目录
1 背景
在我们实际的开发过程中,我们的某些数据可能经常使用,但是过了一段时间,这个数据就不怎么使用了,即我们的数据存在一个热、温、冷等这些特性。那么针对数据的热度,我们可以采用不同的策略,存储到不同的存储介质上。
比如:
- 针对经常访问的数据,我们可以存储在
SSD上。 - 针对访问频率不高的,我们可以存储在
DISK,即普通的硬盘上。 - 针对几乎不会访问的数据,保存在归档介质上。
注意:那么hdfs自己知道哪些数据是热数据,哪些数据是冷数据吗,貌似是不知道的,需要我们自己去判断。
2 hdfs异构存储类型和存储策略
2.1 hdfs支持的存储类型
hdfs支持如下4中存储类型
ARCHIVE:它具有高存储密度(PB级存储)但计算能力弱,一般用于归档文件的存储。DISK :普通磁盘,默认的存储类型SSD :SSD固态硬盘RAM_DISK:支持在内存中写入单个副本文件

2.2 hdfs如何知道数据存储目录是那种存储类型
hdfs是不会自动检测我们指定的数据存储目录是何种存储类型的,需要我们在配置的时候告诉hdfs。
指定目录的存储类型
vim hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///var/hadoop/dfs/data1,[DISK]file:///var/hadoop/dfs/data2</value>
</property>
从上面的配置中可以 /var/hadoop/dfs/data1前面指定了[SSD],则说明data1 这个目录是一个 SSD的存储介质,但是具体是不是真的SSD类型,这个是不会去校验的。

2.3 存储策略
2.3.1 在hdfs中支持如下存储策略
Hot:用于存储和计算。当我们的数据是热数据时,可以使用这种存储策略,所有的副本都在DISK中。Warm:仅适用于计算有限的存储。不再使用的数据或需要归档的数据从热存储移动到冷存储。当一个块冷时,所有副本都存储在ARCHIVE中。Cold:部分热和部分冷。当一个块是热的时,它的一些副本存储在DISK中,其余的副本存储在ARCHIVE中。All_SSD:用于将所有副本存储在SSD中。One_SSD:用于将其中一个副本存储在SSD中。其余副本存储在DISK中。Lazy_Persist:用于在内存中写入具有单个副本的块。副本首先用RAM_DISK写入,然后懒惰地保存在DISK中。Provided:用于在HDFS之外存储数据

2.3.2 存储策略表

2.3.4 Storage Policy Resolution
创建文件或目录时,未指定其存储策略。可以使用storagePolicy -setStoragePolicy命令指定存储策略。文件或目录的有效存储策略由以下规则解析。
- 如果文件或目录指定了存储策略,则返回它。
- 对于未指定的文件或目录,如果是根目录,则返回默认存储策略。否则,返回其父级的有效存储策略。
有效的存储策略可以通过storagePolicy -getStoragePolicy命令检索。
2.3.5 配置存储策略
dfs.storage.policy.enabled用于启用或禁止存储策略特性,默认值是truedfs.datanode.data.dir在每个数据节点上,逗号分隔的存储位置应标记其存储类型。这允许存储策略根据策略将块放置在不同的存储类型上。
举例说明
- 如果一个datanode 上的存储位置
/grid/dn/disk0是DISK类型,应该配置为[DISK]file:///grid/dn/disk0 - 如果一个datanode 上的存储位置
/grid/dn/disk0是SSD类型,应该配置为[SSD]file:///grid/dn/disk0 - 如果一个datanode 上的存储位置
/grid/dn/disk0是ARCHIVE类型,应该配置为[ARCHIVE]file:///grid/dn/disk0
如果
没有显式标记的存储类型,则datanode存储位置的默认存储类型将是DISK。
2.3.6 基于存储策略的数据移动
在已经存在的文件/目录上设置新的存储策略将改变命名空间中的策略,但它不会在存储介质之间物理移动块。
此处介绍基于Mover来解决这个问题,具体的细节需要看官方文档。

2.3.7 存储策略命令
2.3.7.1 列出所有存储策略
hdfs storagepolicies -listPolicies
2.3.7.2 为文件或目录设置存储策略
hdfs storagepolicies -setStoragePolicy -path <path> -policy <policy>
<path>:需要设置存储策略的文件或目录
<policy>:存储策略的名字
2.3.7.3 取消存储策略
hdfs storagepolicies -unsetStoragePolicy -path <path>
取消对文件或目录的存储策略设置。在unset命令之后,将应用最近祖先的存储策略,如果没有任何祖先的策略,则将应用默认存储策略。
2.3.7.4 获取文件或目录的存储策略。
hdfs storagepolicies -getStoragePolicy -path <path>
2.3.7.5 查看文件块分布
hdfs fsck xxx -files -blocks -locations
3 hdfs异构存储案例
3.1 环境准备
| ip地址 | 节点名 | 存储类型 |
|---|---|---|
| 192.168.121.140 | hadoop01 | DISK,ARCHIVE |
| 192.168.121.141 | hadoop02 | DISK,SSD |
| 192.168.121.142 | hadoop03 | SSD,ARCHIVE |
3.2 节点 hdfs-site.xml配置文件
3.2.1 hadoop01
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 开启hdfs异构存储策略 -->
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<!-- 配置block块的存储目录,配置hdfds数据的存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///opt/bigdata/hadoop-3.3.4/data/disk,[ARCHIVE]file:///opt/bigdata/hadoop-3.3.4/data/archive</value>
</property>
3.2.2 hadoop02
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 开启hdfs异构存储策略 -->
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<!-- 配置block块的存储目录,配置hdfds数据的存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[DISK]file:///opt/bigdata/hadoop-3.3.4/data/disk,[SSD]file:///opt/bigdata/hadoop-3.3.4/data/ssd</value>
</property>
3.2.3 hadoop03
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 开启hdfs异构存储策略 -->
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<!-- 配置block块的存储目录,配置hdfds数据的存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///opt/bigdata/hadoop-3.3.4/data/ssd,[ARCHIVE]file:///opt/bigdata/hadoop-3.3.4/data/archive</value>
</property>
3.3 重启hdfs集群,并看数据目录存储类型是否正确
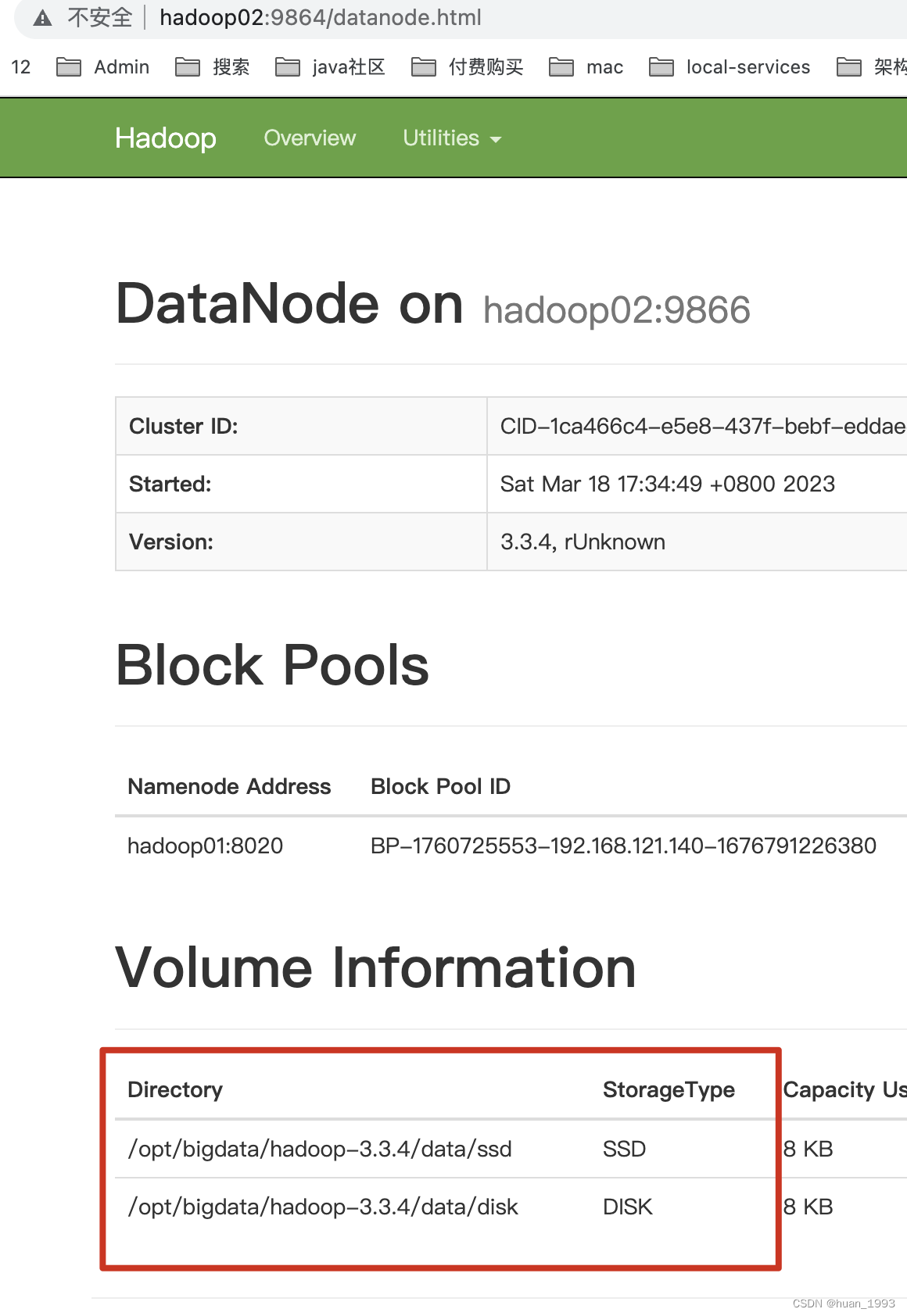
3.4 案例演示
此处仅仅只是演示 Warm类型。
由之前的存储策略表(2.3.2)可知,Warm类型的策略,只有一个块存储在DISK存储上,其余的全部存储在ARCHIVE存储上。
# hdfs 上创建目录
[hadoopdeploy@hadoop01 hadoop]$ hadoop fs -mkdir -p /var/data/storage
# 上传文件到 hdfs 目录中
[hadoopdeploy@hadoop01 hadoop]$ hadoop fs -put /etc/profile /var/data/storage/profile
# 设置 /var/data/storage 目录的存储策略为 warm
[hadoopdeploy@hadoop01 hadoop]$ hdfs storagepolicies -setStoragePolicy -path /var/data/storage -policy WARM
Set storage policy WARM on /var/data/storage
# 查看 /var/data/storage 目录的文件块分布,发现还是 2个 DISK,说明历史数据需要迁移,使用 mover 命令
[hadoopdeploy@hadoop01 hadoop]$ hdfs fsck /var/data/storage -files -blocks -locations
Connecting to namenode via http://hadoop01:9870/fsck?ugi=hadoopdeploy&files=1&blocks=1&locations=1&path=%2Fvar%2Fdata%2Fstorage
FSCK started by hadoopdeploy (auth:SIMPLE) from /192.168.121.140 for path /var/data/storage at Sat Mar 18 17:49:48 CST 2023
/var/data/storage <dir>
/var/data/storage/profile 2098 bytes, replicated: replication=2, 1 block(s): OK
0. BP-1760725553-192.168.121.140-1676791226380:blk_1073741858_1036 len=2098 Live_repl=2 [DatanodeInfoWithStorage[192.168.121.141:9866,DS-e86f80ba-6f04-4074-ab96-f58212c3c0e2,DISK], DatanodeInfoWithStorage[192.168.121.140:9866,DS-ca40e8cf-4d38-4a42-bfcb-e636087e9025,DISK]]
......
# 将 /var/data/storage 按照存储策略移动数据块
[hadoopdeploy@hadoop01 hadoop]$ hdfs mover /var/data/storage
2023-03-18 17:52:04,620 INFO mover.Mover: namenodes = {hdfs://hadoop01:8020=null}
2023-03-18 17:52:04,630 INFO balancer.NameNodeConnector: getBlocks calls for hdfs://hadoop01:8020 will be rate-limited to 20 per second
2023-03-18 17:52:05,368 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.121.142:9866
2023-03-18 17:52:05,368 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.121.140:9866
2023-03-18 17:52:05,368 INFO net.NetworkTopology: Adding a new node: /default-rack/192.168.121.141:9866
2023-03-18 17:52:05,402 INFO balancer.Dispatcher: Start moving blk_1073741858_1036 with size=2098 from 192.168.121.140:9866:DISK to 192.168.121.140:9866:ARCHIVE through 192.168.121.140:9866
2023-03-18 17:52:05,412 INFO balancer.Dispatcher: Successfully moved blk_1073741858_1036 with size=2098 from 192.168.121.140:9866:DISK to 192.168.121.140:9866:ARCHIVE through 192.168.121.140:9866
Mover Successful: all blocks satisfy the specified storage policy. Exiting...
2023-3-18 17:52:15 Mover took 10sec
# 重新查看 /var/data/storage 目录的文件块分布,发现还是 一个是 DISK 另外一个 ARCHIVE,说明存储策略生效了
pdeploy@hadoop01 hadoop]$ hdfs fsck /var/data/storage -files -blocks -locations
Connecting to namenode via http://hadoop01:9870/fsck?ugi=hadoopdeploy&files=1&blocks=1&locations=1&path=%2Fvar%2Fdata%2Fstorage
FSCK started by hadoopdeploy (auth:SIMPLE) from /192.168.121.140 for path /var/data/storage at Sat Mar 18 17:53:23 CST 2023
/var/data/storage <dir>
/var/data/storage/profile 2098 bytes, replicated: replication=2, 1 block(s): OK
0. BP-1760725553-192.168.121.140-1676791226380:blk_1073741858_1036 len=2098 Live_repl=2 [DatanodeInfoWithStorage[192.168.121.141:9866,DS-e86f80ba-6f04-4074-ab96-f58212c3c0e2,DISK], DatanodeInfoWithStorage[192.168.121.140:9866,DS-cf50253c-ea3f-46f6-bdd9-4ac1ad3907d2,ARCHIVE]]

4 参考文档
1、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/ArchivalStorage.html
2、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml