【特征】操作码序列
通常对PE格式文件(.exe文件等),用IDA Pro反汇编得到对应的asm(包含汇编代码)文件。从asm文件中可以提取操作码、函数调用等信息作为特征训练机器学习和深度学习模型。
加壳(对程序的压缩、加密等)后的程序对应的汇编代码中,指令语句会比较少,大部分是数据定义语句。
一个样本对应两种格式文件:
- 关于字节的十六进制表示文件,即字节码文件
- 对PE反汇编后得到的汇编语言文件,保存程序对应汇编指令,即asm文件。
字节的十六进制表示文件:
从asm文件中提取操作码序列:
- 一个asm文件中包含多个函数块,每个函数块中包含一串汇编指令。
- 从汇编指令中提取操作码(push/mov等)、寄存器(ebp, esp)等作为特征,而地址和操作码做特征的很少。
对提取出的操作码序列进行n-gram(1-3):
07-Other-Opcode frequence
旨在说明恶意程序和正常程序在操作码序列和出现频率上的统计差异。
正常程序最常出现的十四种操作码:
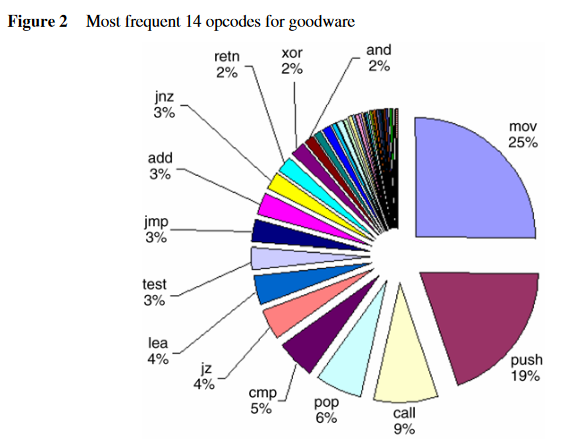
恶意程序最常出现的十四种操作码:
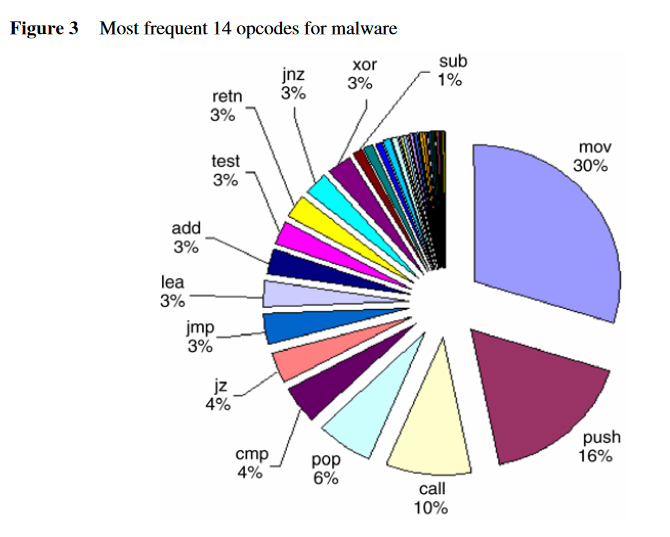
将正常程序视为一个类别,与其他的恶意程序类别比较:
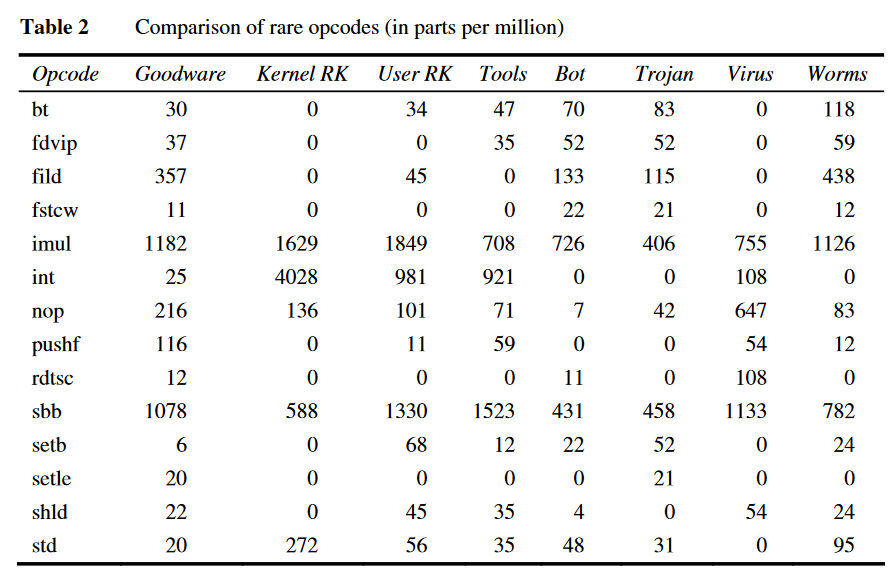
文章提供两个基本结论:
- 正常程序和恶意程序在操作码上存在明显的统计差异,这一点也是应用机器学习方法的理论基础。
- 不常见的操作码对分类器的贡献可能更高。
13-IS-Opcode ngrams
基于操作码序列出现频率的工作。
Introduction
代码混淆(code obfuscation)
- garbage insertion,插入垃圾代码和数据。
- code reordering,改变代码的执行顺序。
- variable renaming,对变量、函数名等重命名,用无意义的名字代替。
- 其他:添加花指令、重写代码逻辑(比如将for循环改写成while循环、将循环改写成递归、精简中间变量等)等。
代码混淆带来的问题:
- 调试变得困难,程序难以被理解。
- 并不能保证原始码的安全。
- 一些公开的代码混淆工具已经被安全厂商拉黑。
D. Bilar, Opcodes as predictor for malware, International Journal of Electronic Security and Digital Forensics 1 (2007) 156–168.
- 操作码序列揭示了恶意软件和正常软件之间的统计差异(opcodes reveal significant statistical differences between malware and legitimate software)。
- 不常见的操作码分类表现比常见操作码更好(rare opcodes are better predictor than common opcodes)。
Idea
- 反汇编提取出汇编代码(asm文件)。
- 对汇编文件处理得到操作码序列,以操作码序列出现频率作为特征。
- 对操作码特征选择和加权。
从汇编代码(asm文件)中提取操作码序列

以上图为例,可以得到长度为2的操作码序列:
- s1 =(mov, add), s2 =(add, push), s3 =(push, add), s4 =(add, and), s5 =(and, push), s6 =(push, push) and s7 =(push, and)
在实验部分使用了长度为1和2的特征码序列,即n-gram,n=1和n=2,用信息增益选择了top 1000个特征。
词频(Term Frequence, TF):
\[tf_{i,j } = \frac{ n_{i, j} }{\sum_{k} n_{k,j}} \]- 分子是序列s(i, j)在一个可执行文件中的出现次数。
- 分母是一个文件中所有操作码序列个数。
互信息(Mutual Information)计算操作码序列权重:
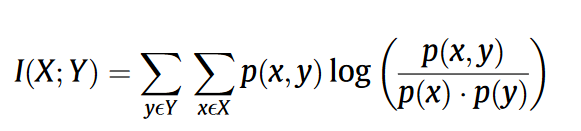
- x是操作码频率, y是文件所属类别。 #补充#
加权:
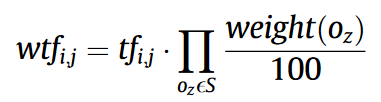
- weight(O)是由互信息计算出来的权重。
Discussion
为什么不用长序列(如何确定序列长度)?
-
难以找到一个合适的序列长度
- 小的值无法检测复杂操作
- 大的值开销很大
-
长序列更容易被代码转置等方法规避。
互信息加权:
- 本质与tf-idf相同,在文档词频的基础上加权。
可改进讨论:
- 得到的矩阵可能非常稀疏,n-gram,n越大特征数量越多,需要更有效的特征筛选方法。
- 无法对抗加壳的程序,要对加壳的程序进行分析要先脱壳。
Reference
Santos, Igor, et al. "Opcode sequences as representation of executables for data-mining-based unknown malware detection." Information Sciences 231 (2013): 64-82.
16-Other-IRMD
Idea
基于以上13年的工作,n-gram的n越大,特征维度越大。
- 如果数据集比较小,模型表现受限。在真实世界中,常是检测的样本数量远多于用于训练的样本数量。
- 序列之间的相似度运算是串行的方式,导致检测的延时比较高。
恶意软件分类问题类似图像分类问题,都是依据某种相似度。而图像分类方法在人脸识别、指纹识别等领域都有许多应用,故而如果有一种方法可以将恶意软件转换为图像,图像识别和分类的方法也可以应用进来。
故而在此可以提取二元操作码序列生成图像,下图只是统计二元操作码序列出现的频率:
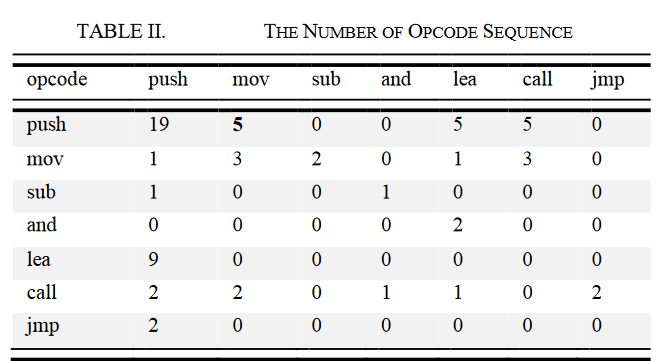
本文中图像某点处的具体像素值为二元序列出现概率乘以对应的信息增益:
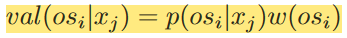
故而计算涉及到两点:
- 二元序列出现的概率。
- 二元序列的信息增益。
符号说明
os指二元操作码序列,os_i指第i条二元操作码序列:
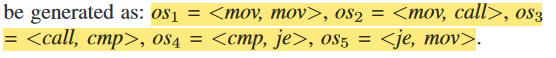
x_j指第j个样本。
y为标签,=1为malware,=0为benign。
二元序列出现的概率
以频率近似概率:
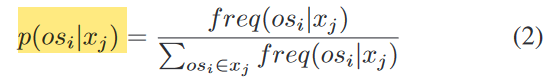
- 计算频率,该操作码序列在单个样本中出现的次数。
- 计算概率,该操作码频率/所有操作码序列出现频率。
信息增益
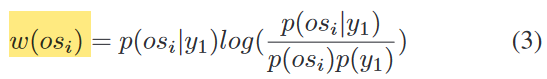
- log分子,首项为二元操作码序列在malware中出现的概率。
- log分母p(os_i):整个训练数据中操作码序列os_i出现的概率。
- log分母p(y_1): malware的概率,应为malware数量/malware + benign数量。
discussion
实验上的亮点,加上了训练样本占总样本的比例。
构造图像的常见思想,只是将13年的文章的n-gram n=2的情况整理为图像,图像像素值为操作码序列出现的概率乘以信息增益,最后用CNN分类。
但没有说明操作码词表大小。
该方法的局限:
- 只考虑的n=2的情况,无法提取出更丰富的序列信息(直观上)。
- 操作码表影响最后图像的大小。
- 在转换为图像后可以借鉴一些图像处理算法。
17-Other-MalOpImg
统计二元操作码序列的出现频率,可视化。
Idea
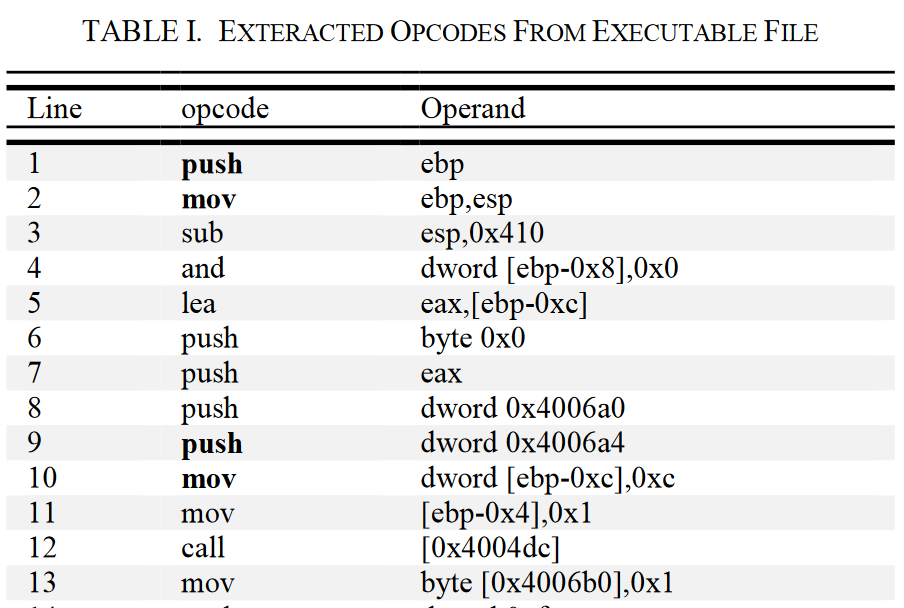
对如上的操作码,忽略操作数遍历:
- 第一行,二元操作码序列:push mov
- 第二行, 二元操作码序列:mov sub
- 直至重复完所有行
得到如下的矩阵数据:
对矩阵数据标准化:
- 矩阵中的最大值缩放到255,如上表的19,放大到255,得255/19=13.4
- 矩阵中所有值缩放到[0, 255],即将矩阵中所有值乘13.4,向下取整
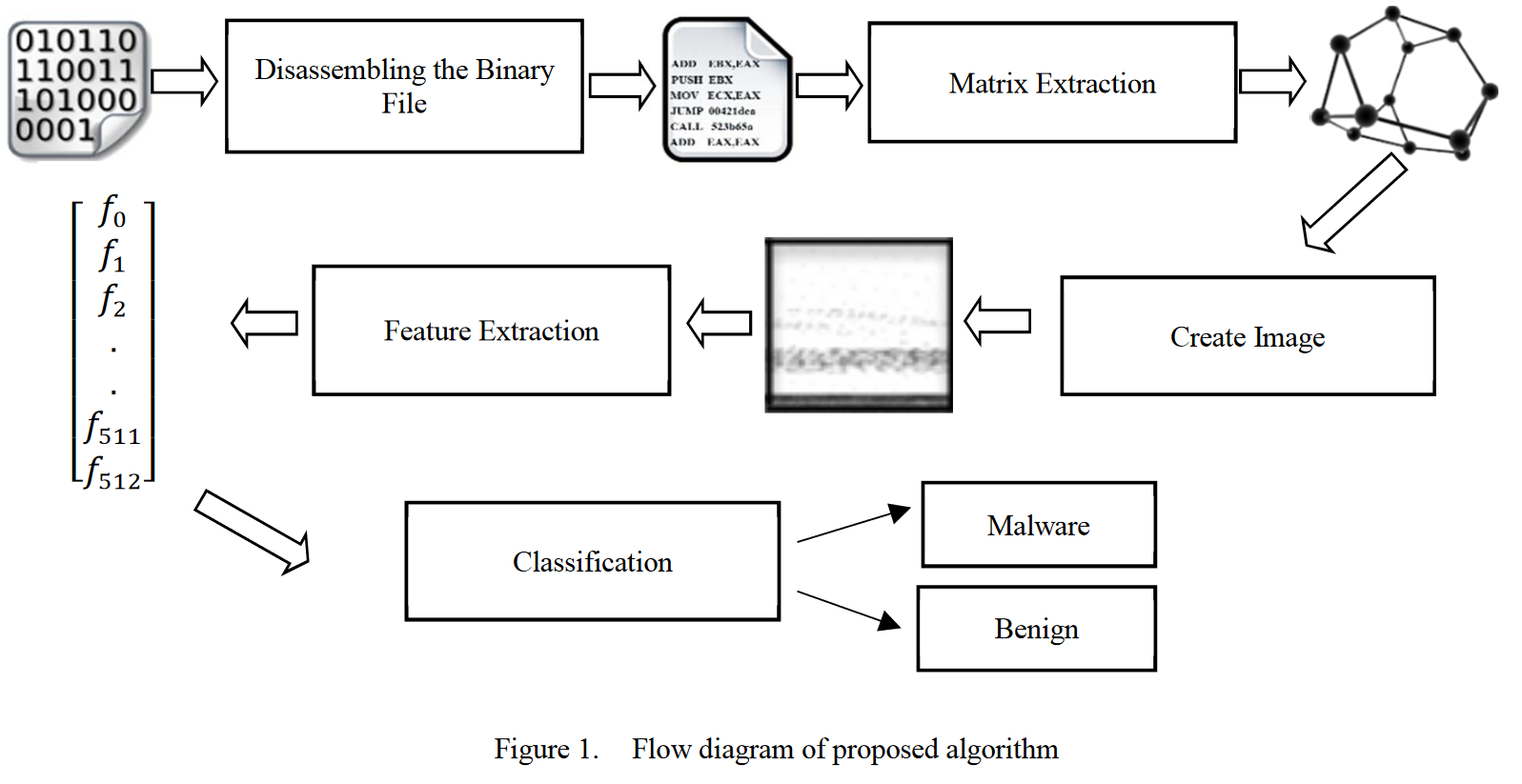
再转化为图像,提取特征,用knn/adaboost/cnn等分类即可。
diagram
Reference
Manavi, Farnoush, and Ali Hamzeh. "A new method for malware detection using opcode visualization." 2017 Artificial Intelligence and Signal Processing Conference (AISP). IEEE, 2017.
18-CS-SimHash Opcode
Introduction
MCSC (Malware Classification using SimHash and CNN),一篇关于操作码可视化的工作:
- 特征:静态特征,从汇编代码中提取操作码序列。
- SimHash:将一个函数块的操作码序列映射为一串向量,操作码序列的相似性体现为向量的相似性。
- CNN:SimHash后的值处理为图像再用CNN分类。
SimHash(无需训练地获取词向量)
- 将一段文本映射为一个向量,可用于数据降维。
- 可用于文本的相似度计算,文本的相似性体现为向量的相似性,用汉明距离计算SimHash向量的距离衡量相似性。
Contributions
-
MCSC (Malware Classification using SimHash and CNN)
- 主要区块的选择
- 数据预处理减少的代码混淆的影响和后续的计算量。
-
使用可视化方法,将并不直观的序列特征转换为图像特征。
-
使用SimHash、主要区块选择和双线性插值改进MCSC。
Idea
框架
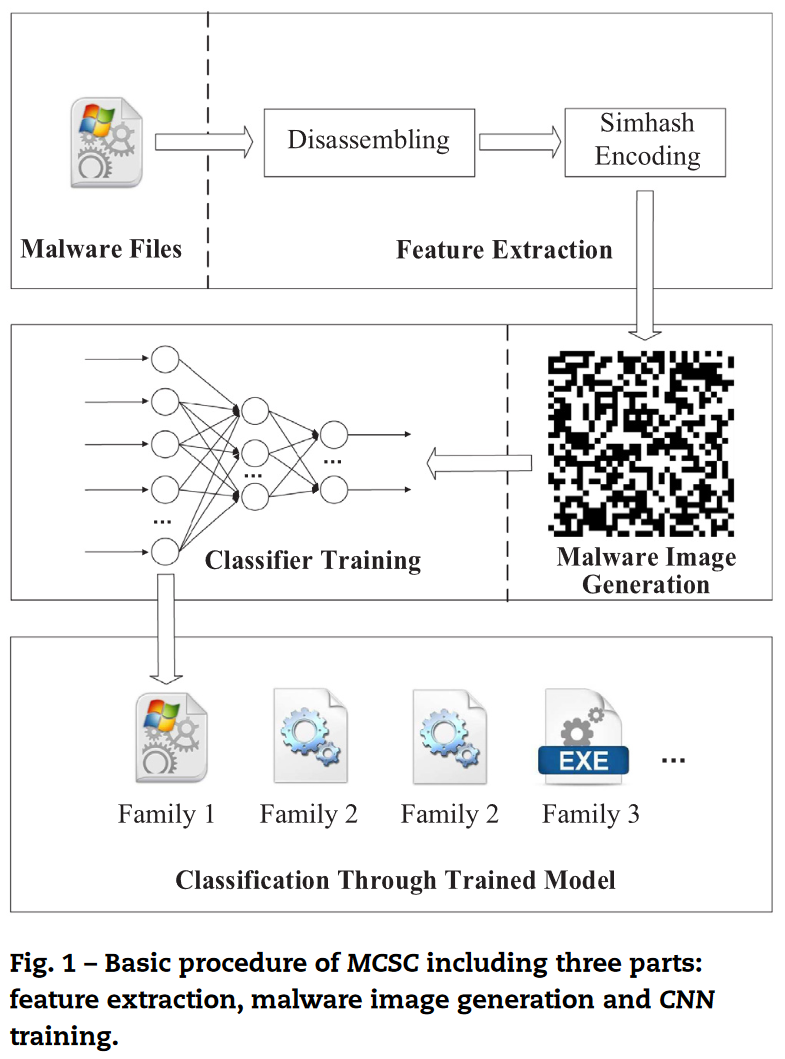
可分为三个部分:
-
Feature extraction(fig.3): 反汇编、提取操作码序列
-
Malware Image Generation
- 操作码视为关键字
-
Classification

Fig 3:操作码序列提取:
- 从PE文件反汇编得到asm文件(包含汇编代码的文件,以.asm后缀结尾)。
- 从汇编代码片段中提取操作码序列。

Fig4 SimHash的计算过程:
- 无论操作码序列有多长,都可以映射为一段向量。
Fig4 SimHash的计算过程,问题:
- 选择不同的Hash函数,向量长度可能不同,进而影响图像大小和分类效果。
Fig5 转换为图像后的结果。
其他细节
如上图fig 3,遍历完整个代码段吗?Major block selection(主要区块选择):
- 主要区块选择(Major block selection):选取含call指令的区块(函数块),call指令用以函数调用、自定义函数调用等。
- “According to the study of Kang et al. (2012), those blocks with CALL instructions should be selected as major blocks. The reason is that the CALL instruction, generally, is used to invoke APIs, library functions, and other user-defined functions, which are the basic implementation behaviors and functions of most programs. Fig. 8 indicates a procedure of major block selection.”
多哈希扩展(Multi-Hash extension):
-
多个hash函数级联得到更长的向量。
For example, SimHash-768 cascades SHA-512 and SHA-256. Similarly, SimHash-896 cascades SHA-512, SHA-256 and MD5.
不同哈希算法的影响:

双线性插值:
- 如上图,SHA-512并不能得到矩阵数据即正方形图像,文章用双线性插值。
- 如下图fig 7。
-

Discussion
SimHash中的加权
- 文章设定各操作码权重相等,有的研究指出不常见的操作码对分类效果更好。
- 在此基础上,是否有文献支持对操作码加权。
SimHash得到的向量:
- 常见Hash函数得到的位数太少,最后得到的图像很小。
- 整体的计算开销不大。
- 过分的数据压缩。
双线性插值
- 引入无意义的填充信息(数学表示上有意义),且本文最后得到的图像较小。
借鉴其他的词向量表征方法。
借鉴其他的文本相似度计算方法/降维/文本映射方法。
Reference
18-Trans-MinHash Opcode
Reference
论文翻译:使用深度学习和可视化技术识别恶意软件家族
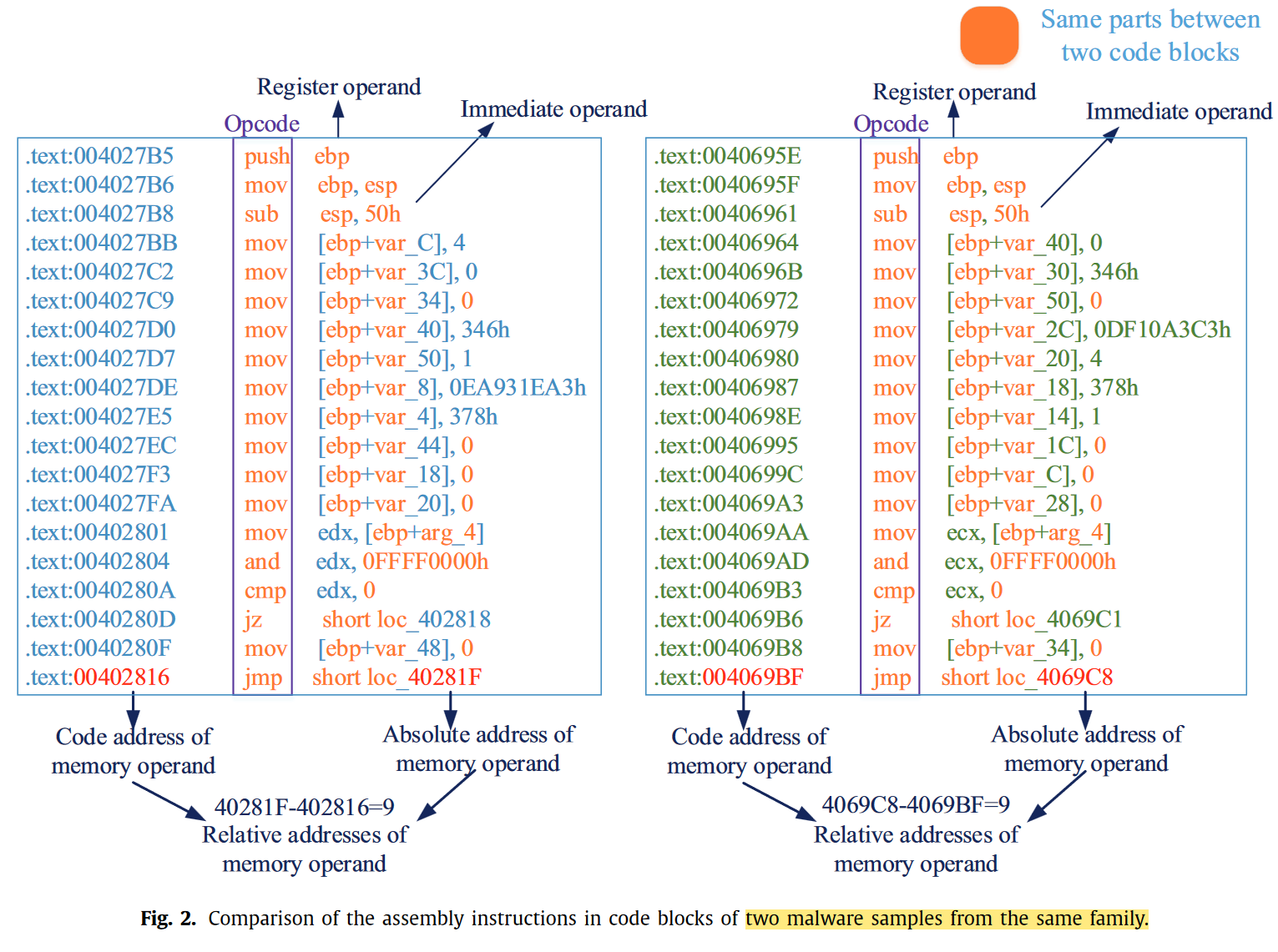
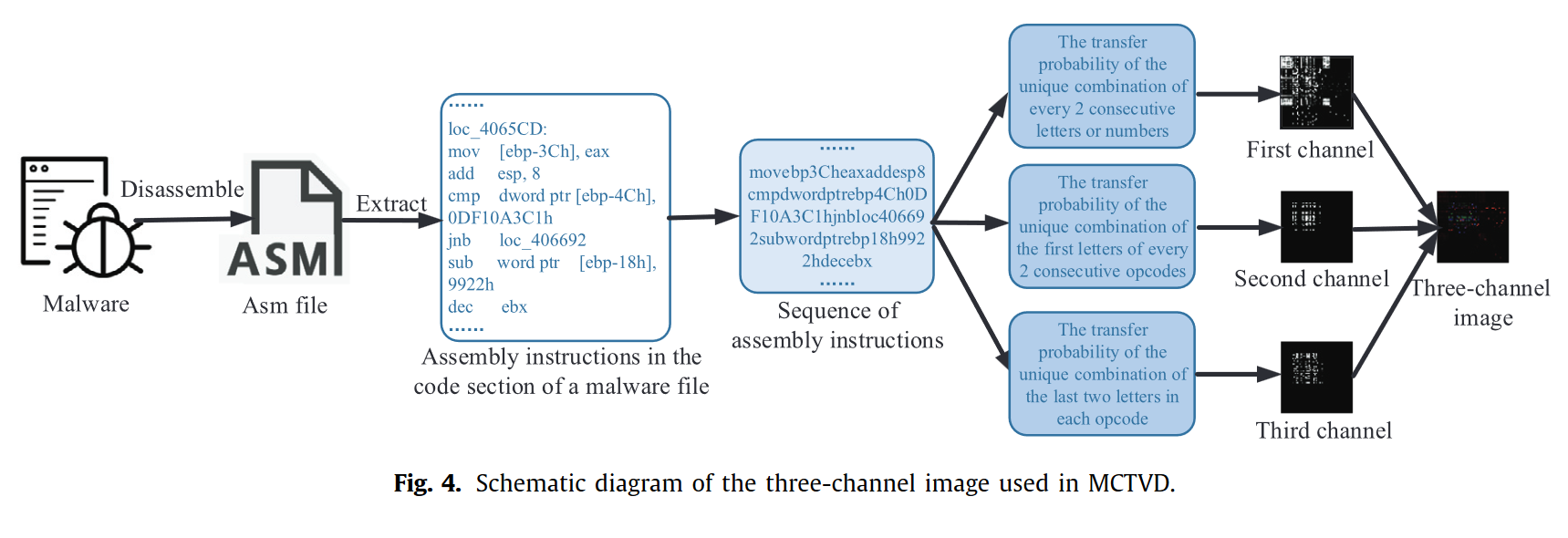
23-CS-MCTVD
标签:文件,特征,代码,操作码,图像,序列,SimHash From: https://www.cnblogs.com/handsome6/p/features-operating-code-sequence-1f1tbd.html