SDEdit


SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Contribution
- 引入新的图像合成和编辑方法Stochastic Differential Editing(SDEdit),通过随机微分方程(SDE)逆向求解生成图像
- 可以自然地在真实性(realism)和正确性(faithfulness)之间实现平衡
VE-SDE
- VE-SDE的采样过程(Reverse SED):
- 其中 \(\nabla _{\mathbf{x}}\log p_t\left( \mathbf{x} \right)\) 可用得分函数 \(\boldsymbol{s}_{\boldsymbol{\theta }}\left( \mathbf{x}\left( t \right) ,t \right)\) 来逼近,训练 \(\boldsymbol{s}_{\boldsymbol{\theta }}\left( \mathbf{x}\left( t \right) ,t \right)\) 拟合 \(\nabla _{\mathbf{x}}\log p_t\left( \mathbf{x} \right)\)
- 目标函数为:\[\begin{equation}L_t=\mathbb{E}_{\mathbf{x}\left( 0 \right) \sim p_{\text{data}},\mathbf{z}\sim \mathcal{N}\left( 0,\mathbf{I} \right)}\left[ \lVert \sigma _t\boldsymbol{s}_{\boldsymbol{\theta }}\left( \mathbf{x}\left( t \right) ,t \right) -\mathbf{z} \rVert _{2}^{2} \right]\end{equation} \]
- 随后用Euler-Maruyama方法近似SDE的解:\[\begin{equation}\mathbf{x}\left( t \right) =\mathbf{x}\left( t+\Delta t \right) +\left( \sigma ^2\left( t \right) -\sigma ^2\left( t+\Delta t \right) \right) \boldsymbol{s}_{\boldsymbol{\theta }}\left( \mathbf{x}\left( t \right) ,t \right) +\sqrt{\sigma ^2\left( t \right) -\sigma ^2\left( t+\Delta t \right)}\mathbf{z,\ \ z}\sim \mathcal{N}\left( 0,\mathbf{I} \right)\end{equation} \]
- 选择一个特定的离散化小量 \(\Delta t\),从 \(\mathbf{x}\left( 1 \right) \sim \mathcal{N}\left( 0,\sigma ^2\left( 1 \right) \mathbf{I} \right)\) 以及上面的近似解不断迭代生成 \(\mathbf{x}\left( 0 \right)\)
Guided Image Synthesis and Editing with SDEdit
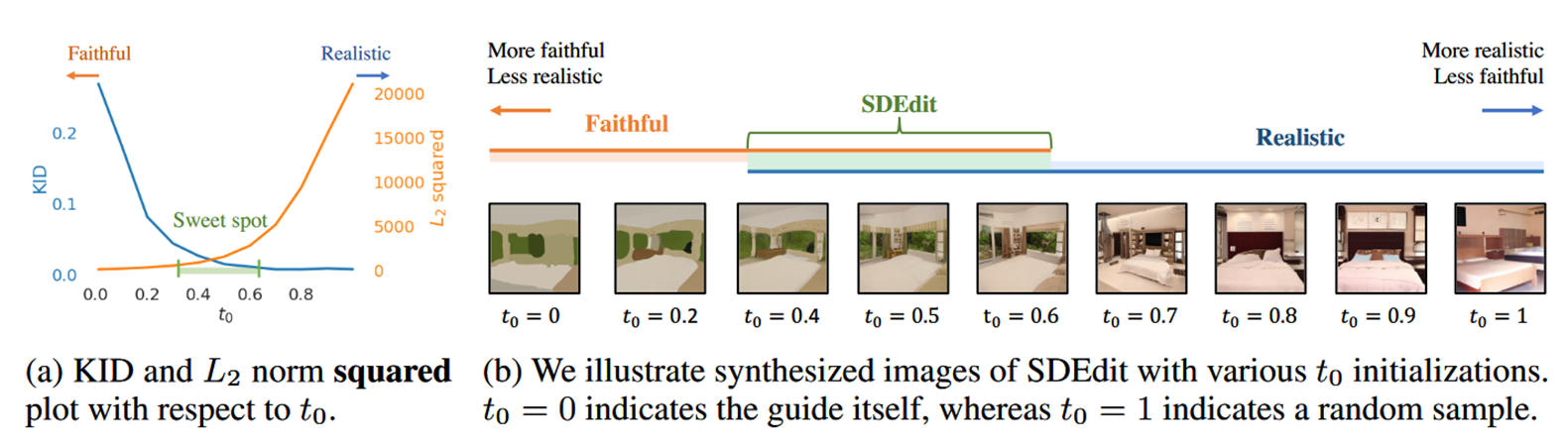
- 任务:两个desiderata——真实性Realism(通过Kernel Inception Score,KID评估),正确性Faithfulness(通过L2 distance评估)
- SDEdit“劫持”(hijack)了生成过程:
- 先加噪(Preturb with SDE)——添加适量的噪声以平滑不良的伪影和畸变(例如笔画像素处的不自然细节),同时仍保留输入用户指南的整体结构
- 再去噪(Reverse SDE)
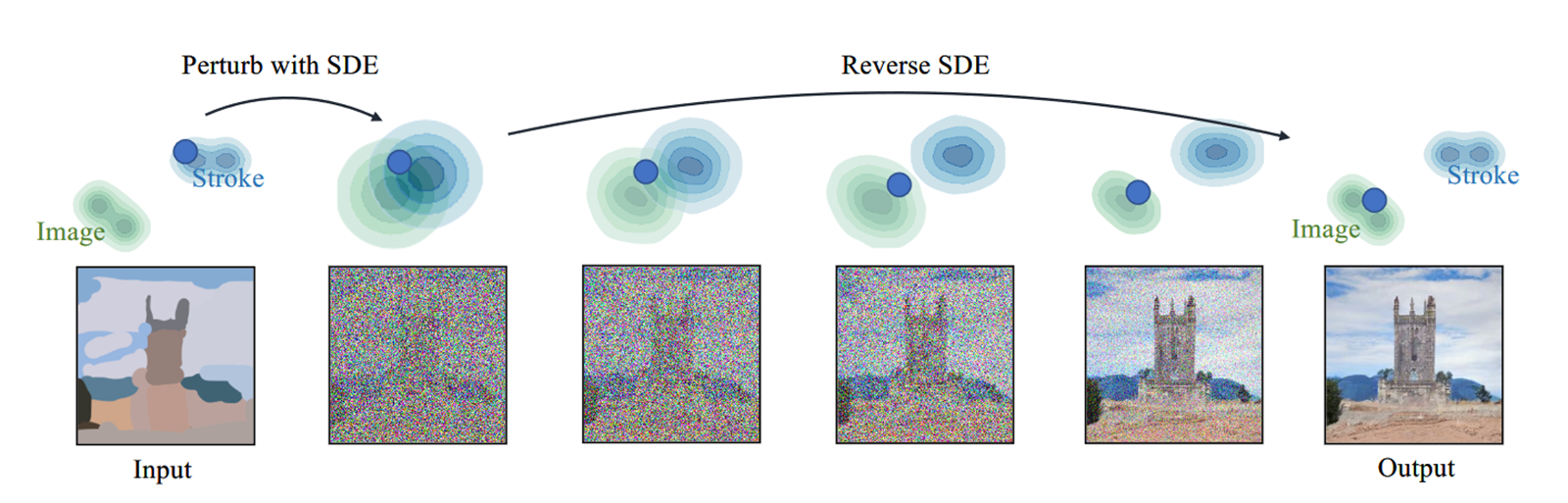
- SDEdit指出需要选择恰当的时间 \(t_0\) 采样,作为起点进行Reverse SDE,而非固定从 \(t=1\) 开始:\[\begin{equation}\begin{aligned}\mathbf{x}^{\left( g \right)}\left( t_0 \right) \sim &\mathcal{N}\left( \mathbf{x}^{\left( g \right)};\sigma ^2\left( t_0 \right) \mathbf{I} \right)\\\mathbf{x}\left( t \right) =\mathbf{x}\left( t+\Delta t \right) +&\left( \sigma ^2\left( t \right) -\sigma ^2\left( t+\Delta t \right) \right) \boldsymbol{s}_{\boldsymbol{\theta }}\left( \mathbf{x}\left( t \right) ,t \right) +\sqrt{\sigma ^2\left( t \right) -\sigma ^2\left( t+\Delta t \right)}\mathbf{z,\ \ z}\sim \mathcal{N}\left( 0,\mathbf{I} \right)\end{aligned} \end{equation} \]

- 经验显示 \(t_0\in \left[ 0.3,\ 0.6 \right]\) 效果较好。当然也可以根据具体任务微调,可以由用户选择“更真实”还是“更正确”,再用二分搜索确定 \(t_0\)
Experiments
- SDEdit本身并没有文本引导的功能,它支持的是简笔画(Given stroke input)或在图像上用简笔画做修改(Stroke-based image editing)


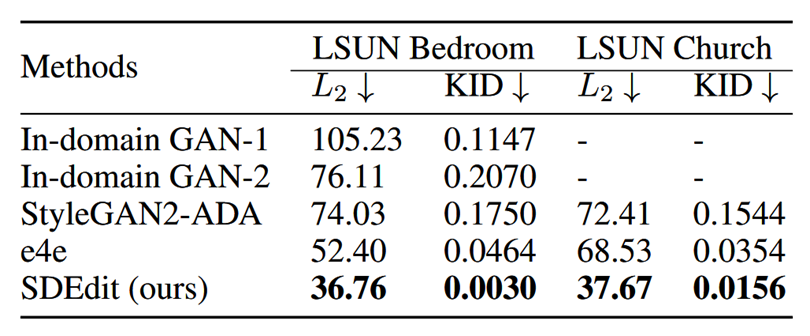
- 论文将SDEdit与当时SoTA的图像编辑方法进行了比较。SDEdit大大提高了对guide信息的忠诚性,同时生成的图片也更满足真实性。
Glide
DreamBooth

DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Contribution
- 将生成对象与唯一的文本标识符绑定
- 只要3~5张图像用于微调,而不会发生语言漂移或过拟合的现象
Personalization of Text-to-Image Models
- 将输入图像标记为:“a [identifier] [class noun]”
- [class noun]是图像中主题的大类,例如dog,由用户提供或来自分类器
- [identifier]是专门为图像中生成对象分配的唯一标识符,例如[V],为相对稀有的标识符
- 在词汇表中查找稀有标识符序列 \(f\left( \hat{V} \right)\) ,其中 \(f\) 是将字符序列映射到标记的tokenizer, \(\hat{V}\) 是从 \(f\left( \hat{V} \right)\) 解码的文本
- 找到 \(f\left( \hat{V} \right)\) 后反解出 \(\hat{V}\) 得到稀有标识符的字符序列
- 有些模型的文本条件使用CLIP,而DreamBooth使用的则是预训练的T5-XXL语言模型,其获取稀有标识符的具体过程为:
- 学习分词器 \(f\)
- 用 \(f\) 对提示 \(\mathbf{P}\) 进行分词,得到定长向量 \(f(\mathbf{P})\)
- 产生一个嵌入 \(\mathbf{c}_{\text{pr}}:=\Gamma \left( f\left( \mathbf{P} \right) \right) \) 作为文本条件
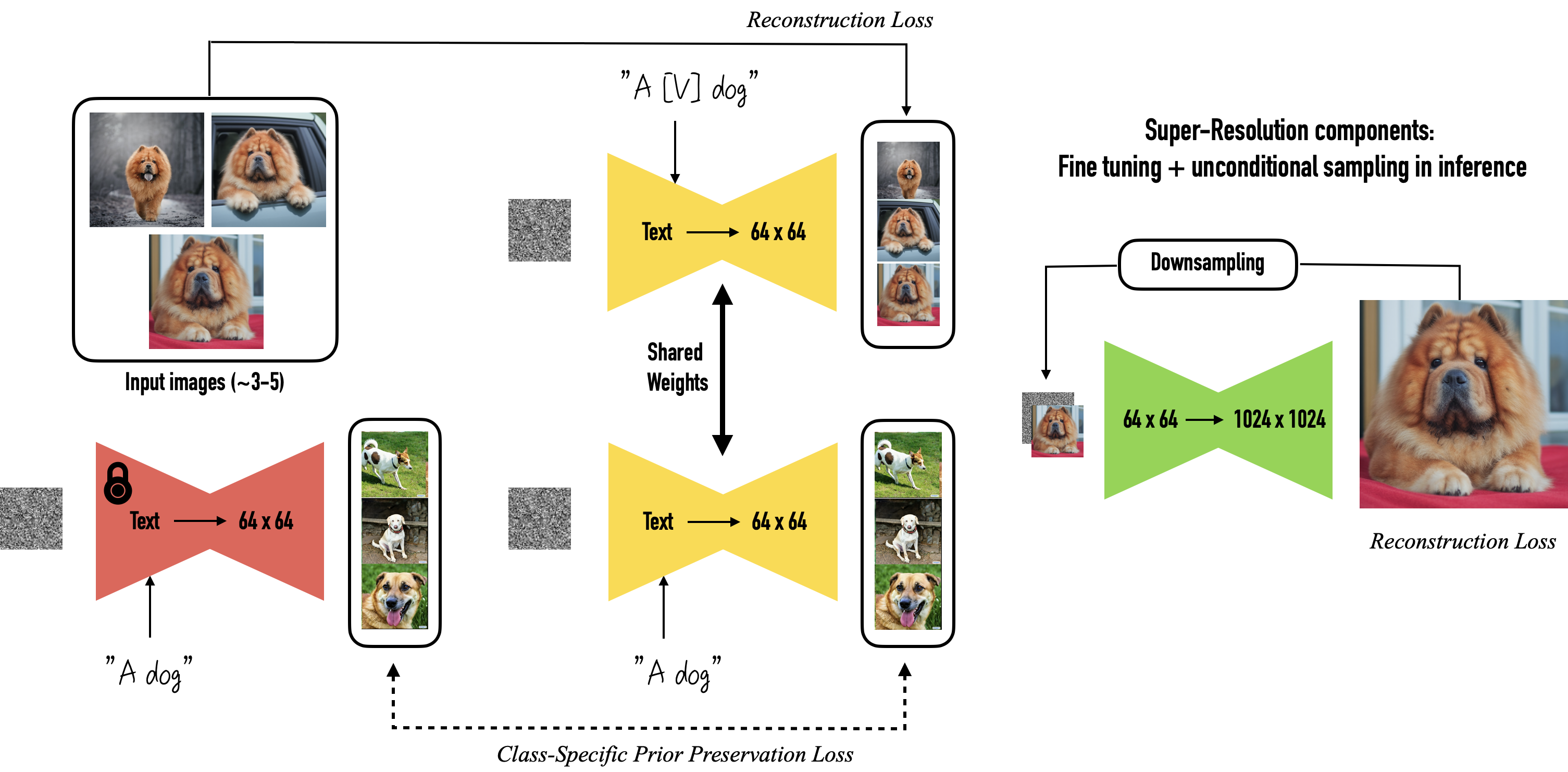
Class-specific Prior Preservation Loss
-
DreamBooth微调使用的图像只有3~5张,且这些图像中 [identifier] 和 [class noun] 总是绑定地出现,如果直接做微调会导致语言漂移和过拟合的问题:
- 微调整个模型,这包括了依赖文本嵌入的层,会造成语言漂移的现象,即逐渐忘记如何生成与目标生成对象相同类别的对象,以及忘记如何生成正确的反射、光影等效果
- 输入图像集过小导致会导致过拟合,减少输出的多样性。例如输入图像只有一种姿势,那么输出图像也可能只有这一种姿势
-
论文设计了一个Prior Preservation Loss(PPL),来对抗上述问题。这个loss利用类的先验知识,鼓励扩散模型不断生成与所给图像主题相同类别的不同实例,本质上就是用模型自己生成的样本来监督模型样本,以便在小样本微调时保留先验
-
加入了PPL后的损失函数为:
\[\begin{equation}\begin{aligned}\mathbb{E}_{\mathbf{x,c,\epsilon ,\epsilon }^{'},t}\big{[}w_t&\lVert \mathbf{\hat{x}}_{\mathbf{\theta }}\left( \alpha _t\mathbf{x}+\sigma _t\mathbf{\epsilon ,c} \right) -\mathbf{x} \rVert _{2}^{2}+\\ &\lambda w_{t^{'}}\lVert \mathbf{\hat{x}}_{\mathbf{\theta }}\left( \alpha _{t^{'}}\mathbf{x}_{\text{pr}}+\sigma _{t^{'}}\mathbf{\epsilon }^{'},\mathbf{c}_{\text{pr}} \right) -\mathbf{x}_{\text{pr}} \rVert _{2}^{2}\big{]}\end{aligned}\end{equation} \]- \(\mathbf{x}_{pr}=\mathbf{\hat{x}}\left( \mathbf{z}_{t_1},\mathbf{c}_{pr} \right)\) 是冻结的预训练模型生成的数据,其中 \(\mathbf{z}_{t_1}\sim \mathcal{N}\left( 0,\mathbf{I} \right)\) 为随机采样的噪声,\(\mathbf{c}_{\text{pr}}\:=\Gamma \left( f\left(\text{a\,\,}\left[ class\ noun \right] \text{"} \right) \right)\) 是条件向量
Inference
- DreamBooth包括三个模型:
- Text-to-Image Model输出64×64的图像
- 两个文本条件的超分辨模型分别将图像从64×64超分辨至256×256,从256×256超分辨至1024×1024
- 超分辨模型会虚构一些高频细节,可能是因为不熟悉生成对象的细节与纹理,需要进行微调
- 降低64×64→256×256模型的噪声水平是很有必要的,可以减少高分辨率下的模糊
- 对于一些情况下,微调256×256→1024×1024有助于生成更高水平粒度的细节
Evaluation Metrics
- DreamBooth通过CLIP-I和DINO来评价生成图像与输入所给主题的一致性(Subject fidelity),通过CLIP-T来评价生成图像与文本提示的一致性(Prompt fidelity)
- CLIP-I是生成图像和所给图像CLIP嵌入之间的平均余弦相似度。论文指出它并不能很好地区分高度相似的文本描述的不同主题(例如,两个不同的黄色时钟)
- 论文提出了DINO指标,它是生成图像和所给图像ViT-S/16 DINO嵌入之间的平均余弦相似度。这是论文评价生成图像的首选指标,因为与监督网络相比,DINO不会忽略同一类别生成对象之间的差异。相反,自监督训练鼓励区分不同生成对象的独特特征
- CLIP-T则是文本提示和生成图像CLIP嵌入之间的平均余弦相似度
Comparisons
- 因为微调只需要3~5张图像,DreamBooth可以在Imagen和Stable Diffusion上迁移
- DreamBooth(Imagen)更接近实际图像的subject fidelity上限,这可能是因为Imagen具有更大的表达能力和更高的输出质量
- 与Textual Inversion(Stable Diffusion)相比,DreamBooth(Stable Diffusion)在subject fidelity和prompt fidelity两个方面都有压倒性的优势
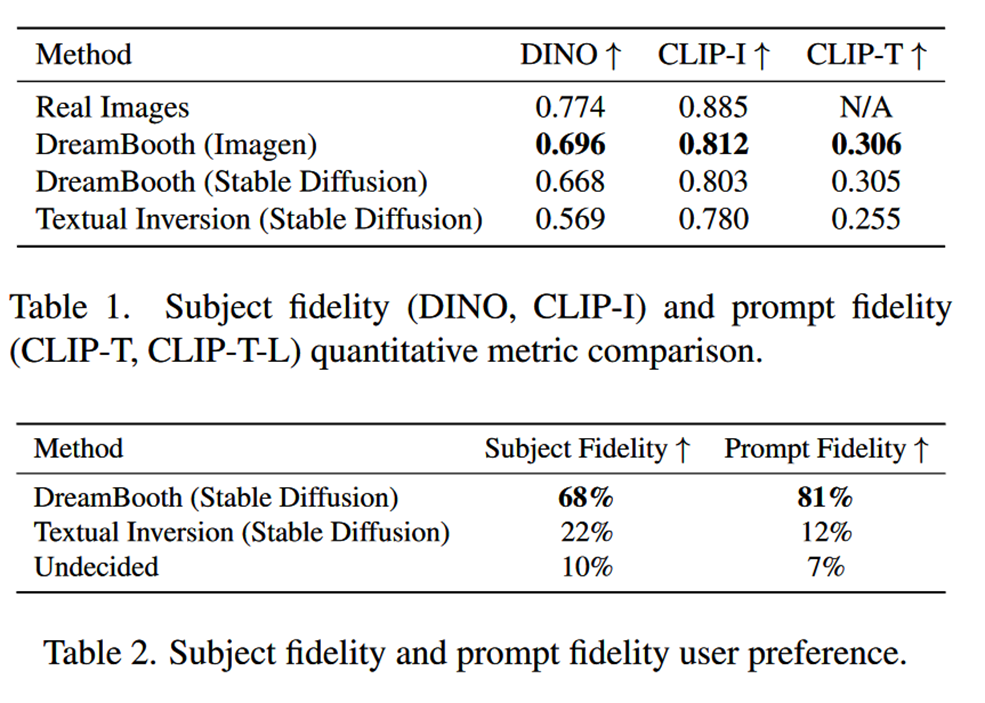
Ablation Studies
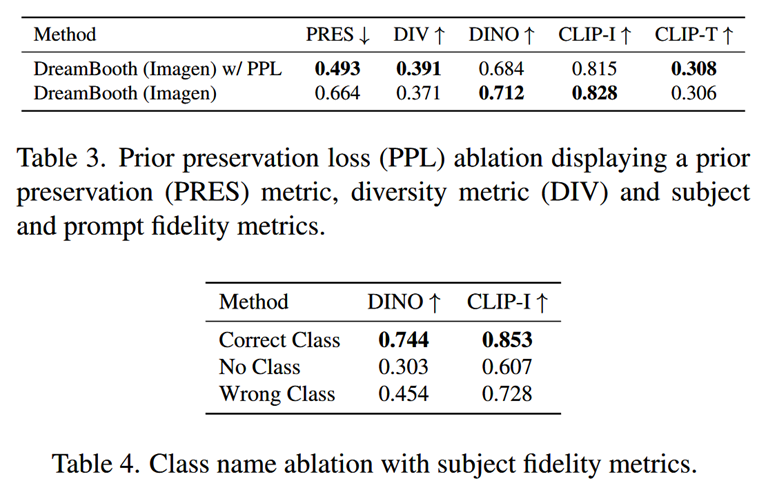
- 首先论文研究了Prior Preservation Loss的作用:
- 先验保留度量PRES计算了来自先验类别的生成图像和输入特定主题的真实图像之间的平均DINO嵌入:该度量越高,生成图像与输入特定对象的相似性就越高,表示先验崩溃。实验发现,PPL显著抵消了语言漂移的现象,同时实现了更高的多样性(如,姿势),而代价仅仅是稍微降低了一点subject fidelity

- 此外论文还做了类先验消融实验:
- 使用正确的类名:能够忠实地适应主题,利用类先验,在各种情境下生成我们的主题
- 使用错误的类名(例如“罐头”用于背包):会遇到主题和类先验之间的争议
- 不使用类名:模型无法利用类先验,难以学习主题并收敛,并可能生成错误的样本
Applications
- 重新语境化(Recontextualization)
- 文本引导视角合成(Text-guided View Synthesis)
- 艺术演绎(Art Renditions)
- 属性修改(Property Modification)
参见https://dreambooth.github.io/
Limitations
- 由于先验知识不足,DreamBooth可能会做错误的上下文合成(如空间站上或月球上的包)
- 如果文字提示对应的先验大多具有不同的外观,那么生成图像的语境与外观会发生纠缠,改变外观的样式
- 提示与所给图像的场景相似,DreamBooth依旧逃不掉过拟合的问题
- 对于一些较为罕见的主题,DreamBooth无法支持过多的变体,例如姿态等变化不够多样,不能很好地适应新的语境
- 不同生成对象的fidelity不同,有些生成对象的保真性不好

InstructPix2Pix

InstructPix2Pix: Learning to Follow Image Editing Instructions
Contribution
- 整合GPT-3和Stable Diffusion来生成数据集
- 解决了编辑指令不直接、不确定的问题
- 条件扩散模型,Classifier-free
Generating Instructions and Paired Captions
- 首先收集了700条图像描述样本,然后手动编写了编辑指令和输出图像描述,构成700组训练数据三元组(human-written dataset of editing triplets),包含:输入的图像描述(Input LAION caption),编辑指令(Edit instruction)和输出的图像描述(Edited caption)
- 微调后的GPT-3接收Input LAION caption,可以自行生成Edit instruction和Edited caption
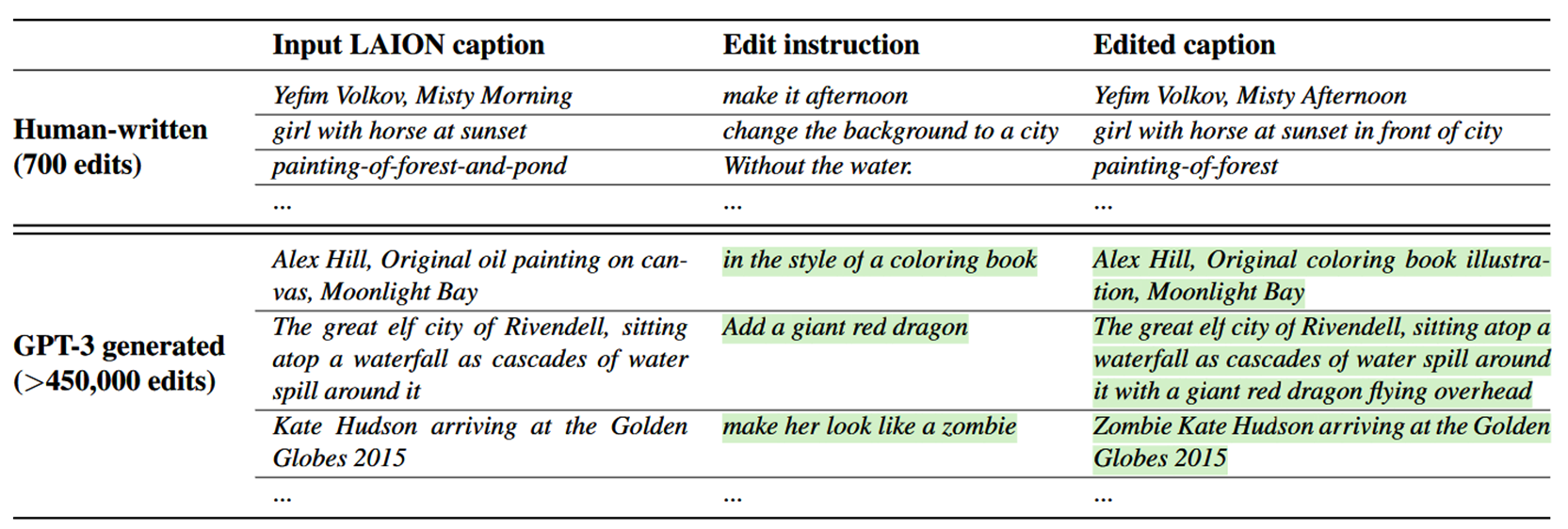
Generating Paired Images from Paired Captions
- Input LAION caption和由GPT-3生成的Edited caption组成一对说明文字(a pair of captions)
- 使用Stable Diffusion将这两个文本提示(a pair of captions)转换成一对相应的图像(a pair of images)
- 单纯使用SD生成的图像,无法保证图像内容的一致性:即使Prompt非常相近,两张图像也可能相差很远,无法构成paired的需求
- InstructPix2Pix使用Prompt-to-Prompt方法来完成操作:Prompt-to-Prompt通过在去噪过程中使用交叉注意力权重,可以针对一个文本生成多代近似的图像,且这些图像彼此之间含有相同的身份信息,从而保证生成图像的一致性。

Training a conditional diffusion model
-
基于Stable Diffusion模型,本质是隐空间扩散模型(Latent Diffusion)。Latent Diffusion通过在带有编码器 \(E\) 和解码器 \(D\) 的VAE的隐空间中运行来提高扩散模型的效率和质量。对于一个图像 \(x\) ,扩散过程将噪声添加到编码的隐层向量 \(z=\mathcal{E}(x)\) 中,产生一个噪声隐变量 \(z_t\) ,其中噪声等级随时间步数 \(t\in T\) 而增加
-
训练一个网络 \(\epsilon _{\theta}\) ,它可以预测在给定的图像条件 \(c_I\) 和文本指令条件 \(c_T\) 下添加到噪声隐变量 \(z_t\) 中的噪声信息
-
训练的目标函数:
\[\begin{equation} L=\mathbb{E}_{\mathcal{E}\left( x \right) ,\mathcal{E}\left( c_I \right) ,c_T,\epsilon \sim \mathcal{N}\left( 0,1 \right) ,t}\left[ \lVert \epsilon -\epsilon _{\theta}\left( z_t,t,\mathcal{E}\left( c_I \right) ,c_T \right) \rVert _{2}^{2} \right]\end{equation} \] -
使用预训练的Stable Diffusion对模型进行初始化,为了赋予其图像编辑的能力,InstructPix2Pix在模型的第一个卷积层中增加额外的条件输入通道
-
InstructPix2Pix使用的是Classifier-free Guidance的策略。Classifier-free Guidance的隐式分类器 \(p_\theta(c|z_t)\) 会将更高的可能性分配给条件 \(c\) ,需要同时训练有条件和无条件去噪的两个扩散模型,并在推理时结合两个分数进行估计
-
这里的条件包括 \(c_I\) 和 \(c_T\),通过设计评分网络,要使InstructPix2Pix能够针对两个或任一条件输入进行有条件或无条件的去噪:
\[\begin{equation}\begin{aligned} \tilde{e}_{\theta}\left( z_t,c_I,c_T \right) =&\:e_{\theta}\left( z_t,\varnothing ,\varnothing \right)\\ &+s_I\cdot \left( e_{\theta}\left( z_t,c_I,\varnothing \right) -e_{\theta}\left( z_t,\varnothing ,\varnothing \right) \right)\\ &+s_T\cdot \left( e_{\theta}\left( z_t,c_I,c_T \right) -e_{\theta}\left( z_t,c_I,\varnothing \right) \right)\\ \end{aligned}\end{equation}\] -
两个指导尺度 \(s_I\) 和 \(s_T\) 分别调整生成的样本对输入图像于编辑指令的遵循程度

Baseline comparisons
- 与SDEdit和Text2Live定性比较
- SDEdit在内容大致不变,改变风格的情况下效果还不错,但会丢失图像主体的一部分身份信息
- Text2Live能够产生真实度比较高的结果,但它基于生成颜色和透明度层进行图像编辑的算法限制了它能够处理的编辑类型
- 与InstructPix2Pix不同的是,SDEdit和Text2Live都需要更加完整的文本描述

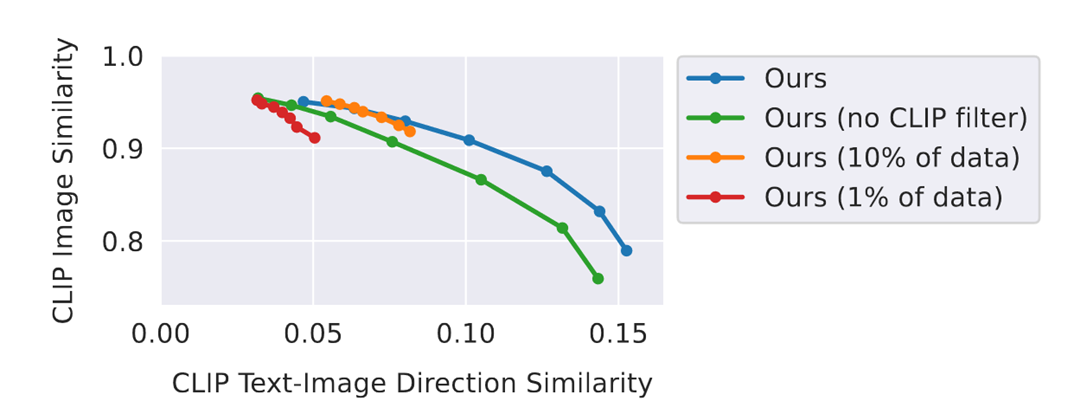
- 与SDEdit定量比较
- 在取得同样的文本一致性的条件下,InstructPix2Pix更加忠于原图
- 横轴:生成图像与指令文本的定向CLIP嵌入相似度(刻画生成图像与文本的一致性)
- 纵轴:生成图像与输入图像之间的CLIP嵌入余弦相似度(刻画生成与输入图像间的一致性)
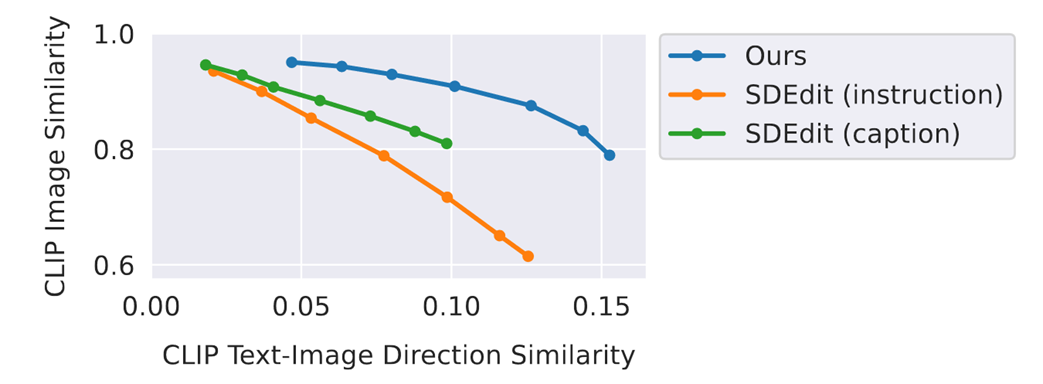
Ablations
- 减小数据集的大小:图像编辑能力下降,只能进行细微的或风格上的调整
- 删除CLIP过滤:生成图像与输入图像的整体一致性降低
- LAION数据集非常嘈杂,包含许多毫无意义或不相关的描述文本,需要利用CLIP对其进行过滤
- 增加 \(s_T\) :对图像做更强的编辑,更符合文本指示
- 增加 \(s_I\) :更倾向于保留输入图像的空间结构,更加忠于原图

Discussion
- 在计数和空间推理相关的问题上表现不是很好
- 使用了GPT-3和Stable Diffusion,因此也继承了这些预训练大模型的偏见

- 论文也给出了一系列可能的改进点:空间推理、用户交互、评估基于指令的图像编辑
- 将人类反馈纳入模型(如ChatGPT的RLHF)以改进其性能是未来工作的另一个重要领域