前言 本章分别从硬件层面和软件层面对 CUDA 编程模型进行描述。主要讨论 GPU 的并行计算是如何在硬件上实现的,CUDA 中的模块理解以及 CPU和 GPU 之间的交互,指令的同步。这部分内容比较抽象和枯燥,希望大家耐心看完。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
一 GPU 架构与异构并行计算
什么是异构并行计算
最初的计算机只包含中央处理器,为了处理越来越复杂的图形计算,GPU 营运而生,因其数据众多的轻量级线程,非常适合处理大规模异构并行计算。
下图所示是一个典型的异构并行架构,包括一个 CPU及其内存 和一个 GPU及其内存,GPU 设备端通过 PCIe 总线与基于 CPU 主机端进行交互。一个异构并行应用包括主机代码和设备代码,分别运行在主机端和设备端。应用由 CPU 初始化,在设备端进行数据运算前,CPU 负责管理设备端的环境,代码和数据。我们称 host 为 CPU 及其内存,device 为 GPU 及其内存。
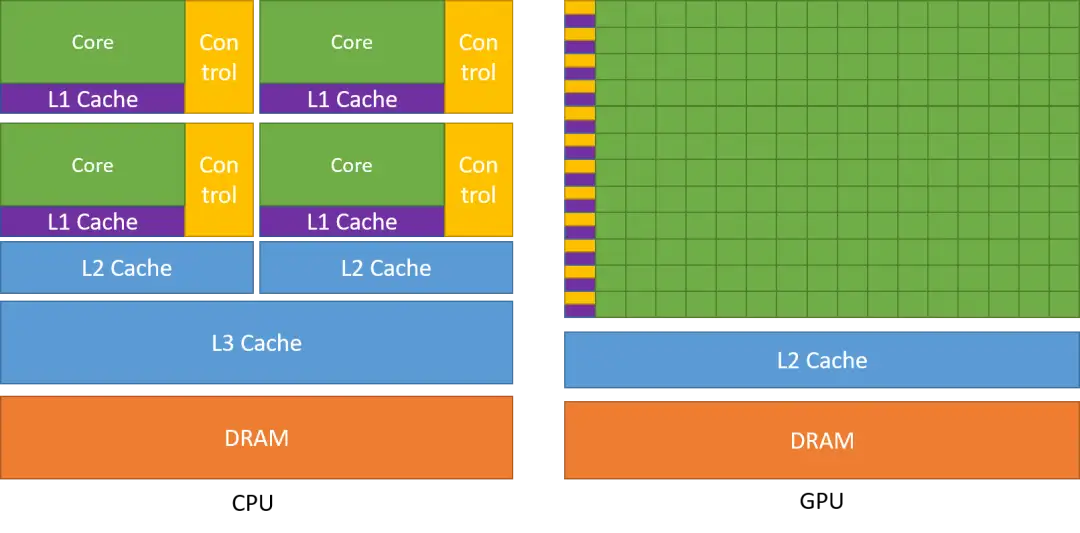
CPU 计算适合处理控制密集型任务,GPU 计算适合处理包含数据并行的计算密集型任务。在 CPU 上执行串行部分或任务并行部分,在 GPU 上执行数据密集型并行部分,这种异构并行架构使得计算能力可以充分被利用。
NVIDIA GPU 显卡架构发展历程
- Tesla(特斯拉)2008年,应用于早期的 CUDA 系列显卡芯片中,并不是真正意义上的 GPU 芯片。
- Fermi(费米)2010年,是第一个完整的 GPU 计算架构。首款可支持与共享存储结合纯 cache 层次的 GPU 架构,支持 ECC(Error Correcting Code) 的 GPU 架构。
- Kepler(开普勒)2012年,Fermi 的优化版。
- Maxwell(麦克斯韦)2014年,首次支持实时的动态全局光照效果,
- Pascal(帕斯卡)2016年,GPU 将处理器和数据集成在同一个程序包内,以实现更高的计算效率。
- Volta(伏打)2017年,首次将一个 CUDA 内核拆分为FP32 和 INT32 两部分,首次支持混合精度运算,提高了5倍于 Pascal 计算速度,还增加了专用于深度学习的 Tensor Core 张量单元。
- Turing(图灵)2018年,增加了 RT Core 专用光线追踪处理器,将实时光线追踪运算加速至上一代架构的 25 倍,并能以高出 CPU 30 多倍的速度进行电影效果的最终帧渲染。去掉了对 FP64 计算的支持。
- Ampere(安培)2020年,重新支持 FP64,新增异步拷贝指令能够从 global memory 中将数据直接加载到 SM shared memory,降低中间寄存器堆(RF)的需求。新增 BF16 数据类型,专为深度学习优化。
二 CUDA 编程模型
CUDA 是一个通用并行计算平台和编程模型,如下图所示,CUDA 平台可以通过 CUDA 加速库、编译器指令、应用程序编程接口或编程语言接口来使用。后面的章节我们会重点讲解 CUDA C 以及 PyCUDA 的编程。

CUDA 软件体系
CUDA 提供了两层 API 来调用底层 GPU 硬件
- CUDA 驱动 API (CUDA Driver API)
是一种基于句柄的底层接口,大多数对象通过句柄被引用,其函数前缀均为cu,在调用 Driver API 前必须进行初始化,再创建 CUDA 上下文,该上下文关联到特定设备并成为主机线程的当前上下文,通过加载 PTX 汇编形式 或 二进制对象形式 的内核,然后启动内核计算。Driver API 可以通过直接操作硬件执行一些复杂的功能,但其编程较为复杂,难度较大。 - CUDA 运行时 API (CUDA Runtime API)
Runtime API 对 Driver API 进行了一定的封装,隐藏了部分实现细节,因此使用起来更为方便,因此我们更多使用的是 Runtime API。Runtime API 没有专门的初始化函数,它将在第一次调用运行时函数时自动完成初始化。使用时,通常需要包含头文件cuda_runtime.h,其函数前缀均为cuda。
如下图所示
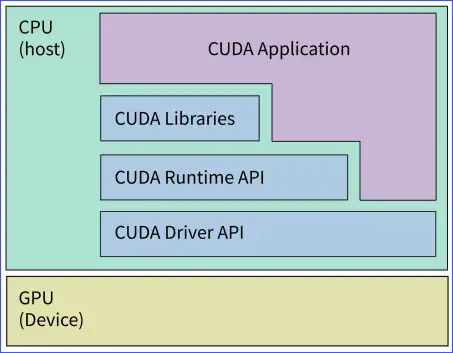
Runtime API 和 Driver API 之间没有明显的性能差距,这两种 API 不能混合使用,只用单独使用其一。
CUDA 函数库 (CUDA Libraries)
CUDA 提供了几个较为成熟的高效函数库,可以直接调用这些库函数进行计算,常见的包括
- CUFFT:利用 CUDA 进行傅立叶变换的函数库
- CUBLAS:利用 CUDA 进行加速的完整标准矩阵与向量的运算库
- CUDPP:并行操作函数库
- CUDNN:利用CUDA进行深度卷积神经网络
CUDA 应用程序 (CUDA Application)
CUDA 程序包含在 host 上运行的主机代码和在 device 上运行的设备代码,设备代码会在编译时通过 CUDA nvcc 编译器从主机代码中分离,再转换成 PTX(ParallelThread Execution) 汇编语言,由 GPU 并行线程执行,主机代码由 CPU 执行。如下图所示
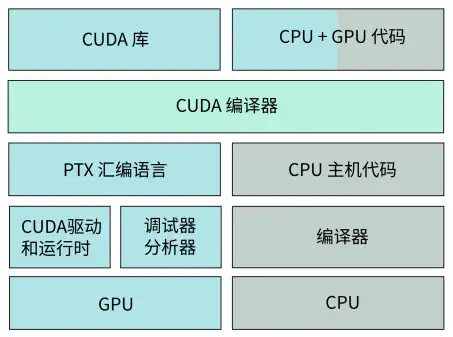
执行流程如下
- 分配 host 内存,并进行数据初始化(CPU初始化)
- 分配 device 内存,并从 host 将数据拷贝到 device 上(GPU初始化)
- 调用 CUDA 的核函数在 device 上完成指定的运算(GPU并行运算)
- 将 device上的运算结果拷贝到 host 上(将GPU结果传回CPU)
- 释放 device 和 host 上分配的内存(初始化清空)
CUDA 硬件结构
- SP(Streaming Processor)也称为 CUDA core,是最基本的处理单元,最后具体的指令和任务都是在 SP 上处理的。GPU 进行并行计算,也就是很多个 SP 同时做处理。
- SM(Streaming Multiprocessor)多个 SP 加上其他资源组成一个 SM,也叫 GPU 大核,其他资源如包括warp scheduler,register,shared memory 等。SM可以看做GPU的心脏(类似 CPU 核心)。每个 SM 都拥有 register 和 shared memory,CUDA 将这些资源分配给所有驻留在 SM 中的线程,但资源非常有限,SM 结构如下图所示。
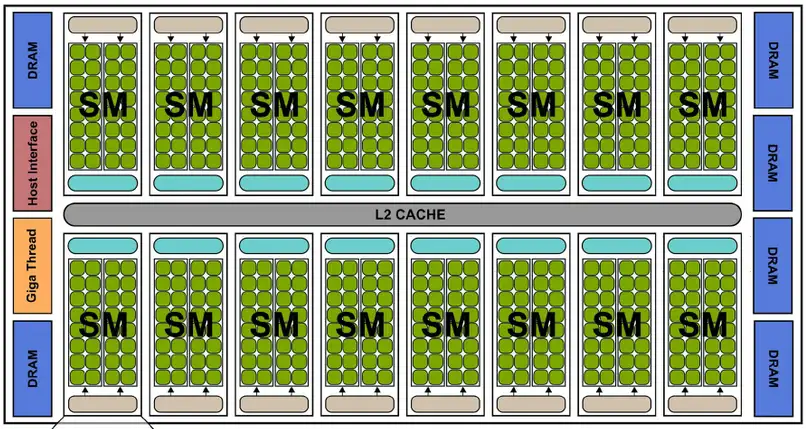
每个 SM 包含的 SP 数量依据 GPU 架构而不同,如 Fermi 架构 GF100 是 32 个,GF10X 是 48 个,Kepler 架构都是 192 个,Maxwell 都是128 个。

在软件逻辑上是所有 SP 是并行计算的,但是物理上并不是,比如只有 8 个 SM 却有 1024 个线程块需要调度处理,因为有些会处于挂起,就绪等其他状态,这有关 GPU 的线程调度,后续章节会展开讨论。
三 理解 kernel, thread, block , grid 与 warp
CUDA 线程模型
线程是程序执行的最基本单元,CUDA 的并行计算通过成千上万个线程的并行执行来实现。下图为 GPU 的线程结构
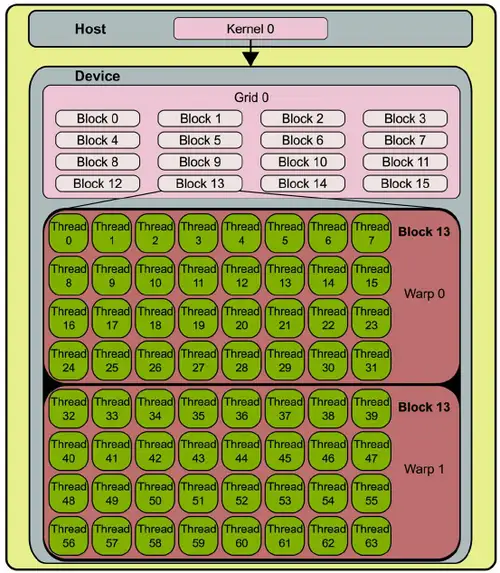
CUDA的线程模型从小往大依次是
- Thread,线程,并行的基本单位
- Block,线程块,互相合作的线程组,线程块有如下几个特点:
- 以1维、2维或3维组织
- 允许彼此同步
- 可以通过共享内存快速交换数据
- Grid,网格,由一组 Block 组成
- 共享全局内存
- 以1维、2维组织
kernel
kernel 是在 device 上线程中并行执行的函数,是软件概念,核函数用__global__符号声明,并用 <<<grid, block>>> 执行配置语法指定内核调用的 CUDA 线程数,每个 kernel 的 thread 都有一个唯一的线程 ID,可以通过内置变量在内核中访问。block 一旦被分配好 SM,该 block 就会一直驻留在该 SM 中,直到执行结束。一个 SM 可以同时拥有多个 blocks。
warp
warp 是 SM 的基本执行单元,也称线程束,一个 warp 有 32 个并行的 thread, SM 旨在同时执行数百个 thread,为了管理如此大量的线程,采用了 SIMT (Single-Instruction, Multiple-Thread:单指令,多线程)的架构,也就是一个 warp 中的所有 thread 一次执行一条公共指令,并且每个thread会使用各自的data执行该指令。
一个块中的 warp 总数计算如下
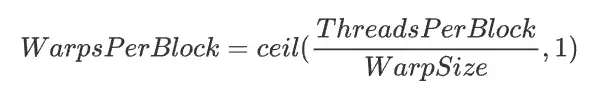
对应下图
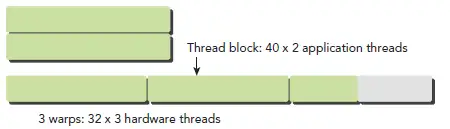
从硬件角度来看,所有的 thread 以一维形式组织,每个 thread 都有个唯一的 ID,于是作为补全整数倍的 thread 在所在的 warp 中为 inactive 状态,会额外消耗 SM 资源,所以要设定 block 中的 thread 一般为32的倍数。
下面从硬件角度和软件角度解释 CUDA 的线程模型
| 软件 | 硬件 | 描述 |
|---|---|---|
| Thread | SP | 每个线程由每个线程处理器(SP)执行 |
| Block | SM | 线程块由多核处理器(SM)执行 |
| Grid | Device | 一个 kernel 由一个 grid 来执行,一次只能在一个 GPU 上执行 |
线程索引
确定线程的唯一索引,以 2D grid 和 2D block 的情况为例。
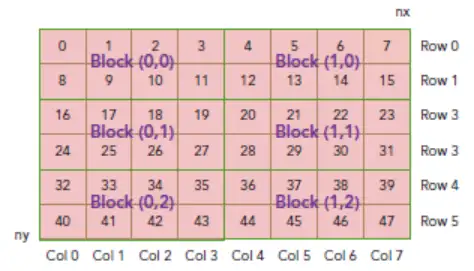
我们要计算的数值矩阵在内存中是 row-major(行主序) 线性存储的,如下图
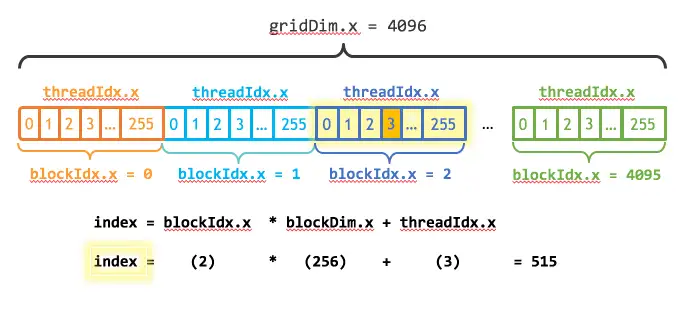
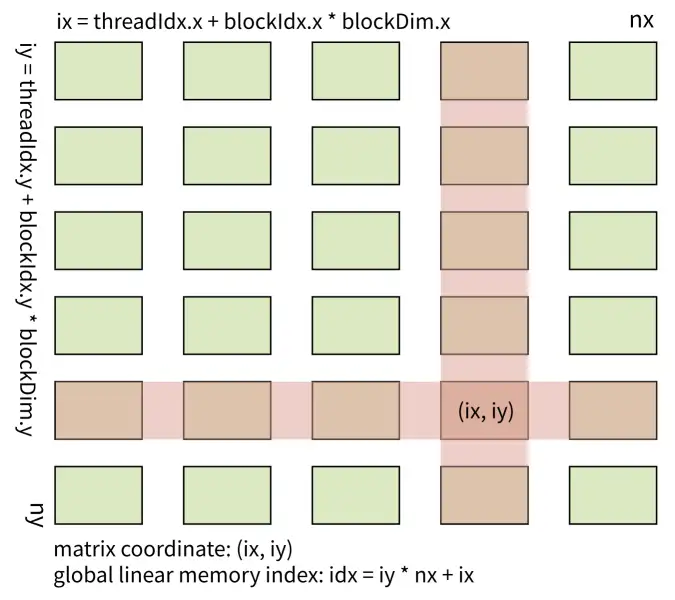
将 thread 和 block 索引映射到矩阵坐标
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
idx = iy * nx + ix
下图为 block 和 thread 索引,矩阵坐标以及线性地址之间的关系
在实践应用中,常常会多一维 grid, 那就是三维情况的索引,如下图所示,设 (gridDim.x,gridDim.y) = (2,3), (blockDim.x,blockDim.y) = (4,2),我们以 thread_id(3,1) block_id(0,1) 为例
可以得到
ix = threadIdx.x + blockIdx.x * blockDim.x = 3 + 0 * 4 = 3
iy = threadIdx.y + blockIdx.y * blockDim.y = 1 + 1 * 2 = 3
coordinate(3,3)
global index: idx = iy * blockDim.x * gridDim.x + ix = 3 * 4 * 2 + 3 = 27
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorRT教程(六)使用Python和C++部署YOLOv5的TensorRT模型
姿态估计端到端新方案 | DirectMHP:用于全范围角度2D多人头部姿势估计
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
标签:教程,CPU,API,线程,CUDA,SM,GPU,概述 From: https://www.cnblogs.com/wxkang/p/17164254.html