前言 目标检测一般包括分类和回归两个子任务。在模型训练的过程中,本文依据回归任务的预测结果动态分配分类任务的标签,同时利用分类任务的预测结果来分配回归任务的标签,以此达到相互指导、左右互搏的效果。
本文转载自计算机视觉研究院
作者 | Edison_G
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

源代码地址:https://github.com/ZHANGHeng19931123/MutualGuide
一、背景
有监督的目标检测是计算机视觉中的一项流行任务,旨在通过边界框定位目标并将它们中的每一个分配给预定义的类。基于深度学习的方法在很大程度上主导了这个研究领域,最近的方法都是基于Anchor机制的。Anchors是在整个图像上均匀堆叠的不同大小和纵横比的预定义参考框。它们通过将目标检测问题转换为基于Anchor的边界框回归和分类问题,帮助网络处理目标尺寸和形状变化。大多数最先进的基于Anchor的目标检测器采用预定义的Anchor boxes和GT框(以下称为 IoU-anchor)之间的交集(IoU)来将样本Anchor分配给目标(正样本Anchor)或背景(负样本Anchor)类别。然后使用这些分配的Anchors来最小化训练期间的边界框回归和分类损失。

Anchor A和Anchor B与框GT具有相同的IoU,但具有不同的视觉语义信息。每个图像中的真实情况标记为虚线框。
基于深度学习的目标检测涉及两个子任务:实例定位和分类。这两个任务的预测分别告诉我们图像上的“位置”和“什么”目标。在训练阶段,两个任务都通过梯度下降联合优化,但是静态Anchor匹配策略并没有明确受益于两个任务的联合解决方案,这可能会导致任务错位问题,即在评估阶段 ,该模型可能会生成具有正确分类但不精确定位的边界框的预测,以及具有精确定位但错误分类的预测。这两种预测都显着降低了整体检测质量。
二、前言
为了解决现有基于IoU-anchor策略的这两个局限性,研究者提出了一种新的自适应Anchor匹配准则,由定位和分类任务相互指导,动态分配训练Anchor样本为优化分类,反之亦然。特别是,将定位良好的Anchor限制为也很好分类(定位到分类),以及那些分类良好的Anchor也很好定位(分类到定位)。这些策略导致内容/上下文敏感的Anchor匹配并避免任务错位问题。尽管所提出的策略很简单,但在PASCAL VOC和MS COCO数据集上,尤其是在严格的指标(如AP75)上,Mutual Guidance与具有不同深度学习架构的传统静态策略相比,带来了一致的平均精度 (AP) 增益。
新提出的方法有望在需要精确实例定位的应用程序上更有效,例如自动驾驶、机器人、户外视频监控等。
三、新框架
传统的Anchor通常是预先定义了一组Anchor的aspect ratio,在实际的滑窗训练过程中先用二分类模型判断这些Anchor的框内有没有物体,并根据设定的阈值将sample标注为positive或者negative或者ignored,然后进行bonding box回归进行refine,最后做多分类再回归调整位置。
这里作者将预定义的Anchor和GT的IoU叫做IoU-anchor,IoU-anchor大于50%的作为positive,小于40%作为negative,其他作为ignored samples。如果没有Anchor的大于50%,那就选最大的IoU的那个作为positive。如下图所示:
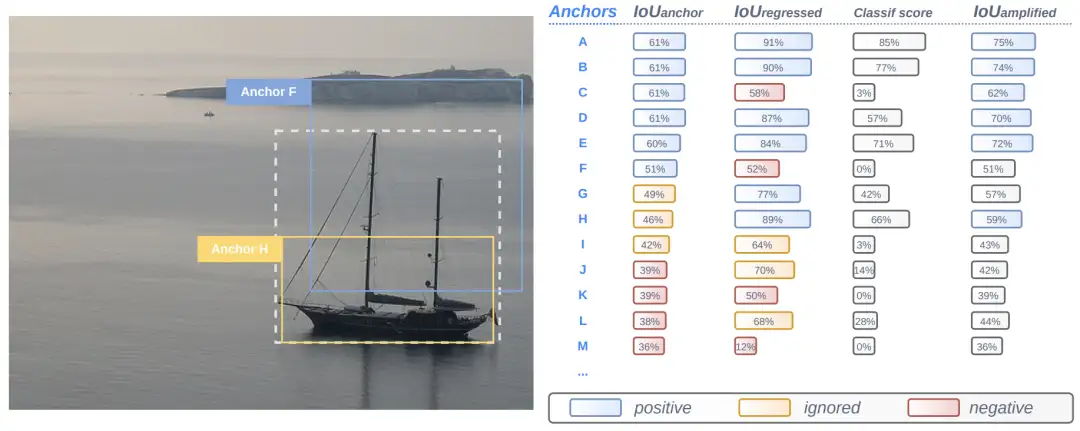
- 定位到分类(Localize to Classify)
动态设置述分类方法中正负样本的阈值。因为随着训练进行,正样本变多(因为二分类模型能力逐渐增强,但是阈值没变),作者认为这样会导致训练不稳定。
于是作者将拟将分类模型的分类能力纳入阈值设置考量范围以动态设置阈值:在根据IoU-regressed标注确定正负样本的时候不再直接采用固定阈值,而是根据IoU-anchor中的正样本数量n来选取IoU-regressed的前n个样本标注为positive,其他negative和ignored同理。
这种策略能够随着定位能力提高而提高,同时也保持了训练过程中正负样本分配的一致性!
- 分类到定位(Classify to localize)
在分类早期,模型处于初始状态,大多数分类的结果都接近于0,存在类似于推荐系统的冷启动问题同时也可能使得训练不稳定,所以研究者定义了一个Classify to localize的策略来避免这种问题。
首先作者定义了一个IoU-amplified用于替换传统的IoU-regressed,其表达式如下:
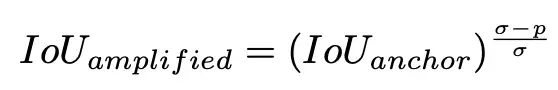
其中σ是超参用于调整的增强系数,p是分类得分。此外,这一部分也采用了类似于前面定位到分类部分动态阈值设置的策略来设置这里的正样本阈值。
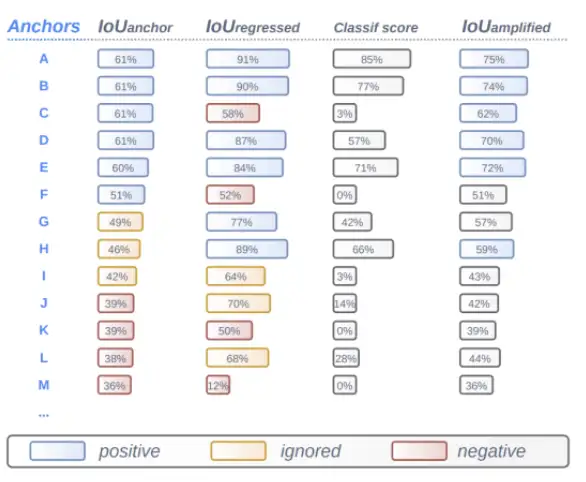
显然开始时与GT的iou较大的anchor box置信度一般更高,被选中的概率也更高;当iou相同时,置信度p较高的anchor得到的IOUamplified也更大。上图的第四列是直接预测的置信度,第五列是amplified之后的score。可以发现amplified后的结果与iou和p都有关。
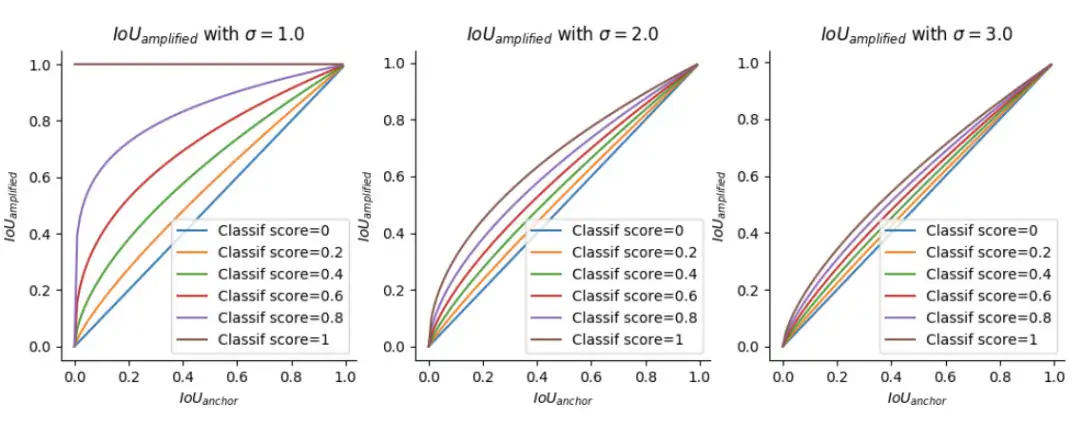
IoU-amplifed总是高于IoU-anchor,并且amplification与预测的Classif分数成正比。特别是σ越小amplification越强(注意σ要大于1),σ变大时就消失。通过这种交互作用,训练过程能够让回归好分类差的Anchor尽可能地提升分类精度,同样让分类好但回归差的Anchor尽可能地提升回归精度,从而一定程度解决 task-misalignment问题。
四、实验及可视化
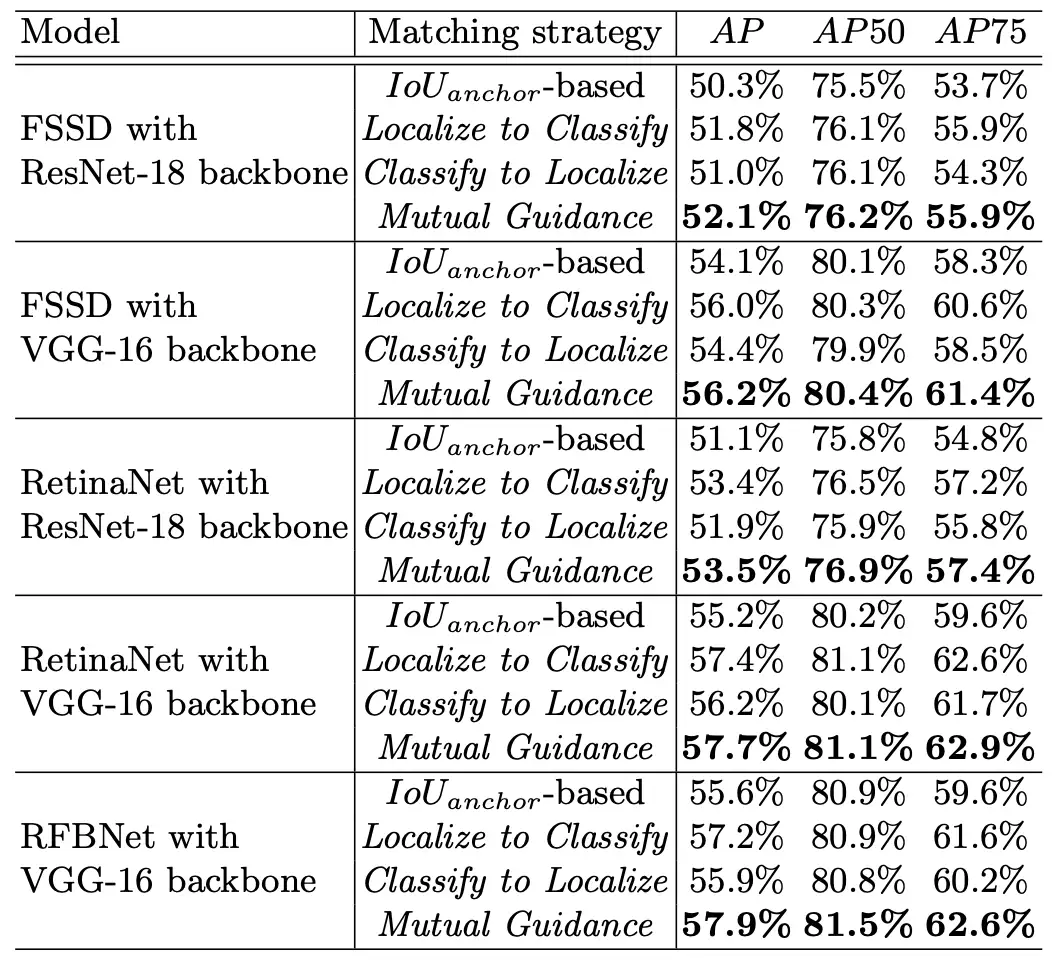
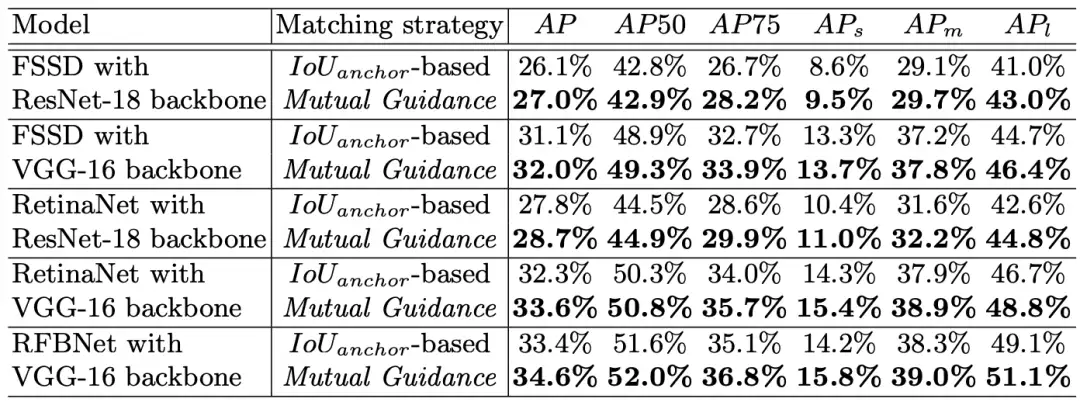

训练阶段标签分配差异的可视化(图像大小设置为320×320像素)。红色、黄色和绿色Anchor框分别是由基于IoU-anchor、Localize to Classify和Classify to Localize分配的正样本Anchor。

欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
标签:样本,训练,IoU,分类,Anchor,anchor,源代码,LCCL,精度 From: https://www.cnblogs.com/wxkang/p/17180536.html