更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
当一家公司的日均处理的数据流量在 PB 级别时,巨大的任务量和数据量会对消息队列(MQ)dump 的稳定性和准确定带来极大的挑战。
针对这一问题,火山引擎数智平台推出的大数据研发治理套件 DataLeap,可以为企业提供完整解决方案,帮助解决 MQ dump 在极端场景中遇到的数据丢失问题。
例如,当 HDFS(一种分布式文件系统)集群某个元数据节点由于硬件故障而宕机。那么在该元数据节点终止半小时后,运维工程师虽然可以通过手动运维操作将 HDFS 切到主 backup 节点,使得 HDFS 恢复服务。但故障恢复后, MQ dump 在故障期间可能有数据丢失,产出的数据与 MQ 中的数据不一致的情况。
此时,技术人员可以在收到数据不一致的反馈后,立即借助火山引擎 DataLeap 进行故障排查。
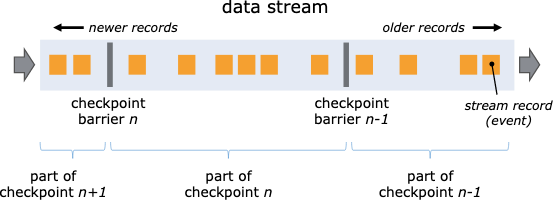
目前,火山引擎 DataLeap 基于开源 Flink,已经实现了流批一体的数据集成服务。通过 Flink Checkpoint 的功能,Flink 在数据流中注入 barriers 将数据拆分为一段一段的数据,在不终止数据流处理的前提下,让每个节点可以独立创建 Checkpoint 保存自己的快照。
每个 barrier 都有一个快照 ID ,在该快照 ID 之前的数据都会进入这个快照,而之后的数据会进入下一个快照。
在排查过程中,火山引擎 DataLeap 基于对 Flink 日志查看以及 HDFS 元数据查看,可以率先定位症结所在:删除操作的重复执行造成数据丢失。进一步解释就是,在故障期间,写入数据前的删除操作在 HDFS NameNode 上重复执行,将写入的数据删除造成最终数据的丢失。
溯源后,用户可以通过火山引擎 DataLeap 选择使用文件 State(当前的 Checkpoint id 和 task id)解决该问题,使用文件 State 前后处理流程对比如下图所示:
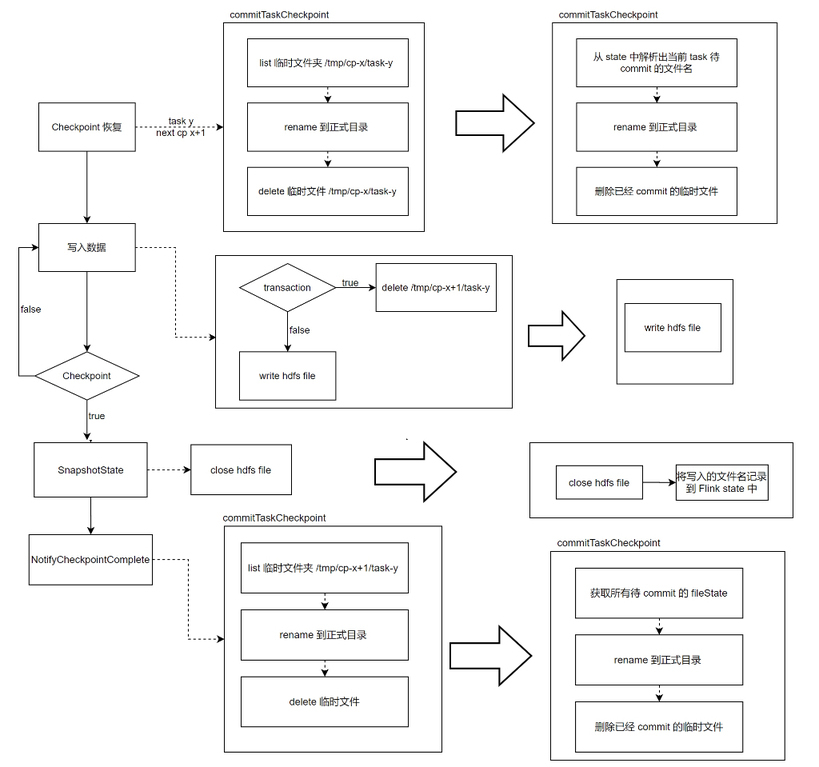
使用文件 State 后,在 Notify 阶段与 HDFS 交互的 metrics(打点监控系统)的平均处理时间减少了一半。
目前,企业均可以通过火山引擎 DataLeap 体验到上述 Flink Checkpoint 实践与优化方案,提升数据价值交付中的效率和质量。
点击跳转 大数据研发治理DataLeap 了解更多
标签:HDFS,快照,解决方案,Flink,排查,引擎,DataLeap,数据 From: https://www.cnblogs.com/bytedata/p/17276204.html