字符串
本文字符串下标从 \(1\) 开始。
\(S[l,r]\) 表示字符串 \(S\) 从 \(l\) 到 \(r\) 的部分。
速通
哈希
没什么可说的,我也不喜欢用。
trie
顾名思义,就是一个像字典一样的树。
基础
01trie
在一些题目中,可以用 trie 维护 01 串。
给定一棵 \(n\) 个点的带权树,求异或和最大的简单路径。
\(0\le n\le 10^5,0\le w<2^{31}\)。
solution
考虑树上两点路径的异或和可以转化为根到两点的异或和异或起来。
于是转化为求寻找两点使两点的权值的异或和最大。
用 trie 维护:不断插入一个数,查询这个数与已插入的数的最大异或和是多少(只要尽量保证前缀是 1)。
自动机
定义
自动机是一个对信号序列进行判定的数学模型。
比如说,你在初始状态,可以往几条路走,通过这几条路可以走到其他状态。
一个确定有限状态自动机(DFA,deterministic finite automation)由以下五部分构成:
(另外有个东西叫做 NFA,以后可能会提到)
- 字符集(\(\sum\)),该自动机只能输入这些字符。
- 状态集合(\(Q\)),顾名思义。
- 起始状态(\(st\)),同样顾名思义,\(st\in Q\)。
- 接受状态集合(\(F\)),\(F\subseteq Q\),或终止状态集合。
- 转移函数(\(\delta(x,y)\)),\(x\) 是一个状态,\(y\) 是字符串,意思就是从 \(x\) 开始,走一个字符串 \(y\) 。
以上的字符串均为广义的。
想要更快的理解,可以把 DFA 看做一个有向图,但是 DFA 只是一个数学模型。
另外不难发现 trie 也是自动机,我称其为广义前缀自动机。下面就拿 01trie 举个例子。
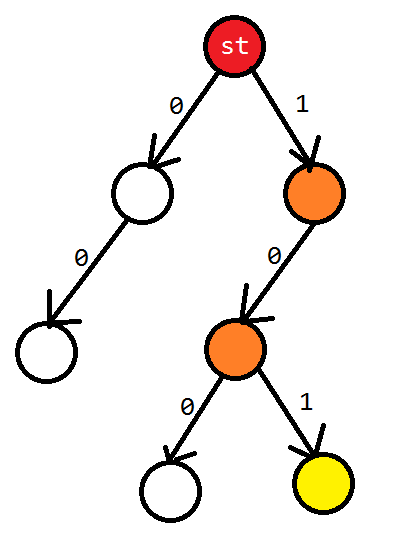
- \(\sum\):0/1。
- \(Q\):每个节点。
- \(st\):如图。
- \(F\):如图黄点。
- \(\delta\):\(\delta(st,101)\)。
边可以看做状态转移。
序列自动机
对于字符串 \(S\) 的一个子串 \(s\),\(\delta(st,s)\) 表示 \(s\) 在 \(S\) 中第一次出现时末位。
转移(\(u\) 是位置,\(c\) 是个字符):\(\delta(u,c)=\min(i|i>u,s_i=c)\)
可以通过记录下一个字符出现位置来实现。
给你两个由小写英文字母组成的串 \(A\) 和 \(B\),求:
- \(A\) 的一个最短的子串,它不是 \(B\) 的子序列。
- \(A\) 的一个最短的子序列,它不是 \(B\) 的子序列。
\(n\le2000\)
solution
第一个相对简单。直接枚举起点跑就行。
设 \(f_{i,j}\) 表示在 \(A\) 中到第 \(i\) 位,在 \(B\) 中到第 \(j\) 位的答案。
那么 \(f_{i,j}=\min\{f_{\delta(i,c),\delta(j,c)}+1\}\)
KMP
设 \(\mathrm p_i\) 表示前 \(i\) 位最长相同真前后缀长度。
对于字符串 \(\texttt{abbaabb}\)
- \(\mathrm p_1=0\):\(\texttt{a}\)
- \(\mathrm p_2=0\):\(\texttt{ab}\)
- \(\mathrm p_3=0\):\(\texttt{abb}\)
- \(\mathrm p_4=1\):\(\underline{\texttt{a}}\texttt{bb}\underline{\texttt{a}}\)
- \(\mathrm p_5=1\):\(\underline{\texttt{a}}\texttt{bba}\underline{\texttt{a}}\)
- \(\mathrm p_6=2\):\(\underline{\texttt{ab}}\texttt{ba}\underline{\texttt{ab}}\)
- \(\mathrm p_7=3\):\(\underline{\texttt{abb}}\texttt{a}\underline{\texttt{abb}}\)
处理出 \(\mathrm p_i\) 有什么用呢?
模式串在匹配文本串的时候,如果是以下这个状态:

发现到第五位时失配了,我们接下来肯定是想让它从蓝色这个状态继续匹配。
可以发现,跳到 \(\mathrm p_i\) 一定不劣。即比如在第五位失配了,就跳到 \(\mathrm p_4=1\) 位,如果跳到这里发现可以匹配下去,由于前后缀相同,所以可以继续匹配下去。如果不能匹配下去,那就继续往前跳。
由于每次只往后移动一格,往前跳的次数一定小于等于往后走的次数,复杂度 \(O(n)\)。
怎么求 \(\mathrm p\) 呢。
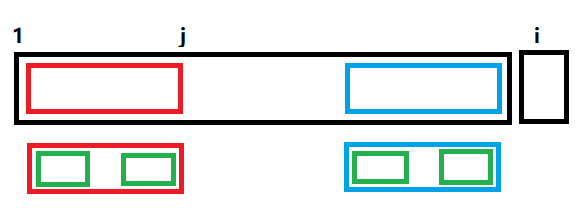
假设当前位是 \(i\),\(\mathrm p_{i-1}=j\)。如果 \(\mathrm p_i>\mathrm p_j\),那么 \(\mathrm p_i=\mathrm p_j+1\) 且 \(S_{j+1}=S_i\)。
否则,贪心地令 \(j=\mathrm p_j\),即上图绿框,可以发现如果此时 \(S_{j+1}=S_i\) 还是可以下去且最优。
最后,不难发现 kmp 的过程与求 \(\mathrm p\) 的过程类似,代码:
int j=0;
for(int i=2;i<=m;i++){
while(j&&b[i]!=b[j+1])j=pre[j];
j+=(b[i]==b[j+1]);pre[i]=j;
}
j=0;
for(int i=1;i<=n;i++){
while(j&&a[i]!=b[j+1])j=pre[j];
j+=(a[i]==b[j+1]);
if(j==m)write(i-m+1,'\n'),j=pre[j];
}
KMP自动机
用 KMP 建出的自动机,转移:
\[\delta(x,c)=\begin{cases} x+1&S_{x+1}=c\\ 0&i=0\land S_1\neq c\\ \delta(\mathrm p_x,c)&i>0\land S_{x+1}\neq c\\ \end{cases} \]求有多少个 \(N\) 位数字文本串满足:没有一个子串为给定模式串。
模式串长度为 \(M\),对 \(K\) 取模。
\(N\leq10^9,M\leq20,K\leq1000\)
solution
dp,设 \(f_{i,j}\) 表示文本串中匹配到第 \(i\) 位,模式串中匹配到第 \(j\) 位的方案数。
那么:
\[\begin{aligned} f_{i,j}=&\sum _c\sum_{k,\delta(k,c)=j}f_{i-1,k}\\ =&\sum_{k}f_{i-1,k}\sum _c[\delta(k,c)=j]\\ \end{aligned} \]设矩阵 \(g\) 有: \(\displaystyle g_{k,j}=\sum _c[\delta(k,c)=j]\),就可以把转移看做向量乘上矩阵。
又发现 \(g\) 与 \(i\) 无关,于是矩阵快速幂。
失配树
border
任意长度相同前后缀。
失配树
考虑一个问题:
给定 \(S\),\(T\) 次询问 \(p,q\),求 \(p\) 前缀和 \(q\) 前缀的最长公共 border。
首先,根据 KMP 中 \(\mathrm p_i\) 的定义,从一个点开始不断往上跳 \(\mathrm p_i\),跳到的就是它的所有 border。
而仔细思考后发现一个点向它的 \(\mathrm p_i\) 连边,连出来的就是一个树形结构,我们称其为失配树。
而两段前缀的最长公共 border 转化为了失配树上的 LCA。
求出对于 \(S\) 每个前缀的不相交 border 个数。
对于一个前缀 \(S[1,i]\) 求不相交 border 可以转化为长度 \(\le \frac{i}2\),所以我们就可以在失配树上往上跳,跳到符合条件,深度就是答案。
可以不用显式建树。
Z 函数
令 \(\mathrm z_i\) 表示一个字符串 \(s\) 和 \(s[i,n]\) 的 LCP,特别的,\(\mathrm z_1=0\)。
对于字符串 \(\texttt{aaabaab}\)
- \(\mathrm z_1=0\):
- \(\mathrm z_2=2\):\(\underline {\texttt{a}\underline{\texttt{a}}}\underline{\texttt{a}}\)
- \(\mathrm z_3=1\):\(\underline {\texttt{a}}\texttt{a}\underline{\texttt{a}}\)
- \(\mathrm z_4=0\):
- \(\mathrm z_5=2\):\(\underline{\texttt{aa}}\texttt{ab}\underline{\texttt{aa}}\)
- \(\mathrm z_6=1\):\(\underline{\texttt{a}}\texttt{aaba}\underline{\texttt{a}}\)
- \(\mathrm z_7=0\):
Z 函数其实也很好求:
从某个位置 \(i\) 开始,与整串前缀相同的前缀(称为 Z-box)为 \(s[i,i+\mathrm z_i-1]\)。
我们维护当前 \(i+\mathrm z_i-1\) 的最大值 \(r\),以及其对应的 \(i\) ,令其为 \(l\)。
假设我们已经求出 \(1\sim i-1\) 的 Z 函数,接下来要求 \(\mathrm z_i\)。
根据定义,有 \(s[i,r]=s[i-l,r-l]\),所以,\(\mathrm z_i\ge\min({\mathrm z_{i-l}},r-i+1)\)。
如果还有机会继续拓展(\(r-i+1\le \mathrm z_{i-l}\)),那就右移 \(r\),否则就 G 了。
l=1,r=0;
for(int i=2;i<=m;i++){
if(i<r)z[i]=min(z[i-l+1],r-i+1);
while(i+z[i]<=m&&b[i+z[i]]==b[z[i]+1])++z[i];
if(i+z[i]-1>=r)r=i+z[i]-1,l=i;
}
匹配另一个串
拼起来再做一遍即可。
但是注意拼起来时中间放一个随便什么引荐字符,避免匹配到后面的串。
给字符串 \(S\),求 \(S = {(AB)}^iC\) 的方案数,设 \(F(S)\) 表示 \(S\) 中出现奇数次的字符数量,有 \(F(A)\le F(C)\)。定义乘法为前后拼接。
solution
枚举循环节长度:
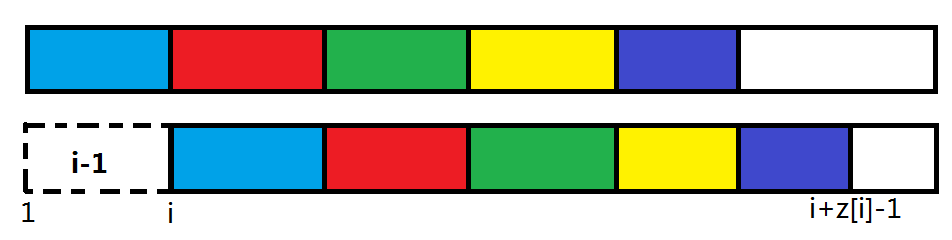
如图为长度为 \(i-1\) 的循环节,不难发现有颜色的段是完全相同的,而且不能再往后延伸一段。
可以得出,最大循环节段数为 \(t_i=\displaystyle\left\lfloor\frac{\mathrm z_i}{i-1}\right\rfloor+1\)。注意:为了最后留至少一个字符给 \(C\),所以如果循环节把整串排满了,要 \(-1\)。
设 \(pre_i\) 表示 \(S[1,i]\) 中出现奇数次的字符数量,\(suf_i\) 表示 \(S[i,n]\) 中出现奇数次的字符数量。
对循环节段数 \(k\) 奇偶分类讨论:
\(k\equiv1\pmod 2\)
不难发现,段数为奇数时,\(F(C)\) 保持不变(两个不同的奇数 \(k\) 对应的串 \(C\) 只差偶数段循环节,正好抵消了)。
所以,我们只要找到 \(S[1,j](j<i)\) 使得 \(F(A)=pre_j\le F(C)=suf_i\)(算 \(k=1\) 时的 \(F(C)\))。
这部分的贡献为:满足条件的 \(j\) 的个数 \(\times\) 满足条件的 \(k\) 的个数。
\(k\equiv0\pmod 2\)
段数为偶数时 \(F(C)\) 也保持不变(原因同上),且等于 \(suf_1\)。
所以,我们只要找到 \(S[1,j](j<i)\) 使得 \(F(A)=pre_j\le F(C)=suf_1\)。
这部分的贡献为:满足条件的 \(j\) 的个数 \(\times\) 满足条件的 \(k\) 的个数。
然后发现做完了。