珂爱的dp们

区间dp
在 \(dp\) 的状态设计中,设计以区间为状态的 \(dp\)
或以区间为阶段进行的 \(dp\)即为区间 \(dp\) ,一般有最值问题和计数问题,一般方程为
或
\[f[l][r][...]=\min (f[l+1][r][...],f[l][r-1][...])+cost(l,r),(l \le k \le r) \]一般来说,最值问题多适用第一种,计数多适用第二种,同时,由于区间dp的特殊性,有时要用记忆化搜索来实现
板子题,但思想很重要,先考虑模拟题意,从小的范围开始。
例如 \(1,7,3,4\),我们可以先将\(7,3\)合并变为 \(1,10,4\),分析一下,发现 \(1,7,3,4\) 和 \(1,10,4\) 都可以看成一种互不干扰局面,进一步的可以发现 \(1,7,3,4\) 到 \(1,10,4\) 实际构成一种关系,\(1,7,3,4\) 能单向推到 \(1,10,4\) 且最值可能从 \(1,10,4\) 中得到,这正好是 \(dp\) 的关系,考虑 \(dp\),还有非常重要的一点,一步操作后 \(10\) 就是 \(3,7\) 得到的,即 \(10\) 代表了 \(3,7\)
发现一步本质上将两个区间合并成了一个区间,与第一类模型相符,套用第一个
以最小值为例
\[f[i][j]=\min\left\{f[i][k]+f[k+1][j]\right\}+cost(i,j)(l \le k \le r) \]其中 \(f[i][j]\) 为 \(i,j\) 区间合并成一个石子的最小代价,最后一定是由两个子区间合并而成,不妨枚举两个区间的分界点计算最小值。\(cost(i,j)\) 为将两个区间合并时的费用,考虑一个区间合并成一堆的石子数一定为区间中所有石子数之和,考虑前缀和,令 \(sum[i]\) 为 \(1\) 到 \(i\) 的所有石子数之和
\[cost(i,j)=sum[r]-sum[l-1] \]别忘了初始化,长度为 \(1\) 的区间为0
题中为一条环,可以考虑套路,将序列复制一次接在后面。
丑图奉上
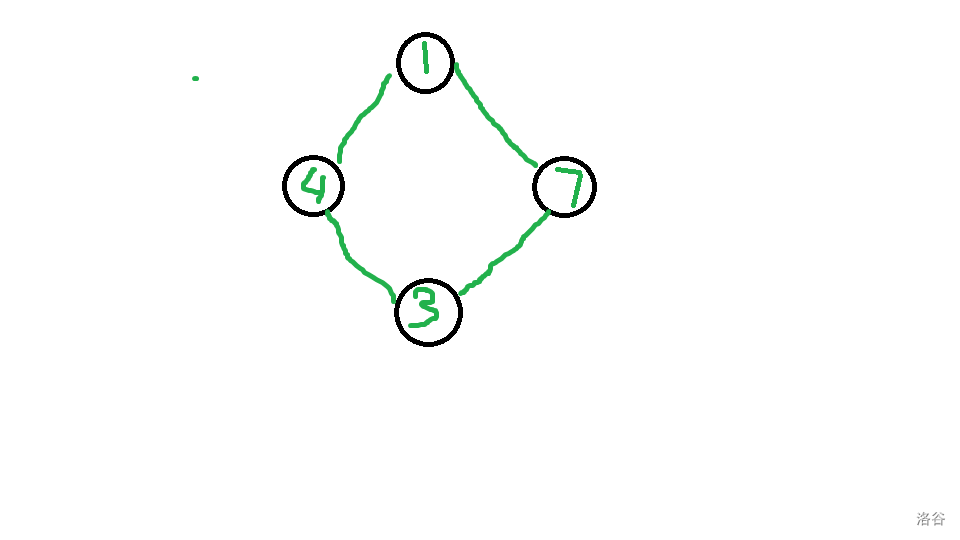
一开始的序列
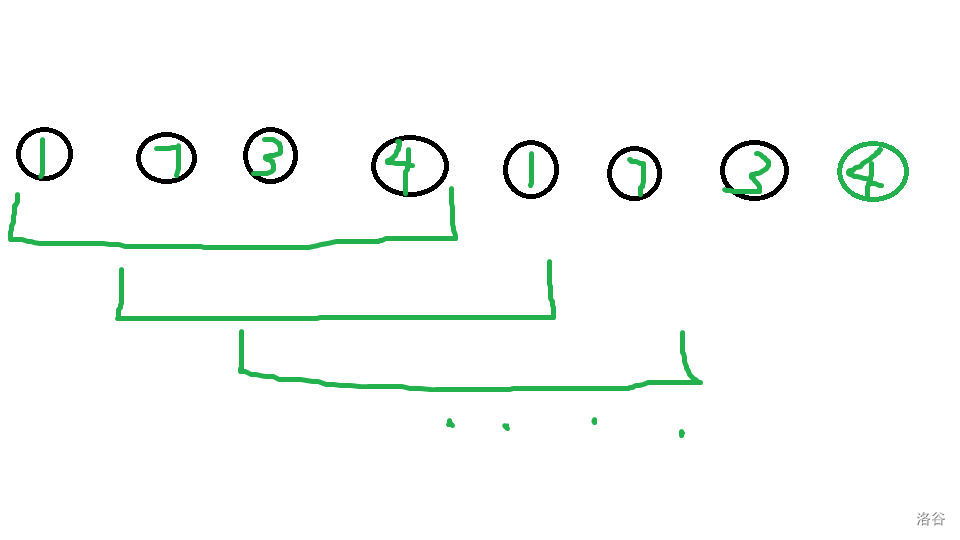
之后的序列
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<queue>
#include<string>
#include<cstring>
#include<vector>
#include<cmath>
using namespace std;
int n;
int a[2001],sum[3003];
int f1[2001][2001],f2[2001][2001];//f1为最大值,f2为最小值
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>a[i];
a[n+i]=a[i];//复制一倍
}
for(int i=1;i<=n+n;i++)
{
sum[i]=sum[i-1]+a[i];//前缀和
}
memset(f2,0x3f,sizeof(f2));//求最小值要初始化为极大值
for(int i=1;i<=n+n;i++)
{
f1[i][i]=f2[i][i]=0;//初始化为0
}
for(int i=2;i<=n;i++)//枚举区间长度
{
for(int l=1,r=l+i-1;l<=n+n&&r<=n+n;l++,r=l+i-1)//枚举区间左右段点
{
for(int k=l;k<r;k++)//枚举断点
{
f1[l][r]=max(f1[l][r],f1[l][k]+f1[k+1][r]+sum[r]-sum[l-1]);
f2[l][r]=min(f2[l][r],f2[l][k]+f2[k+1][r]+sum[r]-sum[l-1]);
}
}
}
int maxn=0,minn=0x3f3f3f3f;
for(int i=1;i<=n;i++)//寻找答案
{
maxn=max(maxn,f1[i][i+n-1]);
minn=min(minn,f2[i][i+n-1]);
}
cout<<minn<<endl<<maxn;
return 0;
}
经典的括号染色方案数题,基本上就是区间 \(dp\) 了
先记住一个思想,方案数 \(dp\) 就是将一个大问题转化为若干个
互不冲突的小问题,即一个大状态转化为若干个
互不冲突的小状态,分别计算再合并
这要求我们的状态具有可划分性
题中有对一对匹配的括号染色有限制,则可以一次决策为将一对匹配的括号染色,其内部的为另一个子问题,又因为有颜色的限制,可以将颜色加入状态,设 \(f[i][j][x][y]\) 为区间 \([l,r]\) 两端颜色分别为\(x,y\)的方案数(\(0\) 为不染色,\(1\) 为蓝色,\(2\) 为红色)
对于
\[() \]\[f[i][j][0][1]=f[i][j][0][2]=f[i][j][1][0]=f[i][j][2][0]=1 \]相邻两个括号颜色不能相同,且为匹配的括号,必须有一个染色
对于
\[(....) \]\[f[i][j][0][1] +=f[i+1][j-1][p][q](p,q\in0,1,2\ q\neq1) \]\[f[i][j][0][2]+=f[i+1][j-1][p][q](p,q\in0,1,2\ q\neq2) \]\[f[i][j][1][0]+=f[i+1][j-1][p][q](p,q\in0,1,2\ p\neq1) \]\[f[i][j][2][0]+=f[i+1][j-1][p][q](p,q\in0,1,2\ p\neq2) \]对于
\[(....)....(....) \]设最左的左括号配对的右括号为 \(match[i]\)
\[f[i][j][l][r]+=f[i][match[i]][l][p]*f[match[i]+1][j][q][r](l,r,p,q\in0,1,2\ p\neq q) \]这个 \(dp\) 初始化为一对括号,且转移方式是按括号划分的,用循环很难写,可以考虑记忆化搜索
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<queue>
#include<string>
#include<cstring>
#include<vector>
#include<cmath>
using namespace std;
string s;
long long mod=1e9+7;
long long f[701][701][3][3],vis[701][701];
int check[701];//每个左括号对应匹配的右括号
int sta[701],top,n;
long long ans;
void dfs(int l,int r)
{
if(vis[l][r]) return ;//记忆化
vis[l][r]=1;
if(r==l+1)
{
f[l][r][1][0]=f[l][r][0][1]=f[l][r][2][0]=f[l][r][0][2]=1;//情况1
// cout<<f[l][r][1][2];
}
else if(r==check[l])//情况2
{
dfs(l+1,r-1);
for(int i=0;i<=2;i++)
{
for(int j=0;j<=2;j++)
{
if(i!=1) f[l][r][1][0]=((f[l][r][1][0]+f[l+1][r-1][i][j])%mod+mod)%mod;
if(j!=1) f[l][r][0][1]=((f[l][r][0][1]+f[l+1][r-1][i][j])%mod+mod)%mod;
if(i!=2) f[l][r][2][0]=((f[l][r][2][0]+f[l+1][r-1][i][j])%mod+mod)%mod;
if(j!=2) f[l][r][0][2]=((f[l][r][0][2]+f[l+1][r-1][i][j])%mod+mod)%mod;
}
}
}
else//情况3
{
dfs(l,check[l]);dfs(check[l]+1,r);
for(int i=0;i<=2;i++)
{
for(int j=0;j<=2;j++)
{
for(int k=0;k<=2;k++)
{
for(int p=0;p<=2;p++)
{
if((j==1&&k==1)||(j==2&&k==2)) continue;
f[l][r][i][p]=((f[l][r][i][p]+(f[l][check[l]][i][j]*f[check[l]+1][r][k][p])%mod)%mod+mod)%mod;
}
}
}
}
}
}
int main()
{
cin>>s;
for(int i=0;i<s.size();i++)
{
if(s[i]=='(') sta[++top]=i+1;
else check[sta[top]]=i+1,top--;//用栈进行括号匹配
}
dfs(1,s.size());
for(int i=0;i<=2;i++)
{
for(int j=0;j<=2;j++)
{
ans=(((ans+f[1][s.size()][i][j])%mod+mod)%mod);//统计答案
}
}
cout<<ans;
// printf("%.2f\n",ans);
return 0;
}
括号匹配问题,考虑区间 \(dp\)
题目给的限制很多,一个个分析
1.\(()\)为合法的,所以要有表示\(()\)的状态
2.\((S)\)为合法的,相当于\(S\)加\(()\),所以要有表示\(S\)的和能表示\((...)\)的
3.\(AB\)为合法的,直接拼
4.\(ASB\)为合法的,较为复杂,可由\(AS\)与\(B\)合并或\(A\)与\(SB\)合并
5.\((A)\),\((SA)\),\((AS)\)都可拼出不在考虑
- 考虑\(AS\)和\(SB\)如何拼出,\(AS\)可以是\(A\)和\(S\),\(SB\)同理
综合一下
记\(dp_{l,r,op}\) 为 \(l\) 到 \(r\) 区间且类型为 \(op\) 合法的方案数,下文统一记作 \(dp_{op}\)
-
\(dp_{1}\) 形如
***,全都是点 -
\(dp_{2}\) 形如
(***), 左右为匹配的括号 -
\(dp_{3}\) 形如
(***)***,左边为括号右边是点 -
\(dp_{4}\) 形如
***(***),左边为点右边是括号 -
\(dp_{5}\) 形如
(*** )***(***),左边为括号右边也是括号(\(2\)状态也属于\(5\)状态)
方程(在可以成立的情况下)
\(dp_{l,r,1}=dp_{l,r-1,1}\)
\(dp_{l,r,2}=dp_{l+1,r-1,1}+dp_{l+1,r-1,5}+dp_{l+1,r-1,3}+dp_{l+1,r-1,4}\)
\(dp_{l,r,3}=\sum\limits_{k=l}^{r-1} dp_{l,k,5}\ast dp_{k+1,r,1}\)
\(dp_{l,r,4}=\sum\limits_{k=l}^{r-1} dp_{l,k,1}\ast dp_{k+1,r,5}\)
\(dp_{l,r,5}=\left(\sum\limits_{k=l}^{r-1} \left(dp_{l,k,4}+dp_{l,k,5}\right)\ast dp_{k+1,r,2}\right) +dp_{l,r,2}\)
情况 \(2\) 在长度为 \(2\) 的区间有特判
代码
#include<iostream>
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<queue>
#include<string>
#include<cstring>
#include<vector>
#include<cmath>
using namespace std;
long long n,k,mod=1e9+7;
string s;
long long dp[505][505][6];
bool comp1(int l,int r)
{
if((s[l]=='('||s[l]=='?')&&(s[r]==')'||s[r]=='?')) return true;//左右能否都为括号
return false;
}
bool comp2(int l,int r)
{
if((s[l]=='*'||s[l]=='?')&&(s[r]=='*'||s[r]=='?')) return true;//左右能否都为点
return false;
}
int main()
{
cin>>n>>k;
cin>>s;
s='#'+s;
for(int i=1;i<=n;i++)
{
if(s[i]=='*'||s[i]=='?') dp[i][i][1]=1;
}
for(int len=2;len<=n;len++)
{
for(int l=1,r=l+len-1;l<=n&&r<=n;l++,r=l+len-1)
{
if(len<=k&&comp2(l,r)) dp[l][r][1]=dp[l][r-1][1];
if(len==2&&comp1(l,r)) dp[l][r][2]=1;
if(len>=3)
{
if(comp1(l,r)) dp[l][r][2]=(dp[l+1][r-1][1]+dp[l+1][r-1][5]+dp[l+1][r-1][3]+dp[l+1][r-1][4])%mod;
for(int k=l;k<r;k++)
{
dp[l][r][3]=(dp[l][r][3]+dp[l][k][5]*dp[k+1][r][1])%mod;
dp[l][r][4]=(dp[l][r][4]+dp[l][k][1]*dp[k+1][r][5])%mod;
dp[l][r][5]=(dp[l][r][5]+dp[l][k][2]*(dp[k+1][r][4]+dp[k+1][r][5])%mod)%mod;
}
}
dp[l][r][5]=(dp[l][r][5]+dp[l][r][2])%mod;
}
}
cout<<dp[1][n][5];
return 0;
}
状压dp
有时 \(dp\) 时,需要枚举一个状态子集,并以状态子集进行推导,这种以子集作为一个状态的称为状压dp,一般每个元素有几种状态就是几进制状压,常见的有二进制状压,即以每个元素选了或没选为状态
常见二进制用法
枚举子集
// 降序遍历 m 的子集
for (int s = m;; s = (s - 1) & m) {
// s 是 m 的一个子集
if (s == 0) break;
}
该操作的时间复杂度为 \(O(3^n)\)
取出二进制表示下的第k位
(n>>k)&1
取出二进制表示下的第0到k-1位
n&((1<<k)-1)
对二进制表示下的第k位取反
n^(1<<k)
对二进制表示下的第k位赋1
n|(1<<k)
对二进制表示下的第k位赋0
n&(!(1<<k))
棋盘上给你一些限制,求满足限制的最大摆放数,是状压dp的经典题型
基本套路是按行从上到下转移
定义 \(dp[i][S1][S2]\) 为到第 \(i\) 行且该行棋子摆放状态集合为 \(S1\) 行且上一行棋子摆放状态集合为 \(S2\) 时的从第一行到这行的最大摆放数。
考虑上一行填什么,且要保证上一行和当前行不冲突
\[f[i][j][k]=\max\left(f[i][j][k],f[i-1][k][l]+num_j\right) \]考虑有不能放的点,一般思路是将不能放的点表示成一个二进制数,每次判状态是否符合条件
有一个优化,因为一行不能有距离少于两个格,可以预处理出每一行状态
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
#include<cstring>
#include<queue>
#include<vector>
#include<cmath>
using namespace std;
int n,m;
int lim[201],num,s[2010],army[2010],f[505][505][505],maxn;
void pre()
{
for(int i=0;i<(1<<m);i++)
{
if((i&(i<<1))||(i&((i<<1)<<1))) continue;
int k=0;
for(int j=0;j<m;j++)
{
if((i&(1<<j)))
{
k++;
}
}
num++;s[num]=i;army[num]=k;
}
}
int main()
{
cin>>n>>m;
for(int i=1;i<=n;i++)
{
char c;
for(int j=m-1;j>=0;j--)
{
cin>>c;
if(c=='H') lim[i]|=(1<<j);
}
}
pre();
if(n==1)
{
for(int i=1;i<=num;i++)
{
if((s[i]&lim[1])) continue;
f[1][i][1]=army[i];
}
}
for(int j=1;j<=num;j++)
{
for(int k=1;k<=num;k++)
{
if((s[j]&s[k])||(s[j]&lim[2])||(s[k]&lim[1])) continue;
f[2][j][k]=army[j]+army[k];
}
}
for(int i=3;i<=n;i++)
{
for(int j=1;j<=num;j++)
{
for(int k=1;k<=num;k++)
{
if((s[j]&s[k])||(s[j]&lim[i])||((s[k]&lim[i-1]))) continue;
for(int l=1;l<=num;l++)
{
if((s[j]&s[l])||(s[k]&s[l])||(s[l]&lim[i-2])) continue;
f[i][j][k]=max(f[i][j][k],f[i-1][k][l]+army[j]);
}
}
}
}
for(int j=1;j<=num;j++)
{
for(int k=1;k<=num;k++)
{
if((s[j]&s[k])||(s[j]&lim[n])||(s[k]&lim[n-1])) continue;
maxn=max(maxn,f[n][j][k]);
}
}
cout<<maxn;
return 0;
}
首先,和谐的方案只是不互质,自然考虑质数
发现当一种方案是和谐的,只有两个集合的质因子集合互不相交,即 \(A|B=0\)
不妨考虑每个数,他可以放 \(A\) 或 \(B\) 或不放,且限制只与质因子有关。
自然想到 \(dp\) ,令 \(dp[i][A][B]\)为到第 \(i\) 个数,第一个集合为 \(A\) 且第二个集合为 \(B\)的方案数,记 \(x\) 为第 \(i\) 个数的质因子集合,则有
\[f[i][A|x][B]+=f[i-1][A][B](B \& x ==0) \]\[f[i][A][B|x]+=f[i-1][A][B](A \& x ==0) \]\[f[i][A][B]+=f[i-1][A][B] \]又发现 \(i\) 只与 \(i-1\) 有关,可以用滚动数组优化
但是 \(500\) 中有 \(95\) 个质数,直接状压是不行的,考虑 \(23\ast 23>500\) 即 \(500\) 中至多有一个大于 \(23\) 的质因数,可以单独拿出来。
具体来说,我们可以将所有最大质因数相同的放到一起,这些数只能放 \(A\) 或放 \(B\),除了最大质因数之外质因数只可能小于 \(23\),就和第一种相同了
对于所有最大质因数相同的,开两个辅助数组 \(f1\) 和 \(f2\),一个表示不放 \(B\) 中的方案,一个表示不放 \(A\) 的方案
\[f1[A|x][B]+=f1[A][B](B \& x ==0) \]\[f2[A][B|x]+=f2[A][B](A \& x ==0) \]还要合并到原方程中,即总方案要加上只放 \(A\) 的,只放 \(B\)的,一个不放的,又知道 \(f1\), \(f2\) 中都考虑了不选的需要减去一次,即
\[f[A][B]=f1[A][B]+f2[A][B]-f[A][B] \]#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
#include<cstring>
#include<queue>
#include<vector>
using namespace std;
struct node{
int maxp,psum;
}a[60010];
int n,p;
int prime[10]={2,3,5,7,11,13,17,19};
int vis[50],ans;
int f[500][500],f1[500][500],f2[500][500];
bool cmp(node x,node y)
{
return x.maxp>y.maxp;
}
void get_prime(int x,int now)
{
int ans=0;
for(int i=0;i<8;i++)
{
if(x%prime[i]==0)
{
ans|=(1<<i);
while(x%prime[i]==0) x/=prime[i];
}
}
if(x>1) a[now].maxp=x;
else a[now].maxp=-1;
a[now].psum=ans;
}
int main()
{
// freopen("txt.txt","r",stdin);
// freopen("txt.out","w",stdout);
cin>>n>>p;
for(int i=2;i<=n;i++) get_prime(i,i-1);
sort(a+1,a+n,cmp);
f[0][0]=1;
int i=1;
for(;a[i].maxp!=-1;i++)
{
if(a[i].maxp!=a[i-1].maxp)
{
memcpy(f1,f,sizeof(f1));
memcpy(f2,f,sizeof(f2));
}
for(int j=(1<<8)-1;j>=0;j--)
{
for(int k=(1<<8)-1;k>=0;k--)
{
if((k&a[i].psum)==0) f1[j|a[i].psum][k]=(f1[j|a[i].psum][k]+f1[j][k])%p;
if((j&a[i].psum)==0) f2[j][k|a[i].psum]=(f2[j][k|a[i].psum]+f2[j][k])%p;
}
}
if(a[i].maxp!=a[i+1].maxp)
{
for(int j=(1<<8)-1;j>=0;j--)
{
for(int k=(1<<8)-1;k>=0;k--)
{
f[j][k]=((f1[j][k]+f2[j][k]-f[j][k])%p+p)%p;
}
}
}
}
for(;i<n;i++)
{
for(int j=(1<<8)-1;j>=0;j--)
{
for(int k=(1<<8)-1;k>=0;k--)
{
if((k&a[i].psum)==0) f[j|a[i].psum][k]=(f[j|a[i].psum][k]+f[j][k])%p;
if((j&a[i].psum)==0) f[j][k|a[i].psum]=(f[j][k|a[i].psum]+f[j][k])%p;
}
}
}
for(int j=(1<<8)-1;j>=0;j--)
{
for(int k=(1<<8)-1;k>=0;k--)
{
ans=(ans+f[j][k])%p;
}
}
cout<<ans%p;
// fclose(stdin);fclose(stdout);
return 0;
}
正确的思路
首先发现 \(b_i\) 很小,考虑状压,其次要算贡献必须知道前面的人,状态中必须有前面的人是谁,且定住当前打饭的人,他前七个人之前的一定都打完了
粗略的方程为\(f[i][S][j]\) 为前 \(i-1\) 个人都打完了,上一个打饭的是 \(j\), \(i\) 和后面 \(7\) 个的打饭状态为 \(S\) 的最小时间,又考虑 \(j\) 只能是前 \(8\) 个到后 \(7\) 个,所以j 只用取 \(-8\) 到 \(7\)
考虑若 \(i\) 已经打完饭,则可以从 \(i\) 转移到 \(i+1\),有\(f[i+1][j>>1][k]=\min(f[i+1][j>>1][k],f[i][j][k-1])\)
若没有,考虑枚举 \(i\) 到 \(i+7\) ,看谁先打饭
设 \(i+l\)先打饭,则有 \(f[i][j|(1<<l)][l]=\min(f[i][j|(1<<l)][l],f[i][j][k]+a[i+k]\ \text{xor} \ a[i+l]\)
初始化有一种很简便的方法,令 \(f[1][0][-1]\) 为 \(0\) ,其余为 \(inf\),转移是判断 \(i+k\)是否大于零,不是的话说明是第一个打饭的不用费用。
最后会收敛到\(n+1\),结果从 \(f[n+1][0][k]\) 找即可
#include <bits/stdc++.h>
#define LL long long
using namespace std;
int c,n;
int t[10010],b[10010],f[1051][1024][20];
int main()
{
cin>>c;
for(int i=1;i<=c;i++)
{
memset(f,0x3f,sizeof(f));
memset(t,0,sizeof(t));
memset(b,0,sizeof(b));
f[1][0][6]=0;
cin>>n;
for(int i=1;i<=n;i++)
{
cin>>t[i]>>b[i];
}
for(int i=1;i<=n;i++)
{
for(int j=0;j<(1<<8);j++)
{
for(int k=-8;k<=7;k++)
{
if(f[i][j][k+8]!=0x3f3f3f3f)
{
if((j&1))
{
f[i+1][j>>1][k+7]=min(f[i+1][j>>1][k+7],f[i][j][k+8]);
}
else
{
int lim=1e9;
for(int l=0;l<=7;l++)
{
if(((j>>l)&1)==0)
{
int now=i+l;
if(now>lim) break;
lim=min(lim,now+b[now]);
f[i][j|(1<<l)][l+8]=min(f[i][j|(1<<l)][l+8],f[i][j][k+8]+(i+k>0?t[i+k]^t[i+l]:0));
}
}
}
}
}
}
}
int ans=0x3f3f3f3f;
for(int k=-8;k<=0;k++)
{
ans=min(ans,f[n+1][0][k+8]);
}
cout<<ans<<endl;
}
return 0;
}
树形dp
当 \(dp\) 位于树上或依赖于父子关系的 \(dp\) 称为树形 \(dp\)
考虑某个节点来不来只会影响孩子节点,故考虑树形 \(dp\),每个点有两种情况,故令 \(dp[i][0/1]\) 为 \(i\) 节点来或不来是以 \(i\) 为子树的最大值
有
\[f[i][1]=f[i][1]+f[v][0] \]\[f[i][0]=f[i][0]+max(f[v][1],f[v][0]) \]#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<string>
#include<queue>
#include<vector>
#include<cmath>
using namespace std;
struct edge{
int to,next;
}e[6400100];
int head[200100],cnt;
int n,rt;
int a[800100],in[800100];
long long f[800100][2];
void add(int u,int v)
{
e[++cnt]={v,head[u]};
head[u]=cnt;
}
void dfs(int now,int fath)
{
f[now][1]=a[now];
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].to;
if(v==fath) continue;
dfs(v,now);
f[now][1]+=f[v][0];
f[now][0]+=max(f[v][1],f[v][0]);
}
}
int main()
{
// freopen("dance.in","r",stdin);
// freopen("dance.out","w",stdout);
cin>>n;
for(int i=1;i<=n;i++) cin>>a[i];
for(int i=1;i<n;i++)
{
int l,k;
cin>>l>>k;
in[l]++;
add(l,k);add(k,l);
}
for(int i=1;i<=n;i++) if(in[i]==0) rt=i;
dfs(rt,0);
cout<<max(f[rt][0],f[rt][1]);
fclose(stdin);
fclose(stdout);
return 0;
}
如果树已建出,则类似与上面的,令 \(f[i][0/1/2]\) 为 \(i\) 节点染绿或红或蓝的方案,最小值同理,有
\[f[now][0]+=max(f[l][1]+f[r][2],f[l][2]+f[r][1]) \]\[f[now][1]+=max(f[l][0]+f[r][2],f[l][2]+f[r][0]) \]\[f[now][2]+=max(f[l][0]+f[r][1],f[l][1]+f[r][0]) \]若只有一个儿子,只加一个就可以了
考虑怎么建树
发现建树是递归定义的,我们不妨也递归的建树
有
int init(int now)
{
id++;int pre=id;
if(s[now]=='1')
{
int k=init(now+1);
add(k,pre);add(pre,k);
}
if(s[now]=='2')
{
int k=init(now+1);
add(k,pre);add(pre,k);;
k=init(id);
add(k,pre);add(pre,k);
}
return pre;
}
完整代码
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
#include<cstring>
#include<queue>
#include<vector>
#include<cmath>
using namespace std;
struct edge{
int to,next;
}e[6400100];
int head[900100],cnt;
void add(int u,int v)
{
// cout<<u<<" "<<v<<endl;
e[++cnt]={v,head[u]};
head[u]=cnt;
}
string s;
int id;
int f[900100][3],g[900100][3];
int init(int now)
{
id++;int pre=id;
if(s[now]=='1')
{
int k=init(now+1);
// cout<<k<<" "<<pre<<endl;
add(k,pre);add(pre,k);
}
if(s[now]=='2')
{
int k=init(now+1);
add(k,pre);add(pre,k);
// cout<<k<<" "<<pre<<endl;
k=init(id);
add(k,pre);add(pre,k);
// cout<<k<<" "<<pre<<endl;
}
return pre;
}
void dfs(int now,int fath)
{
f[now][0]=1;f[now][1]=f[now][2]=0;
g[now][0]=1;g[now][1]=g[now][2]=0;
int cnt=0,l,r;
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].to;
if(v==fath) continue;
// cout<<v<<now<<" ";
dfs(v,now);
cnt++;
if(cnt==1) l=v;
if(cnt==2) r=v;
}
if(cnt==1)
{
f[now][0]+=max(f[l][1],f[l][2]);
f[now][1]+=max(f[l][0],f[l][2]);
f[now][2]+=max(f[l][0],f[l][1]);
g[now][0]+=min(g[l][1],g[l][2]);
g[now][1]+=min(g[l][0],g[l][2]);
g[now][2]+=min(g[l][0],g[l][1]);
}
if(cnt==2)
{
f[now][0]+=max(f[l][1]+f[r][2],f[l][2]+f[r][1]);
f[now][1]+=max(f[l][0]+f[r][2],f[l][2]+f[r][0]);
f[now][2]+=max(f[l][0]+f[r][1],f[l][1]+f[r][0]);
g[now][0]+=min(g[l][1]+g[r][2],g[l][2]+g[r][1]);
g[now][1]+=min(g[l][0]+g[r][2],g[l][2]+g[r][0]);
g[now][2]+=min(g[l][0]+g[r][1],g[l][1]+g[r][0]);
}
}
int main()
{
cin>>s;
init(0);
dfs(1,0);
cout<<max(f[1][0],max(f[1][1],f[1][2]))<<" "<<min(g[1][0],min(g[1][1],g[1][2]));
return 0;
}
换根dp
一般是要求每个节点的结果,且每个节点都不一样
先考虑只 \(dp\) 一个节点的深度和,显然是裸的树形 \(dp\) ,则令 \(f[u]\) 为以 \(u\) 为根节点的深度和,有
\[f[u]=\sum f[v]+dep(u) \]现在考虑换根 \(dp\) 基本套路如下
1.只对根节点进行 \(dp\) 求出根节点的值(子得父)
2.再从根节点往下扫,用父节点去推出子节点(父推子)
3.一般的父推子,都应现将父亲中该子节点之下的信息减去,该子节点之下的信息再用剩余的信息更新
以这题为例,考虑已知父节点,如何推出子节点
如上子节点的子树对答案的贡献已经统计,未统计的只有父节点以上的答案
在考虑父节点以上在父节点中已经存在,用父亲的值减去子树的值就是父节点以上的答案,但实际上少每个节点一深度需要加回去,则有
\[f[v]=f[v]+(f[u]-f[v]-siz[v])+(n-siz[v])=f[u]+(n-2\ast siz[v]) \]
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<queue>
#include<vector>
using namespace std;
struct edge{
int to,next;
}e[8000100];
int head[4001000],cnt;
long long k,n,maxn,f[1001000],depth[1001000],size[1001000];
void add(int u,int v)
{
e[++cnt]={v,head[u]};
head[u]=cnt;
}
void dfs(int now,int fath)
{
depth[now]=depth[fath]+1;
f[1]+=depth[now]-1;
size[now]=1;
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].to;
if(v!=fath) dfs(v,now),size[now]+=size[v];
}
}
void dfs1(int now,int fath)
{
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].to;
if(v!=fath)
{
f[v]=f[now]-size[v]+n-size[v];
if(f[v]>maxn) maxn=f[v],k=v;
dfs1(v,now);
}
}
}
int main()
{
cin>>n;
for(int i=1;i<n;i++)
{
int u,v;
cin>>u>>v;
add(u,v);add(v,u);
}
dfs(1,0);maxn=f[1];k=1;dfs1(1,0);
cout<<k;
return 0;
}
套路的思考一下
先求根节点的值,发现 \(k\) 只有 \(20\) ,自然考虑直接用第二位暴力统计
令 \(f[u][j]\) 为以 \(u\) 为根的子树之内的且与 \(u\) 距离为 \(j\) 的权值和
\[f[u][j]+=f[v][j-1] \]其中 \(f[i][0]=c[i]\)
考虑换根,由父节点推子节点
令 \(g[u][j]\) 为与 \(u\) 距离为 \(j\) 的权值和,有
\[g[u][j]=f[u][j]+g[fa(u)][j-1]-f[u][j-2] \]记得在 \(j=1\) 时有特判
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<string>
#include<cstring>
#include<queue>
#include<vector>
#include<cmath>
using namespace std;
struct edge{
int to,next;
}e[6400100];
int head[200100],cnt;
int n,k;
int f[200100][50],g[200100][50];
void add(int u,int v)
{
e[++cnt]={v,head[u]};
head[u]=cnt;
}
void dfs1(int now,int fath)
{
for(int i=head[now];i;i=e[i].next)
{
int v=e[i].to;
if(v==fath) continue;
dfs1(v,now);
for(int j=1;j<=20;j++) f[now][j]+=f[v][j-1];
}
}
void dfs2(int now,int fath)
{
if(now==1)
{
for(int i=0;i<=20;i++) g[now][i]=f[now][i];
} for(int i=head[now];i;i=e[i].next)
{
int v=e[i].to;
if(v==fath) continue;
for(int j=1;j<=20;j++)
{
if(j==1) g[v][j]=f[v][j]+g[now][j-1];
else g[v][j]=f[v][j]+g[now][j-1]-f[v][j-2];
}
dfs2(v,now);
}
}
int main()
{
cin>>n>>k;
for(int i=1;i<n;i++)
{
int u,v;
cin>>u>>v;
add(u,v);add(v,u);
}
for(int i=1;i<=n;i++) cin>>f[i][0],g[i][0]=f[i][0];
dfs1(1,0);dfs2(1,0);
for(int i=1;i<=n;i++)
{
int sum=0;
for(int j=0;j<=k;j++)
{
sum+=g[i][j];
}
cout<<sum<<endl;
}
return 0;
}