操作码序列
通常对PE格式文件(.exe文件等),用IDA Pro反汇编得到对应的asm(包含汇编代码)文件。从asm文件中可以提取操作码、函数调用等信息作为特征训练机器学习和深度学习模型。
加壳(对程序的压缩、加密等)后的程序对应的汇编代码中,指令语句会比较少,大部分是数据定义语句。
一个样本对应两种格式文件:
- 关于字节的十六进制表示文件,即字节码文件
- 对PE反汇编后得到的汇编语言文件,保存程序对应汇编指令,即asm文件。
字节的十六进制表示文件:
从asm文件中提取操作码序列:
- 一个asm文件中包含多个函数块,每个函数块中包含一串汇编指令。
- 从汇编指令中提取操作码(push/mov等)、寄存器(ebp, esp)等作为特征,而地址和操作码做特征的很少。
对提取出的操作码序列进行n-gram(1-3):
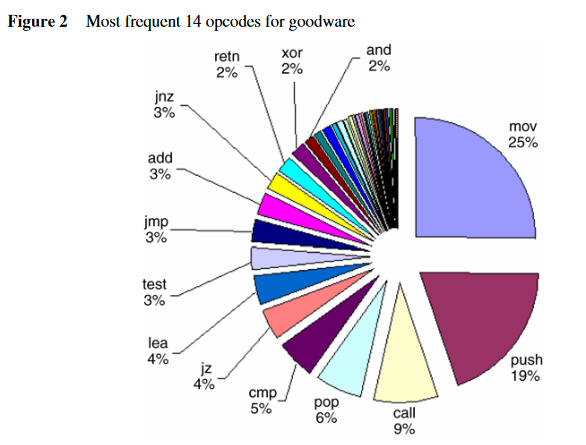
07-Other-Opcode frequence
旨在说明恶意程序和正常程序在操作码序列和出现频率上的统计差异。
正常程序最常出现的十四种操作码:
恶意程序最常出现的十四种操作码:
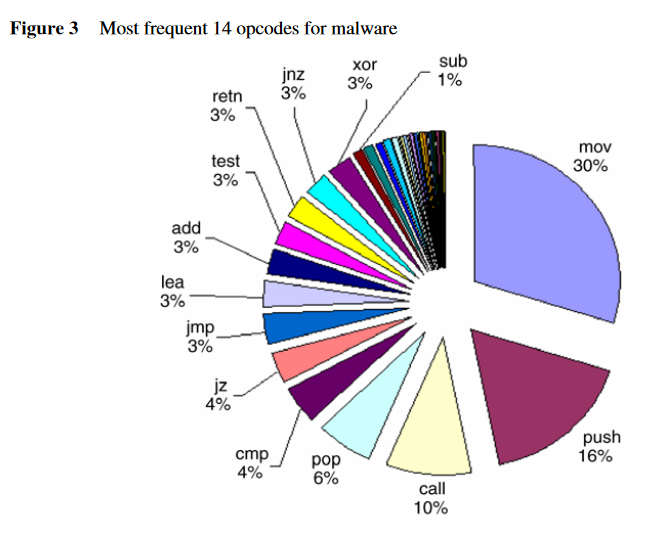
将正常程序视为一个类别,与其他的恶意程序类别比较:
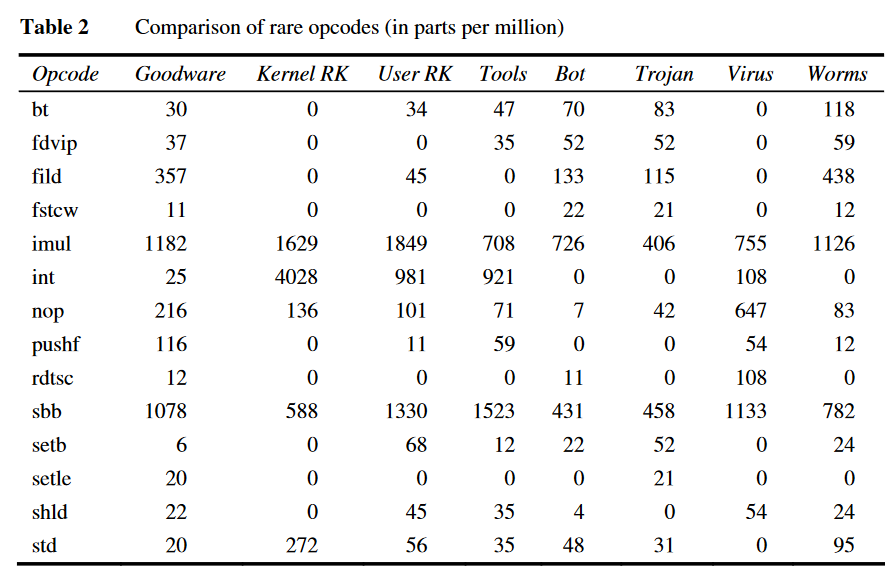
文章提供两个基本结论:
- 正常程序和恶意程序在操作码上存在明显的统计差异,这一点也是应用机器学习方法的理论基础。
- 不常见的操作码对分类器的贡献可能更高。
13-IS-Opcode ngrams
基于操作码序列出现频率的工作。
Introduction
代码混淆(code obfuscation)
- garbage insertion,插入垃圾代码和数据。
- code reordering,改变代码的执行顺序。
- variable renaming,对变量、函数名等重命名,用无意义的名字代替。
- 其他:添加花指令、重写代码逻辑(比如将for循环改写成while循环、将循环改写成递归、精简中间变量等)等。
代码混淆带来的问题:
- 调试变得困难,程序难以被理解。
- 并不能保证原始码的安全。
- 一些公开的代码混淆工具已经被安全厂商拉黑。
D. Bilar, Opcodes as predictor for malware, International Journal of Electronic Security and Digital Forensics 1 (2007) 156–168.
- 操作码序列揭示了恶意软件和正常软件之间的统计差异(opcodes reveal significant statistical differences between malware and legitimate software)。
- 不常见的操作码分类表现比常见操作码更好(rare opcodes are better predictor than common opcodes)。
Idea
- 反汇编提取出汇编代码(asm文件)。
- 对汇编文件处理得到操作码序列,以操作码序列出现频率作为特征。
- 对操作码特征选择和加权。
从汇编代码(asm文件)中提取操作码序列

以上图为例,可以得到长度为2的操作码序列:
- s1 =(mov, add), s2 =(add, push), s3 =(push, add), s4 =(add, and), s5 =(and, push), s6 =(push, push) and s7 =(push, and)
在实验部分使用了长度为1和2的特征码序列,即n-gram,n=1和n=2,用信息增益选择了top 1000个特征。
词频(Term Frequence, TF):
\[tf_{i,j } = \frac{ n_{i, j} }{\sum_{k} n_{k,j}} \]- 分子是序列s(i, j)在一个可执行文件中的出现次数。
- 分母是一个文件中所有操作码序列个数。
互信息(Mutual Information)计算操作码序列权重:
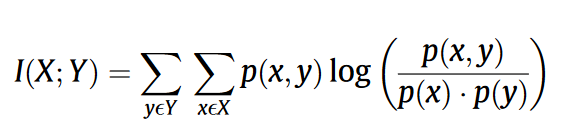
- x是操作码频率, y是文件所属类别。 #补充#
加权:
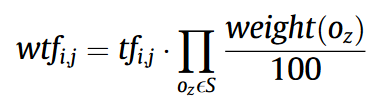
- weight(O)是由互信息计算出来的权重。
Discussion
为什么不用长序列(如何确定序列长度)?
-
难以找到一个合适的序列长度
- 小的值无法检测复杂操作
- 大的值开销很大
-
长序列更容易被代码转置等方法规避。
互信息加权:
- 本质与tf-idf相同,在文档词频的基础上加权。
可改进讨论:
- 得到的矩阵可能非常稀疏,n-gram,n越大特征数量越多,需要更有效的特征筛选方法。
- 无法对抗加壳的程序,要对加壳的程序进行分析要先脱壳。
Reference
Santos, Igor, et al. "Opcode sequences as representation of executables for data-mining-based unknown malware detection." Information Sciences 231 (2013): 64-82.
16-Other-IRMD
Idea
基于以上13年的工作,n-gram的n越大,特征维度越大。
- 如果数据集比较小,模型表现受限。在真实世界中,常是检测的样本数量远多于用于训练的样本数量。
- 序列之间的相似度运算是串行的方式,导致检测的延时比较高。
恶意软件分类问题类似图像分类问题,都是依据某种相似度。而图像分类方法在人脸识别、指纹识别等领域都有许多应用,故而如果有一种方法可以将恶意软件转换为图像,图像识别和分类的方法也可以应用进来。
故而在此可以提取二元操作码序列生成图像,下图只是统计二元操作码序列出现的频率:
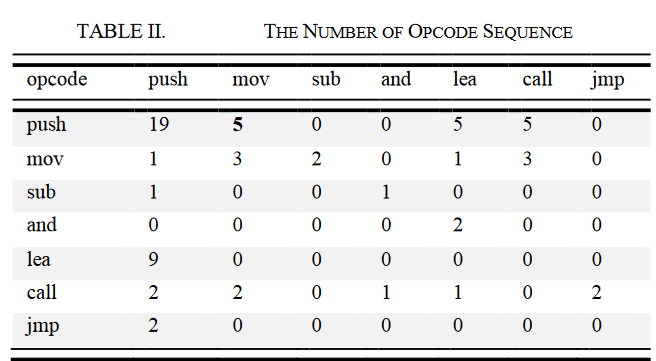
本文中图像某点处的具体像素值为二元序列出现概率乘以对应的信息增益:
标签:文件,代码,push,操作码,序列,asm From: https://www.cnblogs.com/handsome6/p/operation-code-sequence-z16jw28.html