现象
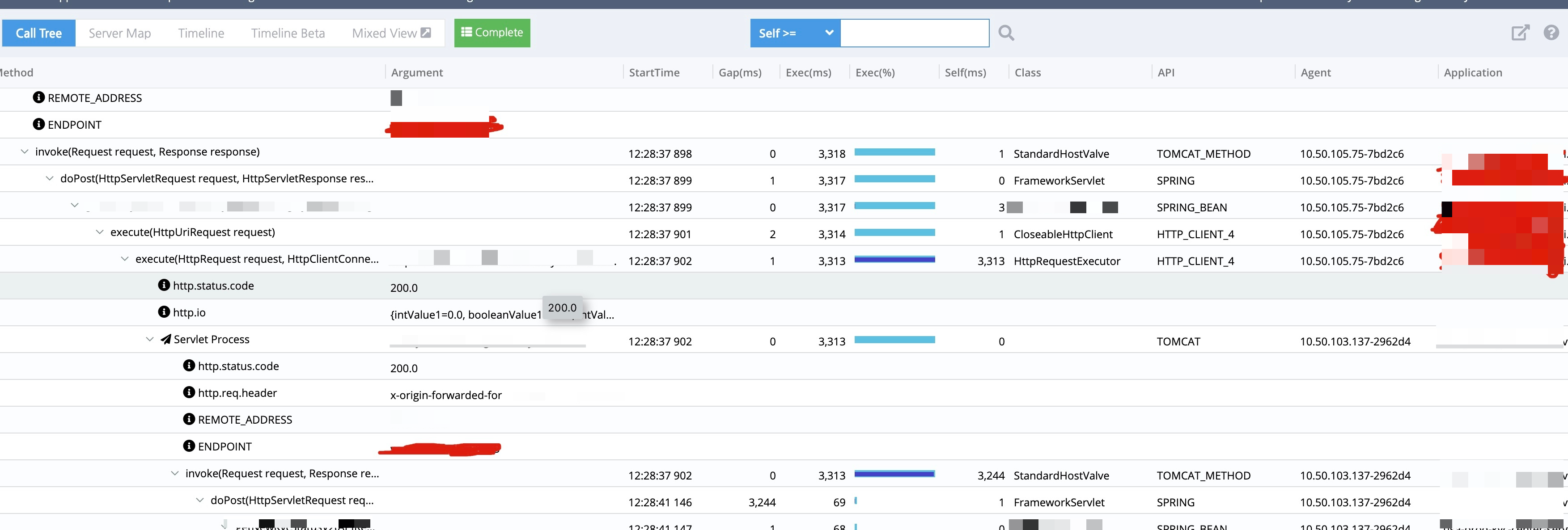
线上某个服务有接口非常慢,通过监控链路查看发现,中间的 GAP 时间非常大,实际接口并没有消耗很多时间,并且在那段时间里有很多这样的请求。
原因分析
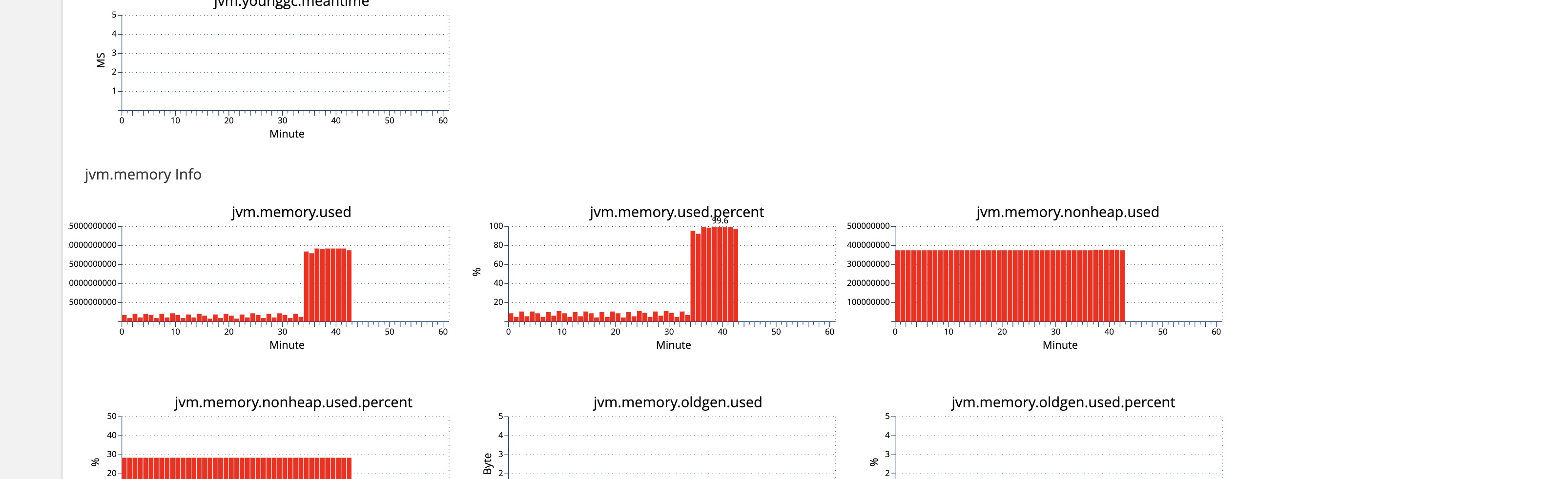
先从监控链路分析了一波,发现请求是已经打到服务上了,处理之前不知道为什么等了 3s,猜测是不是机器当时负载太大了,通过 QPS 监控查看发现,在接口慢的时候 CPU 突然增高,同时也频繁的 GC ,并且时间很长,但是请求量并不大,并且这台机器很快就因为 Heap满了而被下掉了。
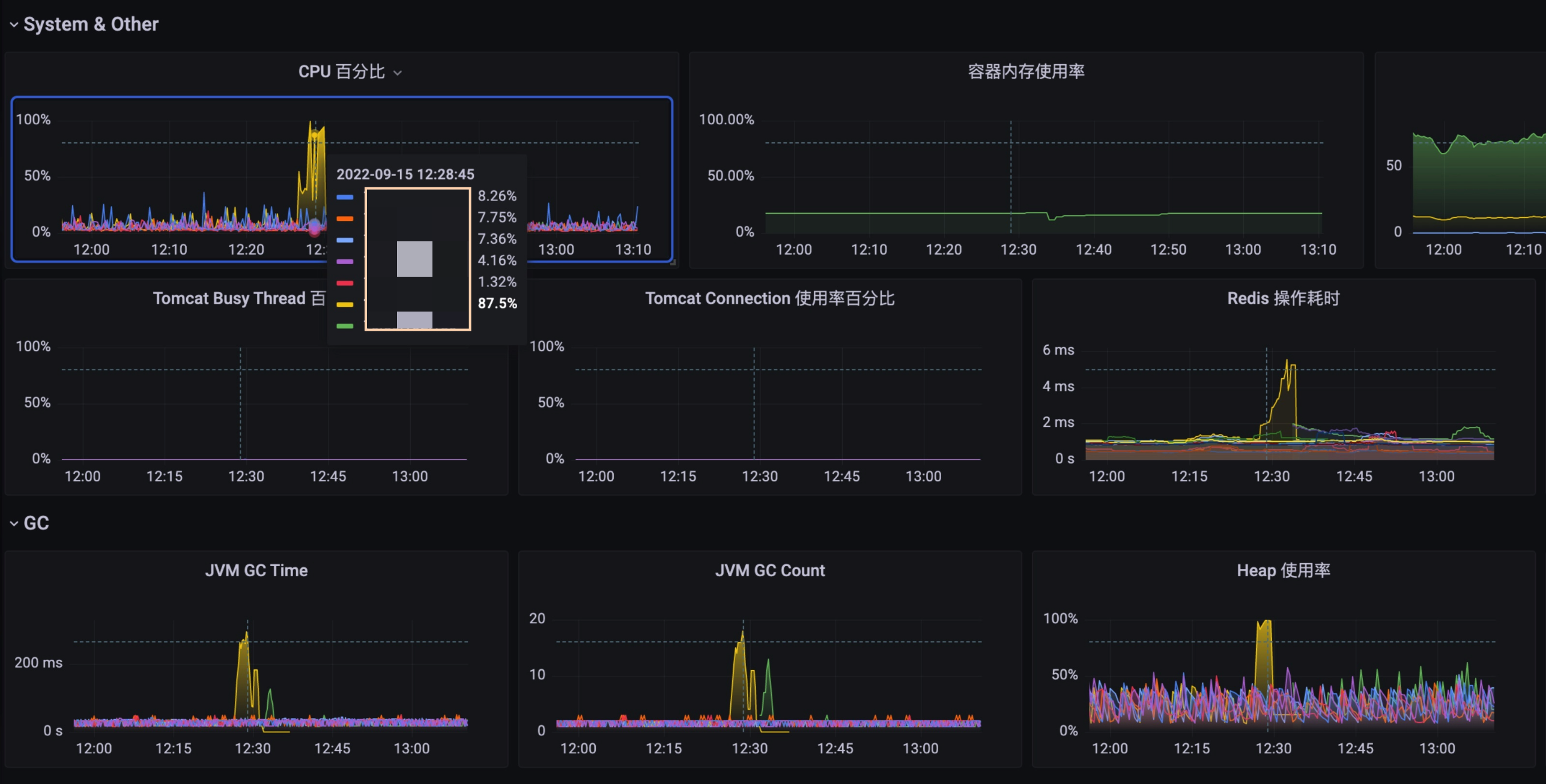
去看了下日志,果然有 OOM 的报错,但是从报错信息上并没办法找到 Root Cause。
system error: org.springframework.web.util.NestedServletException: Handler dispatch failed; nested exception is java.lang.OutOfMemoryError: Java heap space at org.springframework.web.servlet.DispatcherServlet.doDispatch(DispatcherServlet.java:1055) at org.springframework.web.servlet.DispatcherServlet.doService(DispatcherServlet.java:943) at org.springframework.web.servlet.FrameworkServlet.processRequest(FrameworkServlet.java:1006) at org.springframework.web.servlet.FrameworkServlet.doPost(FrameworkServlet.java:909) at javax.servlet.http.HttpServlet.service(HttpServlet.java:681)
另外开发同学提供了线索,在发生问题的时候在跑一个大批量的一次性 JOB,怀疑是不是这个 JOB 导致的,马上把 JOB 代码拉下来分析了下,JOB 做了分批处理,代码也没有发现什么问题。
虽然我们系统加了下面的 JVM 参数,但是由于容器部署的原因,这些文件在 pod 被 kill 掉之后没办法保留下来。
-XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=/logs/oom_dump/xxx.log -XX:HeapDumpPath=/logs/oom_dump/xxx.hprof
这个现象是最近出现的,猜测是最近提交的代码导致的,于是去分析了最近提交的所有代码,很不幸的都没有发现问题。。。
在分析代码的过程中,该服务又无规律的出现了两次 OOM,只好联系运维同学优先给这个服务加了 EFS (Amazon 文件系统)等待下次出现能抓住这个问题。
刚挂载完 EFS,很幸运的就碰到了系统出现 OOM 的问题。
dump 出来的文件足有 4.8G,话不多说祭出 jvisualvm 进行分析,分析工具都被这个dump文件给搞挂了也报了个java.lang.OutOfMemoryError: Java heap space,加载成功之后就给出了导致OOM的线程。
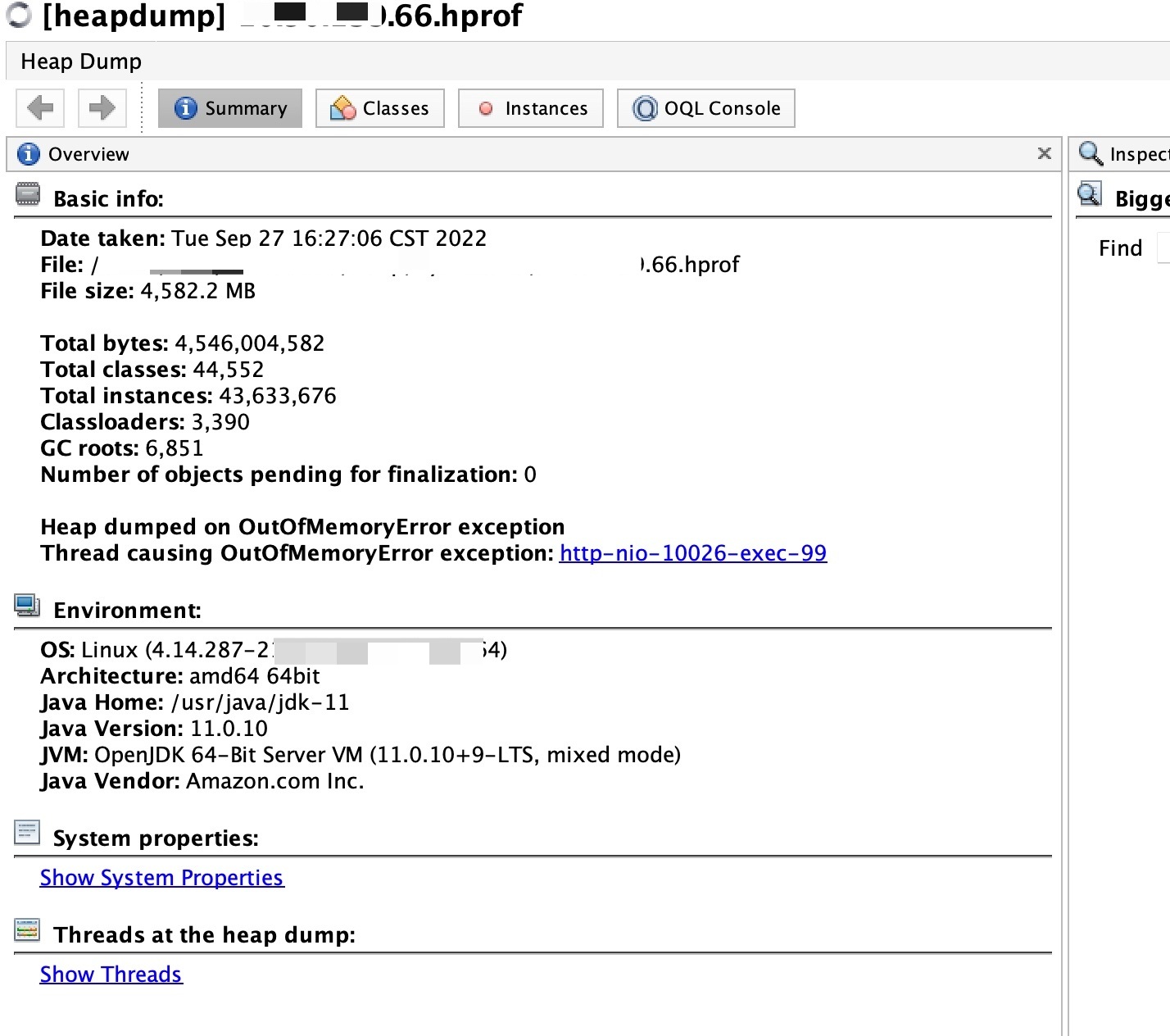
找到了具体报错的代码行号,翻一下业务代码,竟然是一个查询数据库的count操作,这能有啥问题?
仔细看了下里面有个foreach遍历userId的操作,难道这个userId的数组非常大?

找到class按照大小排序,占用最多的是一个 byte 数组,有 1.07G,char 数组也有1.03G,byte 数组都是数字,直接查看 char 数组吧,点进去查看具体内容,果然是那条count语句,一条 SQL 1.03G 难以想象。。。

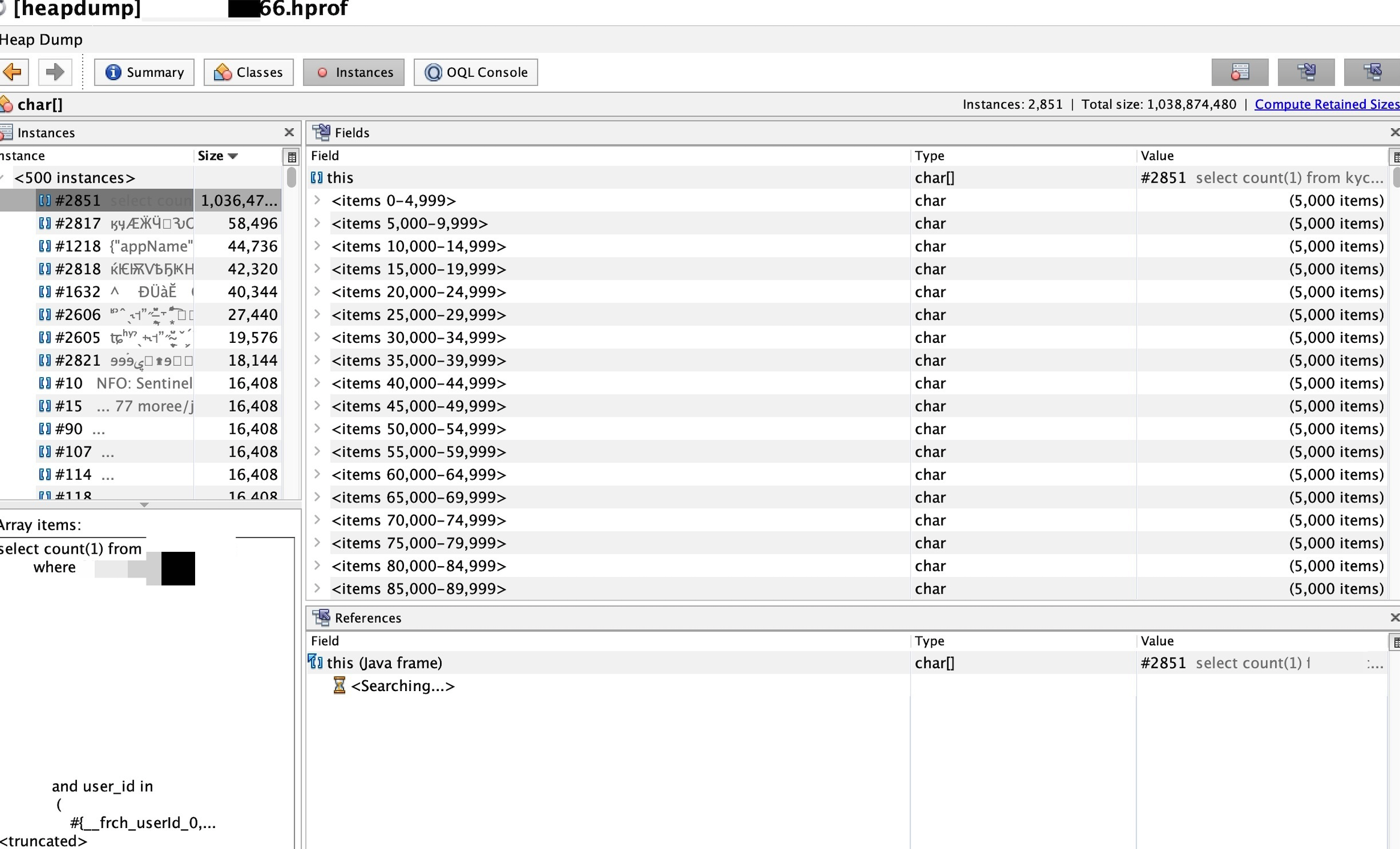
这个userId的数据完全是外部传过来的,并没有做什么操作,从监控上看,这个入参有 64M,马上联系对应系统排查为啥会传这么多用户过来查询,经过一番排查确认他们有个bug,会把所有用户都发过来查询。。。到此问题排查清楚。
解决方案
对方系统控制传入userId的数量,我们自己的系统也对userId做一个限制,问题排查过程比较困难,修改方案总是那么的简单。
别急,还有一个
看到这个问题,就想起之前我们还有一个同样类似的问题导致的故障。
也是突然收到很多告警,还有机器 down 机的告警,打开 CAT 监控看的时候,发现内存已经被打满了。
操作和上面的是一样的,拿到 dump 文件之后进行分析,不过这是一个漫长的过程,因为 down了好几台机器,最大的文件有12GB。
通过 MAT 分析 dump 文件发现有几个巨大的 String(熟悉的味道,熟悉的配方)。

接下来就是早具体的代码位置了,去查看了下日志,这台机器已经触发自我保护机制了,把代码的具体位置带了出来。
经过分析代码发现,代码中的逻辑是查询 TIDB(是有同步延迟的),发现在极端情况下会出现将用户表全部数据加载到内存中的现象。

于是找 DBA 拉取了对应时间段 TIDB 的慢查询,果然命中了。

总结
面对 OOM 问题如果代码不是有明显的问题,下面几个JVM参数相当有用,尤其是在容器化之后。
-XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=/logs/oom_dump/xxx.log -XX:HeapDumpPath=/logs/oom_dump/xxx.hprof
另外提一个参数也很有用,正常来说如果程序出现 OOM 之后,就是有代码存在内存泄漏的风险,这个时候即使能对外提供服务,其实也是有风险的,可能造成更多的请求有问题,所以该参数非常有必要,可以让 K8S 快速的再拉起来一个实例。
-XX:+ExitOnOutOfMemoryError
另外,针对这两个非常类似的问题,对于 SQL 语句,如果监测到没有where条件的全表查询应该默认增加一个合适的limit作为限制,防止这种问题拖垮整个系统。