元字符
元字符就是指那些在正则表达式中具有特殊意义的专用字符
元字符的分类与记忆技巧
我们可以把元字符大致分为这几类:表示单个特殊字符的,表示空白符的,表示某个范围的,表示次数的量词,另外还有表示断言的,我们可以把它理解成边界限定。
特殊单字符
. 任意字符(换行除外)
\d 任意数字 \D 任意非数字
\w 任意字母数字下划线 \W 任意非字母数字下划线
\s 任意空白符 \S 任意非空白符
\d(只能匹配上任意数字)测试实例: https://regex101.com/r/PnzZ4k/1
\w (能匹配上所有的数字下划线) 测试实例:https://regex101.com/r/PnzZ4k/1
空白符
\r 回车符
\n 换行符
\f 换页符
\t制表符
\v 垂直制表符
\s 任意空白符
平时使用正则,大部分场景使用 \s 就可以满足需求,\s 代表任意单个空白符号
量词
*含义: 0到多次
+含义: 1到多次
? 含义: 0到1次,如colou?r
{m}含义:出现m次
{m,}含义:出现至少m次
{m,n}含义:m到n次
在英语中,文本这个词语,可能是带有u的colour,也可能是不带u的color,我们使用colou?r就可以表示两种情况了。在真实的业务场景中,比如某个日志需要添加了一个user字段,但在旧日志中,这个是没有的,那么这时候可以使用问号来表示0次或1次,这样就可以表示user字段存在和不存在两种情况。
color?r
user?
范围
| 或,如ab|bc代表ab或bc
[...] 多选一,括号中任意单个元素
[a-z]匹配a到z之间任意单个元素(按ASCII表,包含a,z)
[^...]取反,不能是括号中的任意单个元素
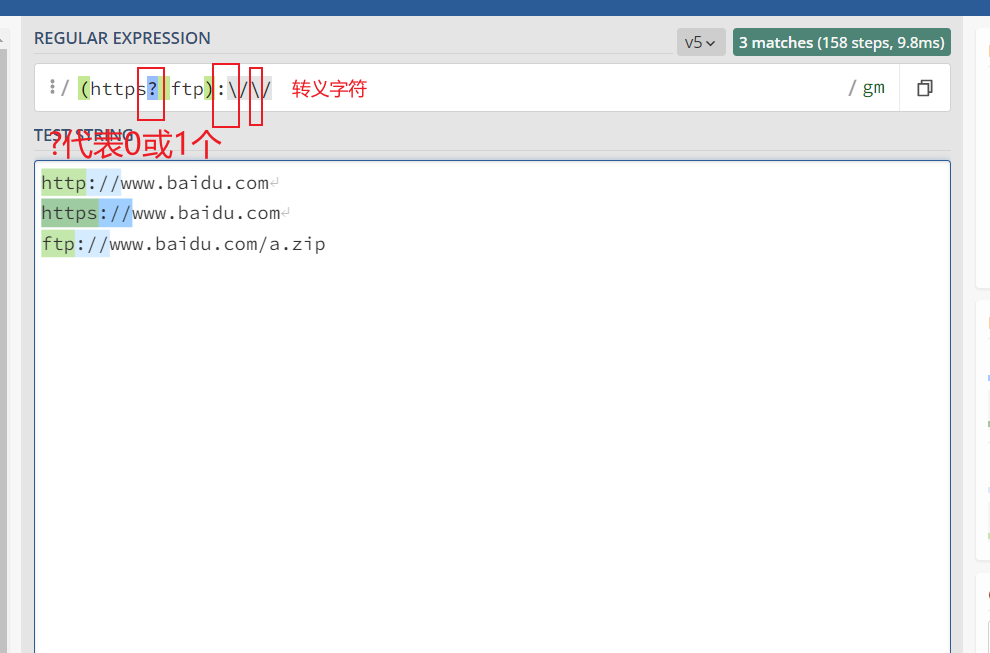
举例
比如某个资源可能以 http://开头,或者https://开头,也可能以ftp://开头,那么资源的协议部分,我们可以使用(https?|ftp):// 来表示
(https?|ftp)://
量词与贪婪
正则中的三种匹配,贪婪匹配、非贪婪匹配和独占模式。
这些模式会改变正则中量词的匹配行为,比如匹配一到多次;
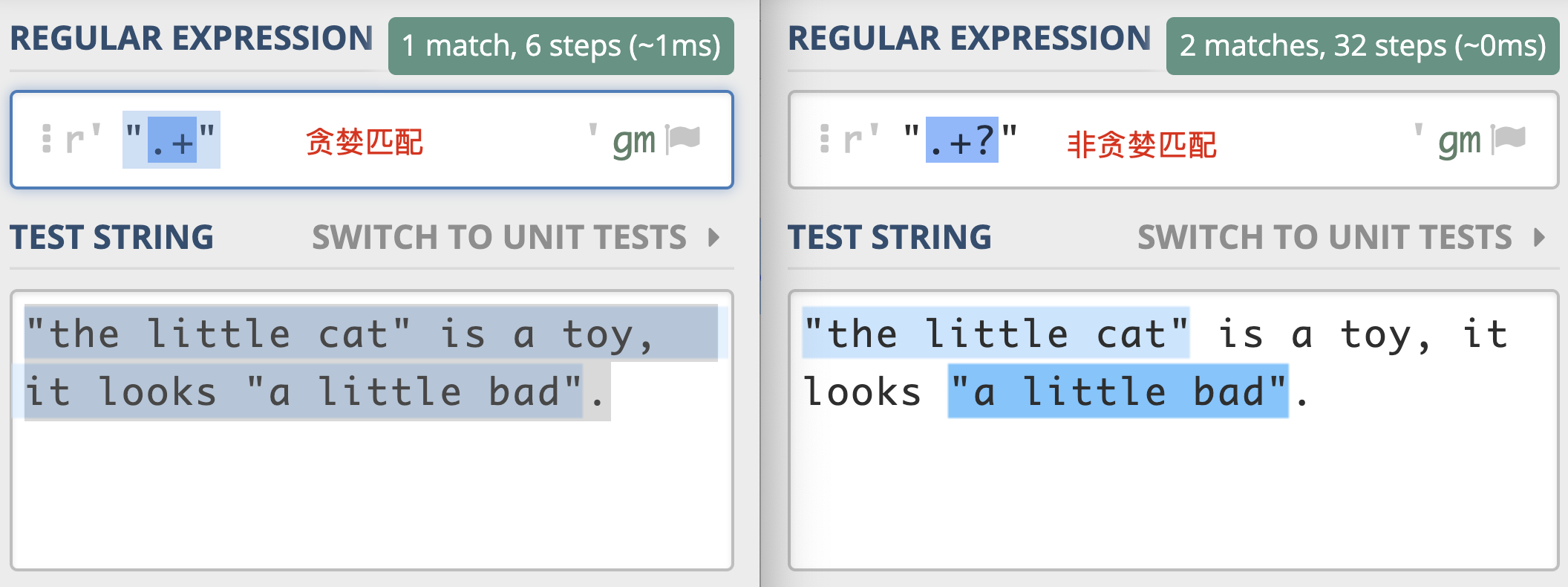
贪婪模式
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
在贪婪模式下, 会尝试尽可能最大长度去匹配。
a+
a*
非贪婪模式
如何将贪婪模式变成非贪婪模式呢?我们可以在量词后面加上英文的问号(?),正则就变成了a*?。此时的匹配结果如下:
a*?
a+?
-
贪婪&非贪婪
-
- 贪婪:表示次数的量词,默认是贪婪的默认尽可能多地去匹配
- 非贪婪:“数量”元字符后加?(英文问号)找出长度最小且满足要求的
独占模式
回溯概念
回溯:后面匹配不上,会吐出已匹配的再尝试、
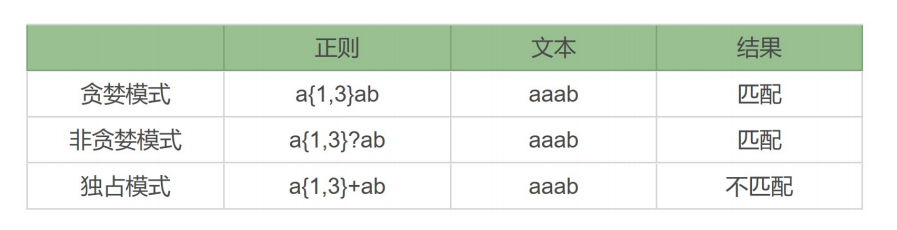
独占模式:
独占模式和贪婪模式很像,独占模式会尽可能多地去匹配,如果匹配失败就结束,不会进行回溯,这样的话就比较节省时间。具体的方法就是在量词后面加上加号(+)。
regex ="xy{1,3}+yz"
text ="xyyz"
使用独占模式,这里就会匹配失败
分组及引用
括号在正则中的功能就是用于分组,简单来理解就是,由多个元字符组成某个部分,应该被看成一个整体,这是括号的一个重要功能。其实用括号括起来还有另外一个作用,那就是复用。
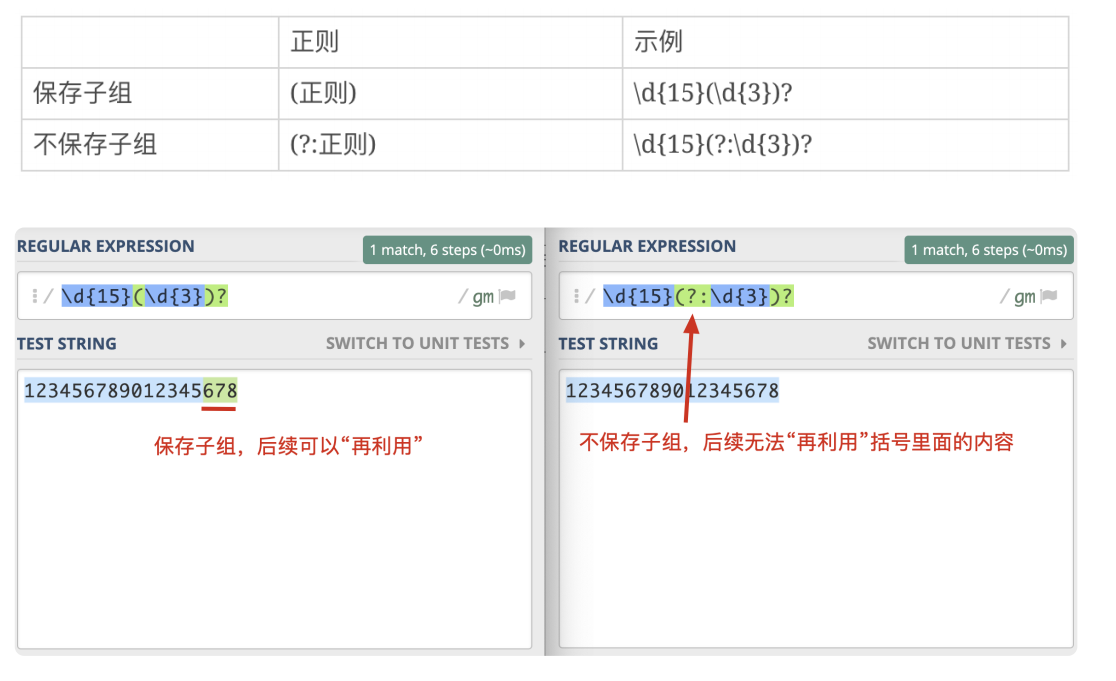
分组与编号
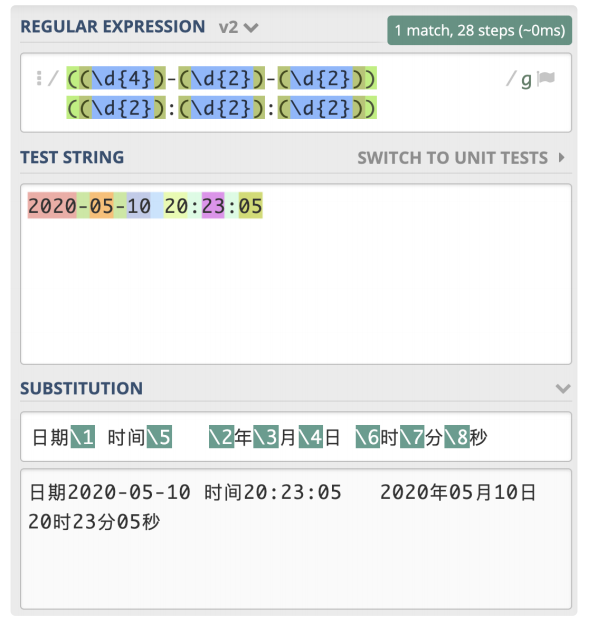
第几个括号就是第几个分组。
只需要数左括号(开括号)是第几个,就可以确定是第几个子组。

这个正则中一共有两个分组,日期是第一个,时间是第二个。
不保存分组
括号只用于归组,把某个部分当成"单个元素",
不分配编号,后面不会再进行这部分的引用
写法(?!:正则)
括号嵌套

日期分组编号是 1,时间分组编号是 5,年月日对应的分组编号分别是 2,3,4,
时分秒的分组编号分别是 6,7,8。
命名分组
由于编号得数在第几个位置,后续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化,因此一些编程语言提供了命名分组(named grouping),这样和数字相比更容易辨识,不容易出错。命名分组的格式为 (?P < 分组名> 正则)。
^profile/(?P<username>\w+)/$
分组引用
在知道了分组引用的编号 (number)后,大部分情况下,我们就可以使用 “反斜扛 + 编号”,即\number 的方式来进行引用
分组引用在查找中使用
分组引用在查找中使用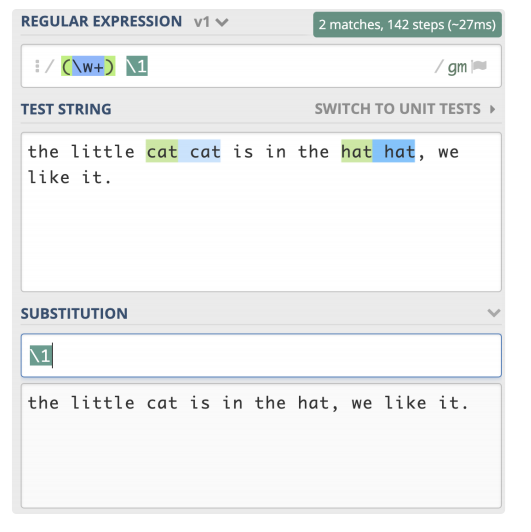
匹配模式
不区分大小写模式
模式修饰符
格式: (?模式标识)
如:
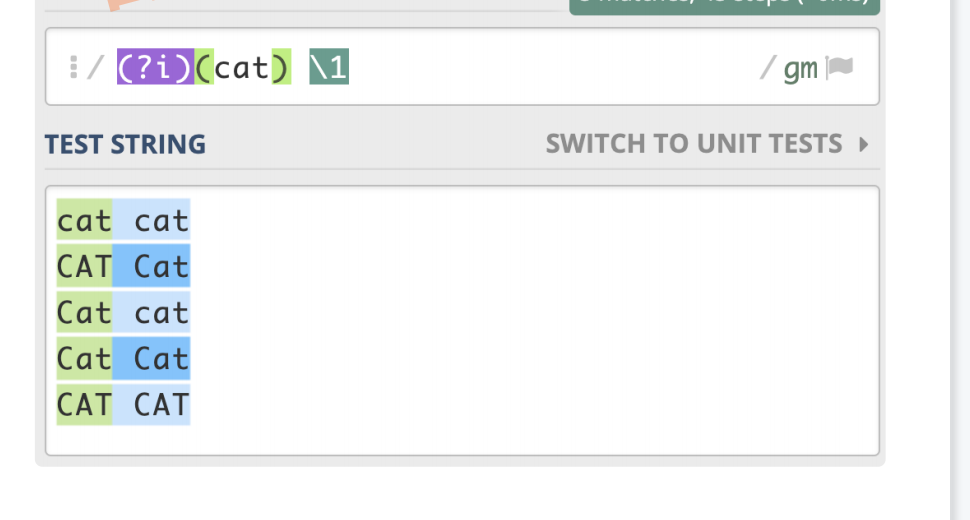
(?i)cat # 不区分大小写的 cat
要点:
1.不区分大小写的指定方式,使用模式修饰符(?i)
2.修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则
3.使用编程语言时可以使用定义好的常量来指定匹配模式。
我们尝试匹配两个不区分大小的连续出现的cat
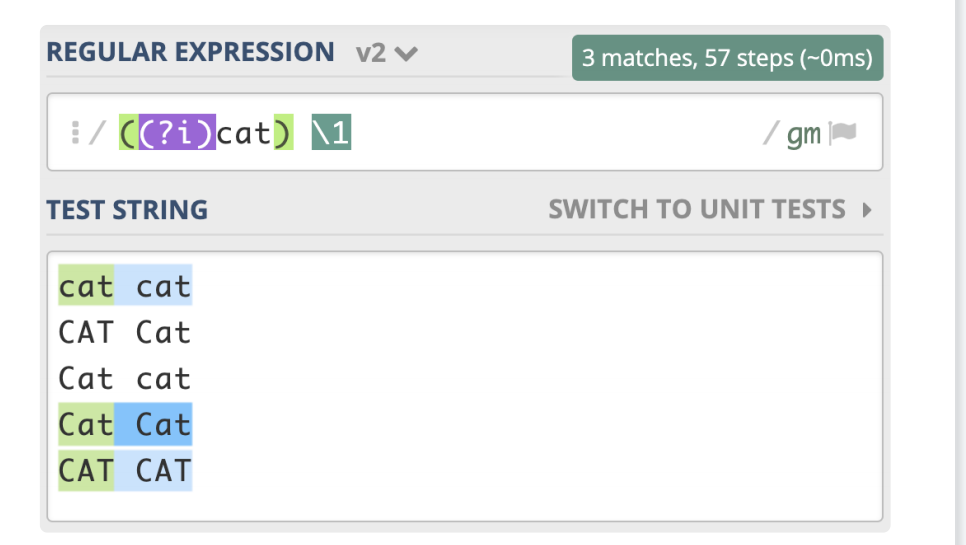
我们想让前面匹配的结果和第二次重复时的大小一致,那就需要用括号把修饰符和正则cat部分括起来,加括号相当于作用范围的限定,让不区分大小写只作用于这个括号里面的内容。
点号通配模式(Dot All)
模式修饰符:
格式: (?s)
如:
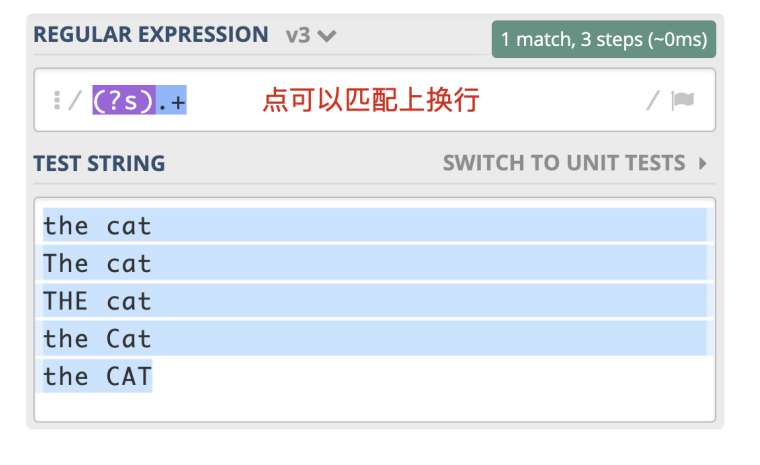
(?s).+
有很多地方把它称作单行匹配模式,但这么说容易造成误解,毕竟它与多行匹配模式没有联系,因此在课程中我们统一用更容易理解的”点号通配模式“。
单行的英文表示是Single Line,单行模式对应的修饰符是(?s),我还是选择用 the cat来给你举一个点号通配模式的例子。如下图所示:
多行匹配模式
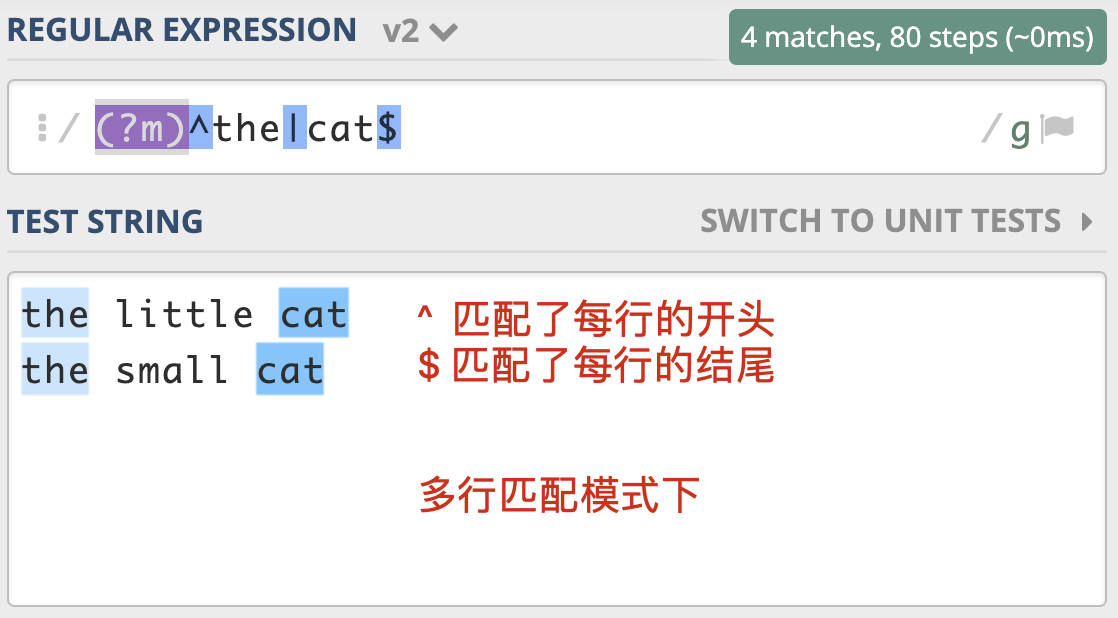
模式修饰符:
格式: (?m)
如:
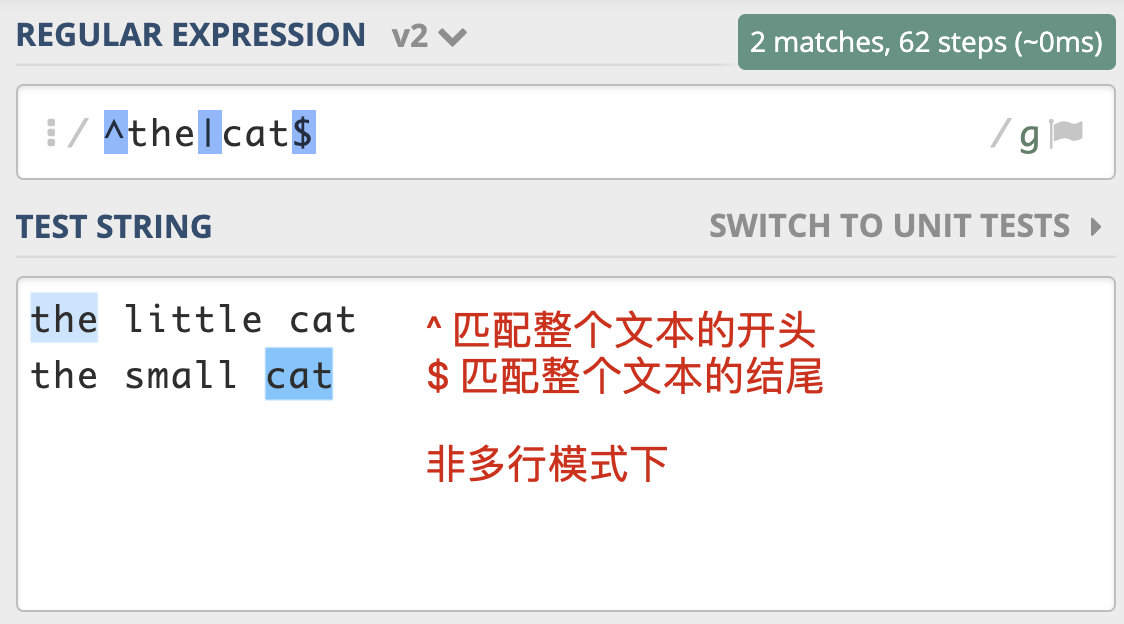
(?m)^the|cat$
^ 匹配整个字符串的开头
$ 匹配整个字符串的结尾
非多行模式
多行模式
注释模式
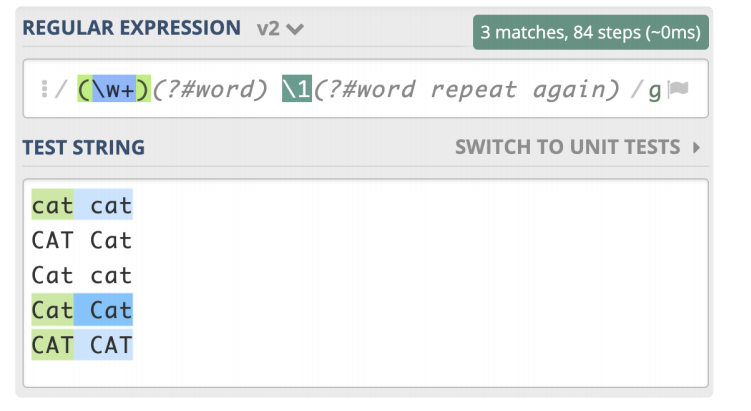
模式修饰符:
格式: (?#comment)
如:
(\w+)(?#word) \1(?#word repeat again)
断言
断言是指对匹配到的文本位置有要求。
有些情况下,我们要对匹配的文本的位置也有一定的要求。
单词边界(Word Boundary)
我们可以在正则中使用\b来表示单词的边界。\b中的b可以理解为是边界(Boundary)这个单词的首字母。
准确匹配单词
使用 \b\w+\b
我们如果想替换语句中的tom
tom asked me if I would go fishing with him tomorrow.
如果我们直接替换
jerry asked me if I would go fishing with him jerryorrow.
我们使用单词边界
使用 \btom\b
行的开始或结束
如果我们要求匹配的内容要出现在一行文本或结尾,就可以使用^和$来进行位置界定。
日志起始行判断:
判断条件:以时间开头
那些不是以时间开头的可能就是打印的堆栈信息
输入数据校验
re.search('^\d{6}$', "123456") # 用户录入的 6 位数字必须是行的开头或结尾
环视(Look Around)
环视就是要求匹配部分的前面或者后面要满足(或不满足)某种规则,
有些地方也称环视为零宽断言。
环视的四种结构:
(?<=Y): 肯定逆序(postive-lookbehind)
(?<!Y): 否定逆序(negative-lookbehind)
(?=Y): 肯定顺序(postive-lookahead)
(?!Y): 否定顺序(negative-lookahead)
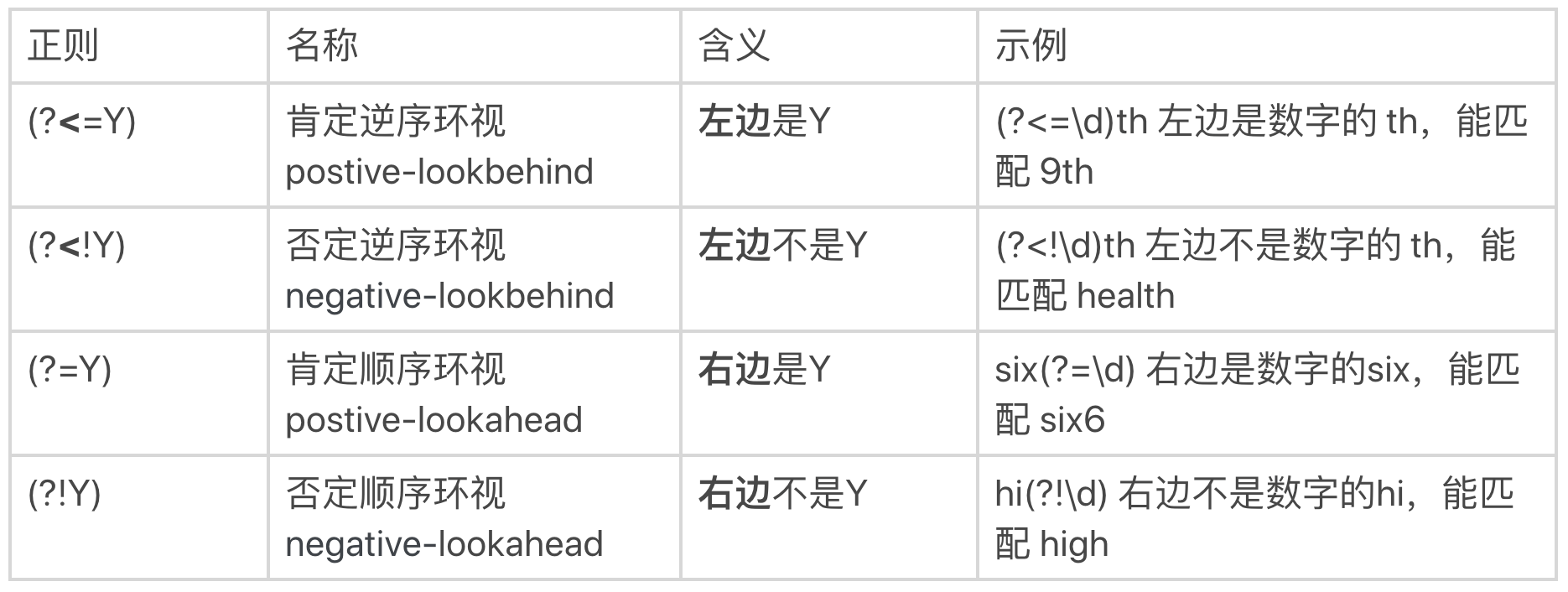
左尖括号代表看左边,没有尖括号是看右边,感叹号是非的意思。
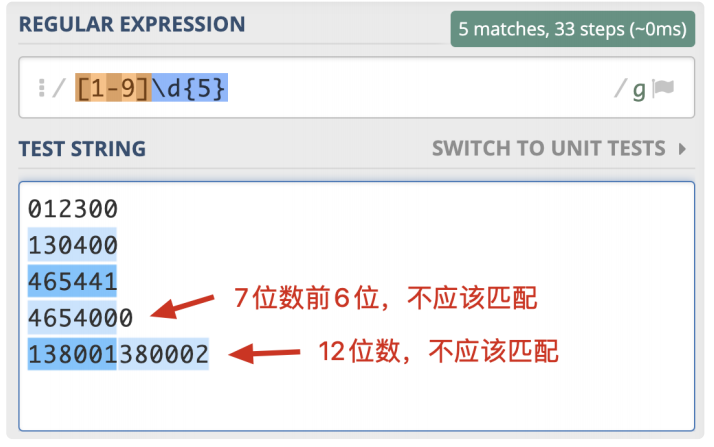
验证是否有且只有 6 位数字。
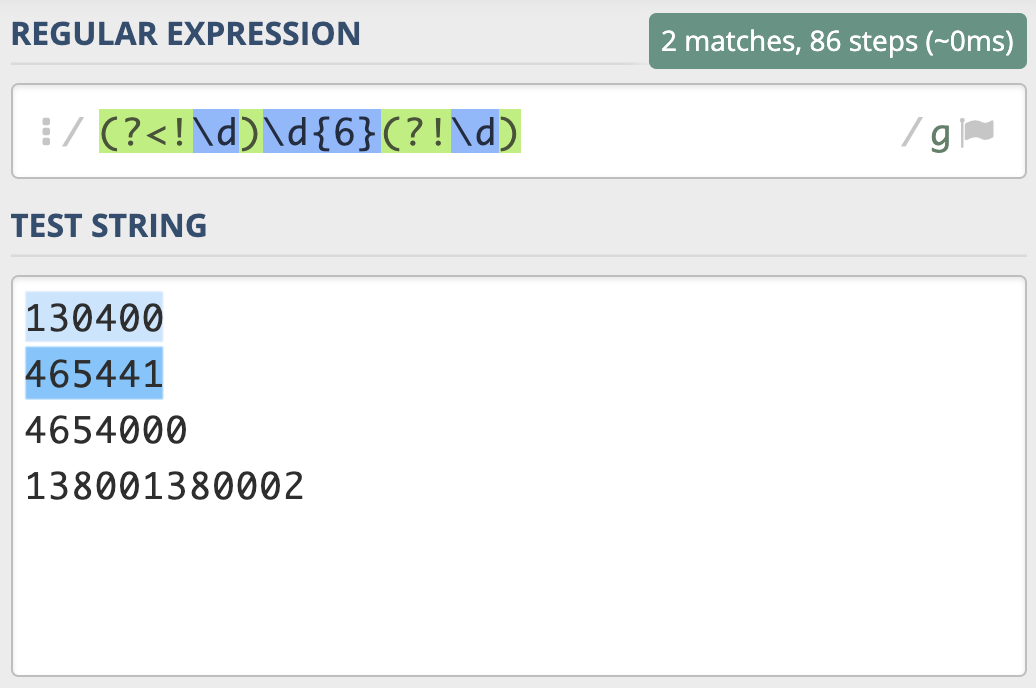 左边不是数字,右边也不是数字的6位数的正则。即
左边不是数字,右边也不是数字的6位数的正则。即(?<!\d)[1-9]\d{5}(?!\d)。
转义Escape
转义字符:Escape Character
转义序列通常有两种功能:
编码无法用字母表直接表示的特殊数据
用于表示无法直接键盘录入的字符(如回车符)
字符串转义和正则转义
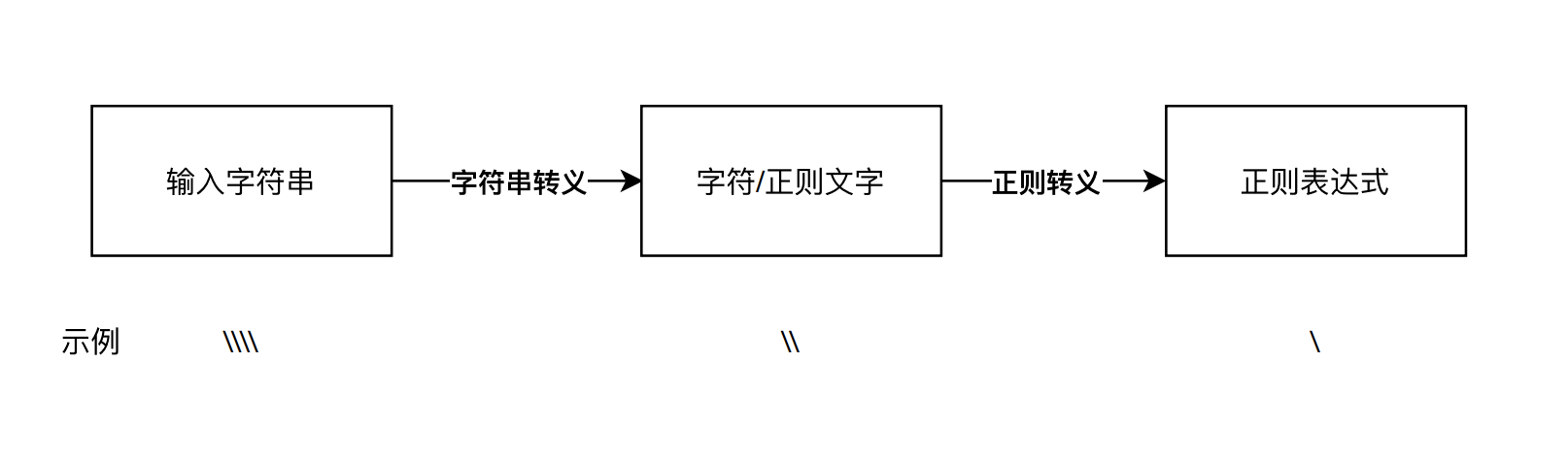
我们输入的字符串,四个反斜杠\,净化过第一步字符串转义,它代表的含义是两个反斜杠\;这两个反斜杠再经过第二步正则转义,它就可以代表单个反斜杠\了。
re.findall('\\\\', 'a*b+c?\\d123d\\')
['\\', '\\']
=>
re.findall(r'\\', 'a*b+c?\\d123d\\')
在Python中,可以在正则前面加上小写字母r来表示
['\\', '\\']
为什么字符也要2个反斜杠\。
因为python处理字符的时候会进行转义。
元字符的转义
re.findall('\+', '+')
['+']
括号的转义
方括号[]和花括号{}只需转义开括号,但圆括号()两个都要转义:
re.findall('\(\)\[]\{}', '()[]{}')
['()[]{}']
方括号和花括号都转义也可以
re.findall('\(\)\[\]\{\}', '()[]{}')
['()[]{}']
在正则中,圆括号通常用于分组,或者将某个部分看成一个整体,如果只转义开括号或闭括号,正则会认为少了另外一半,所以会报错
字符组中的转义
书写正则的时候,在字符组中,如果有过多的转义会导致代码可读性差。在字符组里只有三种情况需要转义。
- 脱字符在中括号中,且在第一个位置需要转义:
re.findall(r'[^ab]', '^ab') # 转义前代表"非"
['^']
re.findall(r'[\^ab]', '^ab') # 转义后代表普通字符
['^', 'a', 'b']
- 中划线在括号中,且不在首尾位置
re.findall(r'[a-c]', 'abc-') # 中划线在中间,代表"范围"
['a', 'b', 'c']
re.findall(r'[a\-c]', 'abc-') # 中划线在中间,转义后的
['a', 'c', '-']
re.findall(r'[-ac]', 'abc-') # 在开头,不需要转义
['a', 'c', '-']
re.findall(r'[ac-]', 'abc-') # 在结尾,不需要转义
['a', 'c', '-']
- 右括号在中括号里,且不在首位
re.findall(r'[]ab]', ']ab') # 右括号不转义,在首位
[']', 'a', 'b']
re.findall(r'[a]b]', ']ab') # 右括号不转义,不在首位
[] # 匹配不上,因为含义是 a后面跟上b]
re.findall(r'[a\]b]', ']ab') # 转义后代表普通字符
[']', 'a', 'b']
除上面三种必须转义的情况,其它情况不转义也能正常工作
一般来说如果我们要想将元字符(.+?() 之类)表示成它字面上本来的意思,是需要对其进 行转义的,但如果它们出现在字符组中括号里,可以不转义。这种情况,一般都是单个长度 的元字符,比如点号(.)、星号()、加号(+)、问号(?)、左右圆括号等。它们都不再具有特殊含义,而是代表字符本身。但如果在中括号中出现 \d 或 \w 等符号时,他们还 是元字符本身的含义。
re.findall(r'[.*+?()]', '[.*+?()]') # 单个长度的元字符
['.', '*', '+', '?', '(', ')']
re.findall(r'[\d]', 'd12\\') # \w,\d等在中括号中还是元字符的功能
['1', '2'] # 匹配上了数字,而不是反斜杠\和字母d
常见的流派及其特性
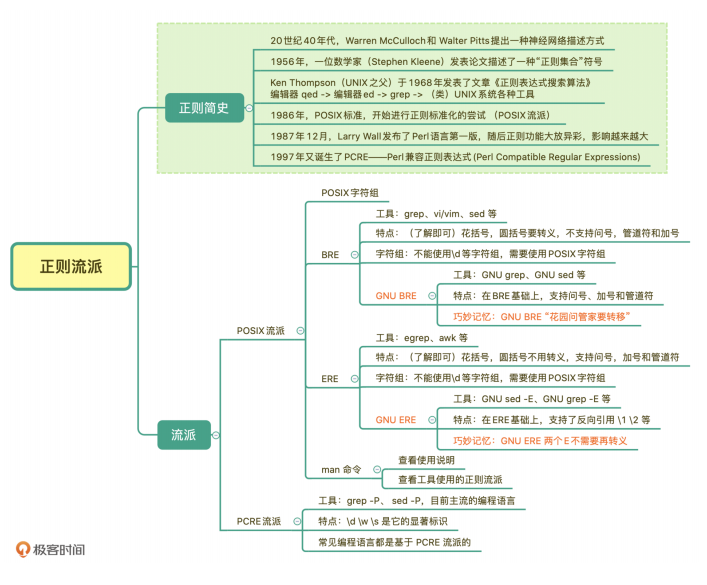
Unicode
Unicode属性
正则中常用的三种 Unicode 字符集:
1. 按功能划分的 Unicode Categories(有的也叫 Unicode Property),比如标点符号,数字符号
2. 按连续区间划分的 Unicode Blocks,比如只是中日韩字符
3. 按书写系统划分的 Unicode Scripts,比如汉语中文字符
 正则中常用的三种 Unicode 字符集
正则中常用的三种 Unicode 字符集
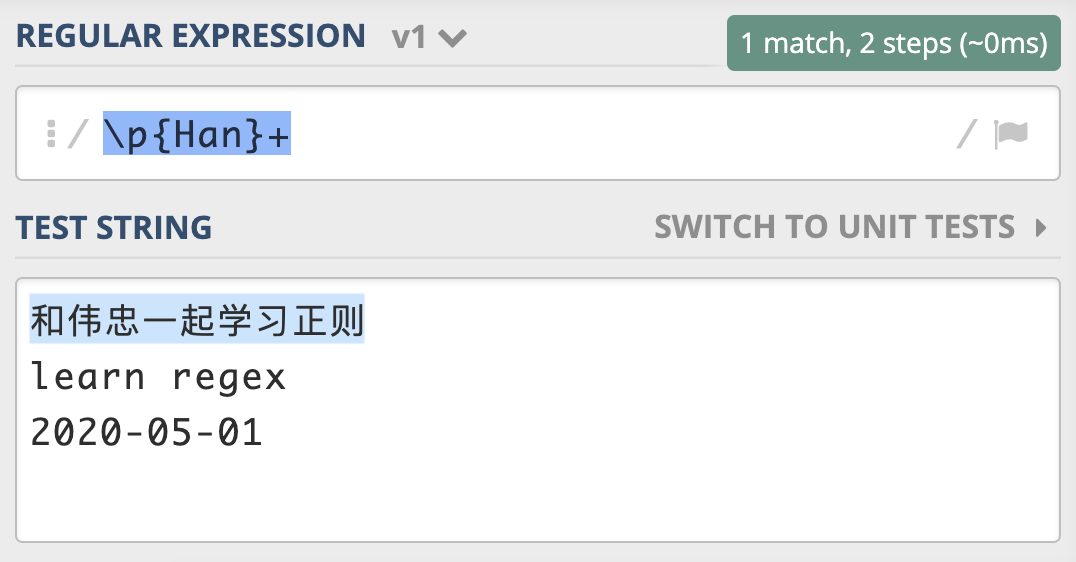
在正则中,这三种属性在正则中的表示方式都是 p {属性}。比如,我们可以使用 Unicode Script 来实现查找连续出现的中文。其中,Unicode Blocks 在不同的语言中记法有差异,比如 Java 需要加上 In 前缀,类似于 p {InBopomofo} 表示注音字符。
表情符号
表情符号有如下特点:
1. 许多表情不在 BMP 内,码值超过了 FFFF
使用 UTF-8 编码时:
普通的 ASCII 是 1 个字节
中文是 3 个字节
有一些表情需要 4 个字节来编码
2. 这些表情分散在 BMP 和各个补充平面中
要想用一个正则来表示所有的表情符号非常麻烦,即便使用编程语言处理也同样很麻烦
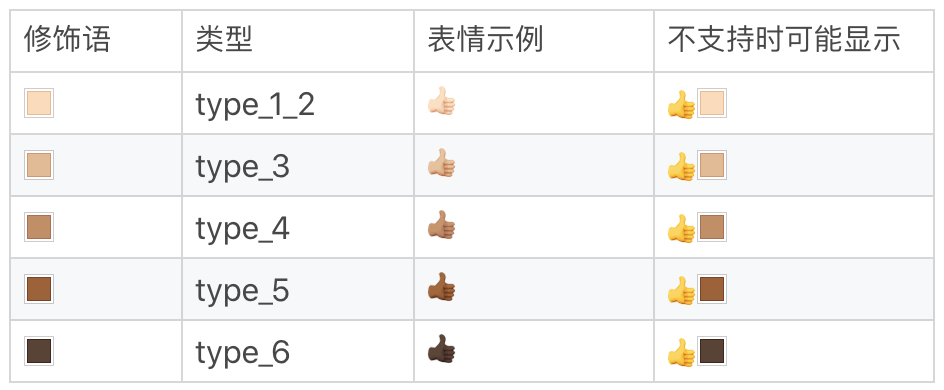
3. 一些表情现在支持使用颜色修饰(Fitzpatrick modifiers),可以在 5 种色调之间进行选择
这样一个表情其实就是 8 个字节了
匹配原则以及优化原则
有穷自动机的具体实现称为正则引擎,包括:
DFA
传统的 NFA
POSIX NFA
NFA工作机制
NFA引擎的工作方式是
先看正则,再看文本,而且以正则为主导
示例演示1
示例:
字符串:we study on jikeshijian app
正则: jike (zhushou|shijian|shixi)
- 正则中的第一个字符是 j,NFA 引擎在字符串中查找 j,接着匹配其后是否为 i ,如果是 i 则继续,这样一直找到 jike:
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshijian app
- 再根据正则看文本后面是不是 z,发现不是,此时 zhushou 分支淘汰:
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支 (zhushou)
text: we study on jikeshijian app
- 看其它的分支,看文本部分是不是 s,直到 shijian 整个匹配上:
说明:
shijian 在匹配过程中如果不失败,就不会看后面的 shixi 分支。
当匹配上了 shijian 后,整个文本匹配完毕,也不会再看 shixi 分支
示范演示2
示例-文本改一下,把 jikeshijian 变成 jikeshixi:
字符串:we study on jikeshixi app
正则:jike (zhushou|shijian|shixi)
正则 shijian 的 j 匹配不上时 shixi 的 x,会接着使用正则 shixi 来进行匹配,重新从 s 开始(NFA 引擎会记住这里):
第二个分支匹配失败
regex: jike(zhushou|shijian|shixi)
^
淘汰此分支 (正则 j 匹配不上文本 x)
text: we study on jikeshixi app
^
再次尝试第三个分支
regex: jike(zhushou|shijian|shixi)
^
text: we study on jikeshixi app
^
总结
NFA是以正则为主导,反复测试字符串,这样字符串中同一部分,有可能被反复测试很多次。
DFA工作机制
NFA引擎的工作方式是
先看文本,再看正则表达式,是以文本为主导的
示例演示
- 从we中的w开始依次查找j,定位到j,这个字符后面是i。所以我们接着看正则部分是否有i,如果正则后面是i,那就以同样的方式,匹配到后面的ke:
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^
- 文本 e 后面是字符 s ,DFA 接着看正则表达式部分,此时 zhushou 分支被淘汰,开头是 s 的分支 shijian 和 shixi 符合要求:
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^ ^ ^
淘汰 符合 符合
- 依次检查字符串,检测到 shijian 中的 j 时,只有 shijian 分支符合,淘汰 shixi,接着看分别文本后面的 ian,和正则比较,匹配成功:
text: we study on jikeshijian app
^
regex: jike(zhushou|shijian|shixi)
^ ^
符合 淘汰
总结
DFA和NFA两种引擎的工作方式完全不同。NFA是以表达式为主导的,先看正则表达式,再看文本。而DFA则是以文本为主导,先看文本,再看正则表达式。
一般来说,DFA 引擎会更快一些,因为整个匹配过程中,字符串只看一遍,
不会发生回溯,相同的字符不会被测试两次。
也就是说 DFA 引擎执行的时间一般是线性的。DFA 引擎可以确保匹配到可能的最长字符串。
但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,
它也不支持捕获子组。
NFA 以表达式为主导,它的引擎是使用贪心匹配回溯算法实现。
NFA 通过构造特定扩展,支持子组和反向引用。
但由于 NFA 引擎会发生回溯,即它会对字符串中的同一部分,进行很多次对比。
因此,在最坏情况下,它的执行速度可能非常慢。
POSIX NFA工作机制
POSIX NFA 与传统NFA区别:
传统的 NFA 引擎 “急于” 报告匹配结果,找到第一个匹配上的就返回了,
所以可能会导致还有更长的匹配未被发现
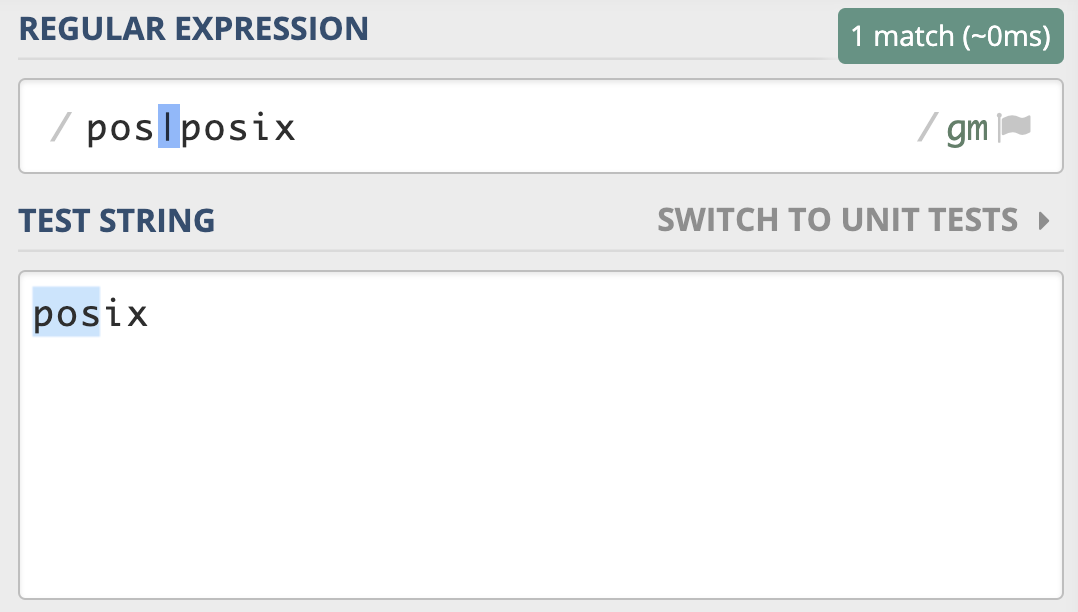
使用正则 pos|posix 在文本 posix 中进行匹配,传统的 NFA 从文本中找到的是 pos,而不是 posix,而 POSIX NFA 找到的是 posix。
POSIX NFA 的应用很少,主要是 Unix/Linux 中的某些工具。
POSIX NFA 引擎与传统的 NFA 引擎类似,但不同之处在于,
POSIX NFA 在找到可能的最长匹配之前会继续回溯,也就是说它会尽可能找最长的,
如果分支一样长,以最左边的为准(“The Longest-Leftmost”)。
因此,POSIX NFA 引擎的速度要慢于传统的 NFA 引擎。
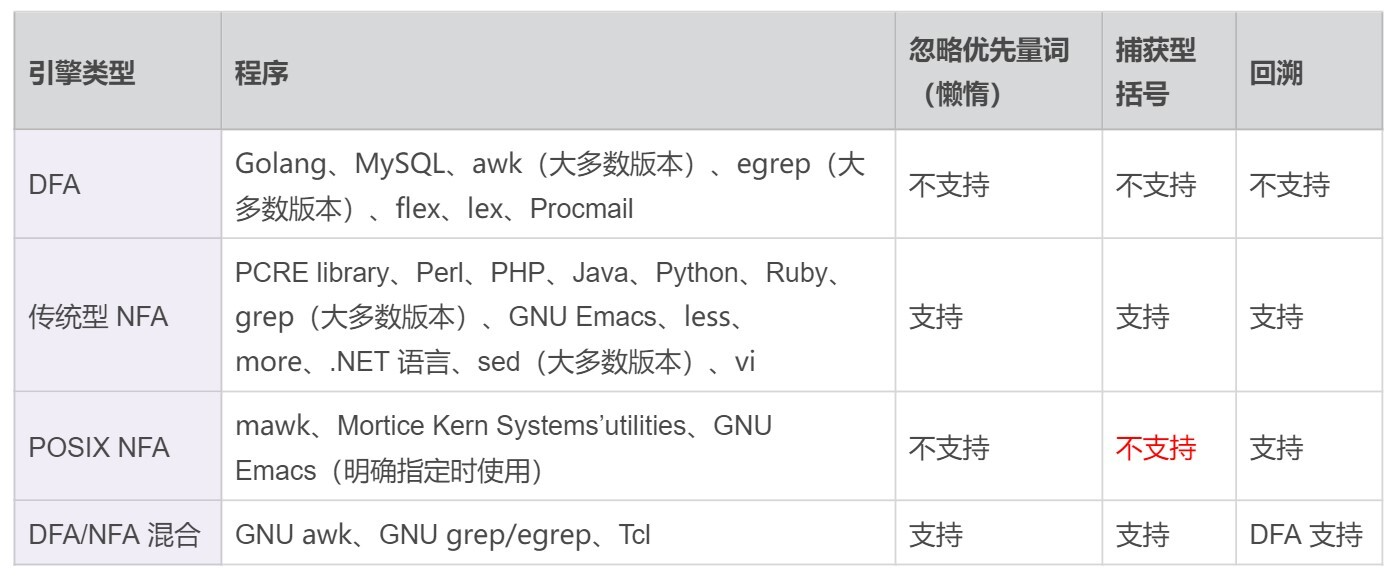 DFA、传统 NFA 以及 POSIX NFA 引擎的特点总结
DFA、传统 NFA 以及 POSIX NFA 引擎的特点总结
回溯
回溯是NFA引擎才有的,并且只有在正则中出现量词或多选分支结构时,才可能发生回溯。
示例1-简单回溯
用正则a+ab来匹配文本aab:
a+ 是贪婪匹配,会占用掉文本中的两个 a
但正则接着又是 a,文本部分只剩下 b,只能通过回溯,让 a+ 吐出一个 a,再次尝试
示例2-.*导致大量回溯
使用.*ab去匹配一个比较长的字符串
.* 会吃掉整个字符串(不考虑换行,假设文本中没有换行)
然后,你会发现正则中还有 ab 没匹配到内容,只能将 .* 匹配上的字符串吐出一个字符,再尝试
还不行,再吐出一个,不断尝试

要尽量不用 .* ,除非真的有必要,因为点能匹配的范围太广了,我们要尽可能精确。常见的解决方式有两种,比如要提取引号中的内容时,使用 “[^”]+”,或者使用非贪婪的方式 “.+?”,来减少 “匹配上的内容不断吐出,再次尝试” 的过程。
示例3-店名匹配
店名可以出现下面这些组合:
1. 英文字母大小写
2. 数字
3. 越南文
4. 一些特殊字符,如 “&”,“-”,“_” 等
正则表达:
^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
测试字符:
this is a cat, cat
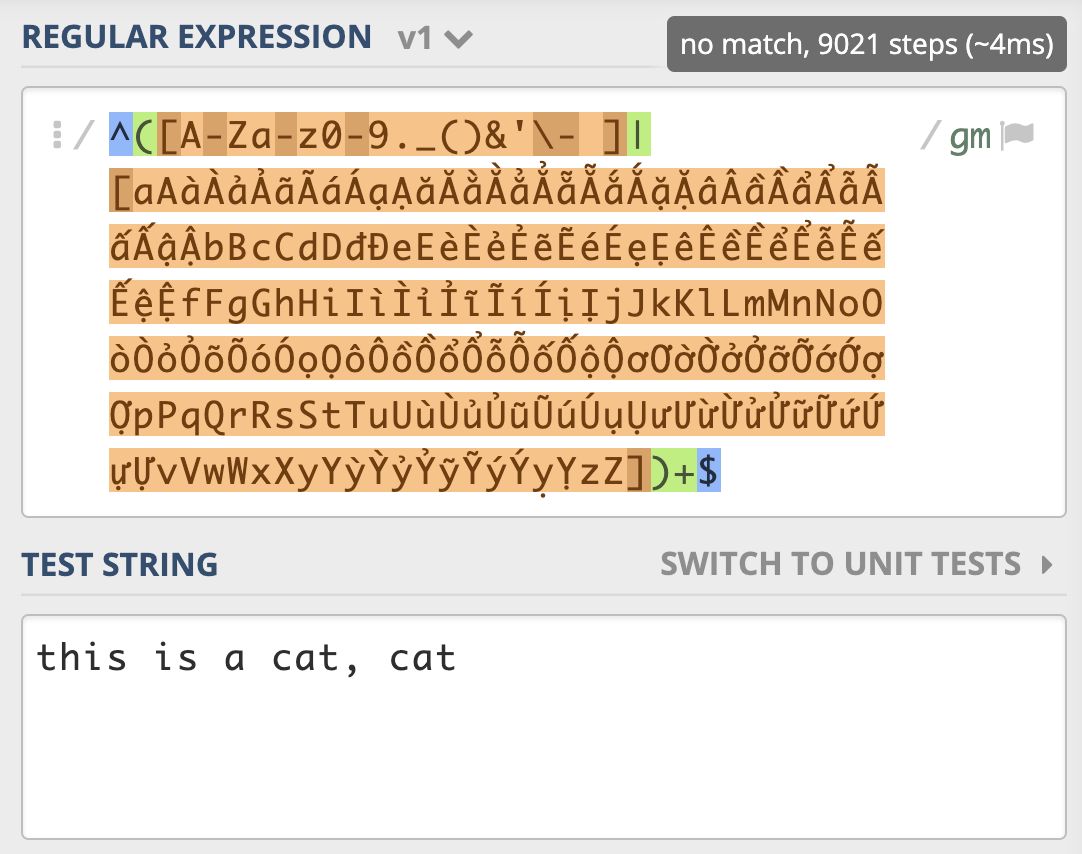 *一个很短的字符串,NFA 引擎尝试步骤达到了 9021 次,由于是贪婪匹配,第一个分支能匹配上 this is a cat 部分,接着后面的逗号匹配失败,使用第二个分支匹配,再次失败,此时贪婪匹配部分结束。NFA 引擎接着用正则后面的 $ 来进行匹配,但此处不是文本结尾,匹配不上,发生回溯,吐出第一个分支匹配上的 t,使用第二个分支匹配 t 再试,还是匹配不上。继续回溯,第二个分支匹配上的 t 吐出,第一个分支匹配上的 a 也吐出,再用第二个分支匹配 a 再试,如此发生了大量的回溯。
*一个很短的字符串,NFA 引擎尝试步骤达到了 9021 次,由于是贪婪匹配,第一个分支能匹配上 this is a cat 部分,接着后面的逗号匹配失败,使用第二个分支匹配,再次失败,此时贪婪匹配部分结束。NFA 引擎接着用正则后面的 $ 来进行匹配,但此处不是文本结尾,匹配不上,发生回溯,吐出第一个分支匹配上的 t,使用第二个分支匹配 t 再试,还是匹配不上。继续回溯,第二个分支匹配上的 t 吐出,第一个分支匹配上的 a 也吐出,再用第二个分支匹配 a 再试,如此发生了大量的回溯。
示例3-店名匹配优化
第一个分支中的 A-Za-z 去掉,因为后面多选分支结构中重复了:
^([0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
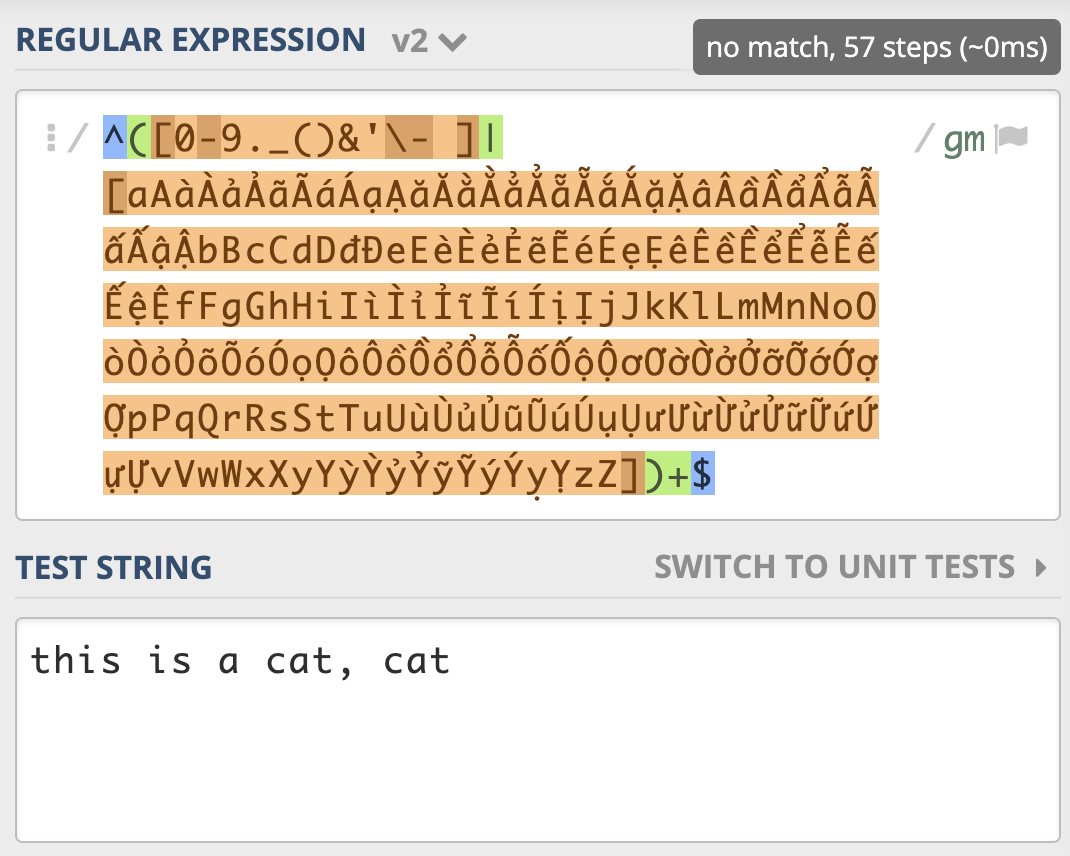 这样优化后只尝试匹配了 57 次就结束了
这样优化后只尝试匹配了 57 次就结束了
一定要记住,不要在多选择分支中,出现重复的元素。即:“回溯不可怕,我们要尽量减少回溯后的判断”
示例3-店名匹配(独占模式优化版)
说明:
独占模式可以理解为贪婪模式的一种优化
它也会发生广义的回溯,但它不会吐出已经匹配上的字符。
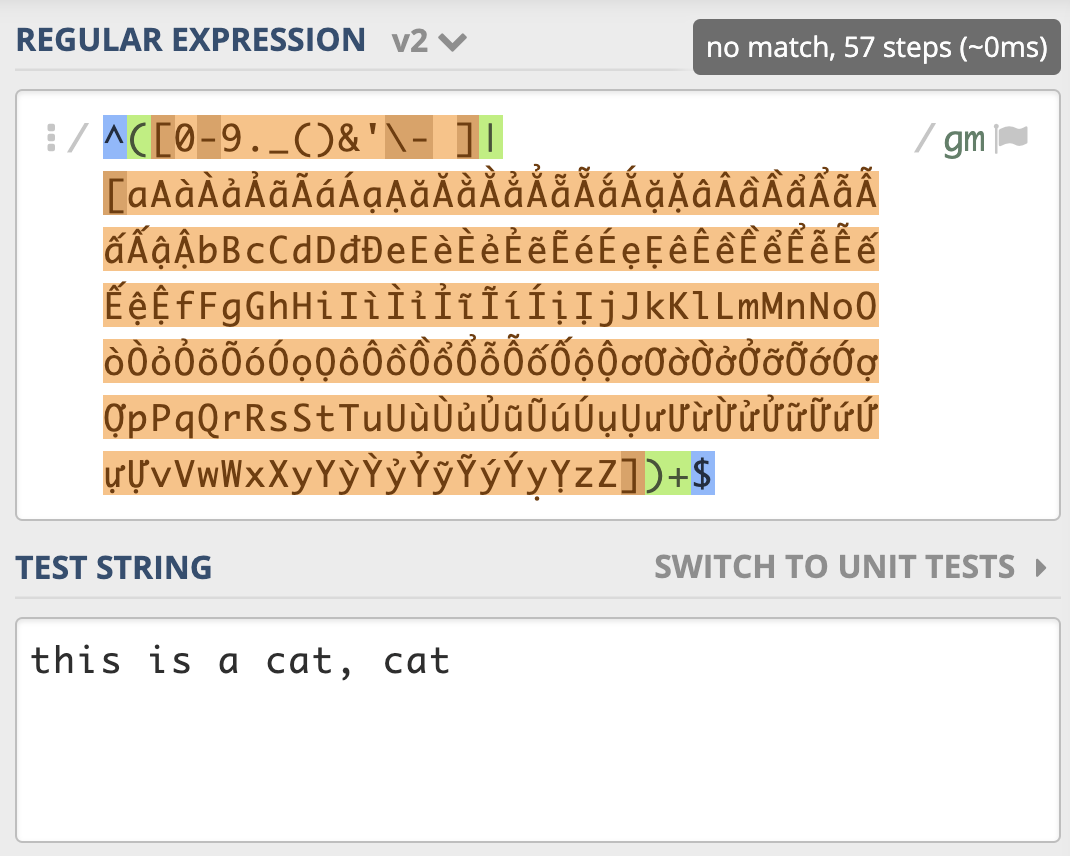
模式匹配到英文逗号那儿,不会吐出已经匹配上的字符,匹配就失败了,所以采用独占模式也能解决性能问题。
独占模式 “不吐出已匹配字符” 的特性,会使得一些场景不能使用它。另外,只有少数编程语言支持独占模式。
示例3-店名匹配(其它优化版)
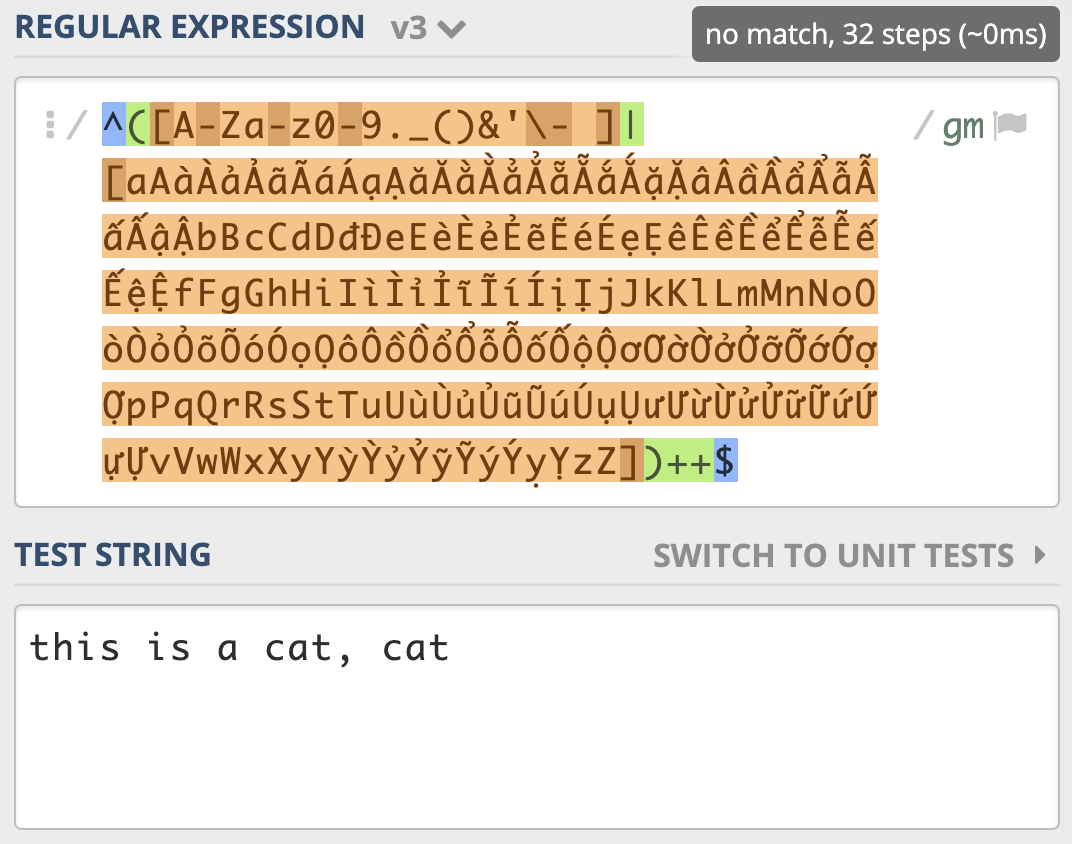
移除多选分支选择结构,直接用中括号表示多选一
正则测试
regex101.com的Regex Debugger
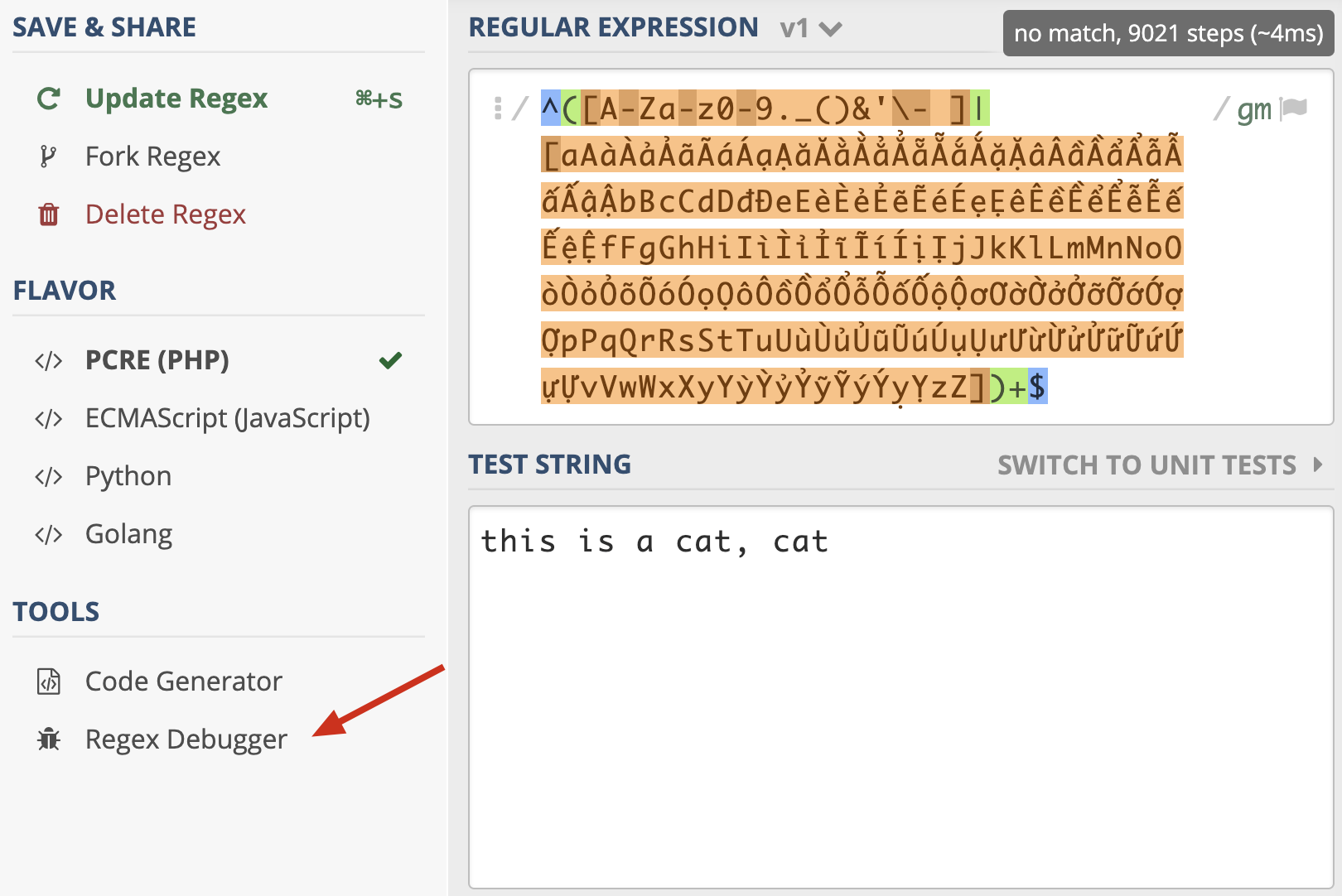

正则优化
1.测试性能的方法
通过前面 regex101.com 查看正则和文本匹配的次数,来得知正则的性能 信息
2.提前编译好正则
编译语言中一般都有“编译”方法,我们可以使用这个方法提前将正则处理好,这样不用在每次使用的时候去反复构造自动机,从而提高正则的性能。
3.尽量准确表示匹配范围
比如我们要匹配引号里面的内容,除了写成“.+?”之外,我们还可以写成"[^"]+ "。使
用 [^"] 要比使用点号好很多,虽然使用的是贪婪模式,但它不会出现点号将引号匹配上, 再吐出的问题。
4.提取出公共部分
通过上面对NFA引擎的学习,相信你应该明白(abcd|abxy)这样的表达式,可以优化成ab(cd|xy),因为NFA以正则为主导,会导致字符串中的某些部分重复匹配多次,影响效率。
5.出现可能性大的放左边
由于正则是从左到右看的,把出现概率大的放左边,域名中.com的使用是比.net多的,所以我们可以写成.(?:com|net)\b,而不是.(?:net|com)\b
6.只在必要时才使用子组
在正则中,括号可以用于归组,但如果某部分后续不会再用到,就不需要保存成子组。通常的做法是,在写好正则后,把不需要保存子组的括号中加上?:来表示只用于归组。如果保存成子组,正则引擎必须做一些额外工作来保存匹配到的内容,因为后面可能会用到,这会降低正则的匹配性能。
7.警惕嵌套的子组重复
如果一个组里面包含重复,接着这个组整体也可以重复,比如(.)这个正则,匹配的次数会呈指数级增长,所以尽量不要写这样的正则。
8.避免不同分支重复匹配
在多选分支选择中,要避免不同分支出现相同范围的情况,上面回溯的例子中,我们已经进行了比较详细的讲解。
标签:匹配,NFA,正则表达式,笔记,转义,括号,正则,模式 From: https://www.cnblogs.com/xiaochenNN/p/17309429.html