在单机系统中,所有的数据都存储在同一个服务器下,当数据量越来越多的时候,超过了单机存储容量的上限,就需要使用分布式存储系统,在分布式存储系统重,数据会被拆分到不同的存储服务下,减少单机服务的压力。
哈希算法
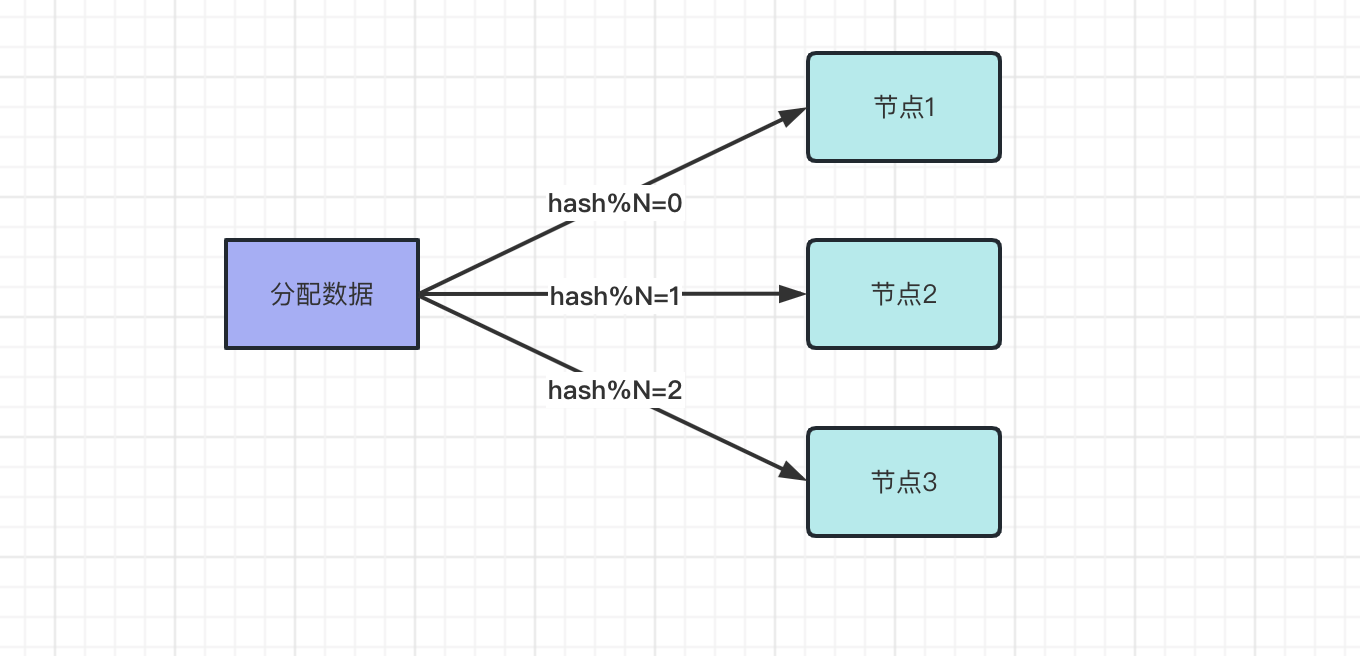
在分布式系统中,每个节点存储的数据都是不同的。通过使用分布式存储,将数据水平拆分到不同的节点上,新的数据也会分配到新的节点上,比如使用取模方式分配节点,先用hash算法算出hash值,然后使用hash/N,N是节点数,比如三个节点。
- 取模值=0,分配节点1
- 取模值=1,分配节点2
- 取模值=2,分配节点3
如果节点数量是固定的,数据分配方式是固定的,获取数据的方式也是固定,数据也能正常的获取。
如果节点数量发生了变化,新增或者减少节点时,比如新增节点4,原来分配到节点1的数据被分配到节点4,原来的数据映射都无效,数据也无法正常获取了。这就需要使用到一致性哈希算法。
一致性哈希
一致性哈希,从名字就能看出来,该算法符合一致性原则,当服务节点数量增加或减少,数据还能正常获取到。那一致性哈希有什么神奇的地方呢?先介绍什么是一致性哈希:
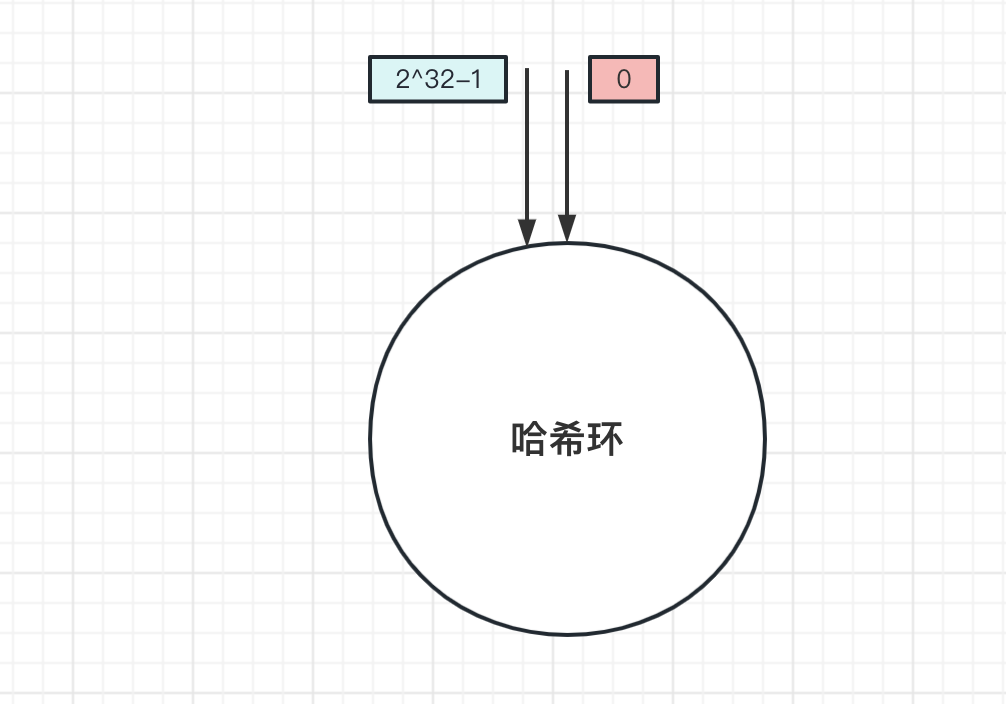
上面是一个哈希环,环上有2^32个节点。和上面取模算法一样,一致性哈希算法也是取模算法,不同的是一致哈希算法是对2^32个节点取模运算,哈希环的节点是固定的,取模运算结果值也是固定的。
- 数据先进行哈希运算,获取哈希值。
- 对哈希值对
2^32取模运算。
取模后的值一定是在哈希环上。那是如何找到存储的节点呢?答案在环上往顺时针方向找到第一个节点。
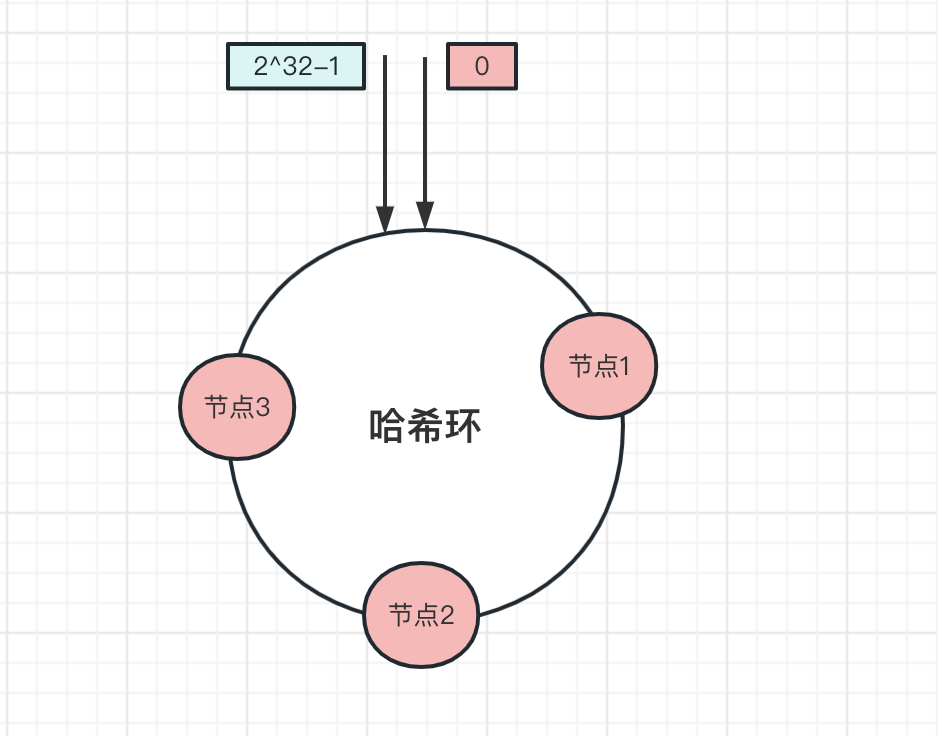
比如哈希环上,有三个节点,分别是节点1、节点2、节点3,平均分布在哈希环上:
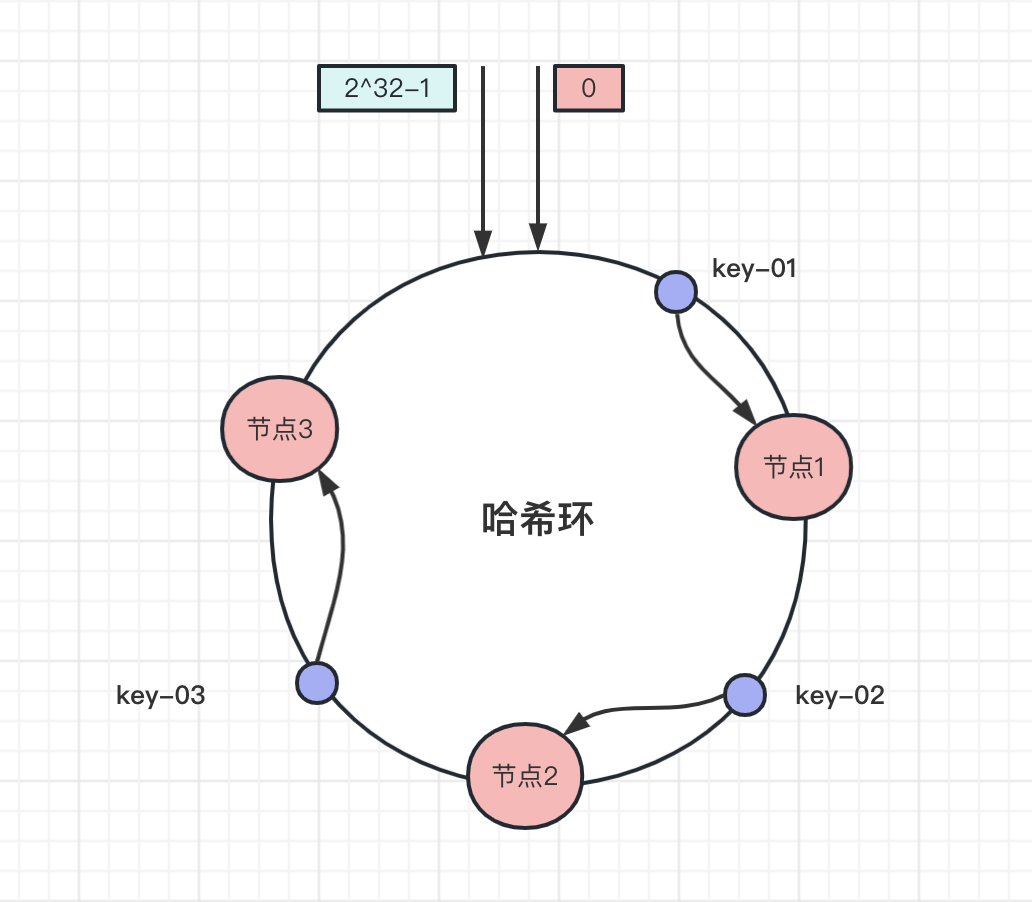
新增一个数据,先算出来哈希值,确定该数据在哈希环上的位置,然后从这个位置顺时针方向找到第一个节点,就是存储数据的节点。
比如下图中数据key-01,先算出该数据在哈希环的位置,往顺时针方向找到第一个节点,也就是节点1,同理key-02、key-03顺时针分别找到节点2和节点3:
增减节点
增加一个节点之后,比如新增加一个节点4,经过哈希计算获取节点的位置:
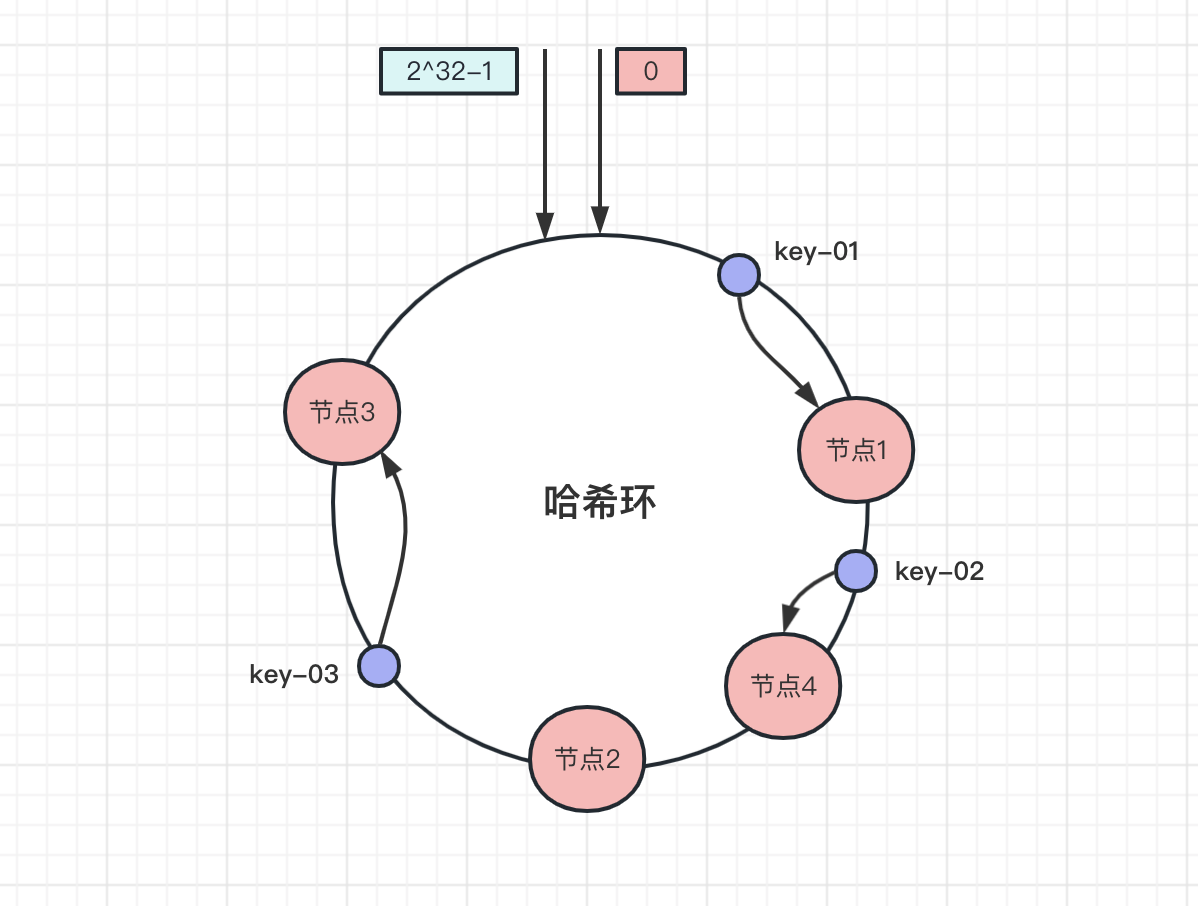
可以看到,此时key-01和key-03数据不受影响,key-02存储的节点从节点2迁移到了节点4。
那减少一个节点,移除节点1:
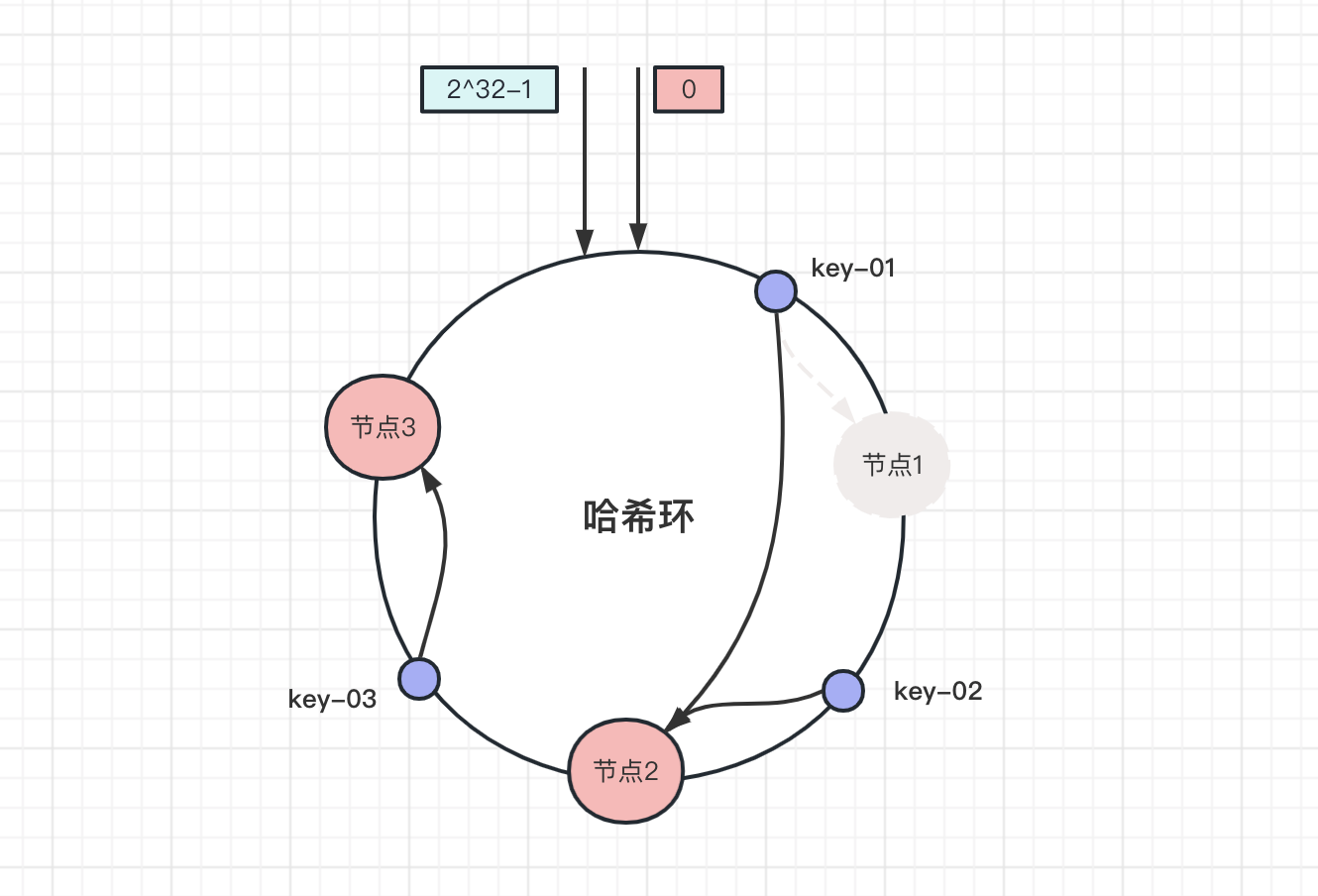
此时key-02和key-03数据不受影响,只有key-01被迁移到节点2。
在一致性哈希上,增加或减少节点,影响的节点从新节点逆时针方向到上一个节点的数据。
对服务器节点扩容或者缩容,影响的数据只占整体数据一小部分,对整体系统的影响不大,对于数据准确性要求多的数据则不适用一致性哈希。
数据倾斜
上面数据是均匀的分布在哈希环上,每个节点的存储压力都比较均衡,但是一致性哈希并不能保证数据会平均的分布在各个节点上,当大量的数据都分布在同一个节点上,如下图所示,大量的节点都分布在节点3上:
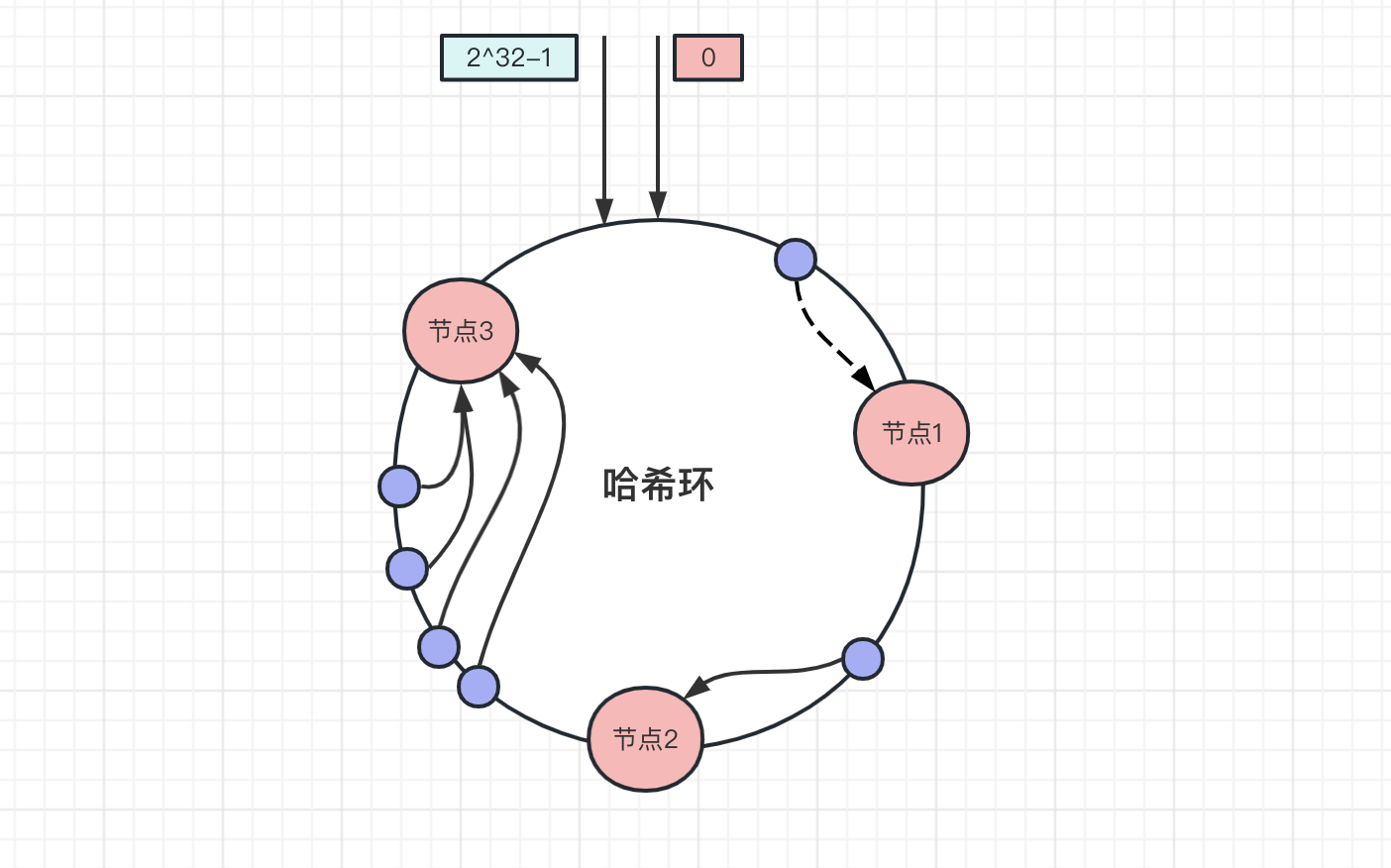
此时请求访问数据主要是集中在节点3上,而环上的节点服务器配置基本是一致的,不会因为某个服务器压力大,就单独加大某个服务器的配置。节点3数据存储和访问量是其他节点的几倍以上,当请求压力超过了服务处理的上限后,就会导致节点3崩溃,节点3挂了之后,全部数据压力都会转移到节点1,节点1也会宕机,最后形成雪崩。
数据倾斜解决
为了解决数据倾斜问题,一致性哈希算法引入了虚拟节点,一个节点对应多个虚拟节点,上面三个真实节点,每个节点引入3个虚拟节点:
节点1引入三个虚拟节点:1A、1B、1C节点2引入三个虚拟节点:2A、2B、2C节点3引入三个虚拟节点:3A、3B、3C
引入虚拟节点之后,环上一共有9个节点:

节点数量多了之后,数据在哈希环上的分布就更加均匀了,就不容易出现上面数据倾斜的问题,当有数据存储到1A虚拟节点,在通过1A虚拟节点就能找到真实节点节点1了。
在实际应用中,虚拟节点的数量远大于上面虚拟节点数量。虚拟节点越多,对应的数据分布就更加的均匀。比如Nginx的一致性哈希算法中的虚拟节点就有160个。
虚拟节点除了使数据分布更加均衡之外,也会极大的提高数据的稳定性,当节点的数量变化时,会有不同的节点分担数据的请求压力,而不会像上面一样,当一个节点挂了,数据全都转到另一个节点上,导致雪崩发生。
总结
- 常见的哈希算法,先计算出哈希值,再根据服务数量取模(hash%N),将数据存储到固定的服务器下。
- 当节点增加或者减少,N发生了变化,原来
hash%N方式都失效了,数据也无法正常的获取了。
- 当节点增加或者减少,N发生了变化,原来
- 一致性哈希算法就是为了解决节点数量发生变化时,数据一致性的问题。
- 在一个环上有
2^32节点,新增一个数据,先算出来哈希值,然后取模,算出来在环上的位置,往顺时针找到第一个服务节点,就是存储的服务节点。 - 如果添加或者减少服务,比如服务挂了,或者服务扩容了。只是影响从新的服务节点逆时针方向摘到的第一个服务节点,其他数据不受影响。
- 在一个环上有
- 哈希环数据分布不均匀时,出现
数据倾斜,就需要引入虚拟节点,一个服务节点对应多个虚拟节点,访问数据请求到虚拟节点,再找到对应的真实服务节点。虚拟节点越多,数据的分布就越均衡。同时,新增或者减少节点,会有不同的服务节点分摊压力,使服务更加稳定。