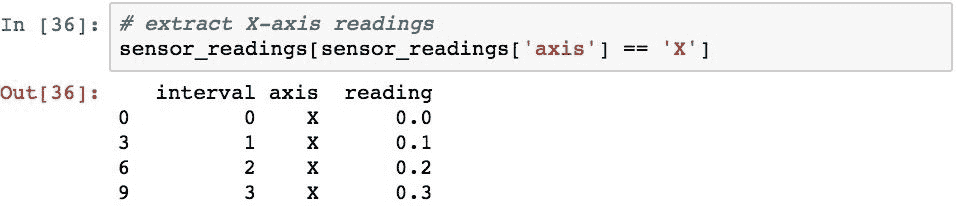
这里的问题是,如果您想知道给定时间所有轴的值而不仅仅是x轴,该怎么办。 为此,您可以为轴的每个值执行选择,但这是重复的代码,并且在不更改代码的情况下无法处理将新的轴值插入DataFrame的情况。
更好的表示方式是,列代表唯一的变量值。 要转换为这种形式,请使用DataFrame对象的.pivot()函数:

这已从axis列获取了所有不同的值,并将它们旋转到新DataFrame上的列中,同时为原始DataFrame的适当行和列中的新列填充了值。 这个新的DataFrame证明了现在很容易在每个时间间隔识别X,Y和Z传感器读数。
堆叠
与枢轴函数相似的是.stack()和.unstack()方法。 堆叠过程将列标签的级别旋转到行索引。 取消堆叠执行相反的操作,即将行索引的某个级别旋转到列索引中。
堆叠/解除堆叠与执行枢轴之间的区别之一是,与枢轴不同,堆叠和解除堆叠函数能够枢转层次结构索引的特定级别。 同样,在枢轴在索引上保留相同数量的级别的情况下,堆叠和非堆叠总是会增加其中一个轴(用于堆叠的列和用于堆叠的行)的索引上的级别,而会降低另一轴上的级别。
使用非分层索引的堆叠
为了演示堆叠,我们将看几个使用带有非分层索引的DataFrame对象的示例。 我们将使用以下DataFrame开始示例:

堆叠会将列索引的一级移到行索引的新级。 由于我们的DataFrame只有一个级别,因此这会将DataFrame对象折叠为具有分层行索引的Series对象:

要访问值,我们现在需要将一个元组传递给Series对象的索引器,该对象仅使用索引进行查找:

如果DataFrame对象包含多个列,则所有列都将移至新Series对象的相同附加级别:


现在可以使用带有索引的元组语法访问以前属于不同列的值:

通过将行索引的高度移动到列轴的高度,解除堆叠将在相反的方向上执行类似的操作。 在下一部分中,我们将检查此过程,因为通常情况下,堆叠假设假定要进行索引的索引是分层的。
使用分层索引的解除堆叠
为了演示分层索引的解除堆叠,我们将重新访问本章前面看到的传感器数据。 但是,我们将在测量数据中增加一列,以表示多个用户的读数,并复制两个用户的数据。 以下设置了此数据:


利用数据中的这种组织,我们可以执行以下操作:仅使用索引检查特定人员的所有读数:

我们还可以使用.xs()间隔1获取所有轴和所有用户的所有读数:

取消堆叠会将行索引的最后一级移动到列索引的新级别,从而导致列具有MultiIndex。 以下内容演示了此索引的最后一层(索引的axis层):

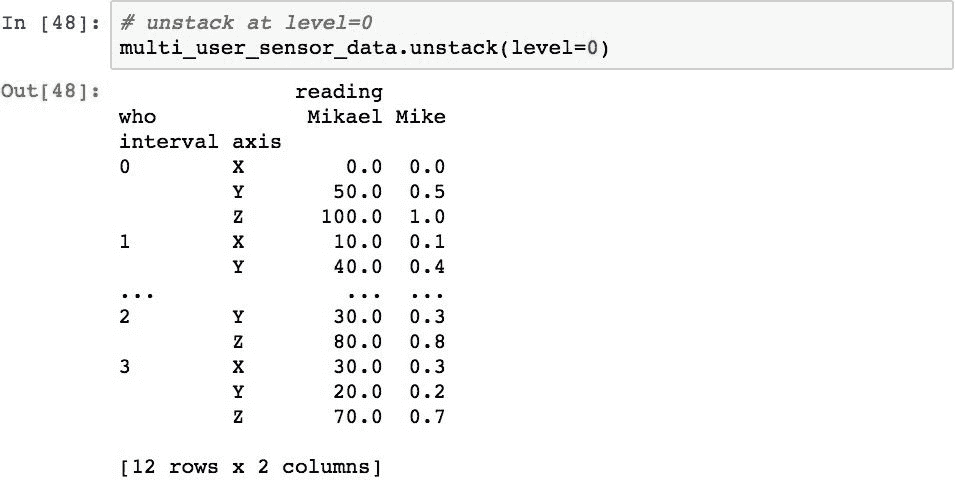
要取消堆叠其他级别,请使用level参数。 以下代码将第一层(level=0)解除堆叠:
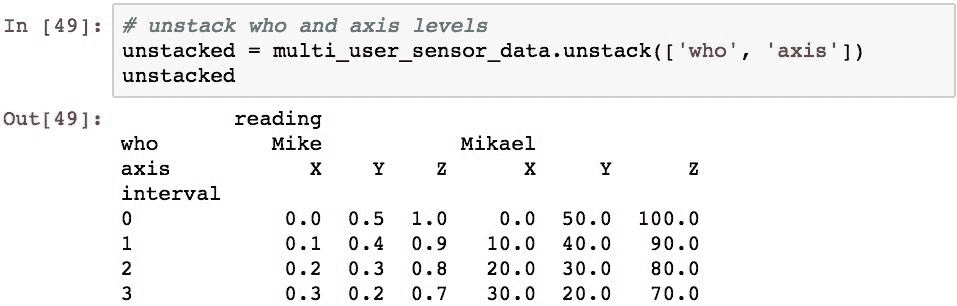
通过将级别列表传递到.unstack()可以同时取消堆叠多个级别。 此外,如果已命名级别,则可以通过名称而不是位置来指定它们。 以下按名称拆解who和axis级别:
确切地说,我们可以重新堆叠这些数据。 下面的代码会将列的who级别堆叠回到行索引中:
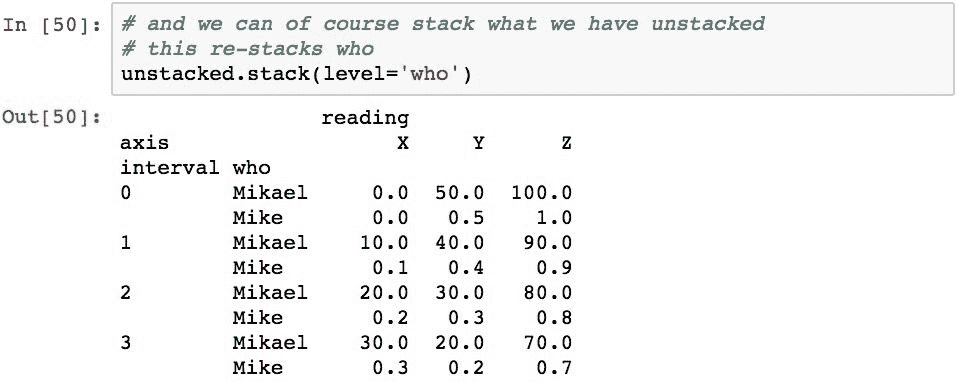
关于此结果,有两点值得指出。 首先,堆叠和解除堆叠总是将级别移动到另一个索引的最后级别。 请注意,who级别现在是行索引的最后一个级别,但它较早开始作为第一个级别。 这将对通过该索引访问元素的代码产生影响,因为它已更改为另一个级别。 如果您想将一个级别放回另一个位置,则需要使用堆叠和解除堆叠以外的其他方法来重新组织索引。
其次,随着所有这些数据移动,堆叠和解除堆叠(以及数据透视)不会丢失任何信息。 他们只是改变组织和访问它的方式。
在长格式和宽格式之间融合数据
熔化是一种不可旋转的类型,通常称为将DataFrame对象从宽格式更改为长格式。 这种格式在各种统计分析中很常见,并且您读取的数据可能已经以融合形式提供。 或者,您可能需要将这种格式的数据传递给期望该组织的其他代码。
从技术上讲,熔化是将DataFrame对象整形为
格式的过程,其中通过不旋转variable列中的列标签来创建两个或更多列,分别称为variable和value ,然后将数据从这些列移到value列中的适当位置。 然后将所有其他列制作为有助于描述数据的标识符列。
通常使用一个简单的例子可以最好地理解熔化的概念。 在此示例中,我们从一个DataFrame对象开始,该对象表示两个变量的测量值,每个变量用其自己的列Height和Weight表示,还有一个附加列表示人并由Name列指定:

下面使用Name列作为标识符列,并使用Height和Weight列作为测量变量来融化DataFrame。 Name列保留,而Height和Weight列未旋转到variable列中。 然后,将这两列中的值重新排列到value列中,并确保与原始数据中已经存在的Name和variable的适当组合值对齐:

现在对数据进行了重组,因此很容易提取variable和Name的任何组合的值。 此外,采用这种格式更容易添加新的变量和度量,因为可以简单地将数据添加为新行,而不需要通过添加新列来更改DataFrame的结构。
堆叠数据的性能优势
最后,我们将研究为什么要堆叠数据。 可以证明,堆叠数据比通过单个级别索引进行查询然后再进行列查询,甚至与按位置指定行和列的.iloc查找相比,效率更高。 以下内容说明了这一点:

如果需要从DataFrame中重复访问大量标量值,则这对应用性能可能具有极大的好处。
总结
在本章中,我们研究了在一个或多个DataFrame对象中合并和重塑数据的几种技术。 我们通过检查如何组合来自多个 Pandas 对象的数据来开始本章。 然后,我们研究了如何沿行轴和列轴连接多个DataFrame对象。 由此,我们随后研究了如何基于多个DataFrame对象中的值,使用 Pandas 执行类似于数据库的连接和数据合并。
然后,我们研究了如何使用枢轴,堆叠和融合来重塑DataFrame中的数据。 通过这一过程,我们看到了每个过程如何通过改变索引的形状以及将数据移入和移出索引来提供如何移动数据的多种变体。 这向我们展示了如何以有效地从其他形式查找数据的格式组织数据,这可能会给数据提供者带来更多便利。
在下一章中,我们将学习有关分组和对这些组中的数据进行聚合分析的知识,这将使我们能够基于数据中的相似值来得出结果。
十二、数据聚合
数据聚合是根据信息的某些有意义的类别对数据进行分组的过程。 然后对每个组进行分析,以报告每个组的一个或多个摘要统计信息。 在这种意义上,这种概括是一个通用术语,其中聚合可以从字面上是求和(例如,售出的产品总数)或统计计算(例如,均值或标准差)。
本章将研究 Pandas 执行数据聚合的功能。 这包括强大的拆分应用组合模式,用于分组,执行组级别的转换和分析,以及报告聚合 Pandas 对象中每个组的结果。 在此框架内,我们将研究几种对数据进行分组,在组级别上应用函数以及能够过滤数据进出分析的技术。
具体而言,在本章中,我们将介绍:
- 数据分析的拆分,应用和合并模式概述
- 按单个列的值分组
- 访问 Pandas 分组的结果
- 使用多列中的值进行分组
- 使用索引级别分组
- 将聚合函数应用于分组数据
- 数据转换概述
- 转换的实际示例:填充均值和 z 得分
- 使用过滤来有选择地删除数据分组
- 离散化和分级
配置 Pandas
本章中的示例使用以下导入和配置语句:

分割,应用和合并(SAC)模式
许多数据分析问题利用称为拆分应用合并的数据处理模式。 在这种模式下,采取了三个步骤来分析数据:
- 根据特定条件将数据集分成较小的部分
- 这些部分中的每一个都是独立操作的
- 然后将所有结果合并回一个单元
下图演示了一个简单的拆分应用组合过程,该过程用于计算由基于字符的键(a或b)分组的值的平均值:
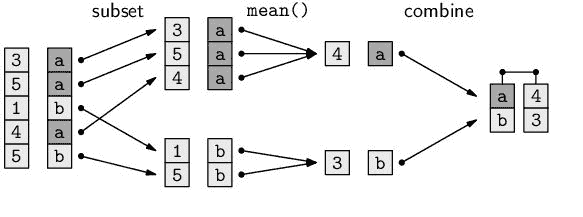
然后,数据由索引标签分为两组(a和b一组)。 计算每组中值的平均值。 然后,将来自该组的结果值组合到一个 Pandas 对象中,该对象将通过代表每个组的标签进行索引。
使用Series或DataFrame的.groupby()方法执行 Pandas 拆分。 给此方法一个或多个索引标签和/或列名; 他们将根据关联的值对数据进行分组。
拆分数据后,可以对每个组执行以下一种或多种操作类别:
- 聚合:计算聚合统计信息,例如组均值或每个组中项目的计数
- 转换:执行特定于组或项目的计算
- 过滤:根据组级计算删除整个数据组
最后一个阶段,合并,由 Pandas 自动执行,Pandas 收集应用阶段的结果并构建单个合并结果。
有关拆分应用合并的更多信息,《统计软件杂志》上有一篇论文,标题为“数据分析的拆分应用合并策略”。 本文将详细介绍该模式,尽管在示例中使用了 R,但对于学习 Pandas 的人来说仍然是有价值的读物。 您可以在这里获得此论文。
示例数据
本章中的示例将利用代表几个设备传感器测量值的数据集。 数据由加速度计和方向传感器的 X, Y 和 Z 轴上的读数组成:

分割数据
我们对在 Pandas 对象内拆分数据的检查将分为几个步骤。 首先,我们将基于列创建分组,然后检查所创建分组的属性。 然后,我们将检查访问各种属性和分组的结果,以了解所创建组的多个属性。 然后,我们将使用索引标签而不是列中的内容来检查分组。
按单个列的值来分组
传感器数据由三个类别变量(sensor,interval和axis)和一个连续变量(reading)组成。 通过将其名称传递给.groupby(),可以对任何单个类别变量进行分组。 以下代码按传感器列中的值对传感器数据进行分组:

DataFrame上的.groupby()的结果是GroupBy对象的子类,其中DataFrame的DataFrameGroupBy或Series的SeriesGroupBy。 该对象表示最终将要执行的分组的临时描述。 该对象帮助 Pandas 在执行之前首先验证相对于数据的分组。 这可以帮助优化和识别错误,并为您提供了一个点,您可以在此之前检查某些属性,而这可能是昂贵的计算过程。
此临时对象具有许多有用的属性。 .ngroups属性将检索结果中将形成的组数:

.groups属性将返回一个 Python 字典,该字典的键代表每个组的名称(如果指定了多列,则为元组)。 字典中的值是每个相应组中包含的索引标签的数组:

访问分组结果
可以将grouped变量视为已命名组的集合,并且可用于检查组的内容。 让我们使用以下函数检查这些分组:

此函数将遍历每个组并打印其名称和前五行:

对这些结果的检查为我们提供了有关 Pandas 如何进行分裂的一些见解。 已为sensors列中的每个不同值创建了一个组,并以该值命名。 然后,每个组都包含一个DataFrame对象,该对象由传感器值与该组名称匹配的行组成。
.size()方法返回所有组大小的摘要:

.count()方法返回每个组的每一列中的项目数:

可以使用.get_group()方法检索任何特定的组。 以下代码检索accel组:

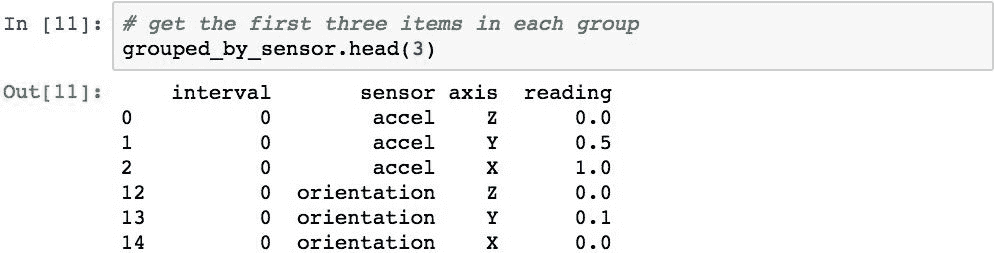
.head()和.tail()方法可用于返回每个组中指定数量的项目。 此代码检索每个组中的前三行:
.nth()方法将返回每个组中的第 n 个项目。 以下代码演示了如何使用它来检索每个组的第二行:

.describe()方法可用于返回每个组的描述性统计信息:
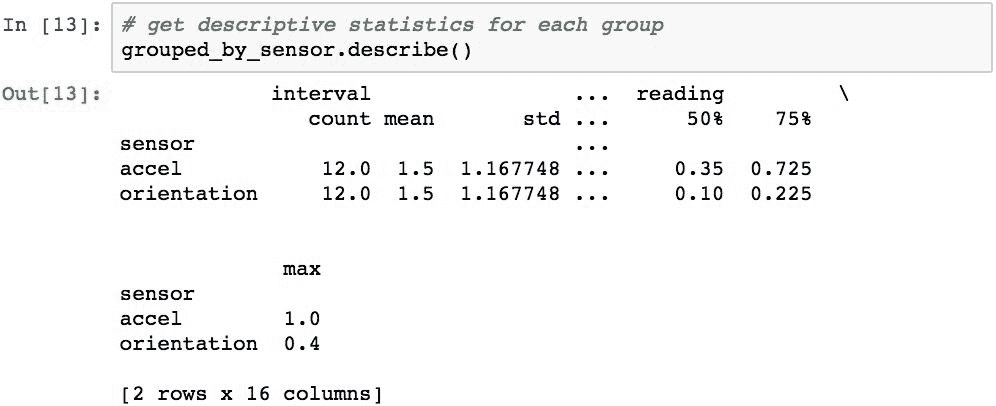
组按其组名升序排序。 如果要防止在分组过程中进行排序,请使用sort=False选项。
使用多列来分组
也可以通过传递列名列表对多个列进行分组。 以下代码按sensor和axis列对数据进行分组:

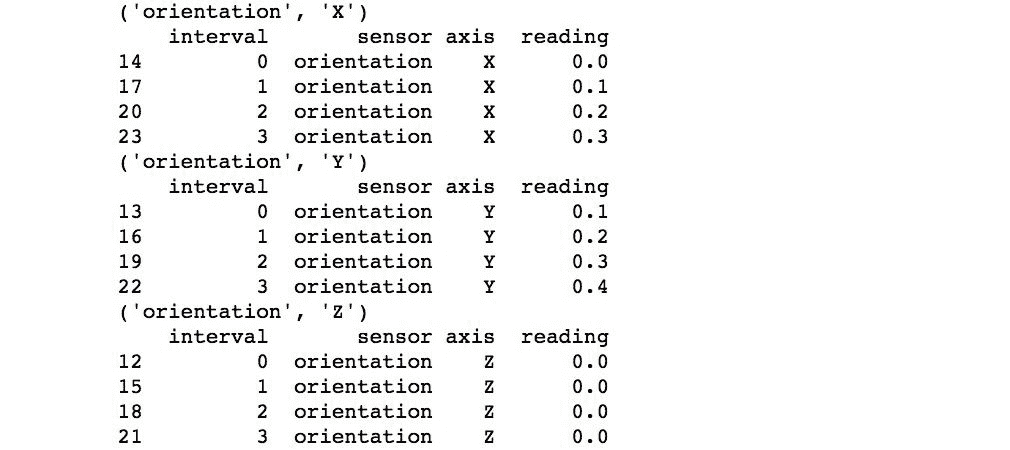
由于指定了多列,因此每个组的名称现在是一个元组,代表sensor和axis中值的每种不同组合。
使用索引级别来分组
可以使用索引中的值而不是列进行分组。 传感器数据非常适合用于层次结构索引,可用于演示此概念。 让我们使用由sensor和axis列组成的层次结构索引来设置此数据的形式:

现在可以使用分层索引的各个级别执行分组。 该代码将按索引级别 0(传感器名称)分组:
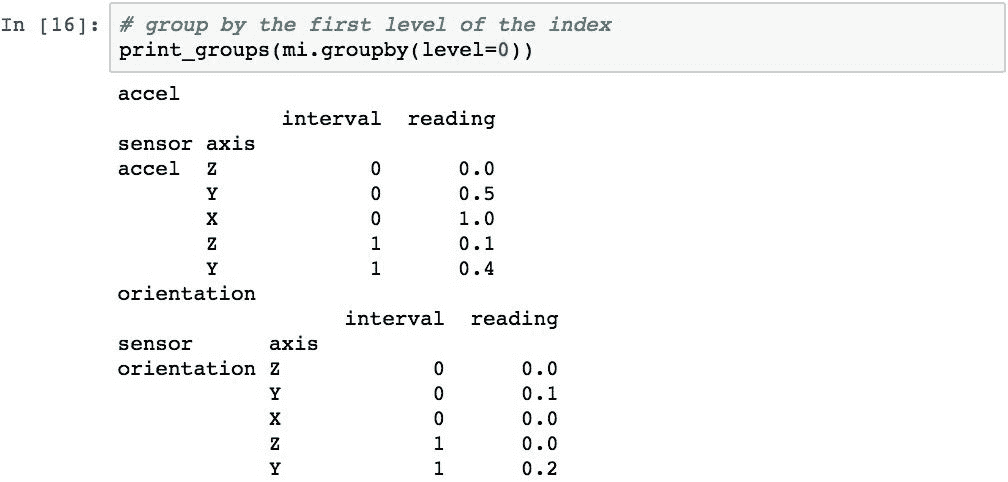
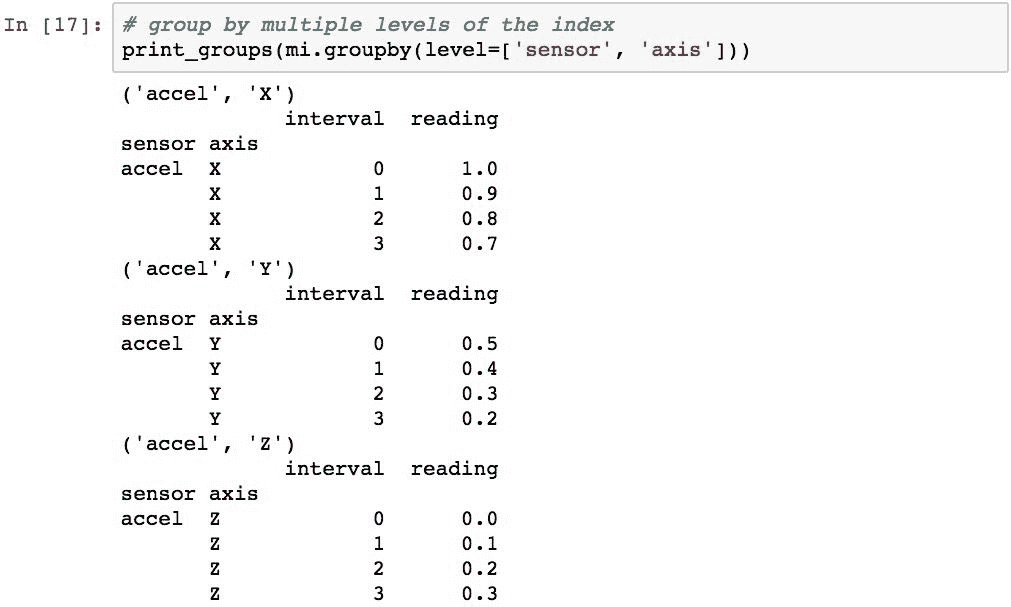
可以通过在列表中传递级别来执行按多个级别分组。 并且,如果MultiIndex具有为级别指定的名称,则可以使用这些名称代替整数。 以下代码演示了按sensor和axis进行分组:

应用聚合函数,变换和过滤器
Apply 步骤允许对每组数据进行三个不同的操作:
- 应用聚合函数
- 执行转换
- 从结果中过滤整个组
让我们检查所有这些操作。
将聚合函数应用于组
可以使用GroupBy对象的.aggregate()(或简称为.agg())方法将聚合函数应用于每个组。 .agg()的参数是将应用于每个组的函数的引用。 对于DataFrame,此函数将应用于组中的每一列数据。
下面的示例演示计算每个sensor和axis的平均值:

由于.agg()将把该方法应用于每组中的每一列,因此 pandas 也会计算间隔值的平均值(可能不太实用)。
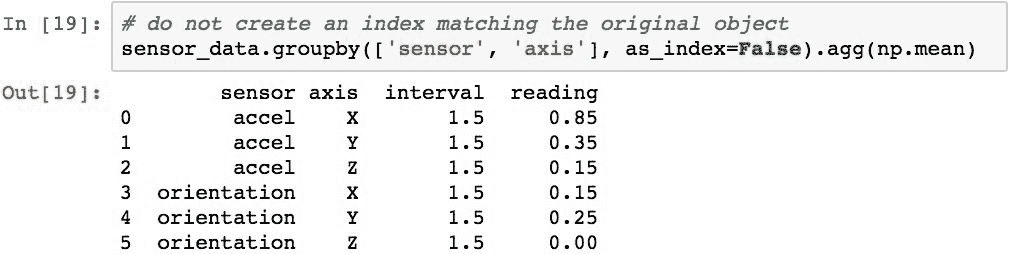
聚合的结果将具有与原始数据相同的结构化索引。 as_index=False可用于创建数字索引并将原始索引的级别移入列:
许多聚合函数直接内置在GroupBy对象中,以节省您的键入时间。 具体来说,这些函数是(前缀为gb):
gb.agg gb.boxplot gb.cummin gb.describe gb.filter gb.get_group gb.height gb.last gb.median gb.ngroups gb.plot gb.rank gb.std gb.transform
gb.aggregate gb.count gb.cumprod gb.dtype gb.first gb.groups gb.hist gb.max gb.min gb.nth gb.prod gb.resample gb.sum gb.var
gb.apply gb.cummax gb.cumsum gb.fillna gb.gender gb.head gb.indices gb.mean gb.name gb.ohlc gb.quantile gb.size gb.tail gb.weight
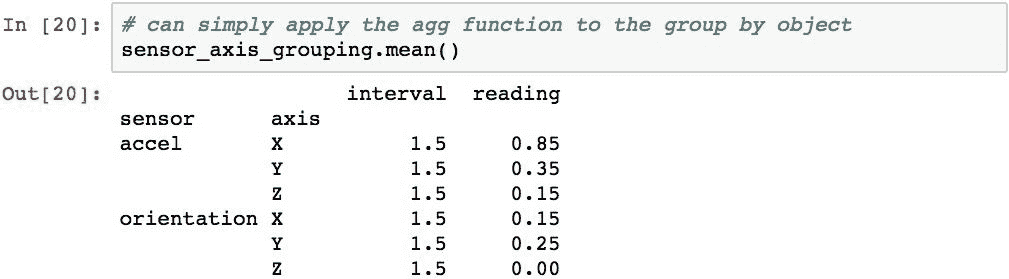
作为演示,以下代码还计算每个sensor和axis组合的平均值:
通过在列表中传递函数,也可以在同一语句中应用多个聚合函数。
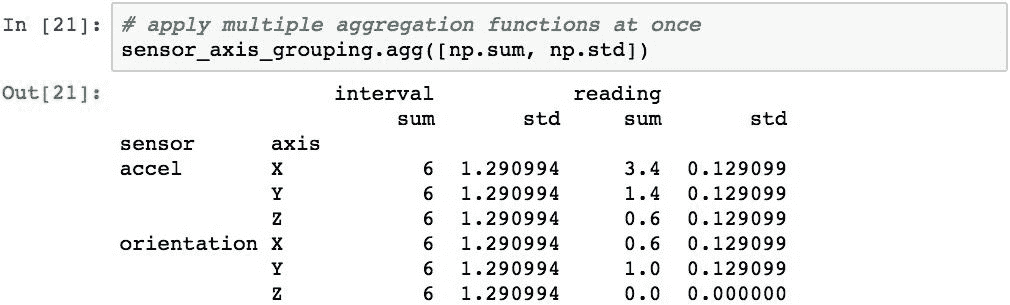
通过将 Python 字典传递给.agg(),可以将不同的函数应用于每列。 字典的键表示要应用该函数的列名,每个字典条目的值就是该函数。 以下代码通过计算reading列的平均值并返回该组的长度代替interval值来演示此技术:
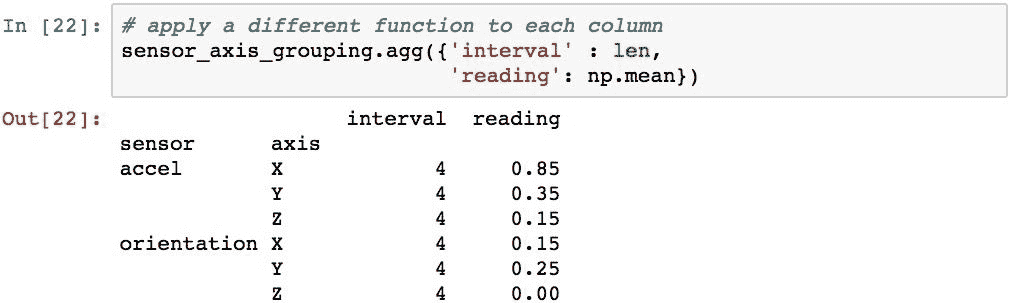
也可以使用GroupBy对象上的[]运算符在特定列上执行聚合。 此代码仅计算reading列的平均值:

转换数据组
GroupBy对象提供了.transform()方法,该方法将功能应用于每个组中DataFrame中的所有值。 我们将研究一般的转换过程,然后看两个真实的例子。
转换的一般过程
GroupBy对象的.transform()方法将一个函数应用于数据帧中的每个值,并返回另一个具有以下特征的DataFrame:
- 它的索引与所有组中索引的连接相同
- 行数等于所有组中的行数之和
- 它由未分组的列组成,Pandas 已成功将给定函数应用于该列(可以删除某些列)
为了演示实际的转换,让我们从以下数据帧开始:

让我们按Label列分组:

以下代码执行一个转换,该转换应用一个函数将每个值加 10:

pandas 尝试将函数应用于所有列,但是由于Label和Other列具有字符串值,因此转换函数将失败(它将引发异常)。 由于该失败,结果中将省略这两列。
结果也未分组,因为从转换结果中删除了分组结构。 生成的对象将具有与原始DateFrame对象的索引匹配的索引,在这种情况下为V,W,X,Y和Z。
用分组的平均值填充缺失值
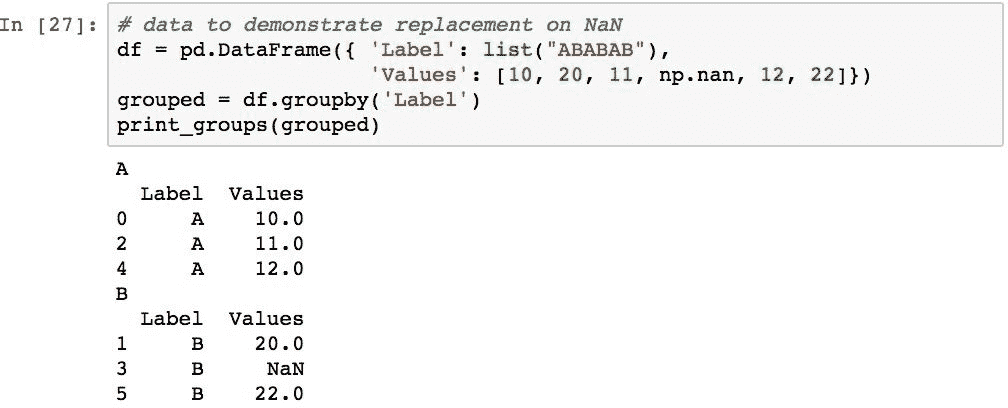
使用分组数据进行统计分析的常见转换是用组中非NaN值的平均值替换每个组中的缺失数据。 为了说明这一点,下面的代码创建一个DataFrame,其中Label列带有两个值(A和B),以及一个Values列,其中包含整数序列,但其中一个值替换为NaN。 然后,将数据按Label列分组:
每组的平均值可以使用.mean()计算:

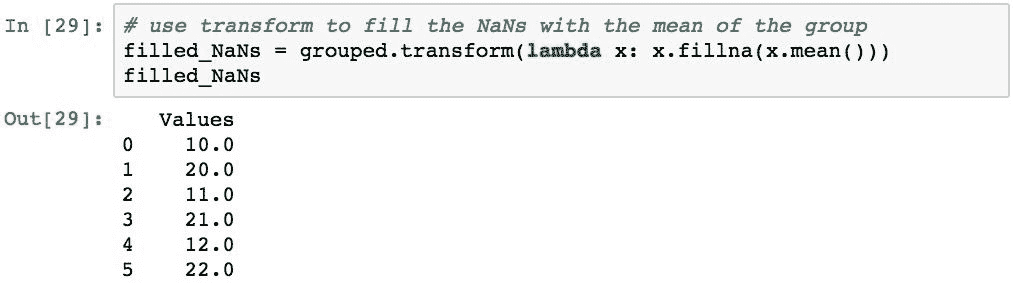
现在假设我们需要B组填写所有NaN值,因为其他使用此数据代码的人可能难以处理NaN值。 可以使用以下方法简洁地执行此操作:
通过转换计算归一化的 z 得分
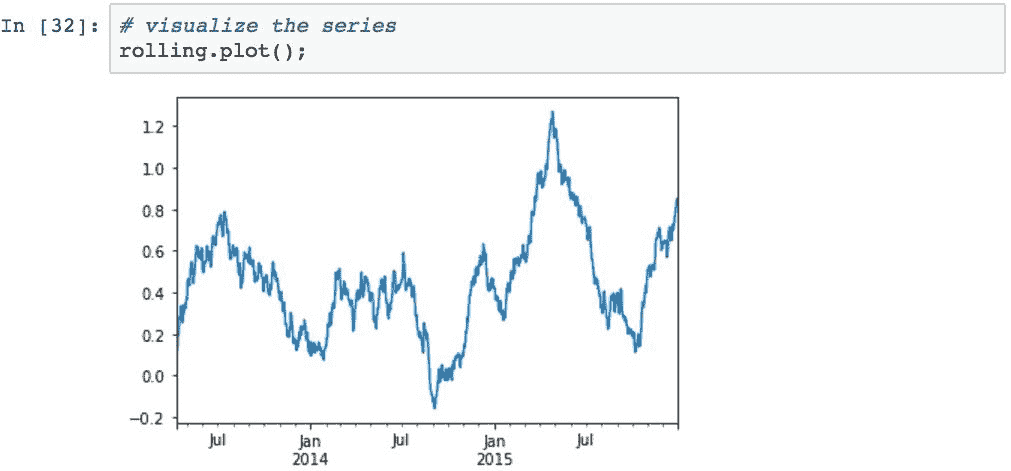
转换的另一个常见示例是在数据组上创建归一化的 z 得分。 为了证明这一点,我们将使用均值为 0.5 且标准差为 2 的正态分布来随机生成值的序列。按天为数据编制索引,并在 100 天的时间范围内计算滚动平均值以生成样本均值:

滚动装置具有以下外观:
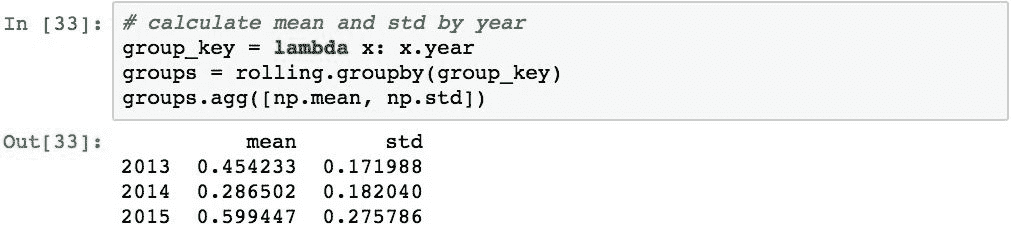
在这一点上,我们希望标准化每个日历年的滚动方式。 以下代码按年份对数据进行分组,并报告每组的现有平均值和标准差:
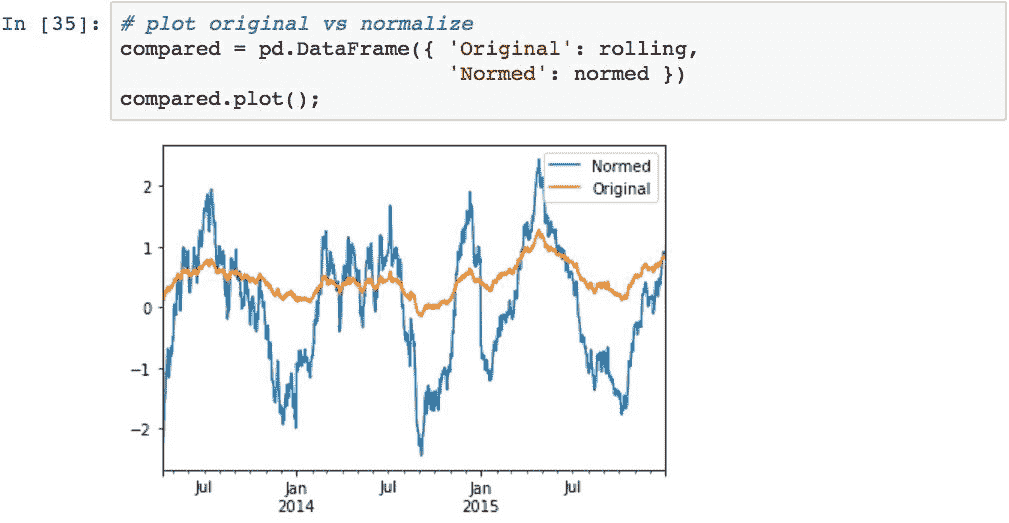
为了执行标准化,此代码定义了 z 得分函数,将其作为变换应用于每个组,并报告新的均值和标准差:

我们还可以比较原始数据和转换后的数据:
从聚合中过滤组
可以从使用.filter()的处理中选择性地删除数据组。 此方法提供了一个功能,可用于在合并后对结果中是否包括整个组做出组级决策。 如果要在结果中包含该组,则该函数应返回True,并排除该组。
我们将使用以下数据检查几种方案:

第一个演示将删除没有最少项目数的组。 具体来说,如果它们只有一项或更少,它们将被丢弃:

下面的示例将忽略具有任何NaN值的组:

下一个示例将仅选择均值大于整个数据集均值的 2.0 的组(基本上,这将选择与整体相比具有异常行为的数据组):

总结
在本章中,我们研究了使用 Pandas 对数据组进行分组和分析的各种技术。 介绍了拆分应用组合模式,并概述了如何在 Pandas 中实现这种模式。 然后,我们学习了如何基于列和索引级别中的数据将数据分为几组。 然后,我们研究了如何使用聚合函数和转换来处理每个组中的数据。 我们快速检查了如何根据数据组的内容过滤数据组。
在下一章中,我们将深入研究 Pandas 最强大,最强大的功能之一 -- 时间序列数据建模。
十三、时间序列建模
时间序列是一个时间段内和特定时间间隔内一个或多个变量的度量。 捕获时间序列后,通常会进行分析以识别时间序列中的模式,实质上是确定随着时间的流逝发生了什么。 分析时间序列数据的能力在现代世界中至关重要,这是为了分析财务信息或监视可穿戴设备上的运动并使您的运动与目标和饮食相匹配。
Pandas 提供了广泛的时间序列数据建模能力。 在本章中,我们将研究许多这些功能,包括:
- 创建具有特定频率的时间序列
- 日期,时间和间隔的表示
- 用时间戳表示时间点
- 使用
Timedelta表示时间间隔 - 使用
DatetimeIndex建立索引 - 创建具有特定频率的时间序列
- 用日期偏移量表示数据间隔
- 将时间段固定到一周,一月,一季度或一年中的特定日期
- 用时间段建模时间间隔
- 使用
PeriodIndex建立索引 - 用日历处理假期
- 使用时区标准化时间戳
- 移动和滞后时间序列
- 在时间序列上执行频率转换
- 向上和向下重新采样时间序列
- 在时间序列上执行滚动窗口操作
配置 IPython 笔记本
要利用本章中的示例,我们将需要包括以下导入和设置:
日期,时间和间隔的表示
为了开始理解时间序列数据,我们需要首先检查 Pandas 如何表示日期,时间和时间间隔。 pandas 提供了广泛的内置工具来表示这些概念,因为这些概念的表示没有足够强大地由 Python 或 NumPy 实现,无法处理处理时序数据所需的许多概念。
一些附加功能包括能够跨不同频率转换数据并应用不同的日历以在财务计算中考虑诸如工作日和假日之类的事情。
日期时间,日期和时间对象
datetime对象是datetime库的一部分,而不是 Pandas 的一部分。 此类可用于构造表示几种常见模式的对象,例如使用日期和时间的固定时间点,或者简单地是没有时间部分的一天,或者没有日期部分的时间。
datetime对象的准确性不高,涉及时间序列数据的大量计算所涉及的许多数学。 但是,它们通常用于初始化 pandas 对象,pandas 将它们转换为幕后的 pandas 时间戳对象。 因此,在这里仍然值得一提,因为它们在初始化期间会经常使用。
可以使用至少三个参数分别表示年,月和日来初始化datetime对象:

结果已将小时和分钟值默认为0。 还可以使用构造器的另外两个值来指定小时和分钟成分。 下面创建一个datetime对象,该对象还指定下午 5:30:

可以使用datetime.now()函数来确定当前日期和时间,该函数检索本地日期和时间:

datetime.date对象代表特定的日期(没有时间成分)。 可以通过将datetime对象传递给datetime的构造器来创建它:

您可以使用以下方法检索当前的本地数据:

可以使用datetime.time对象并将datetime对象传递给其构造器来创建不带日期成分的time:

当前本地时间可以使用以下方法检索:

用时间戳表示时间点
使用pandas.tslib.Timestamp类执行日期和时间的 Pandas 表示。 Pandas Timestamp基于datetime64 dtype,并具有比 Python datetime对象更高的精度。 在 Pandas 中,Timestamp对象通常可以与datetime对象互换,因此通常可以在使用日期时间对象的任何地方使用它们。
您可以使用pd.Timestamp(pandas.tslib.Timestamp的快捷方式)并通过传递表示日期,时间或日期和时间的字符串来创建Timestamp对象:

也可以指定时间元素:

也可以仅使用一个时间来创建Timestamp,默认情况下还将指定当前的本地日期:

下面演示了如何使用Timestamp检索当前日期和时间:

作为 Pandas 用户,通常不会直接创建Timestamp对象。 使用日期和时间的许多 Pandas 函数都允许您传递datetime对象或日期/时间的文本表示,并且这些函数将在内部执行转换。
使用Timedelta表示时间间隔
为了表示时间上的差异,我们将使用 Pandas Timedelta对象。 这些通常是确定两个日期之间的持续时间或从另一个日期和/或时间开始的特定时间间隔内计算日期的结果。
为了演示Timedelta,下面使用timedelta对象计算从指定日期开始的时间增加一天:

下面演示了如何计算两个日期之间有多少天:

介绍时间序列数据
Pandas 擅长处理时序数据。 这很可能是由于其起源于处理财务信息。 这些功能在其所有版本中都得到了不断完善,以逐步提高其时间序列操纵的能力。
使用DatetimeIndex建立索引
Pandas 中时间序列功能的核心围绕着使用专用索引来表示,该索引表示一个或多个时间戳下的数据度量。 Pandas 中的这些索引称为DatetimeIndex对象。 这些是功能强大的对象,它们使我们能够根据日期和时间自动对齐数据。
有几种方法可以在 Pandas 中创建DatetimeIndex对象。 下面通过将datetime对象的列表传递到Series来创建DateTimeindex:

该Series已获取datetime对象,并根据日期值构造了一个DatetimeIndex。 该索引的每个值都是一个Timestamp对象。
以下内容验证索引的类型以及索引中的标签的类型:


不需要在列表中传递datetime对象来创建时间序列。 Series对象足够聪明,可以识别出代表datetime的字符串并为您进行转换。 以下等效于先前的示例:
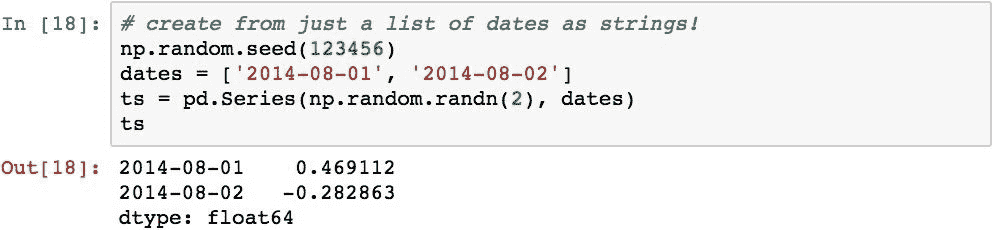
pandas 在pd.to_datetime()中提供了一个工具函数,该函数接受相似或混合类型的对象的列表,pandas 尝试将这些对象转换为Timestamp对象,然后将其转换为DatetimeIndex。 如果序列中的某个对象无法转换,则 Pandas 将创建一个NaT值,这表示不是时间:
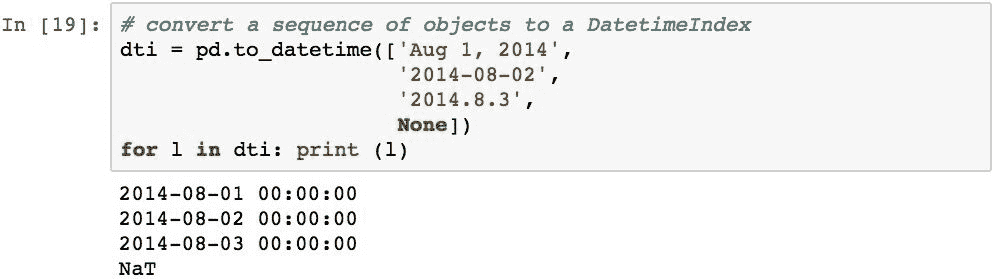
请注意,如果pd.to_datetime()函数无法将值转换为Timestamp,则会引发异常:

要强制函数将其转换为日期而不是引发异常,可以使用errors="coerce"参数。 然后,无法转换的值将在结果索引中分配NaN:

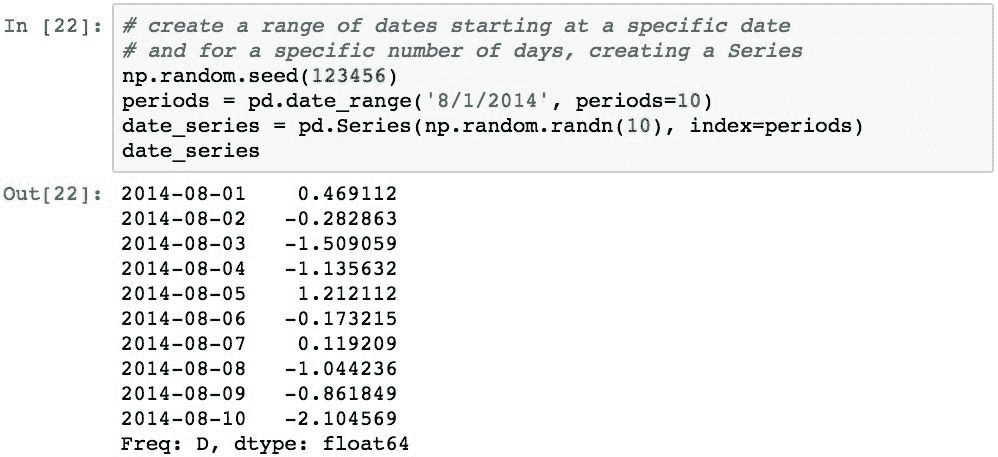
使用pd.date_range()函数可以轻松创建具有特定频率的时间戳序列。 下面根据连续10天的DatetimeIndex创建一个Series对象:
DatetimeIndex可用于各种索引操作,例如数据对齐,选择和切片。 下面演示了按位置进行切片:

为了演示对齐方式,我们将使用下面创建的Series和刚刚创建的子集的索引:

当我们添加s2和date_series时,将执行对齐,并在项目未对齐的地方返回NaN。 每个索引标签上的值将是在相同标签上找到的值的总和:

可以使用表示日期的字符串检索带有DatetimeIndex的Series中的项目,而不必指定datetime对象:

DatetimeIndex也可以使用表示日期的字符串进行切片:

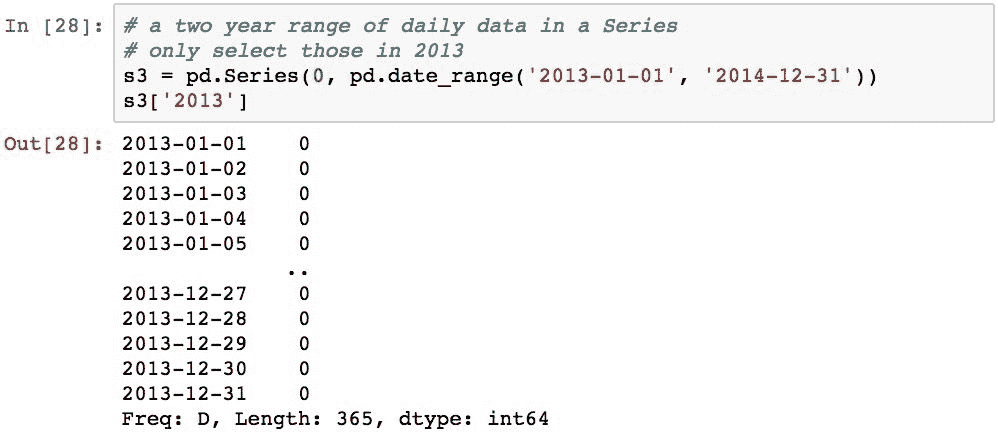
Pandas 的另一个便利功能是可以使用部分日期规范来切片DatetimeIndex。 例如,以下代码创建一个Series对象,其日期跨越两年,然后仅选择 2013 年的那些项目:
也可以选择特定年份和月份中的项目。 以下选择 2014 年 8 月的项目:

这也适用于切片。 以下是 2014 年 8 月和 9 月返回的项目:

创建具有特定频率的时间序列
可以按除每日频率以外的时间间隔创建时间序列数据。 通过使用freq参数,可以使用pd.date_range()生成不同的频率。 该参数默认为代表每日频率的值D。
为了演示替代频率,下面通过指定freq='T'以 1 分钟的间隔创建DatetimeIndex:

这个时间序列使我们能够以更高的分辨率进行切片。 在分钟级别上的以下切片:

下表列出了可能的频率值:
| 别名 | 描述 |
|---|---|
B |
业务日频率 |
C |
自定义业务日频率 |
D |
日历日频率(默认) |
W |
星期频率 |
M |
月结束频率 |
BM |
业务月结束频率 |
CBM |
自定义业务月结束频率 |
MS |
月开始频率 |
BMS |
业务月开始频率 |
CBMS |
自定义业务月开始频率 |
Q |
季度结束频率 |
BQ |
业务季度结束频率 |
QS |
季度开始频率 |
BQS |
业务季度开始频率 |
A |
年结束频率 |
BA |
业务年结束频率 |
AS |
年开始频率 |
BAS |
业务年开始频率 |
H |
小时频率 |
T |
分钟频率 |
S |
每秒频率 |
L |
毫秒频率 |
U |
微秒频率 |
您可以使用'B'频率来创建仅使用工作日的时间序列:

我们可以看到跳过了两天,就像周末一样。
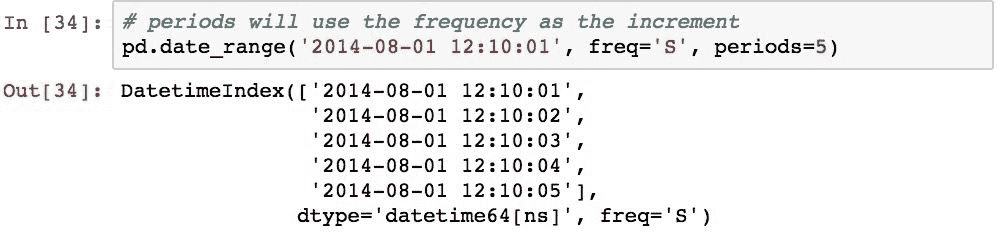
可以使用periods参数在特定的日期和时间,特定的频率和特定的数范围内创建范围。 下面创建了一个 5 项DatetimeIndex,从2014-08-01 12:10:01开始,间隔为 1 秒:
使用偏移量计算新日期
Pandas 的频率使用日期偏移量表示。 在讨论Timedelta对象时,我们已在本章开头谈到了这一概念。 Pandas 使用DateOffset对象的概念扩展了它们的功能。 它们是代表如何相对于DatetimeIndex对象整合时间偏移量和频率的知识的对象。
用日期偏移量表示数据间隔
通过使用传递的频率字符串,例如'M','W'和'BM'和pd.date_range()的freq参数,以各种频率创建DatetimeIndex对象。 在引擎盖下,这些频率字符串被转换为 Pandas DateOffset对象的实例。
DateOffset代表规则的频率增量。 在具有DateOffset各种子类的 Pandas 中,可以表示特定的日期偏移逻辑,例如“月”,“工作日”或“小时”。 DateOffset为 Pandas 提供了智能,使其能够确定如何从参考日期和时间开始计算特定的时间间隔。 与仅使用固定的数字间隔相比,这为 Pandas 用户提供了更大的灵活性,可以表示日期/时间偏移
一个有用且实用的示例是计算第二天的营业时间。 这不是简单地通过在datetime中增加一天来确定的。 如果日期表示星期五,则美国金融市场的下一个工作日不是星期六,而是星期一。 在某些情况下,如果星期一是假日,那么从星期五开始的一个工作日实际上可能是星期二。 Pandas 为我们提供了处理这类棘手情况所需的所有工具。
让我们通过使用'B'作为频率生成日期范围来研究一下这一点:

该时间序列已省略2014-08-30和2014-08-30,因为它们是星期六和星期日,而不被视为工作日。
DatetimeIndex具有.freq属性,该属性表示索引中时间戳的频率:

注意,Pandas 创建了BusinessDay类的实例来表示此索引的DateOffset单位。 如前所述,Pandas 用DateOffset类的子类表示不同的日期偏移量。 以下是 Pandas 提供的各种内置的日期偏移量类:
| 类 | 描述 |
|---|---|
DateOffset |
默认为一个日历日的通用偏移量 |
BDay |
业务日 |
CDay |
自定义业务日 |
Week |
星期,可以选择固定在一周中的某一天 |
WeekOfMonth |
每月第 y 周的第 x 天 |
LastWeekOfMonth |
每月最后一周的第 x 天 |
MonthEnd |
日历月结束 |
MonthBegin |
日历月开始 |
BMonthEnd |
业务月结束 |
BMonthBegin |
业务月开始 |
CBMonthEnd |
自定义业务月结束 |
CBMonthBegin |
自定义业务月开始 |
QuarterEnd |
季度结束 |
QuarterBegin |
季度开始 |
BQuarterEnd |
业务季度结束 |
BQuarterBegin |
业务季度开始 |
FYS253Quarter |
零售季度(52-53 周) |
YearEnd |
日历年结束 |
YearBegin |
日历年开始 |
BYearEnd |
业务年结束 |
BYearBegin |
业务年开始 |
FYS253 |
零售年(52-53 周) |
Hour |
小时 |
Minute |
分钟 |
Second |
秒 |
Milli |
毫秒 |
Micro |
微秒 |
Pandas 使用这种使用DateOffset及其专业知识的策略来编纂逻辑来计算第二天。 这使得使用这些对象既灵活又强大。 DateOffset对象可以在各种情况下使用:
- 可以将它们相加或相减以获得转换后的日期
- 可以将它们乘以整数(正数或负数),以便多次应用增量
- 它们具有
rollforward和rollback方法,可以将日期向前或向后移动到下一个或上一个“偏移日期”
可以通过向datetime对象传递代表固定时间段的datetime对象或使用多个关键字参数来创建DateOffset对象。 关键字参数分为两大类。 第一类是代表绝对日期的关键字:年,月,日,小时,分钟,秒和微秒。 第二类代表相对持续时间,可以是负值:年,月,周,日,小时,分钟,秒和微秒。
下面的代码创建 1 天的偏移量并将其添加到datetime中:

以下内容将从给定日期计算下一个工作日:

特定DateOffset的多个单位可以通过乘法表示:

下面的示例演示如何使用BMonthEnd对象从给定日期(在本例中为2014-09-02)计算一个月的最后一个工作日:

以下使用BMonthEnd对象.rollforward()方法计算下个月结束:

可以对多个偏移量类别进行参数设置,以提供对偏移量行为的更好控制。 例如,以下内容将计算2014-08-31之前一周中的星期二(weekday = 1)的日期:

锚定的偏移
锚定偏移是代表给定频率并从特定点开始的频率,例如周,月或年的特定日期。 锚定的偏移量使用特定的速记术语。 例如,以下字符串指定一周中的特定日期:
| 别名 | 描述 |
|---|---|
W-SUN |
每周日(与W相同) |
W-MON |
每周一 |
W-TUE |
每周二 |
W-WED |
每周三 |
W-THU |
每周四 |
W-FRI |
每周五 |
W-SAT |
每周六 |
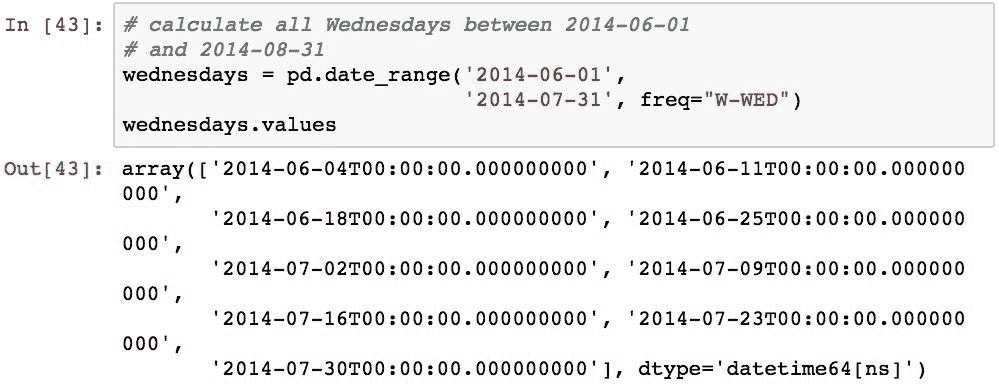
例如,下面的代码生成一个索引,该索引由两个指定日期之间的所有星期三的日期组成:
也可以使用年度和季度频率来创建锚定偏移。 这些频率锚的格式为[B][A|Q][S]-[MON],其中B(工作日)和S(开始而不是结束)是可选的,A代表年度,Q代表季度,MON是月份的三位数缩写(JAN,FEB 等)。
为了说明这一点,以下代码生成了 2014 年季度末的业务日期,而当年锚定在 6 月底:

使用时间段表示持续时间
对时序数据进行许多有用的分析操作都需要分析特定时间间隔内的事件。 一个简单的例子是确定在特定时期内发生了多少笔金融交易。
可以使用Timestamp和DateOffset进行这些类型的分析,在其中计算范围,然后根据这些范围过滤项目。 但是,当您需要处理必须分为多个时间段的事件时,这变得很麻烦,因为您开始需要管理Timestamp和DateOffset对象集。
为了促进这些类型的数据组织和计算,Pandas 使用Period类将时间间隔作为正式构造。 Pandas 还使用PeriodIndex对Period对象序列进行形式化,该功能提供了根据与对象相关联的索引对齐数据项的功能。
用时间段建模时间间隔
Pandas 使用Period对象将时间间隔的概念形式化。 Period允许您根据频率(例如每天,每周,每月,每年,每季度等)指定持续时间,它将提供一个特定的开始和结束Timestamp,代表特定的时间间隔。
使用时间戳和频率创建Period,其中时间戳表示用作参考点的锚点,频率是持续时间。 为了说明这一点,下面创建了一个代表一个月的期间,该期间固定在 2014 年 8 月:

Period具有start_time和end_time属性,可告知我们派生的开始时间和结束时间:

当我们指定 2014 年 8 月为时,Pandas 会确定锚点(start_time),然后根据指定的频率计算end_time。 在这种情况下,它将根据start_time计算一个月,并返回该值之前的最后一个时间单位。
Period上的数学运算过载,根据给定值计算另一个Period。 下面基于变量aug2014创建一个新的Period对象,该变量以其表示频率(一个月)的1单位移位:

转变的概念非常重要和强大。 向此Period对象添加1会通知它在时间上以一个正单位移动该对象表示的任何频率。 在这种情况下,它将期限从 1 个月移至 2014 年 9 月。
如果我们检查sep2014变量中表示的开始时间和结束时间,我们会发现 Pandas 已经努力确定代表 2014 年 9 月整个时间的正确日期:

请注意,Period具有知道 9 月是 30 天而不是 31 天的智能。这是Period对象背后的智能的一部分,它节省了很多编码,帮助我们解决了许多困难的日期管理问题。
使用PeriodIndex建立索引
Period对象的序列可以组合成一种特殊形式的 Pandas 索引,称为PeriodIndex。 PeriodIndex索引可用于将数据与特定时间间隔相关联,并且能够对每个间隔中的事件进行切片和执行分析。
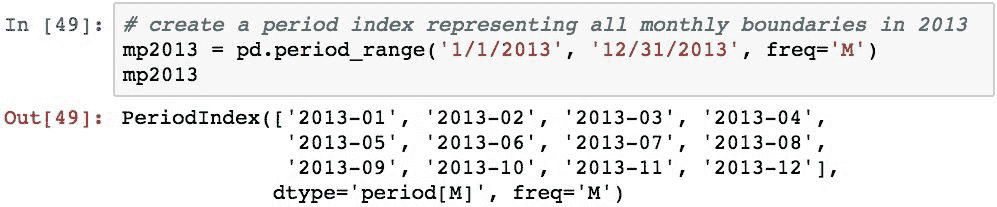
下面创建了一个PeriodIndex,其中包含 2013 年的 1 个月时间间隔:
PeriodIndex与DatetimeIndex的不同之处在于索引标签是Period对象。 以下显示索引中所有Period对象的开始和结束时间:

Pandas 已确定每个月的开始和结束,同时考虑了每个特定月份的实际天数。
使用PeriodIndex,我们可以将其用作索引来构造Series对象,并将值与索引中的每个Period相关联:

现在,我们有了一个时间序列,其中特定索引标签上的值表示跨一段时间的度量。 像这样的序列的一个例子是给定月份而不是特定时间的证券的平均值。 当我们将时间序列重新采样到另一个频率时,这变得非常有用。
像DatetimeIndex一样,PeriodIndex可用于使用Period来索引值,该字符串表示一个或部分规范。 为了演示,我们将创建另一个类似于上一个序列的序列,但跨度为 2013 年和 2014 年:

可以使用Period对象或代表句点的字符串使用特定的索引标签来选择各个值。 下面演示了如何使用字符串表示形式:

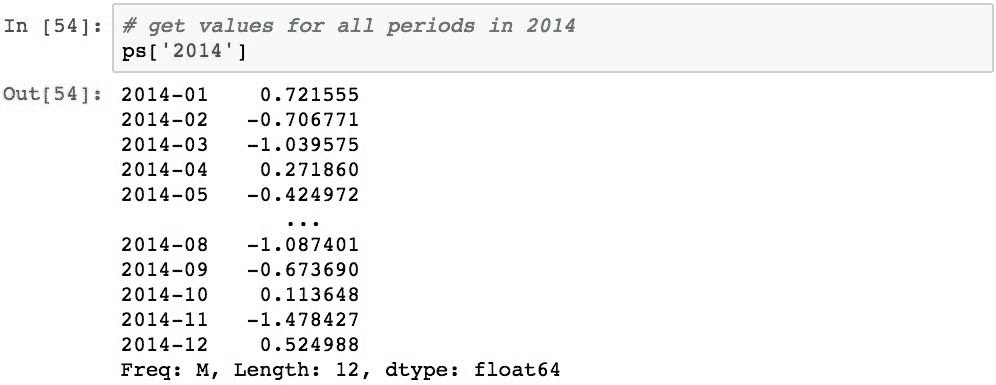
也可以使用部分规格,例如以下内容,它仅检索 2014 年期间的所有值:
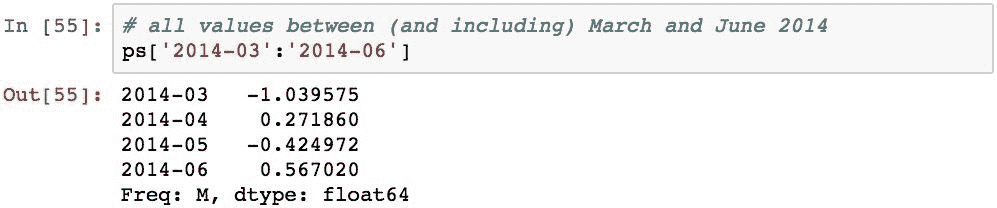
PeriodIndex也可以切片。 以下内容检索 2014 年 3 月至 2014 年 6 月之间(含)的所有值:
使用日历处理假期
早前,当我们计算 2014 年 8 月 29 日的下一个工作日时,Pandas 告诉我们该日期是 2014 年 9 月 1 日。在美国,这实际上是不正确的:2014 年 9 月 1 日是美国联邦假日,并且银行在这一天关闭交易。 原因是 Pandas 计算下一个工作日时使用特定的默认日历,并且此默认 Pandas 日历不包括 2014 年 9 月 1 日作为假日。
解决此问题的方法是创建一个自定义日历(我们将不对其进行详细介绍),或仅针对这种情况使用 Pandas 提供的一个自定义日历USFederalHolidayCalendar。 然后,可以将此自定义日历传递给CustomBusinessDay对象,而不是BusinessDay对象。 然后,使用此CustomBusinessDay对象进行的计算将使用新日历并考虑美国联邦假日。
以下内容演示了USFederalCalendar对象的创建以及如何使用它报告其认为假期的日子:

然后,可以使用此日历来计算自 2014 年 8 月 29 日起的下一个工作日:

现在,所得的计算结果将劳动节(不是工作日)考虑在内,并返回了正确的2014-09-02日期。
使用时区标准化时间戳
在使用时序数据时,时区管理可能是最复杂的问题之一。 数据通常是使用当地时间在全球范围内的不同系统中收集的,有时,它需要与在其他时区收集的数据进行协调。
幸运的是,Pandas 为使用不同时区的时间戳提供了丰富的支持。 在后台,Pandas 利用pytz和dateutil库来管理时区操作。 dateutil支持是 Pandas 0.14.1 版本的新增功能,目前仅支持固定偏移量和tzfile区域。 Pandas 使用的默认库是pytz,并提供了对dateutil的支持以与其他应用兼容。
时区感知的 Pandas 对象支持.tz属性。 默认情况下,出于时效考虑,支持时区的 Pandas 对象不使用timezone对象。 下面的代码获取当前时间,并演示默认情况下没有时区信息:

这表明 Pandas 默认情况下将Timestamp("now")视为 UTC,但没有时区数据。 这是一个很好的默认值,但请注意这一点。 总的来说,我发现如果您要根据存储的时间来收集数据以供以后访问,或者从多个数据源收集数据,则最好始终定位到 UTC。
同样,默认情况下,DatetimeIndex及其Timestamp对象将不具有关联的时区信息:

可以检索常见时区名称的列表,如以下示例所示。 如果您经常处理时区数据,这些将变得非常熟悉:

本地 UTC 时间可以使用使用的以下内容找到。 Timestamp的tz_localize()方法并传递UTC值:

通过将时区名称传递给.tz_localize(),可以将任何Timestamp本地化到特定时区:

可以使用pd.date_range()方法的tz参数在特定的时区创建DatetimeIndex:

也可以显式构造其他时区。 该模型可以让您更好地控制.tz_localize()中使用哪个时区。 下面的代码创建两个不同的timezone对象,并将Timestamp定位到每个对象:

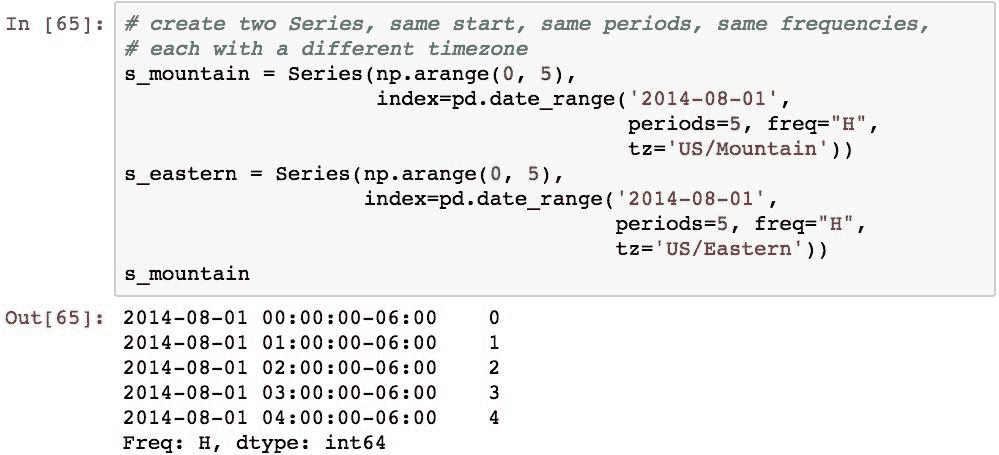
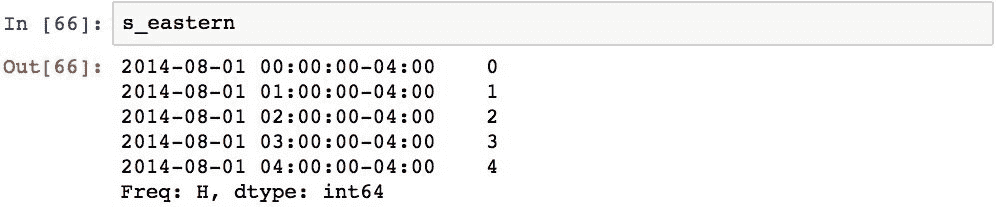
考虑到时区信息,对多个时间序列对象的操作将在其索引中按Timestamp对齐。 为了证明这一点,我们将使用以下代码,使用两个DatetimeIndex对象创建两个Series对象,每个对象的开始,周期和频率相同,但使用不同的时区:
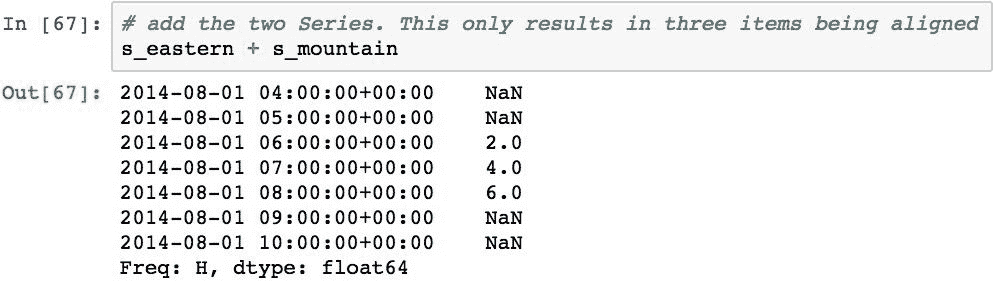
下面通过将两个Series对象加在一起展示了它们按时区的对齐方式:
将时区分配给对象后,可以使用.tz.convert()方法将该对象转换为另一个时区:
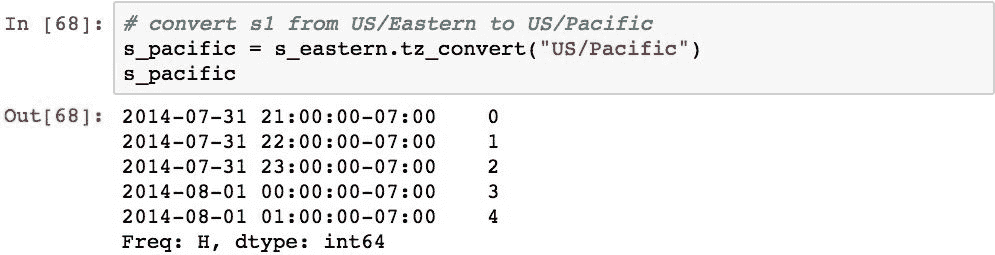
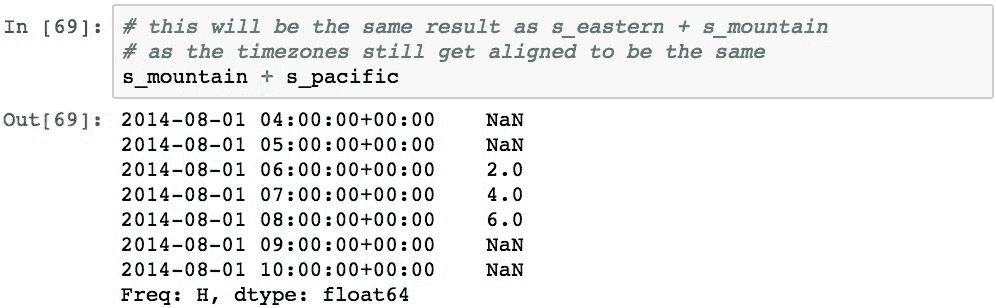
现在,如果将s_pacific添加到s_mountain,则对齐将强制执行相同的结果:
处理时间序列数据
现在,我们将研究对时间序列数据执行的几种常见操作。 这些操作需要重新排列数据,更改样本频率及其值,以及在连续移动的数据子集上计算合计结果,以确定随时间变化的数据值的行为。
移动和滞后
时间序列数据的常见操作是将值在时间上前后移动。 Pandas 方法是.shift(),它将Series或DataFrame中的值移动索引中指定频率单位的数量。
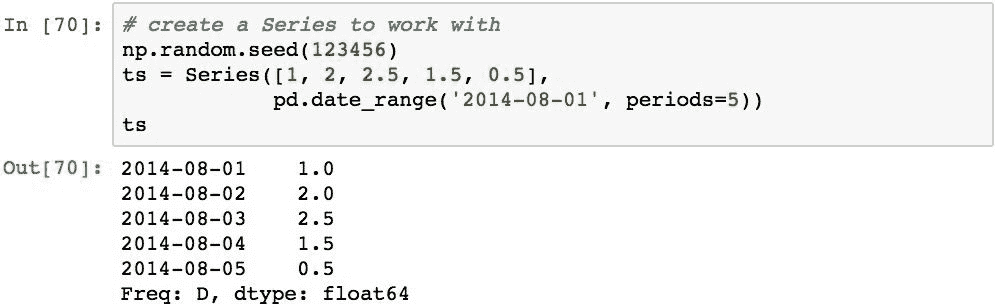
为了演示移位,我们将使用以下Series。 Series具有五个值,并按日期从2014-08-01开始索引,并使用每日频率:
以下将值向前移动 1 天:

Pandas 将这些值向前移动了指数频率的一个单位,即一天。 索引本身保持不变。 没有2014-08-01的替代数据,因此已用NaN填充。
滞后是向负方向的偏移。 以下时间比Series落后2天:

索引标签2014-08-04和2014-08-03现在具有NaN值,因为没有要替换的项目。
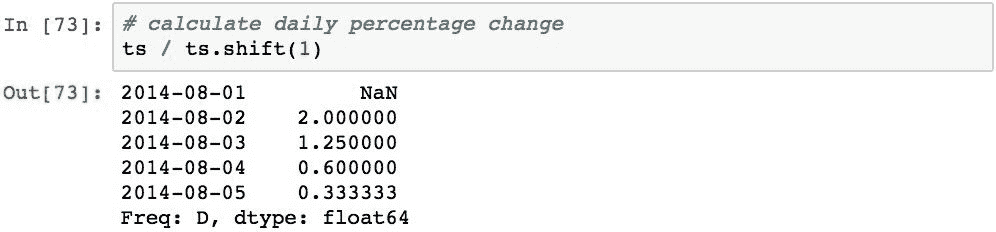
使用班次执行的常见计算是计算值的每日变化百分比。 这可以通过将Series对象除以其值偏移 1 来执行:
可以在不同于索引的频率上执行移位。 执行此操作后,索引将被修改并且值保持不变。 例如,以下将Series向前移动一个工作日:
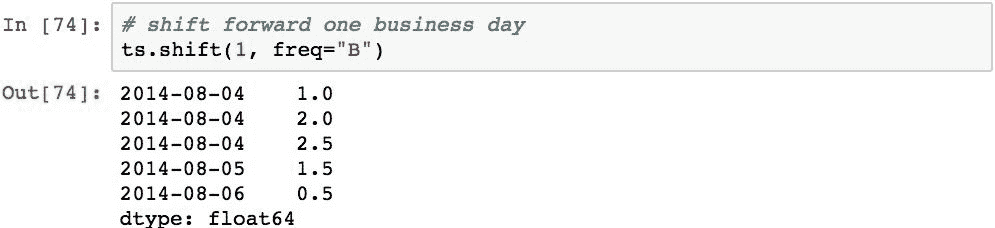
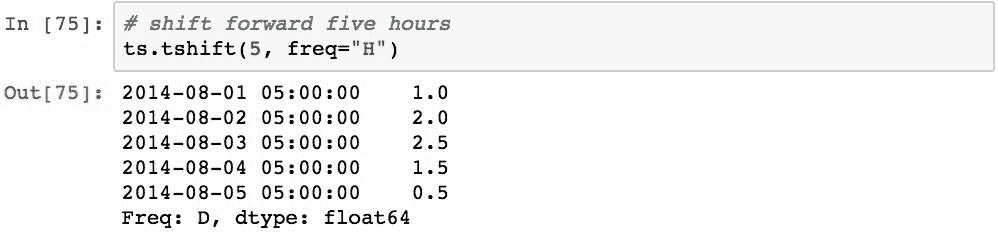
再举一个例子,以下向前移动5小时:
时间序列也可以使用DateOffset进行移位。 以下代码将时间序列向前移动0.5分钟:

.tshift()方法提供了另一种形式的移位。 此方法以指定单位和freq参数指定的频率(要求)移动索引标签。 以下代码通过按-1小时调整索引来演示此方法:

在时间序列上执行频率转换
可以使用时序对象的.asfreq()方法将频率数据转换为 Pandas。 转换频率时,将创建一个新的Series对象和一个新的DatatimeIndex对象。 新Series对象的DatetimeIndex从原始文件的第一个Timestamp开始,并以给定的频率运行,直到原始文件的最后Timestamp。 然后将值与新的Series对齐。
为了演示,我们将使用以下时间序列的连续增量整数映射到 2014 年 8 月的每一天的每一小时:
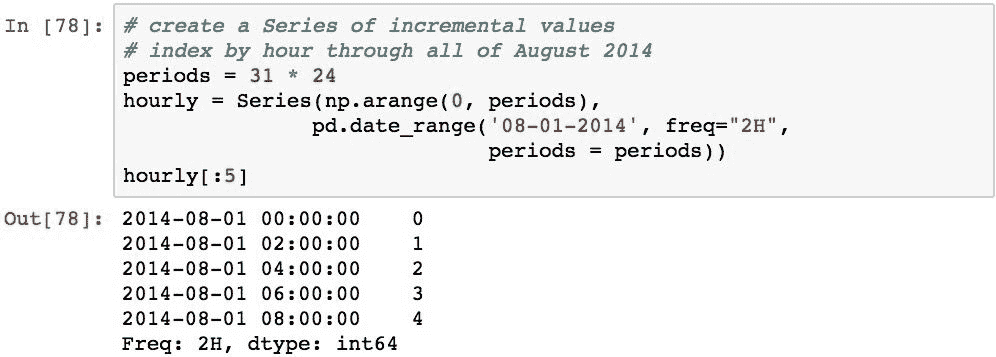
以下代码使用.asfreq('D')将此时间序列转换为每日频率:
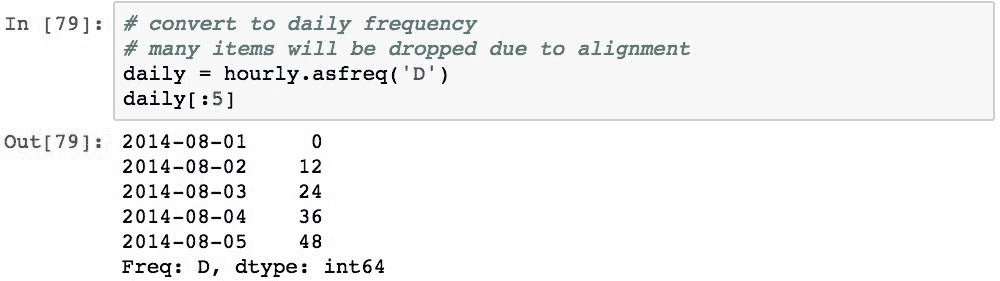
由于数据与每小时时间序列中的新的每日时间序列一致,因此仅复制与确切日期匹配的值。
如果将结果转换回每小时一次,我们将看到许多值是NaN:
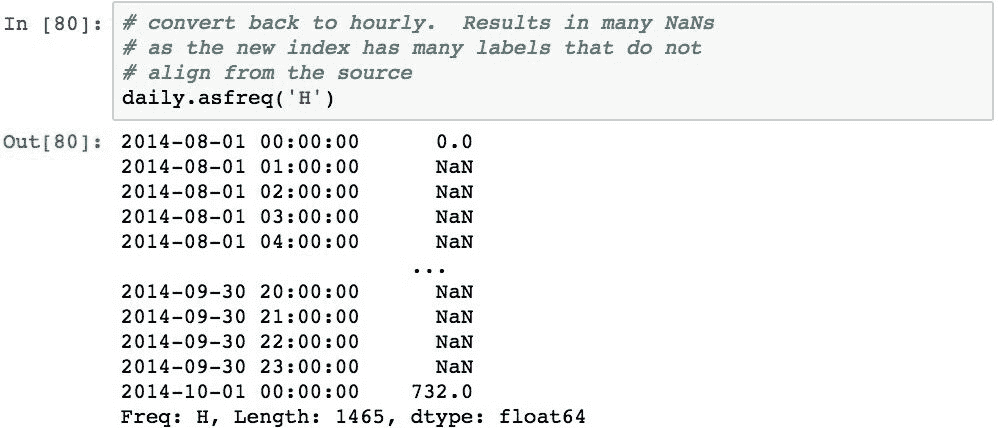
新索引按小时间隔具有Timestamp对象,因此仅确切日期的时间戳记与每日时间序列一致,从而得到 670 NaN值。
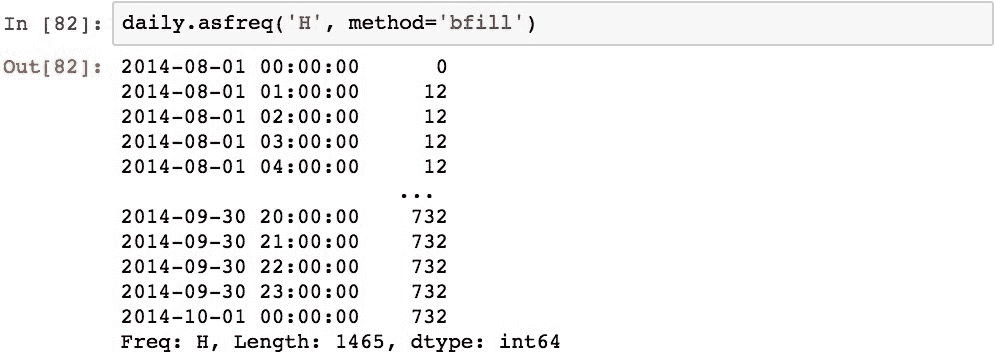
可以使用.asfreq()方法的method参数更改此默认行为。 该值可用于正向填充,反向填充或填充NaN值。
ffill方法将向前填充最后一个已知值(pad也这样做):

bfill方法将从下一个已知值回填值:
向上和向下重新采样时间序列
频率转换提供了一种将时间序列中的索引转换为另一个频率的基本方法。 新时间序列中的数据与旧数据一致,并可能导致许多NaN值。 使用填充方法可以部分解决此问题,但是其填充适当信息的能力受到限制。
重采样的不同之处在于,它不会执行纯对齐。 新序列中放置的值可以使用相同的正向和反向填充选项,但是也可以使用其他 Pandas 提供的算法或您自己的函数来指定它们。
为了演示重采样,我们将使用以下时间序列,该时间序列表示 5 天周期内值的随机游动:

使用.resample()方法并为其传递新的频率可以完成对 Pandas 的重新采样。 为了证明这一点,下面将每秒数据重新采样为分钟。 这是下采样,因为结果的频率较低,并且值较小:

请注意,第一个值为 -8.718220,而原始数据的值为 0.469112。 进行频率转换后,该值应保持在-8.718220。 这是因为重采样不会通过对齐复制数据。 重新采样实际上将根据新的周期将数据拆分为数据桶,然后对每个桶中的数据执行特定操作,在这种情况下,将计算桶的平均值。 可以使用以下方法对此进行验证,该方法将从步行中提取第一分钟的数据并计算其平均值:

在下采样中,由于现有数据是根据新的间隔放入存储桶中的,因此通常可能会问到存储桶两端的值是多少。 例如,上一次重采样的第一个间隔是从2014-08-01 00:00:00到2014-08-01 23:59:59,还是应该在2014-08-04 00:00:00处结束但在2014-08-03 23:59:59处开始?
默认值是前者,它称为左关闭。 排除左值并包括右值的另一种情况是右关闭,可以使用close='right'参数来执行。 以下内容对此进行了说明,并注意到所得到的间隔和值之间的细微差别:

关于使用左右关闭的决定实际上取决于您和您的数据建模,但是 pandas 为您提供了选择。
计算每个存储桶的平均值只是一个选择。 下面演示了在每个存储桶中获取第一个值:

为了演示上采样,我们将对步行进行重新采样至几分钟,然后又恢复为几秒钟:
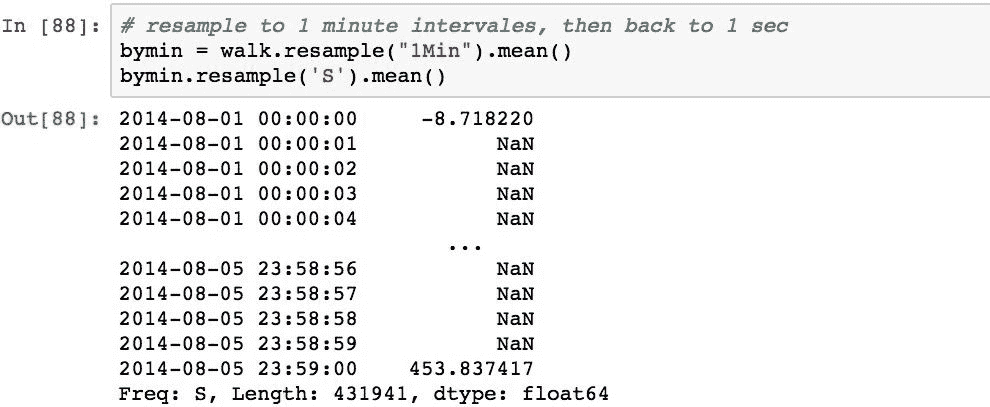
上采样为秒数据创建了索引值,但默认情况下插入了NaN值。 可以使用fill_method参数修改此默认行为。 我们在使用向前和向后填充选项更改频率时看到了这一点。 这些也可以重新采样。 下面演示了如何使用正向填充:
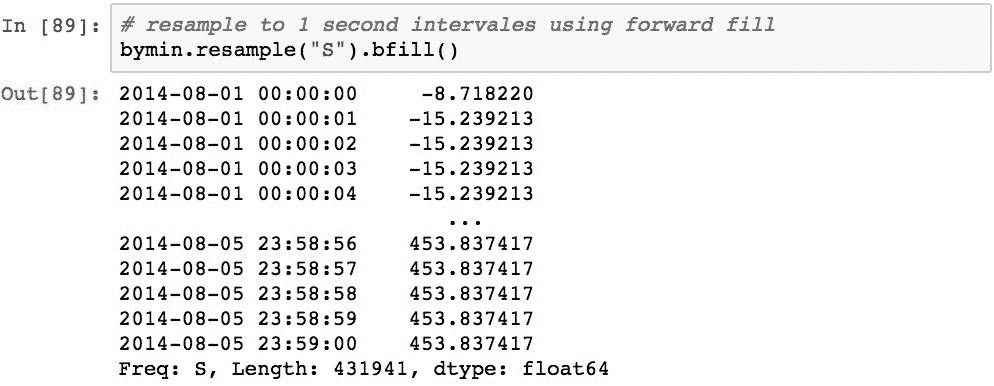
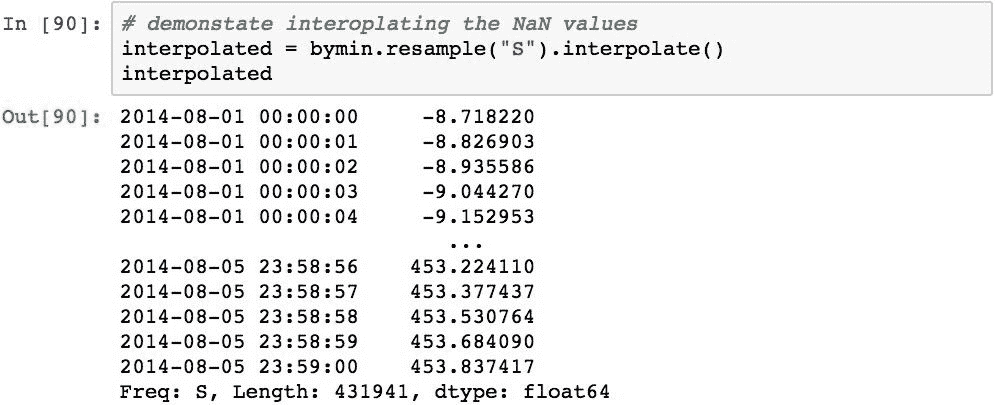
还可以使用.interpolate()方法对结果内插缺失值。 这将为重采样期间创建的所有NaN值计算结果中存在的值之间的线性插值:
Pandas 还使用.ohlc()方法提供了一种非常方便的重采样方法,称为开,高,低和关。 以下示例获取了我们的秒数据并计算了小时ohlc值:

时间序列的滚动窗口操作
Pandas 提供了许多函数来计算移动(也称为滚动)统计信息。 在滚动窗口中,pandas 在特定时间段表示的数据窗口上计算统计信息。 然后,该窗口将沿某个间隔滚动,只要该窗口适合时间序列的日期,就将在每个窗口上连续计算统计信息。
通过在序列和数据帧对象上提供.rolling()方法,pandas 为滚动窗口提供了直接支持。 然后,来自.rolling()的结果值可以具有许多调用的不同方法之一,这些方法可以在每个窗口上执行计算。 下表显示了许多这些方法:
| 函数 | 描述 |
|---|---|
.rolling().mean() |
窗口中的平均值 |
.rolling().std() |
窗口中值的标准差 |
.rolling().var() |
窗口中值的方差 |
.rolling().min() |
窗口中的最小值 |
.rolling().max() |
窗口中的最大值 |
.rolling().cov() |
窗口中值的协方差 |
.rolling().quantile() |
窗口中值的百分比/样本分位数 |
.rolling().corr() |
窗口中值的相关性 |
.rolling().median() |
窗口中值的中位数 |
.rolling().sum() |
窗口中值的总和 |
.rolling().apply() |
用户函数在窗口中的值的应用 |
.rolling().count() |
窗口中非NaN值的数量 |
.rolling().skew() |
窗口中值的偏度 |
.rolling().kurt() |
窗口中值的峰度 |
作为一个实际示例,滚动平均值通常用于消除短期波动并突出显示数据的长期趋势,并且在财务时间序列分析中非常常用。 为了演示,在本章前面创建的随机游走的第一分钟,我们将使用窗口 5 计算滚动平均值。

图表的生成将在第 14 章“可视化”中详细介绍
可以看出.rolling().mean()如何提供对基础数据的更平滑表示。 较大的窗口将产生较小的方差,较小的窗口将产生更多的方差(直到窗口大小为 1 为止,这将与原始序列相同)。
下面的示例展示了滚动平均值,其中窗口 2、5 和 10 与原始序列相对应:

请注意,窗口越大,曲线开始处缺失的数据越多。 大小为 n 的窗口在计算度量之前需要 n 个数据点,因此在图的开始处存在间隙。
可以使用.rolling().apply()方法通过滚动窗口来应用任何用户定义的函数。 提供的函数将在窗口中传递值数组,并且应返回一个值。 然后,Pandas 会将每个窗口的结果组合成一个时间序列。
为了说明这一点,以下代码计算了平均平均偏差,使您可以感觉到样本中所有值与总体平均值之间的距离:
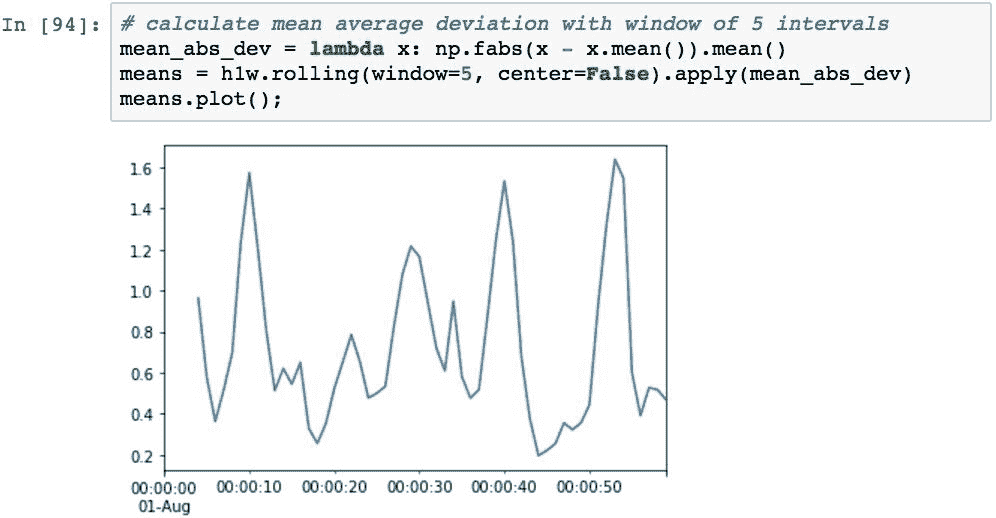
可以使用pd.rolling_mean函数的使用的微小变化来计算扩展的窗口平均值,该函数通过始终从时间序列中的第一个值开始重复计算平均值,并且每次迭代都将窗口大小增加一个。 与滚动窗口相比,扩展窗口平均值将更稳定(响应性更差),因为随着窗口大小的增加,下一个值的影响将减小:

总结
在本章中,我们研究了多种方法来表示在特定时间点发生的事件,以及如何对这些值随时间变化进行建模。 这涉及学习 Pandas 的许多功能,包括日期和时间对象,表示时间间隔和周期的时间变化,以及对时间序列数据执行多种类型的操作,例如频率转换,重采样和计算滚动窗口。
在本书的其余两章中,我们将抛弃 Pandas 的机制,而将更多的精力放在数据的可视化以及将 Pandas 应用于财务数据分析上。
十四、可视化
数据分析的最重要部分之一是创建出色的可视化效果,以立即传达数据中的潜在含义。 数据可视化是有效的,因为我们人类是视觉生物,并且已经发展成为能够识别信息布局的含义的方式,当视网膜的冲动击中大脑时,我们的大脑几乎可以立即解释。
多年来,已经进行了大量研究,结果产生了许多有效的可视化技术来传达数据中的特定模式。 这些模式已在可视化库中实现,Pandas 被设计为利用这些模式并使它们的使用非常简单。
本章将介绍其中的几种技术,主要侧重于 matplotlib 和许多常见的可视化。 我们将分三个步骤进行操作。 第一部分介绍了用 Pandas 编程可视化的一般概念,着重介绍了创建时序图的过程。 在此期间,我们将深入研究标记轴的技术以及创建图例,颜色,线条样式和标记的技术。
第二步将集中在 Pandas 和数据分析中常用的多种数据可视化类型,包括:
- 用条形图显示相对差异
- 用直方图描绘数据的分布
- 用箱形图和胡须图描述类别数据的分布
- 用面积图显示累计总数
- 散点图与两个变量之间的关系
- 用核密度图估计分布
- 散点图矩阵与多个变量之间的相关性
- 热图与多个变量之间的关系强度
最后一步将检查如何通过将绘图划分为多个子部分来创建合成绘图,以便能够在单个图形画布中渲染多个绘图。 这将帮助可视化的查看者一目了然地关联不同的数据集。
配置 Pandas
本章中的所有示例均基于以下导入和默认设置。 本章的一个小区别是在整个示例中共享的seedval变量的声明:

Pandas 绘图的基础知识
Pandas 库本身执行不执行数据可视化。 为了做到这一点,Pandas 与 Python 生态系统中的其他强大的可视化库紧密集成。 这些集成中最常见的是与matplotlib集成。 因此,本章将把示例重点放在matplotlib上,但我们还将为您指出其他可能的库,以供您自己尝试。 其中两个值得一提。
Seaborn 是另一个基于matplotlib的 Python 可视化库。 它提供了一个高级接口来呈现引人注目的统计图形。 它具有对 NumPy 和 pandas 数据结构的本地支持。 Seaborn 的目标是创建在本质上看起来不太科学的matplotlib图。 要了解有关 Seaborn 的信息,请访问站点。
尽管 Seaborn 和matplotlib在渲染数据方面都很出色,但它们都缺乏用户交互性。 尽管可以通过 Jupyter 之类的工具将两者的渲染显示在浏览器中,但是渲染本身并不使用 DOM 创建,也不使用浏览器的任何功能。
为了促进在浏览器中的呈现并提供丰富的交互性,已创建了几个库来将 Python 和 Pandas 与D3.js集成在一起。 D3.js是一个 JavaScript 库,用于处理文档并创建丰富的交互式数据可视化。 其中最流行的一种是 mpld3。 不幸的是,在编写本书时,它不适用于 Python 3.6,因此无法覆盖。 但是请仍然在 d3js.org 和 mpld3 上查看D3.js。
创建时间序列图
时间序列数据是最常见的数据可视化之一。 在 Pandas 中可视化时间序列就像在对时间序列建模的DataFrame或Series对象上调用.plot()一样简单。
下面的示例演示如何创建一个时间序列,该时间序列表示一段时间内价值的随机波动,类似于股票价格的波动:
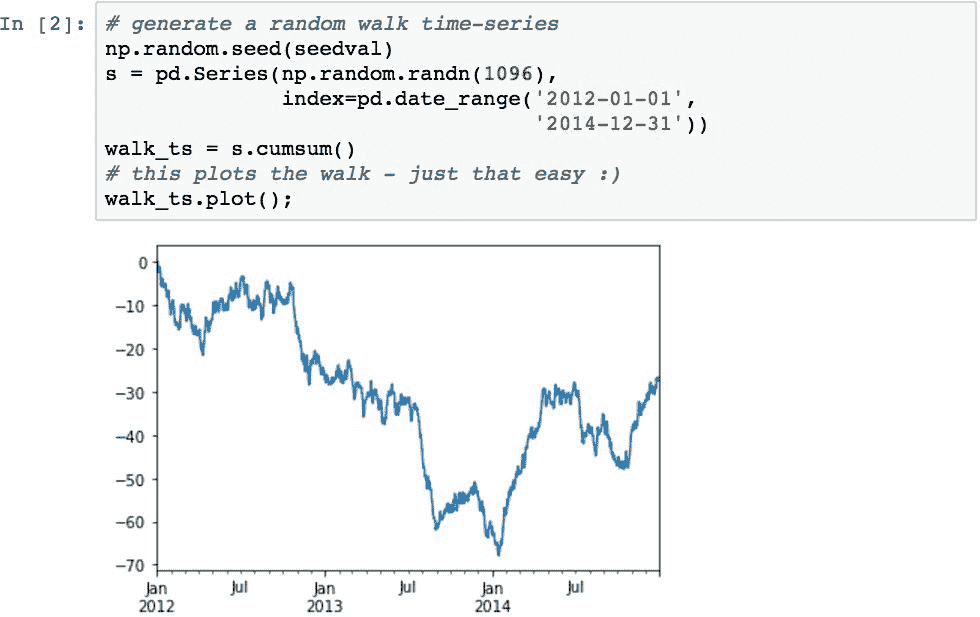
Pandas 对象的.plot()方法是matplotlib库的plot()函数的包装函数。 它使 Pandas 数据图非常易于创建,因为其实现被编码为知道如何基于基础数据呈现许多可视化。 它处理许多细节,例如选择序列,标记和轴生成。
在前面的示例中,.plot()确定Series包含其索引的日期,因此 x 轴应设置为日期格式。 它还为数据选择默认颜色。
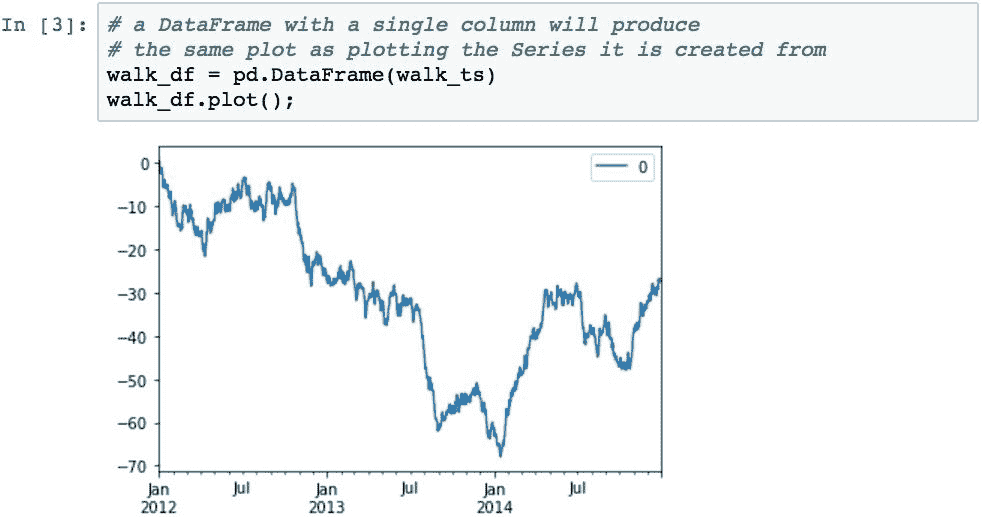
绘制一些数据所产生的结果与使用单列呈现DataFrame相似。 下面的代码通过产生相同的图但略有不同来说明这一点:它为图添加了图例。 从DataFrame生成的图表默认情况下将包含图例。
如果DataFrame包含多列,则.plot()将在图例中添加多个项目,并为每行选择不同的颜色:


如果要使用DataFrame中的数据列作为图的 x 轴上的标签(而不是索引标签),请使用x参数指定表示标签的列的名称。 然后,使用y参数指定将哪些列用作数据:

装饰和设计时间序列图
内置的.plot()方法具有许多选项,可用于更改图形中的内容。 让我们介绍许多绘图中使用的几种常用选项。
添加标题和更改轴标签
可以使用title参数设置图表标题。 调用.plot()之后,不使用.plot()设置轴标签,而是直接使用plt.ylabel()和plt.xlabel()函数设置:

指定图例的内容和位置
要更改图例中用于每个数据序列的文本(默认为DataFrame中的列名),请捕获从.plot()方法返回的ax对象,并使用其.legend()方法。 该对象是AxesSubplot对象,可用于在生成图形之前更改其各个方面:
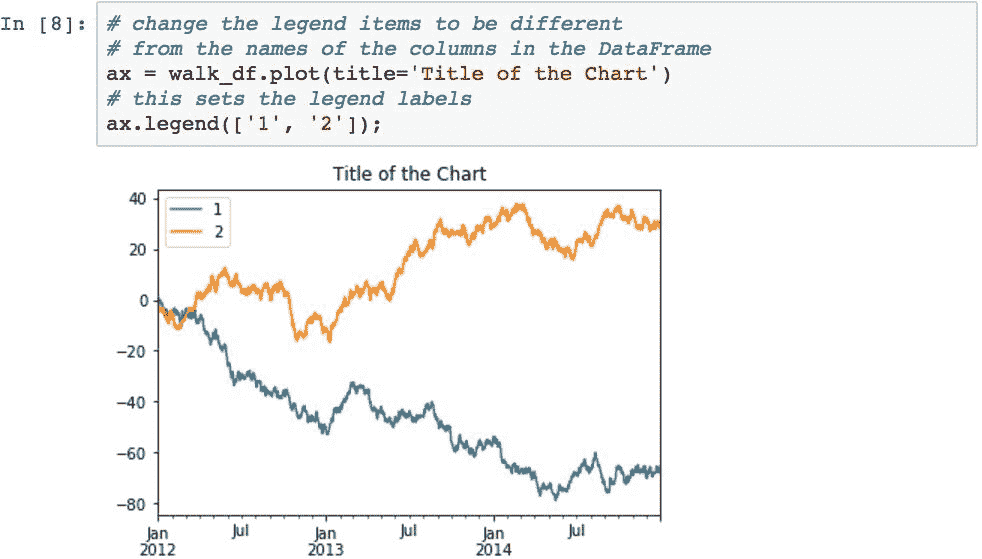
可以使用.legend()的loc参数设置图例的位置。 默认情况下,pandas 将该位置设置为'best',这告诉matplotlib检查数据并确定认为放置图例的最佳位置。 但是,您也可以指定以下任意一项来更具体地放置图例(可以使用字符串或数字代码):
| 字符串 | 代码 |
|---|---|
'best' |
0 |
'upper right' |
1 |
'upper left' |
2 |
'lower left' |
3 |
'lower right' |
4 |
'right' |
5 |
'center left' |
6 |
'center right' |
7 |
'lower center' |
8 |
'upper center' |
9 |
'center' |
10 |
下面的示例演示了将图例放置在图形的上部中央部分:

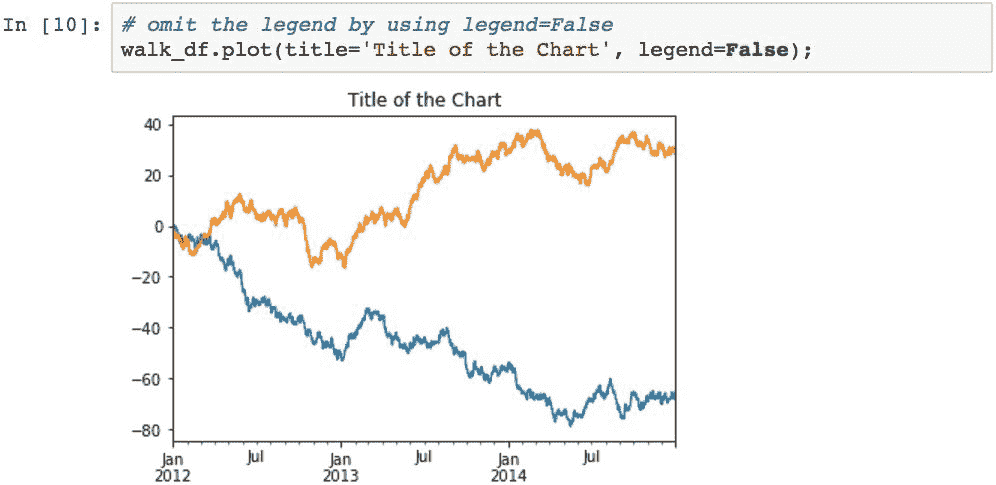
可以使用legend=False关闭图例:
指定线条颜色,样式,粗细和标记
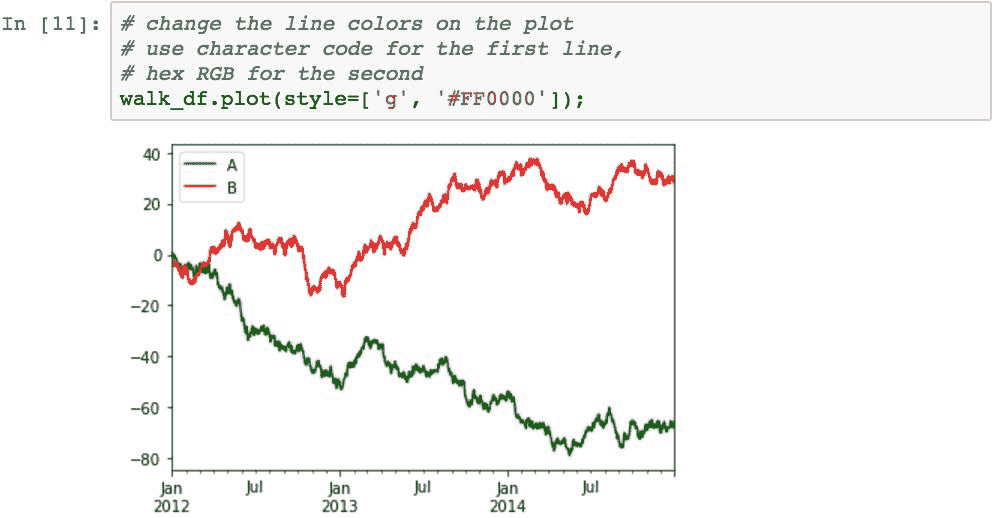
Pandas 会在任何图表上自动设置每个序列的颜色。 要指定自己的颜色,请向绘图函数的style参数提供样式代码。 pandas 具有许多内置的颜色单字符代码,此处列出了其中的一些:
b:蓝色g:绿色r:红色c:青色m:洋红色y:黄色k:黑色w:白色
也可以使用#RRGGBB格式的十六进制 RGB 代码指定颜色。 下面的示例通过使用一位数字代码将第一个序列的颜色设置为绿色,以及使用 RGB 十六进制代码将第二个序列的颜色设置为红色来演示这两个示例:
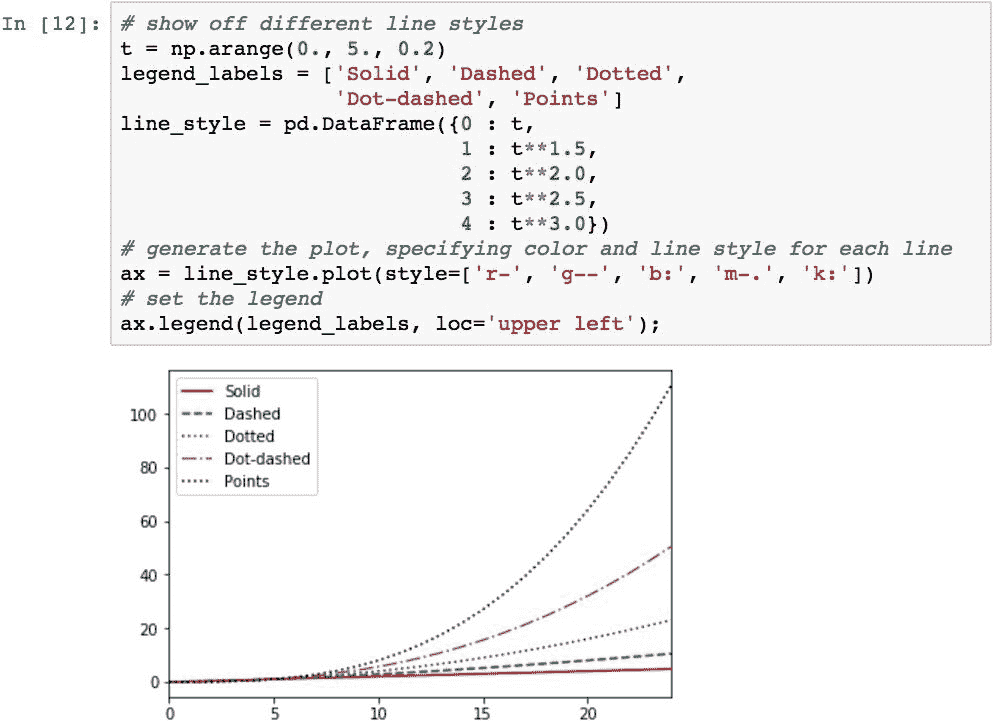
可以使用线型代码指定线型。 通过紧跟在颜色代码之后,可以将它们与颜色样式代码结合使用。 以下是一些有用的线型代码的示例:
'-':实线'-':虚线':':点线'-':点划线'.':点
下图通过绘制五个数据序列来演示这五种线型,每个数据序列都具有以下一种线型:
可以使用lw参数.指定线的粗细。可以通过传递宽度列表或应用于所有线的单个宽度来传递多条线的厚度。 下面的代码以 3 的线宽重绘该图形,使这些线更明显:

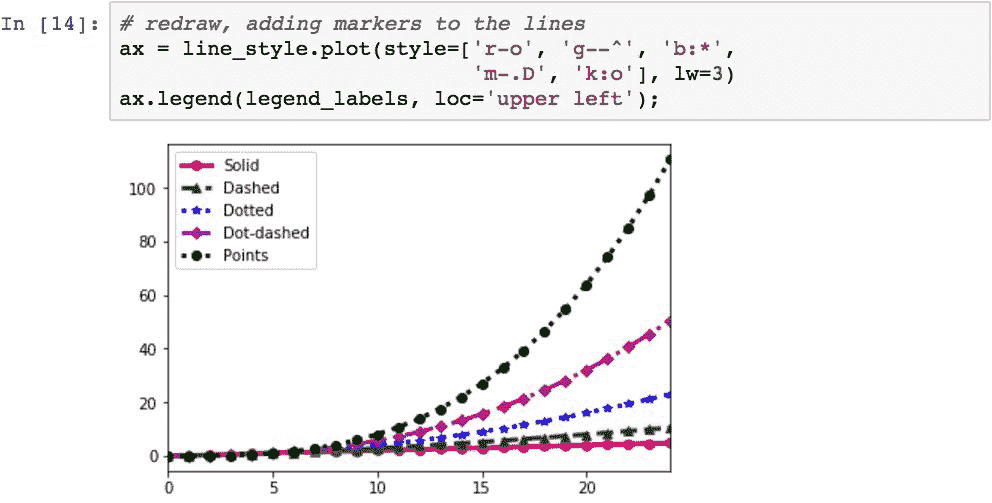
可以通过使用样式代码中的缩写来指定行上的标记。 提供了很多标记类型,您可以在这里中查看所有标记类型。 在下一个图表中,我们将通过使每个序列使用与以下不同的标记来检查其中的五个:圆形,星形,三角形,菱形和点:
指定刻度线位置和刻度线标签
刻度线的位置和渲染可以使用各种函数进行自定义。 以下代码引导您完成几个控制其值和渲染的示例。
Pandas 决定在标签位置使用的值可以使用plt.xticks()函数找到。 此函数返回两个值:每个刻度的值和代表实际标签的对象:
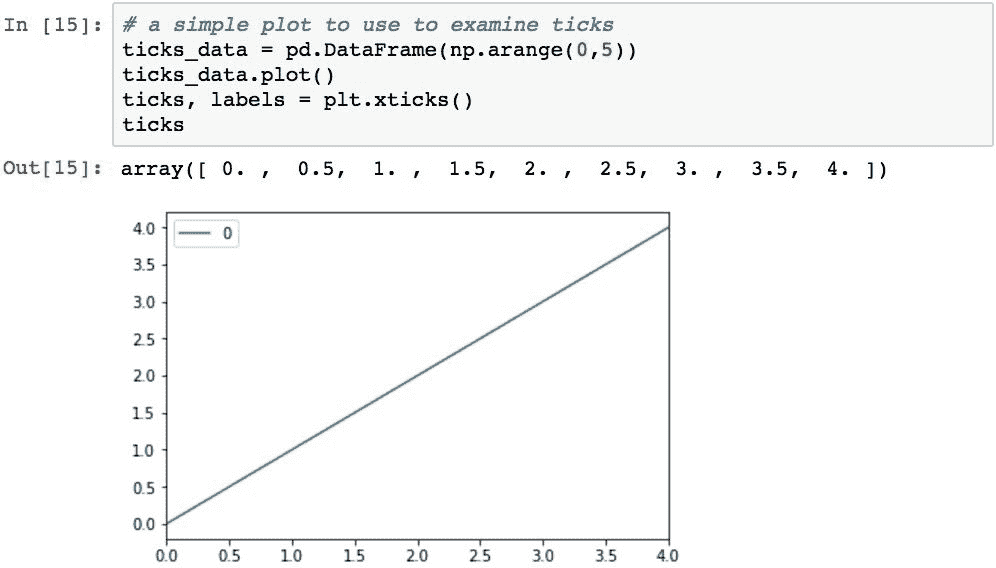
此报价数组包含沿 x 轴以实际数据为单位的报价位置。 在这种情况下,Pandas 认为 0 到 4(最小和最大)的范围和 0.5 的间隔是合适的。
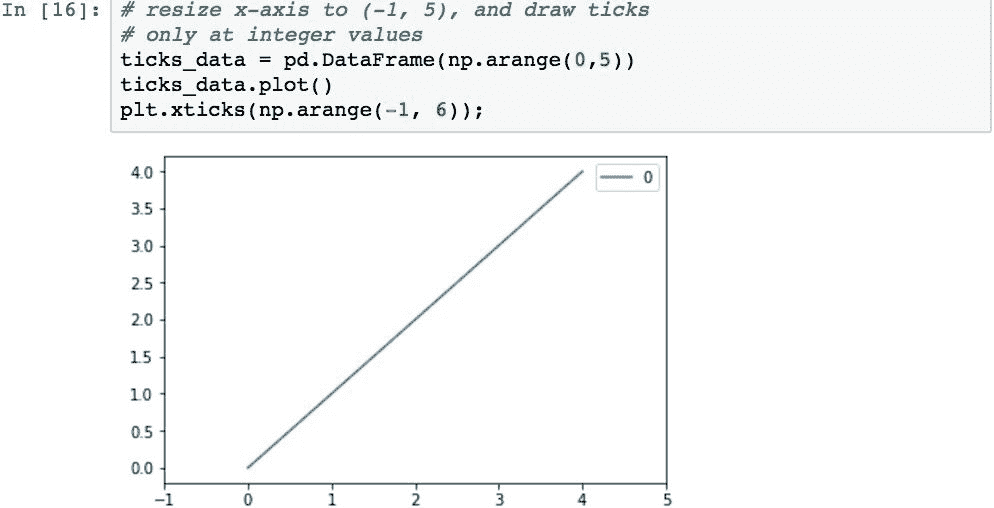
如果要使用其他位置,请通过将列表传递到plt.xticks()来提供它们。 以下代码使用从-1到5的偶数整数对此进行了演示。 这组值将更改轴的范围并删除非整数标签:
可以通过将每个刻度位置的标签作为第二个参数来指定它们。 在以下示例中,通过将 y 轴刻度和标签更改为整数值和连续的字母字符,可以显示出这一点:

使用格式化器格式化轴的刻度日期标签
使用定位器和格式化器完成其基础数据类型为datetime的轴标签的格式化。 定位器控制刻度线的位置,格式器控制标签的格式。
matplotlib在maptplotlib.dates中提供了几个类来帮助简化该过程:
MinuteLocator,HourLocator,DayLocator,WeekdayLocator,MonthLocator和YearLocator- 这些是专用的编码器,用于确定每种类型的日期字段的刻度将在轴上的哪里找到
DateFormatter- 此类可用于将日期对象格式化为轴上的标签
默认的定位器和格式化器为AutoDateLocator和AutoDateFormatter。 这些可以通过提供不同的对象实现来更改。
为了演示,让我们从前面的示例中的以下随机游走数据子集开始; 它仅代表 2014 年 1 月至 2014 年 2 月的数据。绘制此图可得到以下输出:

该图的 x 轴上的标签有两个序列,次要和主要。 此图中的次要标签包含当月的日期,而主要标签则包含年和月(仅第一个月的年份)。 我们可以为每个次要和主要级别设置定位器和格式化器,以更改值。
这将通过将次要标签更改为从每周的星期一开始并包含日期和星期几来演示(现在,图表使用每周,并且仅使用星期五的日期,没有日期名称)。 主要标签将使用每月位置,并且始终包含月份名称和年份:

这几乎是我们想要的。 但是,请注意,该年份报告为0045。 要使用基于自定义日期的标签创建图,需要避开 Pandas .plot()并直接使用matplotlib。 幸运的是,这并不难。 此代码片段会略微更改代码,并以所需的格式呈现我们需要的内容:

我们可以使用 x 轴对象的.grid()方法为短轴和长轴刻度线添加网格线。 第一个参数是True(用于渲染线)或False(用于隐藏线)。 第二个指定滴答集。 以下代码在不绘制主线的情况下重新绘制此图形,同时渲染了次线:
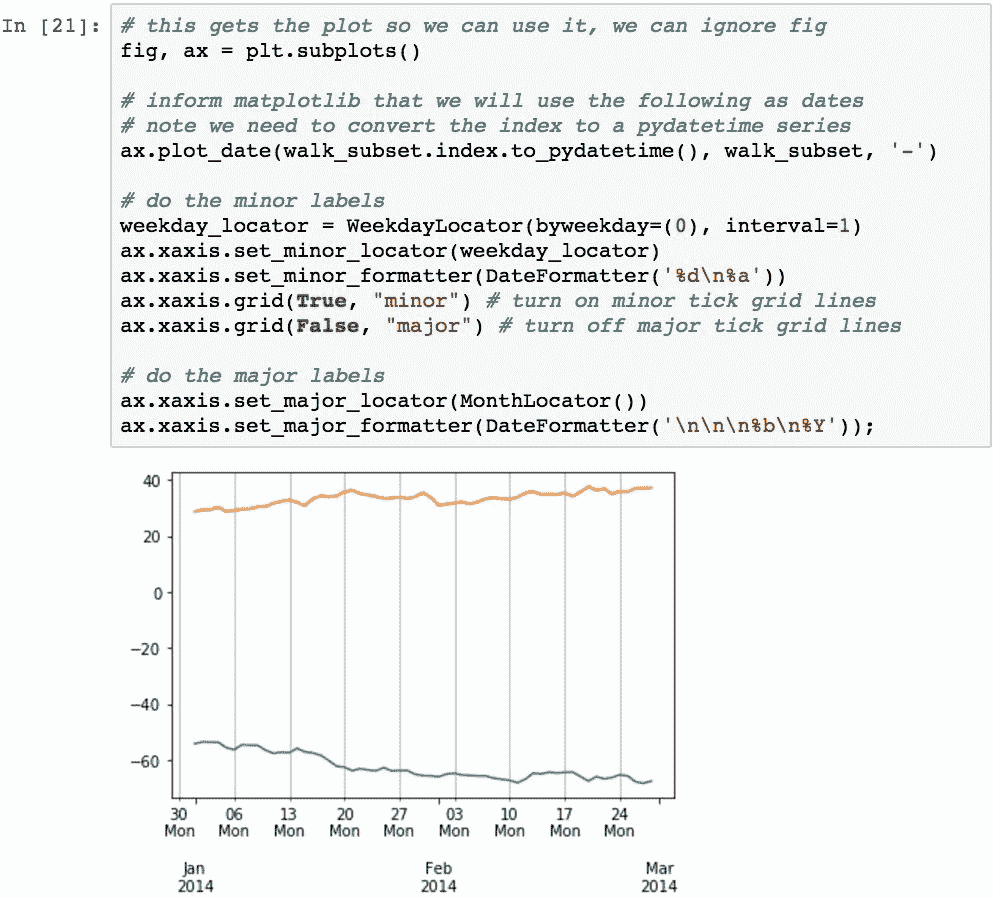
格式化的最终演示将仅使用主要标签,但每周使用YYYY-MM-DD格式。 但是,由于这些会重叠,因此我们将指定它们应该旋转以防止重叠。 此旋转通过fig.autofmt_xdate()函数指定:

统计分析中常用的图
在学习了如何创建,布置和标注时间序列图之后,我们现在将着眼于创建对表示统计信息有用的变量。
用条形图显示相对差异
条形图可用于可视化非时间序列数据值的相对差异。 可以使用.plot()的kind='bar'参数创建条形图:
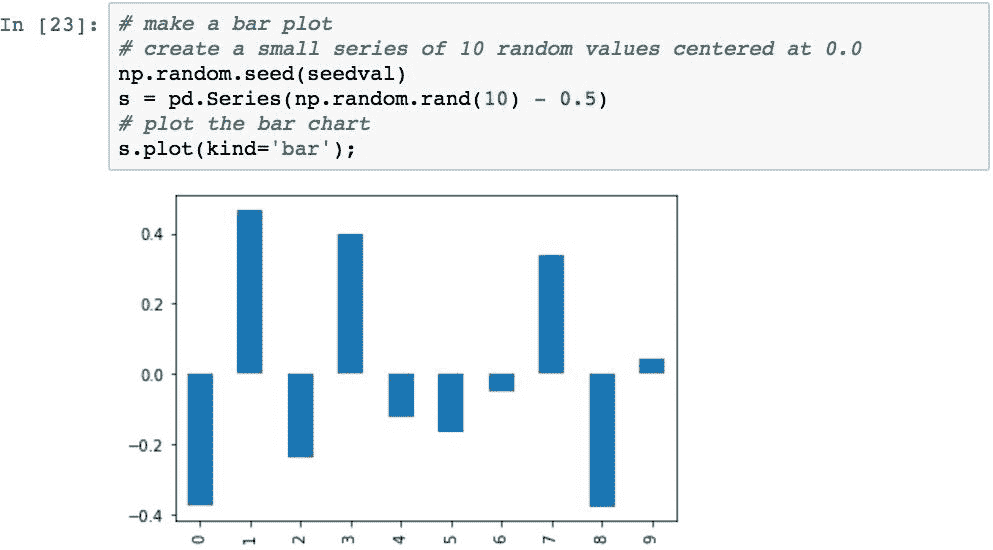
将创建一个多序列条形图,以比较每个 x 轴标签上的多个值:
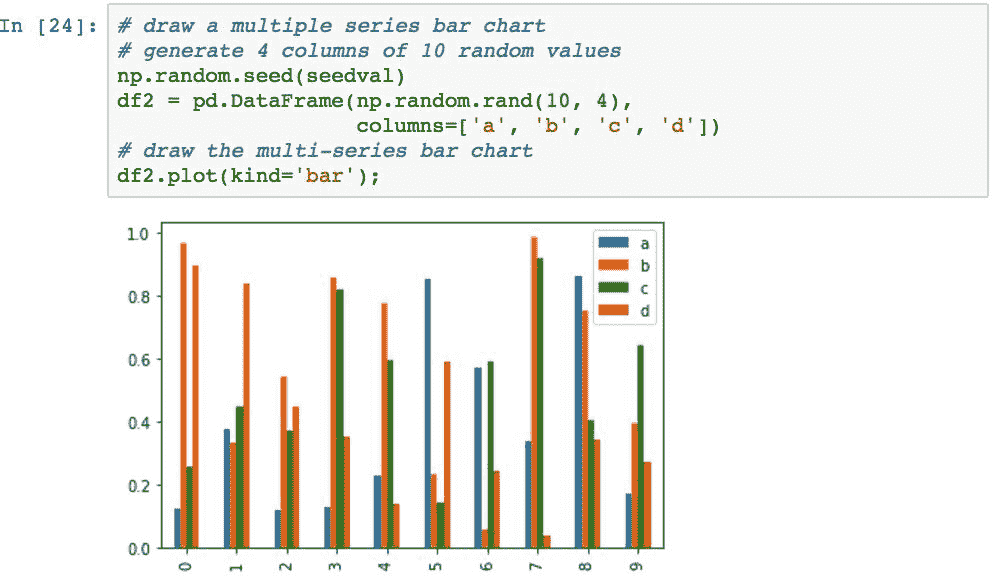
stacked=True参数可用于堆叠条形,而不必并排:

可以使用kind='barh'将方向变为水平:

用直方图描绘数据的分布
直方图对于可视化数据分布很有用。 以下代码基于正态分布中的1000随机值生成直方图:

直方图的分辨率可以通过指定要分配给图的仓数来控制。 默认值为 10,增加箱的数量可为直方图提供更详细的信息。 此代码将容器数增加到100:
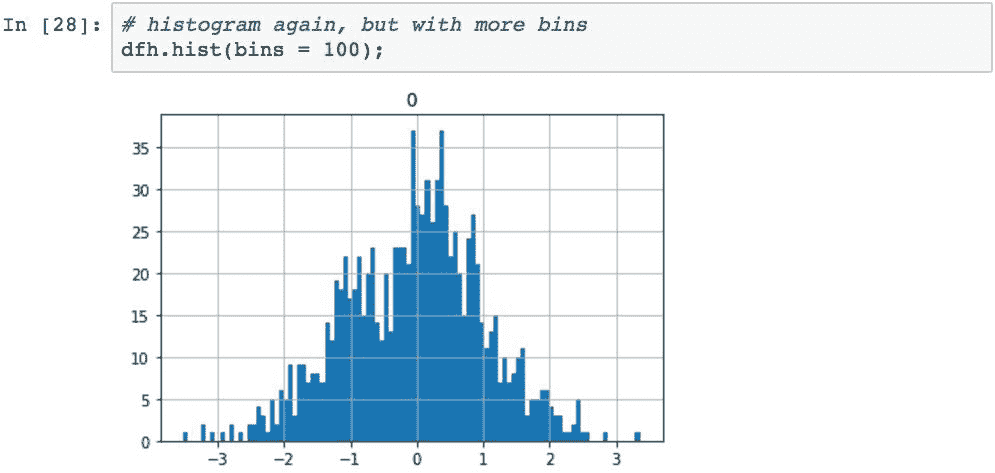
如果数据有多个序列,则直方图函数将自动生成多个直方图,每个序列一个:

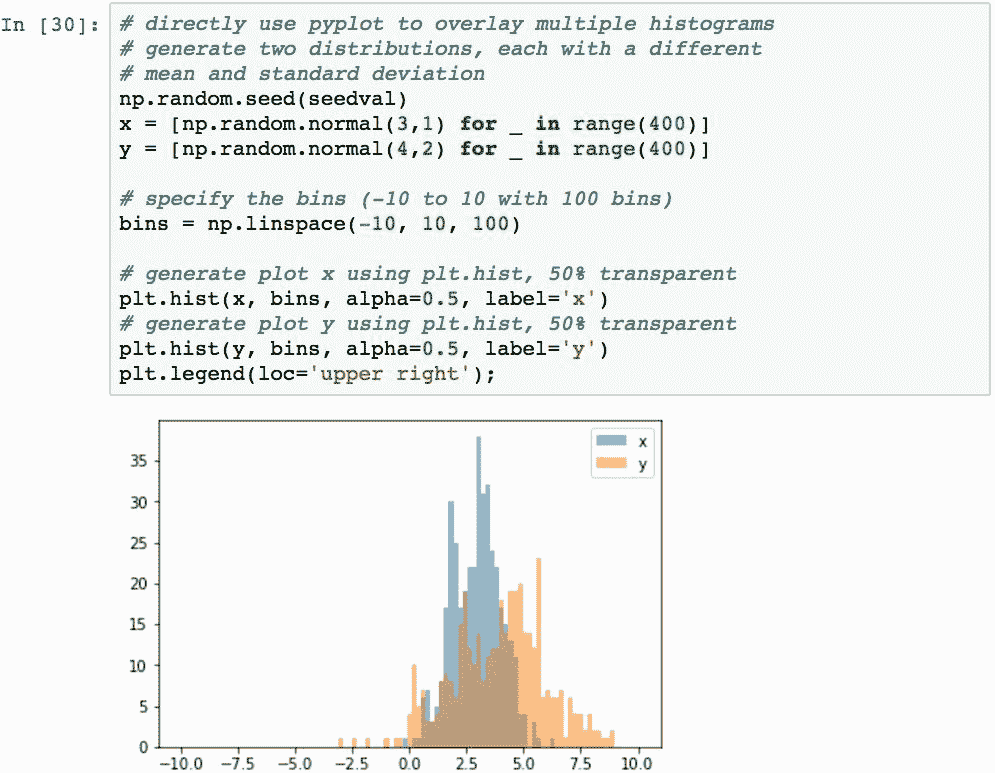
要将多个直方图叠加在同一张图上(以便快速看到分布的差异),请在.show()之前多次调用pyplot.hist()函数:
用箱形图和胡须图描述类别数据的分布
箱形图来自描述性统计数据,是使用四分位数描述类别数据分布的有用方式。 每个框代表数据的第一和第三四分位数之间的值,并且在中位数处跨框有一条线。 每个胡须伸出手来展示在第一和第三四分位数上下的五个四分位数范围的程度:

用面积图显示累计总数
面积图用于表示一段时间内的累计总数,并演示相关属性之间的时间趋势变化。 也可以将它们“堆叠”以显示所有变量的代表性总计。
通过指定kind='area'生成面积图。 堆积面积图是默认设置:

使用stacked=False会生成未堆积的面积图:
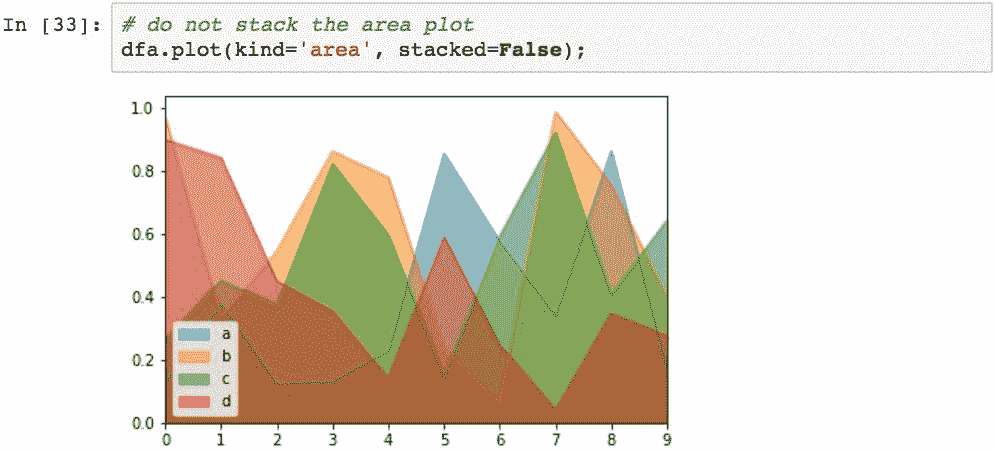
默认情况下,未堆叠的图的 alpha 值为 0.5,因此可以查看多个数据序列如何重叠。
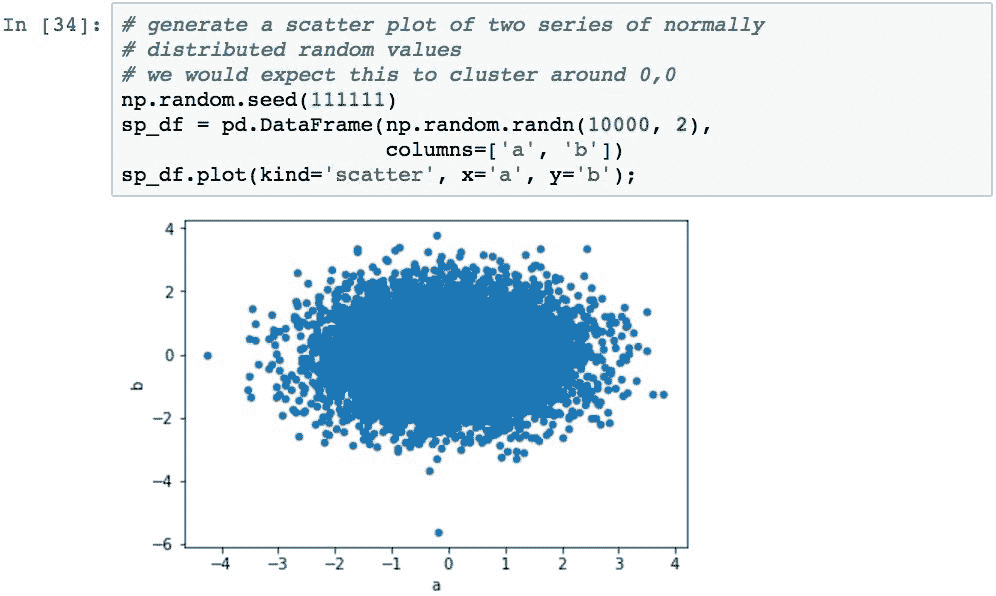
散点图与两个变量之间的关系
散点图显示一对变量之间的相关性。 通过使用.plot()并指定kind='scatter'以及DataFrame源中的 x 和 y 列,可以从DataFrame创建散点图:
可以通过拖放到matplotlib中来创建更精细的散点图。 以下代码演示了 2016 年 Google 股票数据的使用,计算每日收盘价中的增量,然后将收盘量与交易量渲染为从交易量得出的大小不同的气泡:
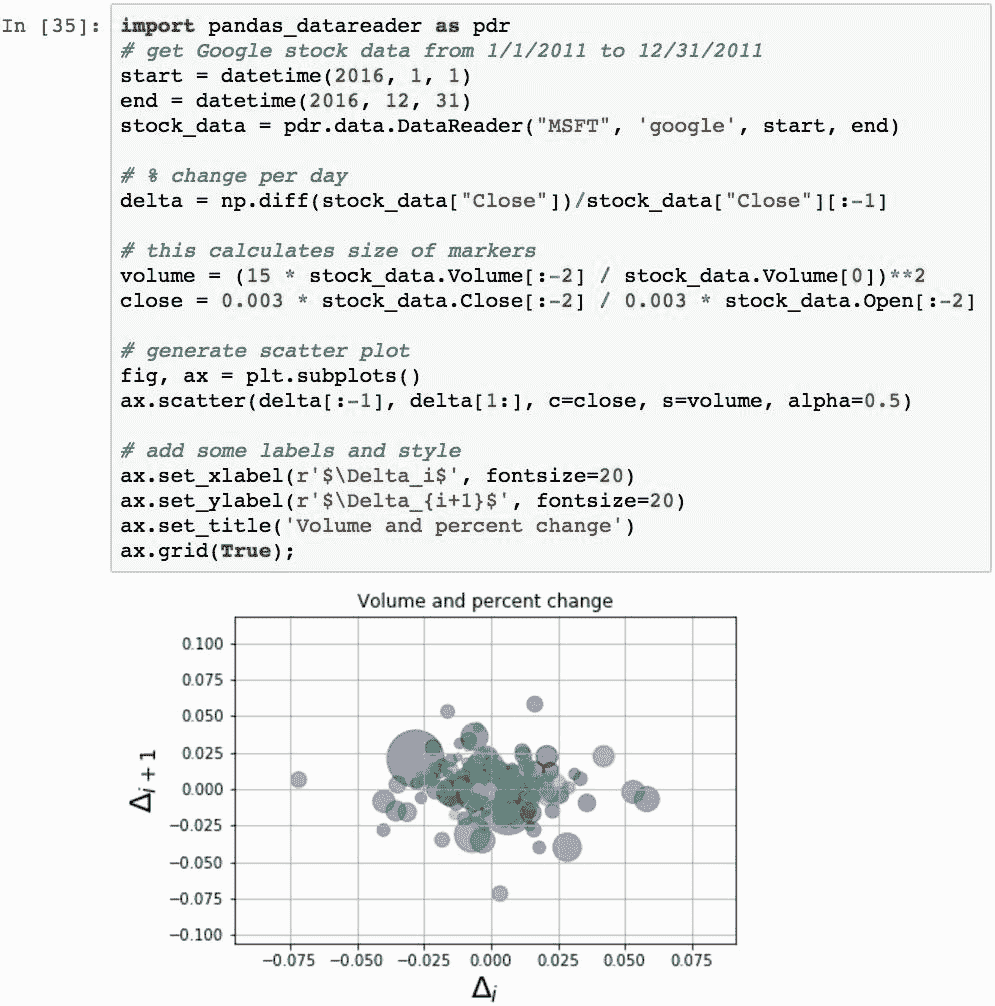
请注意 x 和 y 轴标签的命名法,这得益于 matplotlib 的内部 LaTeX 解析器和布局引擎,为标签创建了不错的数学风格。
用核密度图估计分布
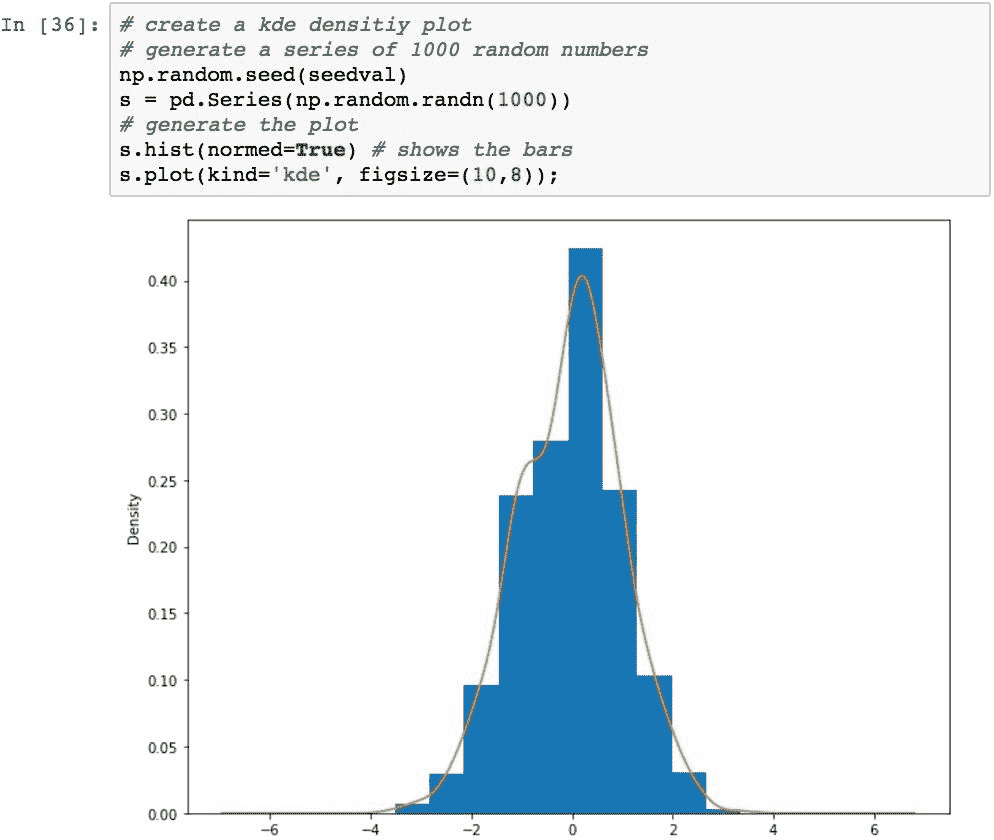
核密度估计图,而不是通过估计数据的真实分布来将数据平滑化为连续图,而不是数据的纯粹经验表示。 可以使用.plot()方法并设置kind='kde'来创建内核密度估计图。 以下代码生成一组正态分布的数字,将其显示为直方图,并覆盖kde图:
散点图矩阵与多个变量之间的相关性
散点图矩阵是确定多个变量之间是否存在线性相关性的一种流行方法。 此代码创建具有随机值的散点图矩阵,并为每个变量组合以及每个对角线每个变量的 kde 图绘制散点图:
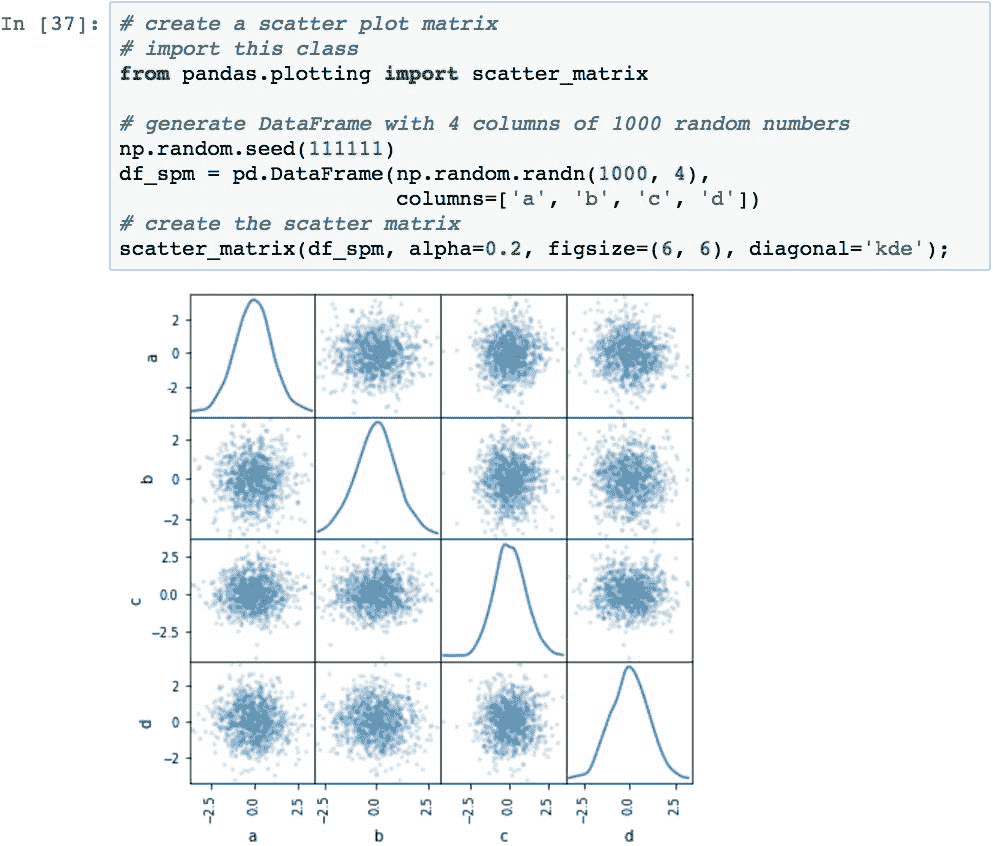
当将其应用于金融时,当计算各种股票的相关性时,我们将再次看到该图。
热图与多个变量之间的关系强度
热图是数据的图形表示,其中矩阵内的值由颜色表示。 这是显示在两个变量的交点处测得的值之间关系的有效方法。
常见的情况是将矩阵中的值归一化为 0.0 到 1.0,并使行和列之间的交点表示两个变量之间的相关性。 相关性较小(0.0)的值为最暗,相关性最高(1.0)的值为白色。
使用.imshow()函数,可以通过 Pandas 和matplotlib轻松创建热图:


下一章还将重新讨论热图,以证明相关性。
在单个图表中手动绘制多个图
通过将多个图彼此相邻显示来对比数据通常很有用。 我们已经看到,pandas 对几种类型的图自动执行此操作。 也可以在同一画布上手动渲染多个图。
要使用matplotlib在画布上渲染多个子图,请多次调用plt.subplot2grid()。 每次经过网格的大小时,子图都将位于(shape=(height, width)上,子图的左上角位置(loc=(row, column))将位于网格上。 尺寸以总列数为单位,而不是以像素为单位。
每次调用plt.subplot2grid()的返回值都是一个不同的AxesSubplot对象,可用于指定子图渲染的位置。
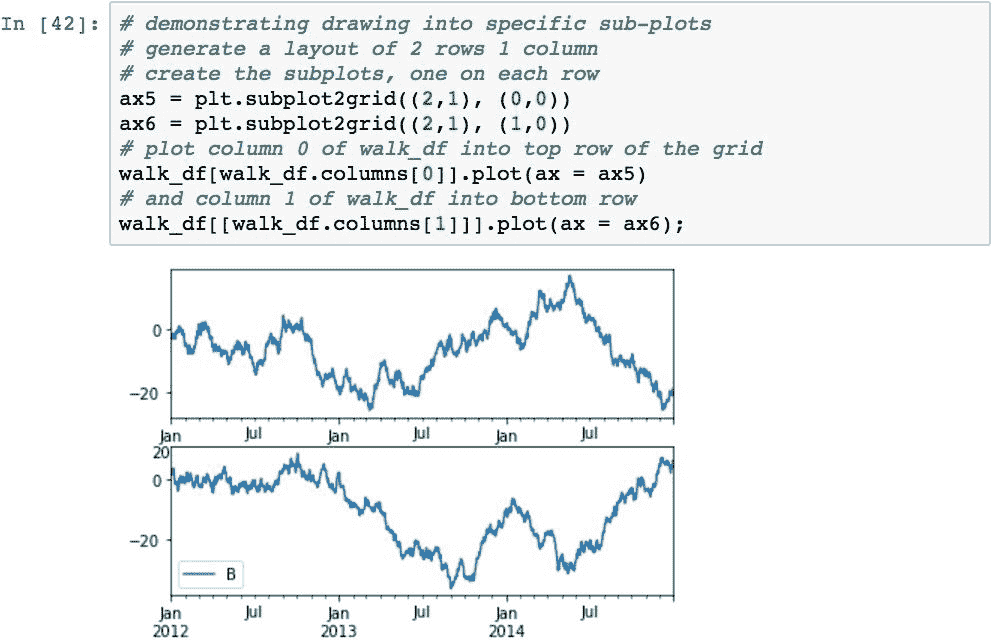
以下代码通过基于两行一列(shape=(2,1))创建一个绘图来演示这一点。 由ax1引用的第一个子图位于第一行(loc=(0,0)),由ax2引用的第二个子图位于第二行(loc=(1,0)):

子图已创建,但我们都尚未参与。
可以在每次调用plt.subplot2grid()的过程中使用rowspan和colspan参数指定任何子图的大小。 这种指定跨度的方式与 HTML 表格中的 Speng 跨度非常相似。 这段代码演示了如何使用跨度为每个图指定不同的行,列和跨度来创建五个图的更复杂的布局:

要渲染为特定的子图,请使用ax参数将目标轴对象传递到.plot()。 下面的代码通过从本章开头创建的随机游走中提取每个序列,然后在不同的子图中渲染每个序列,来演示这一点:
使用这种技术,我们可以执行不同序列数据的组合,例如股票收盘价与交易量图。 给定我们在上一个 Google 示例中读取的数据,此代码将绘制成交量与收盘价的关系:

总结
在本章中,我们研究了许多最常见的可视化 Pandas 数据的方法。 数据的可视化是快速了解数据中正在讲述的故事的最佳方法之一。 Python,pandas 和matplotlib(甚至其他一些库)提供了一种非常快速的方法,只需几行代码即可获取基础消息并以精美的方式显示它。
在本书的下一章和最后一章中,我们将研究 Pandas 在金融中的应用,尤其是股票价格分析。
十五、历史股价分析
在最后一章中,我们将使用 Pandas 对从 Google 财经获取的股票数据进行各种财务分析。 这还将涵盖财务分析中的多个主题。 重点将放在使用 Pandas 得出实用的时序股票数据上,而不是在金融理论的细节上。 但是,我们将涵盖许多有用的主题,并学习将 Pandas 应用于此领域和其他领域有多么容易。
具体而言,在本章中,我们将完成以下任务:
- 从 Google 财经中获取和整理股票数据
- 绘制时间序列价格
- 绘制交易量序列数据
- 计算简单的每日百分比变化
- 计算简单的每日累计收益
- 将从数据每日重新采样为每月的收益
- 分析收益分布
- 执行滚动平均计算
- 比较股票的每日平均收益
- 根据收盘价的每日百分比变化的股票相关性
- 计算股票波动率
- 可视化相对于预期收益的风险
配置 IPython 笔记本
本章中的所有示例均基于以下导入和默认设置:

从 Google 获取和整理股票数据
我们的首要任务是编写几个函数,以帮助我们从 Google 财经中检索股票数据。 我们已经看到可以使用 pandas DataReader对象读取此数据,但是我们将需要与 Google 财经提供的数据组织方式稍有不同,因为我们稍后将对这些信息进行各种处理 。
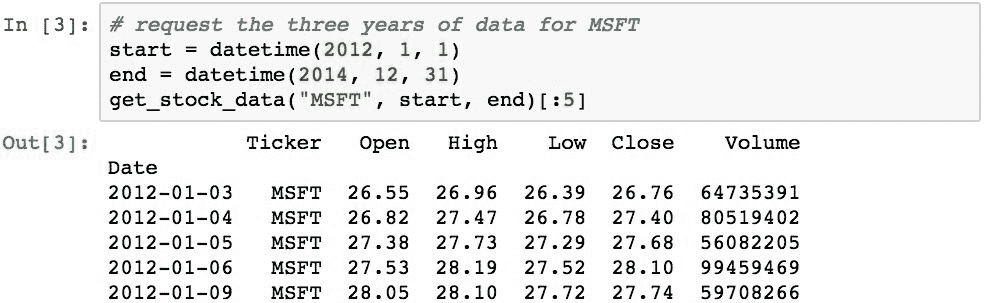
以下函数将获取两个指定日期之间特定股票的所有 Google 财经数据,并将该股票的代码添加到列中(稍后需要进行数据透视)。

数据将包含一个固定的 3 年窗口,范围从 2012 年到 2014 年。以下内容是MSFT代码的 3 年期数据:
既然我们有了一个可以获取单个报价器数据的函数,那么拥有一个可以读取多个报价器的数据并将它们全部返回到单个数据结构中的函数将很方便。 以下代码执行此任务:

本章中的示例将使用苹果(AAPL), 微软(MSFT),通用电气(GE), IBM(IBM),美国航空(AA), 达美航空(DAL),美联航航空公司(UAL),百事可乐(PEP), 和可口可乐(KO)。
选择这些股票是为了在三个不同部门(技术,航空和软饮料)中的每个样本中都有多个股票的样本。 这样做的目的是演示如何在相似行业的选定股票之间的选定时间段内,得出各种股票价格测量值之间的相关性,并演示不同行业之间的股票差异。
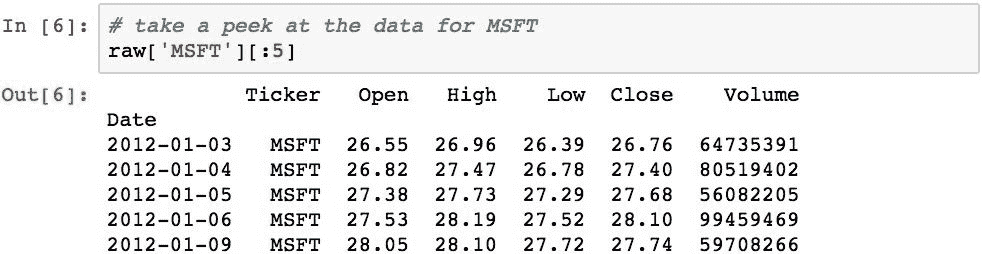
我们可以阅读以下内容:

注意:在测试期间,已经确定根据您的位置,这可能会由于 URL 可访问性而导致一些错误。
我们将对Close列中的收盘价特别感兴趣。 但是,如果我们有一个DataFrame对象按日期索引,并且其中每一列都是特定股票的价格,而行是该股票在该日期的收盘价,那么对我们来说更方便。 可以通过旋转数据来完成此操作,这是在读取数据时添加“股票行情指示器”列的原因。 以下函数将为我们做到这一点:

以下使用该函数将数据转移到新组织:
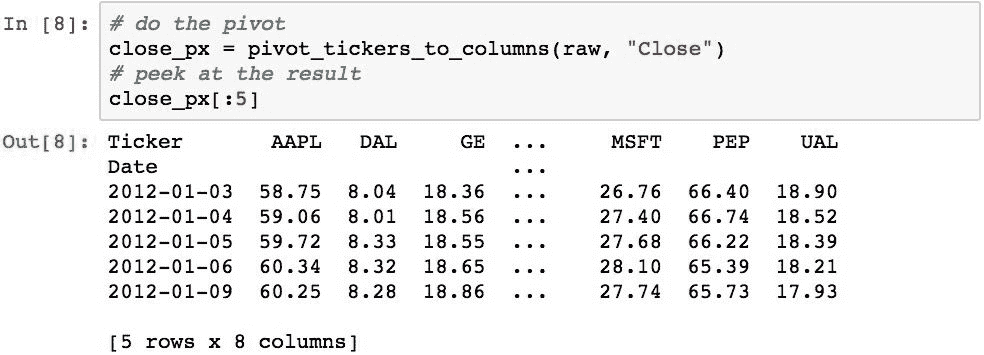
现在,所有股票的收盘价都是每一列中一列的值。 通过这种格式,可以轻松比较每只股票的收盘价和其他股票的收盘价。
绘制价格时间序列
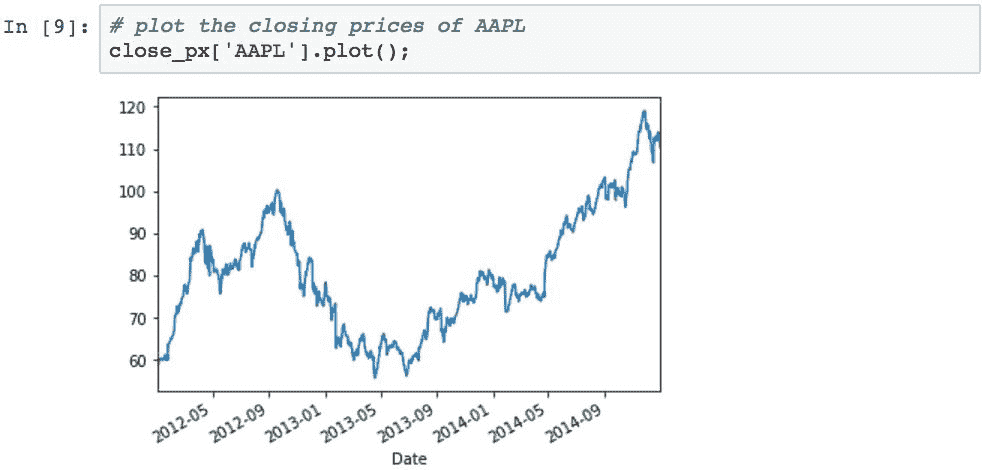
现在,让我们对AAPL和MSFT的收盘价进行图形比较。 下图显示了AAPL的调整后收盘价:
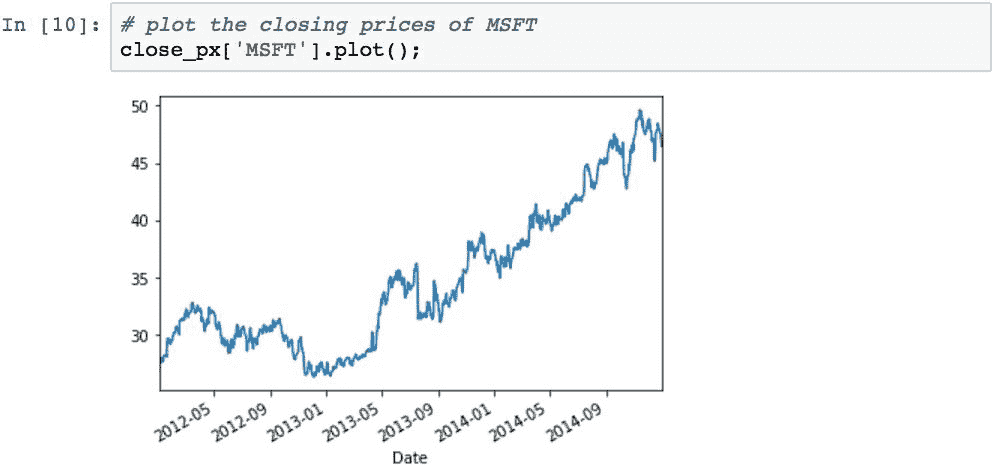
下面显示了MSFT:
两组收盘价都可以轻松地显示在单个图表上,以进行并排比较(或彼此比较):

绘制交易量序列数据
可以使用条形图绘制交易量数据。 我们首先需要获取交易量数据,这可以使用之前创建的pivot_tickers_to_columns()函数来完成:
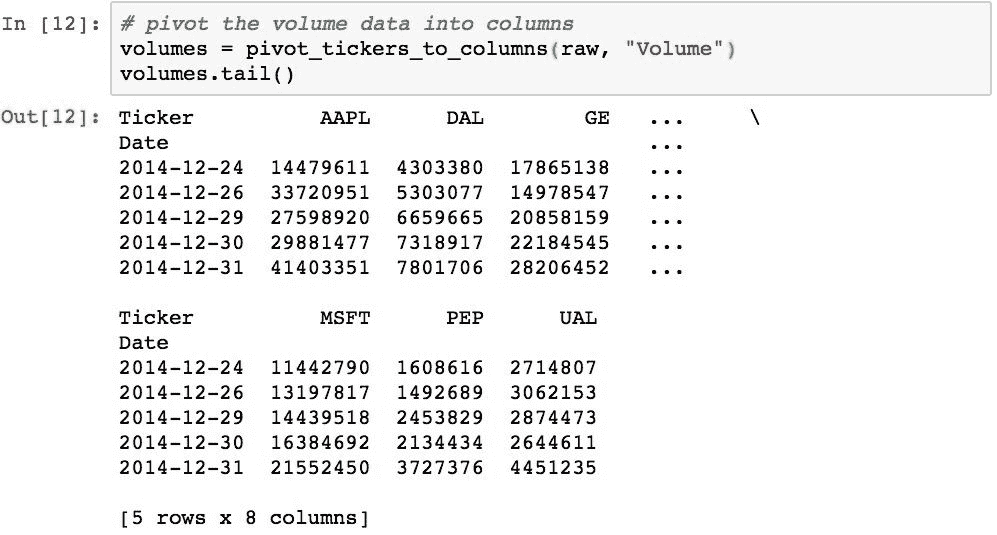
现在,我们可以使用此数据绘制条形图。 下图显示了MSFT的交易量:
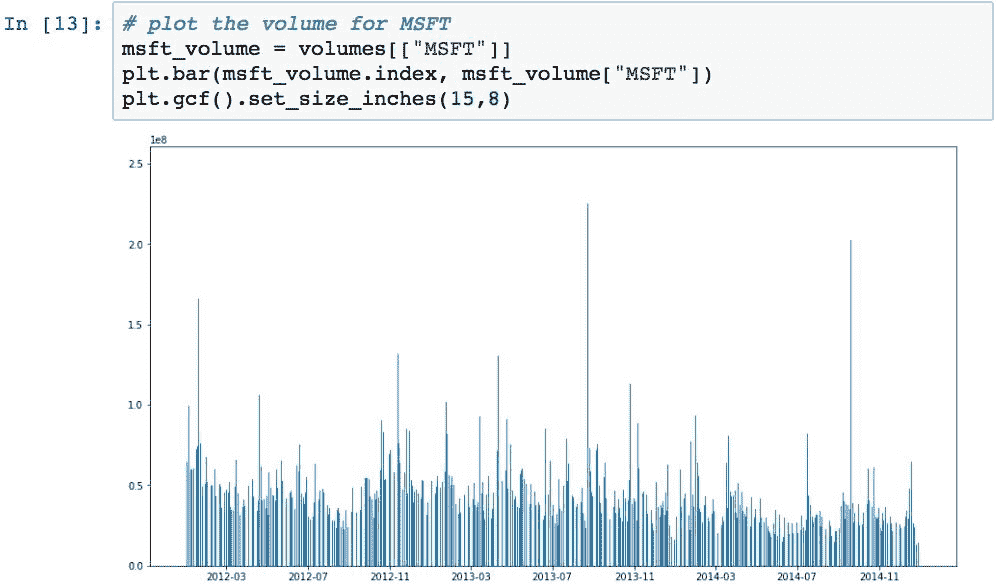
普通类型的财务图会绘制相对于其收盘价的股票量。 以下示例创建了这种类型的可视化:

计算收盘价的简单每日百分比变化
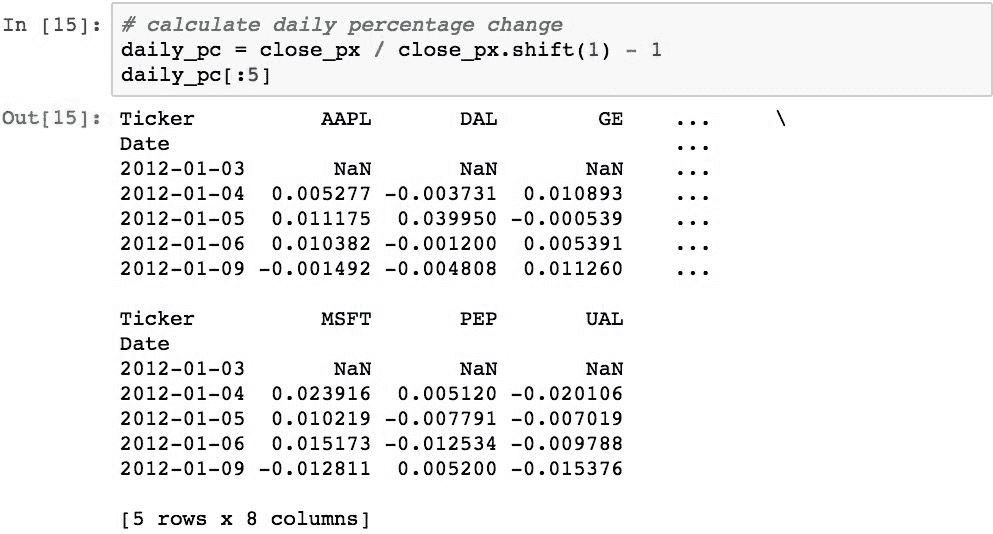
收盘价的每日简单百分比变化(不包括股息和其他因素)是指股票在一天的交易中价值的百分比变化。 它由以下公式定义:
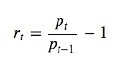
可以使用.shift()在 Pandas 中轻松计算出:
快速检查确认AAPL在2011-09-08上的收益是正确的:


如上图所示,每日百分比变化图通常看起来像噪声。 但是,当我们使用这些值的累积乘积(称为每日累积收益)时,便可以查看股票值随时间的变化。 那是我们的下一个任务。
计算股票的简单每日累计收益
简单的累积每日收益是通过计算每日百分比变化的累积乘积来计算的。 此计算由以下公式表示:
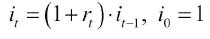
使用.cumprod()方法简洁地计算出:
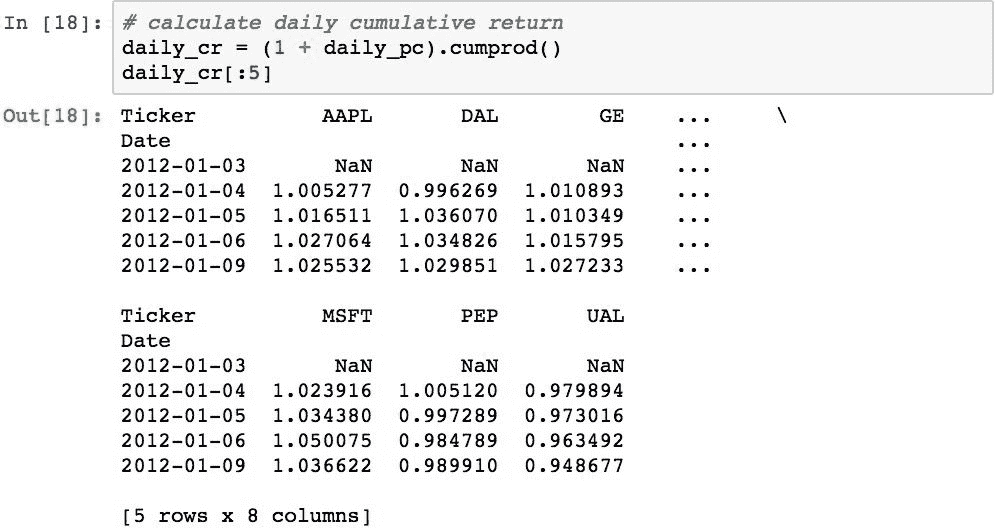
现在可以绘制累积收益,以查看各种股票的价值随时间变化的情况:

将数据从每日重新采样为每月的收益
要计算每月的回报率,我们可以使用一些 Pandas 魔术,然后对原始的每日回报进行重新采样。 在此过程中,我们还需要舍弃不属于月底的日期,并预先填写所有缺少的值。 可以使用.ffill()完成重采样的结果:
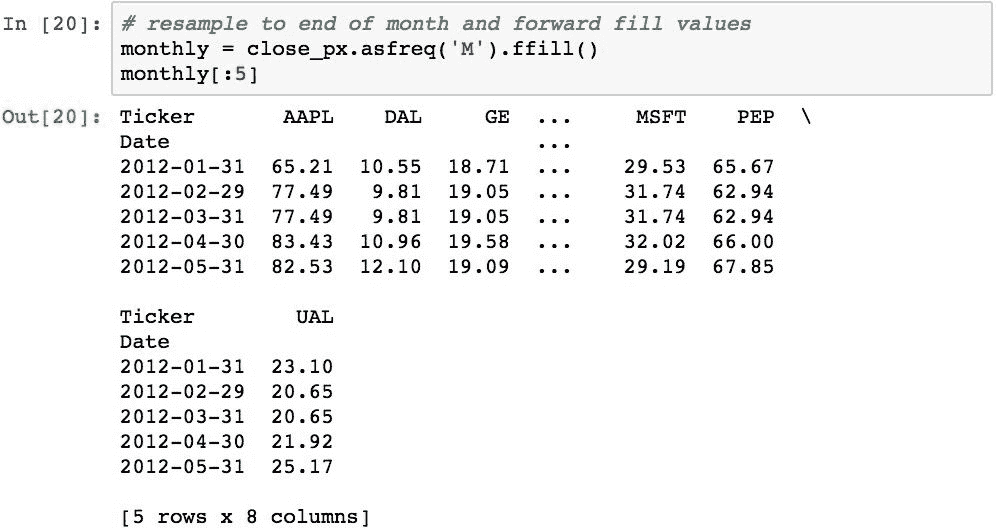
请注意条目的日期,并且它们现在都是月末日期。 值未更改,因为重新采样仅选择了月底的日期,或者如果源中不存在该日期之前的值,则使用该日期之前的值进行填充。
现在我们可以使用它来计算每月百分比变化:

现在,可以计算每月累积回报:

月度收益具有以下可视化效果:

这看起来像每日收益,但总的来说,它并不那么顺利。 这是因为它使用了大约 30% 的数据,并且绑定到月底。
分析收益分布
通过将数据绘制在直方图中,可以感觉到特定股票每日百分比变化的分布差异。 生成数据(例如每日收益)的直方图的一个技巧是选择要聚合值的箱数。 该示例将使用 50 个桶,这使您可以很好地感觉到三年数据中每日变化的分布。
以下显示了AAPL的每日百分比变化的分布:

该可视化告诉我们几件事。 首先,大多数日常运动以 0.0 为中心。 其次,左侧有少量偏斜,但是数据显得相对对称。
我们可以在一个直方图矩阵图中绘制所有股票每日百分比变化的直方图。 这为我们提供了一种快速确定这三年内股票行为差异的方法:
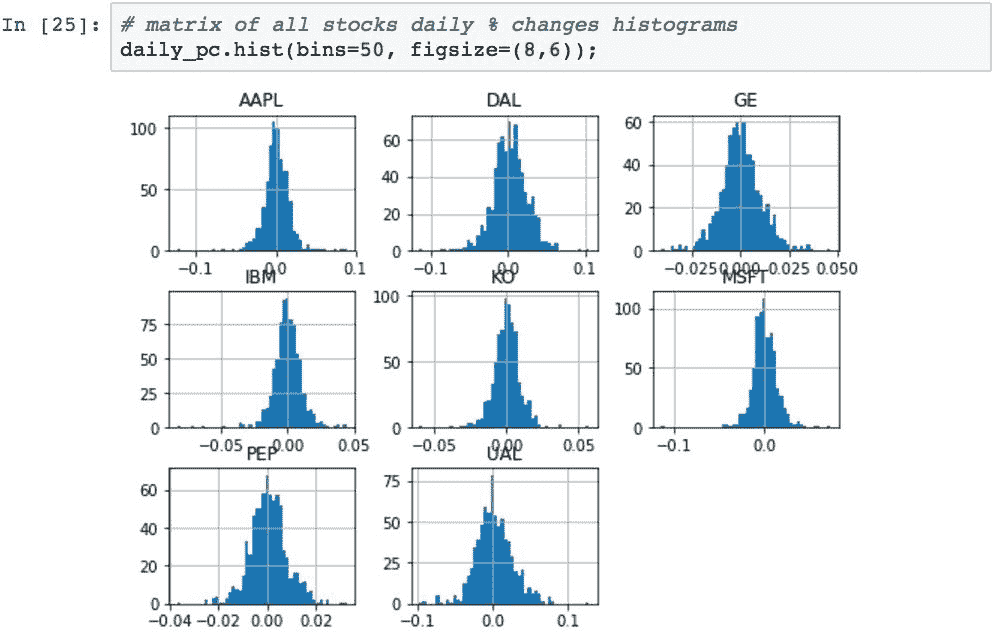
轴上的标签有点挤在一起,但是直方图的形状很重要。
从该图表可以看出这九只股票的表现差异,尤其是偏度(均值一侧有更多例外值)。 我们还可以看到总体分布宽度的差异,从而可以快速查看波动性较大的股票。
执行滚动平均计算
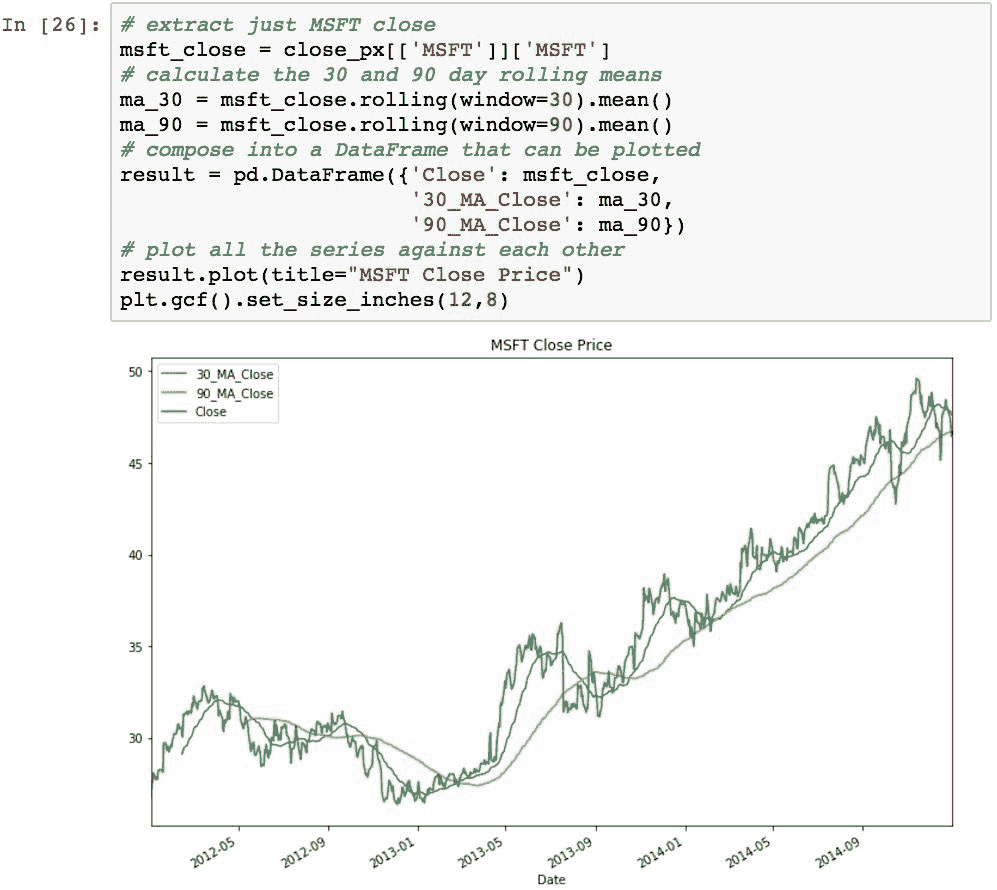
可以使用.rolling().mean()计算股票的滚动平均线。 通过消除股票表现中的“噪音”,滚动平均线将使您对股票在给定时间内的表现有所了解。 滚动窗口越大,图形将越平滑且随机性越小,但是会牺牲准确性。
以下示例使用每日收盘价计算 30 天和 90 天期间MSFT的滚动平均值。 可以从视觉上轻松确定降噪的差异:
股票间的每日平均回报的比较
散点图是一种非常有效的方法,可以直观地确定两个股票之间的股价变化率之间的关系。 下图显示了MSFT和AAPL之间的收盘价每日百分比变化的关系:
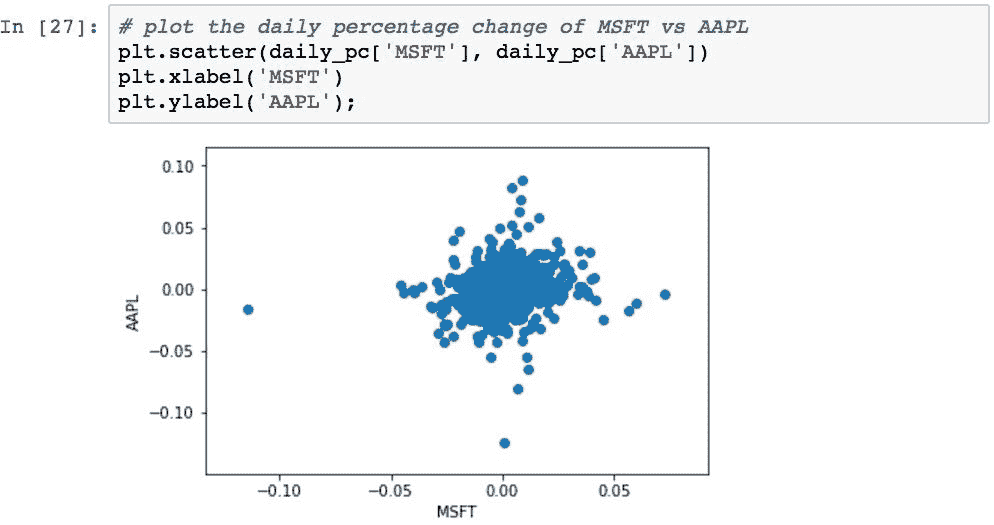
这使我们可以快速查看两种股票之间的每日收益的整体相关性。 每个点代表两只股票的一天。 每个点沿着AAPL的百分比变化沿垂直方向绘制,而对于MSFT沿水平线绘制。
如果对于AAPL值更改的每个金额,MSFT当天也更改了相同比例的金额,则所有点将从左下部分到右上部分沿理想的垂直对角线落下。 在这种情况下,两个变量将与 1.0 的相关值完全相关。 如果两个变量完全不相关,则相关性以及线的斜率将为 0,即完全水平。
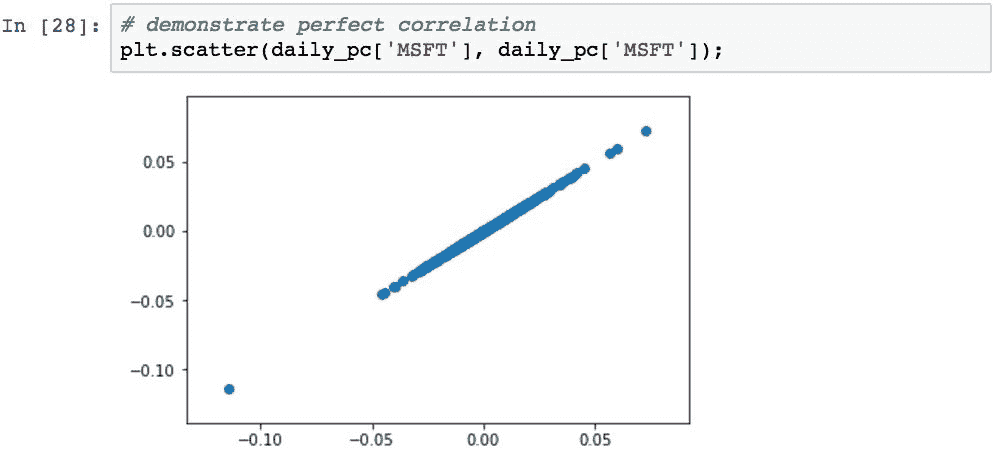
为了演示完美的相关关系,我们可以绘制MSFT与MSFT的关系图。 与自己相关的任何此类序列将始终为 1.0:
回到AAPL与MSFT的图,不包括几个离群值,由于所有值似乎都集中在中心附近,因此该群集似乎仅显示出两只股票之间的适度相关性。
实际的相关性计算(将在下一节中进行研究)显示相关性为 0.1827(这是回归线的斜率)。 该回归线将比对角线更水平。 这意味着,从统计学上来说,对于AAPL价格的任何特定变化,将无法根据 AAPL 的价格变化预测给定日期MSFT价格的变化。
为了促进对多个相关性的整体视觉分析,我们可以使用散点图矩阵图:
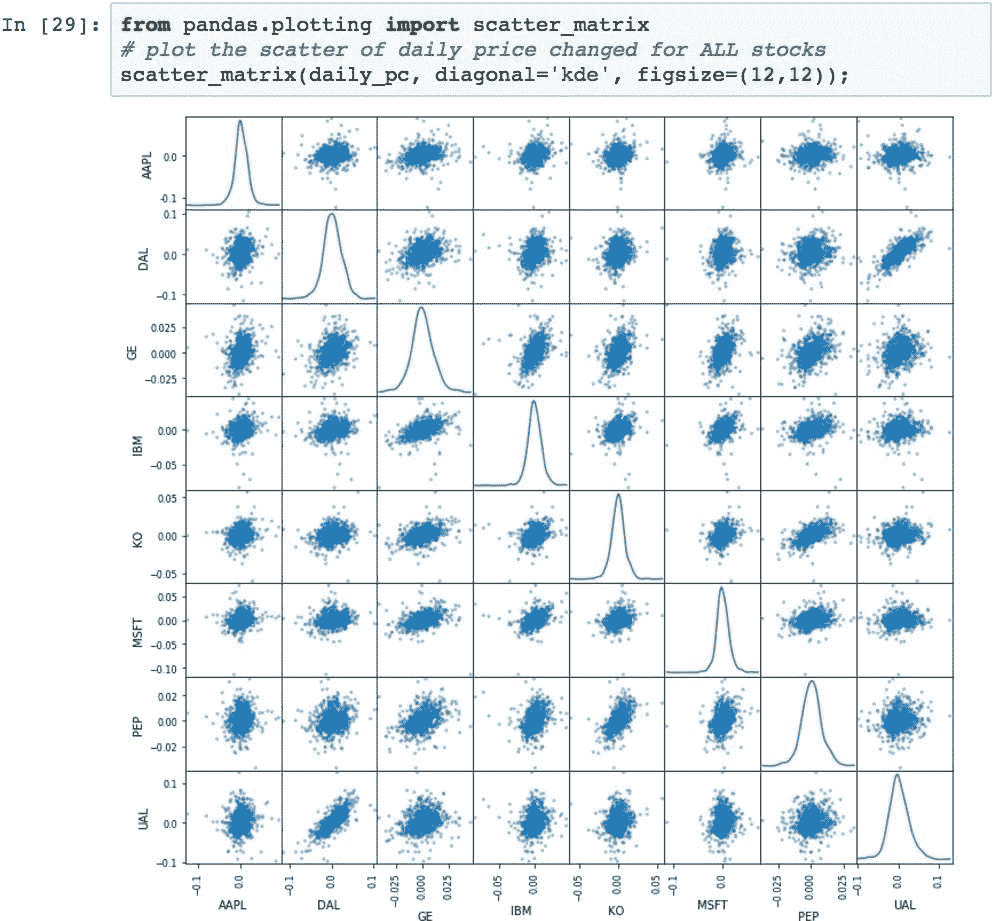
该图中的对角线是核密度估计图。 较窄的曲线与较宽的曲线相比波动性较小,偏斜表示较大的收益或亏损趋势。 结合散点图,可以快速总结具有两种不同视觉指标的任意两种股票的比较。
基于收盘价的每日百分比变化的股票相关性
相关性是两个变量之间关联强度的度量。 相关系数为 1.0 意味着,一组数据中的每个值更改在另一组数据中都有相应的值更改。 0.0 相关性意味着数据集没有关系。 相关性越高,基于一个或另一个预测每个变化的能力就越大。
散点图矩阵使我们快速直观地了解了两种股票之间的相关性,但它不是一个确切的数字。 可以使用.corr()方法计算DataFrame中数据列之间的确切相关性。 这将生成代表列的变量之间所有可能相关性的矩阵。
下面的示例计算样本三年中所有这些股票的收盘价每日百分比变化的相关性:

对角线始终为 1.0,因为股票始终与自身完全相关。 可以使用热图可视化此相关矩阵:
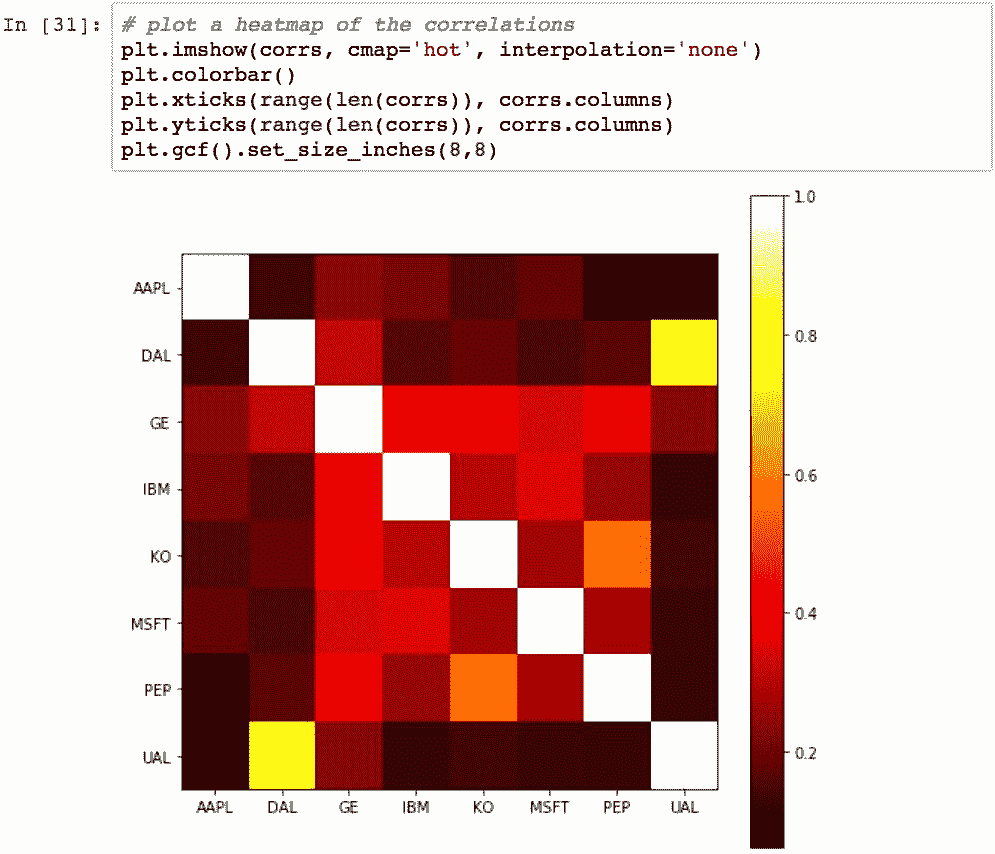
该图的想法是,您可以通过查找垂直和水平变量的交点,通过颜色查看相关程度。 颜色越深,相关性越小; 颜色越浅,相关性越大。
计算股票的波动性
股票的波动率是对特定时间段内股票价格方差变化量的度量。 通常,将一只股票的波动率与另一只股票的波动率进行比较,以获得可能风险较小的感觉,或者将一个市场指数与股票的波动率与整个市场进行比较,这是很常见的。 通常,波动性越高,对该股票进行投资的风险就越大。
波动率是通过对股票变化百分比取滚动窗口标准差(并相对于窗口大小缩放比例)来计算的。 窗口的大小会影响整体结果。 窗口越大,代表的测量值就越不代表。 随着窗口变窄,结果接近标准差。 因此,根据数据采样频率选择适当的窗口大小是一项技巧。 幸运的是,Pandas 使得交互修改非常容易。
作为示例,给定 75 个周期的窗口,以下内容将计算样本中股票的波动率:
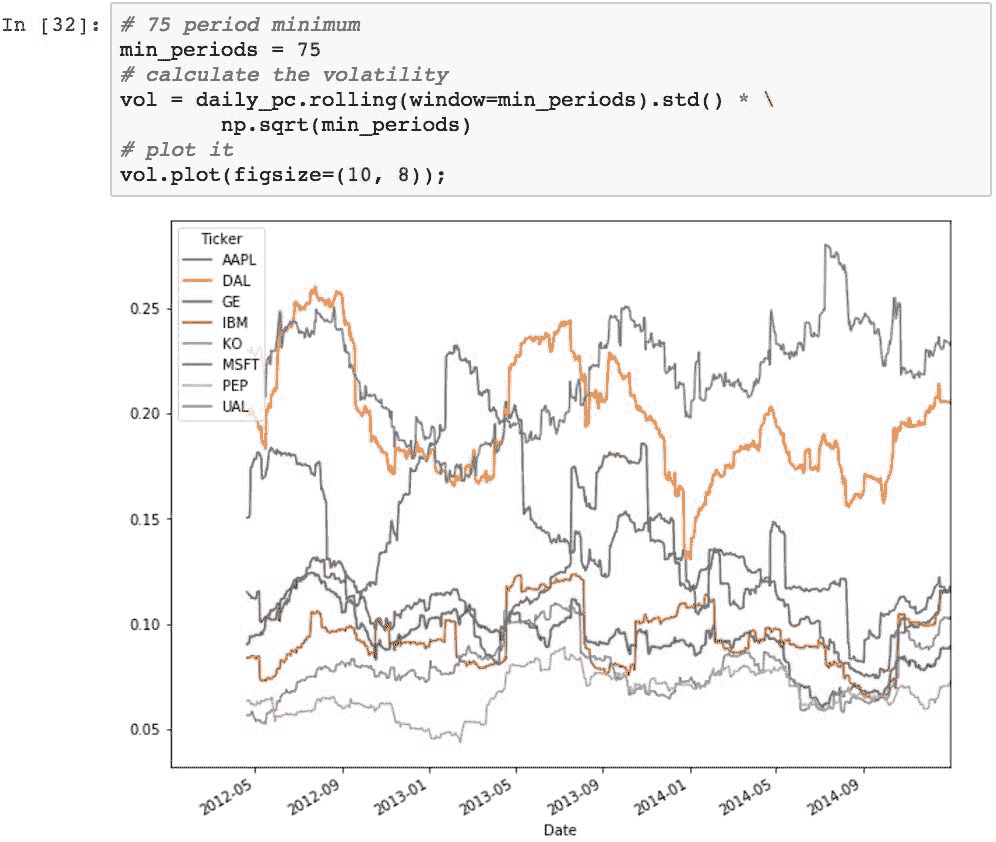
图表上较高的线表示总体较高的波动率,并且波动率随时间的变化显示为每条线中的运动。
确定相对于预期收益的风险
有用的分析是将股票每日百分比变化的波动率与其预期收益相关联。 这给人一种股票投资的风险/收益率的感觉。 这可以通过将每日百分比变化的平均值相对于相同值的标准差进行映射来计算。
创建一个散点图,将散点图与我们的一组样本股票的风险和回报相关联,并用气泡和箭头标记点:

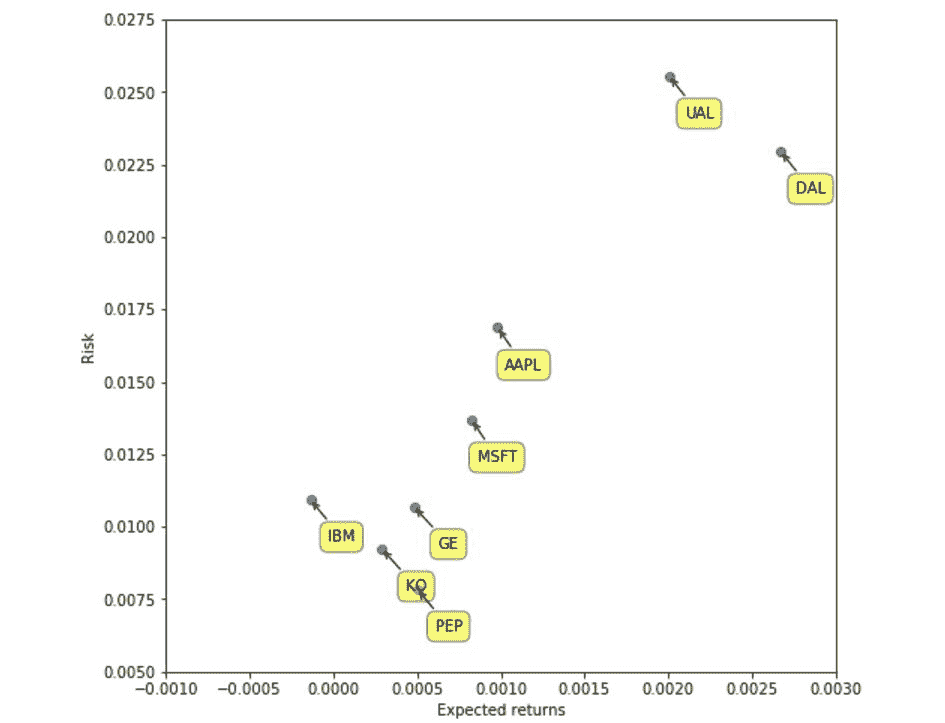
这样的结果立即从可视化中跳出来,但是仅通过查看数字表就很难看到:
- 航空股票(
AA,DAL和UAL)具有最高的风险,但也具有最高的回报率(这不是一般的投资规则吗?)。 - 科技股具有中等风险,但回报也中等。
- 在科技股中,
IBM和GE是四家中最保守的。 - 可乐股票的风险最低,但总体回报率也最低。 对于大宗商品,这是有意义的。
总结
在学习 Pandas 及其为数据处理和分析提供的功能方面,我们已经走到了旅程的尽头。 在本章之前,我们花费了大部分时间来学习 Pandas 的功能,并且在许多情况下,使用的是设计用来演示概念的数据,而不是使用实际数据。
在本章中,我们将利用到目前为止所学到的所有知识,来说明使用 Pandas 分析现实世界的数据(尤其是股票数据)并从数据中得出结果是多么容易。 通常,这使我们能够通过可视化来快速得出结论,这些可视化旨在使数据中的模式显而易见。
本章还介绍了一些财务概念,例如每日百分比变化,计算收益和时间序列数据的相关性。 重点不是金融理论,而是证明使用 Pandas 来管理和从数字列表中获取含义是多么容易。
最后,值得注意的是,尽管 Pandas 是由金融分析师创建的(因此它具有在金融领域提供简单解决方案的能力),但 Pandas 绝不仅限于金融。 它是用于数据分析的非常强大的工具,可以同样有效地应用于许多其他领域。 其中有几个新兴市场代表着巨大的机遇,例如社交网络分析或可穿戴计算的应用。 无论您将 Pandas 用于哪个领域,我都希望您能像我一样发现使用 Pandas 很有趣。
标签:11,15,对象,DataFrame,索引,使用,数据,Pandas From: https://www.cnblogs.com/apachecn/p/17314601.html