背景
近期发现自己实验用的 Prometheus 性能出现瓶颈, 经常会出现如下告警:
PrometheusMissingRuleEvaluationsPrometheusRuleFailures
之后慢慢排查发现是由于 Prometheus 的某些 series 的高基数(High Cardinality)导致的. 本文是对 Prometheus 高基数问题的一次全面总结.
什么是基数(Cardinality)?
基数的基本定义是指一个给定集合中的元素的数量。
在Prometheus和可观察性的世界里,标签基数是非常重要的,因为它影响到你的监控系统的性能和资源使用。
下面这张图, 可以清晰地反应基数的重要性:
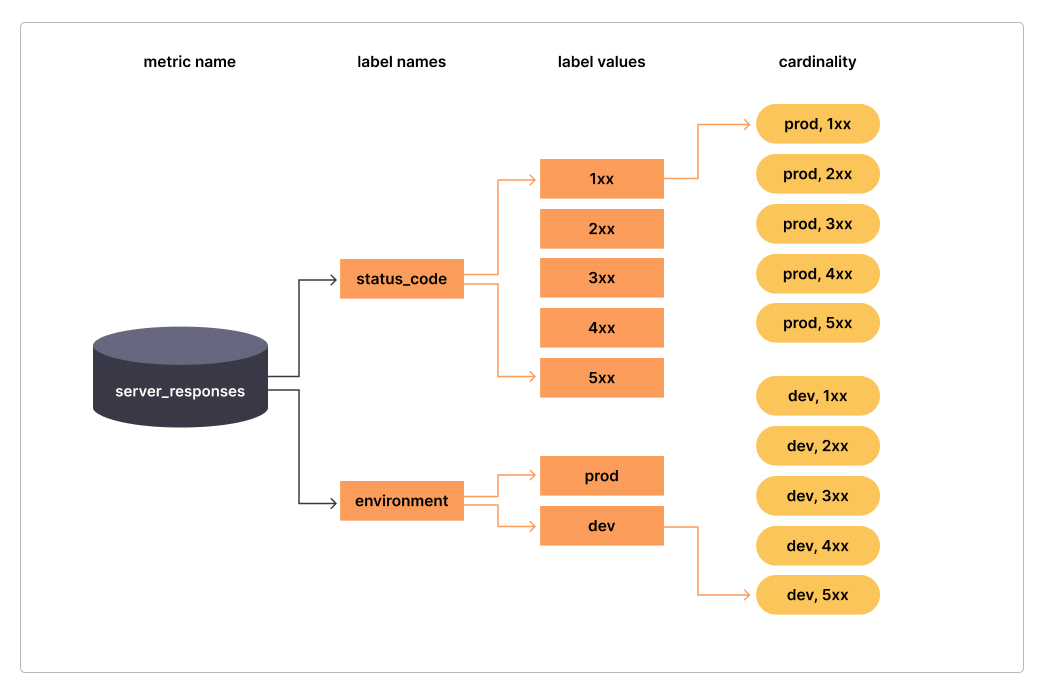
简单地说。基数 是指一个标签的总体数值的计数。在上面的例子中,标签status_code的基数是5,(即:1xx 2xx 3xx 4xx 5xx),environment的基数是2(即prod dev),而指标server_responses的总体基数是10。
多少算高基数?
一般来说:
- 较低的基数 1:5的标签值比率,
- 标准基数 1:80的标签值比率
- 高基数 1:10000的标签值比率。
还是上面的例子, 如果 status_code 是详细的code, 如200 404..., 那它的基数就可能高达数百个, environment的基数再多一些, 指标server_responses的总体基数就会迅速膨胀.
高基数的典型案例
这还不够形象, 再举 2 个特别典型的例子:
- 有一个指标叫做:
http_request_duration_seconds_bucket- 它有
instancelabel, 对应 100 个实例; - 有
lelabel, 对应的是不同的 buckets, 有 10 个 buckets, 如(0.0020.0040.008...=+inf) - 它还有
url这个 label, 对应的是不通的 url:- 即使规模很小, url 可能也会有 400 个 url
- 这里还有个特别恐怖的隐患, 就是对于大规模系统来说, 这个 url 可能是近乎于无穷!!!
- 它还有
http_method这个label, 对应有 5 个 http method - 在这种情况下, 该指标的 label
- 它有