前言 本文介绍的这篇文章提供了关于扩散模型从其训练数据中复制内容的潜力的重要见解,这项研究可以帮助改进扩散模型的设计和训练,确保它们能够生成独特的原创艺术和图形,非常值得大家借鉴。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
Title: <Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models>
Paper: https://arxiv.org/pdf/2212.03860.pdf
Github: Just get the point.
导读
 Cutting-edge diffusion models
Cutting-edge diffusion models
稳定扩散模型(Stabel diffusion model)是扩散模型的一种,凭借着生成高质量图像并具有高度定制性而闻名。它通过使用扩散的数学模型来生成具有独特抽象外观的图像来实现这一点。
稳定扩散模型的关键特征之一是它能够复制训练数据。这意味着它能够通过拼凑它从训练数据中记住的前景和背景对象来创建新图像。这使得模型能够生成与训练数据具有相似视觉风格的图像,同时仍然保持高水平的原创性和创造力。
总的来说,稳定扩散模型是一个强大的工具,用于生成独特而原始的图像,同时也能复制其训练数据的视觉风格。这使得它成为艺术家和设计师的首选,通过利用这类模型来创建高品质的艺术和图形。
需要注意的是,使用扩散模型来创作艺术或图形设计并不一定意味着从训练数据中复制。事实上,好的扩散模型旨在生成独特的原始图像,即使在大型数据集上进行训练也是如此。但是,正如作者提到的,这些模型有可能从它们的训练数据中复制内容,特别是在训练集很小或模型没有得到适当训练的情况下。
在这篇工作中,作者将研究图像检索框架,这些框架可用于将生成的图像与训练样本进行比较,并检测内容何时被复制。通过将这些框架应用于在各种数据集上训练的扩散模型,我们可以探索训练集大小等因素如何影响内容复制的可能性。此外,作者还确定了扩散模型(包括流行的稳定扩散模型)直接从其训练数据中复制内容的特定情况。
整体来说,这篇工作提供了关于扩散模型从其训练数据中复制内容的潜力的重要见解,这项研究可以帮助改进扩散模型的设计和训练,确保它们能够生成独特的原创艺术和图形,非常值得大家借鉴。
动机
透过本篇论文,我们尝试用较大的篇幅为大家介绍扩散模型目前的发展近况。
扩散模型的快速崛起导致了新的生成工具的出现,这些工具有可能用于商业艺术和平面设计。这些工具基于扩散的数学模型,用于生成独特且抽象的图像。
扩散模型成功的关键原因之一是它们依赖于简单的降噪网络。当训练包含数十亿图像标题对的大型数据集时,这些网络能够保持其稳定性。这使得扩散模型在训练非常大的数据集时仍能生成高质量的图像,成为商业艺术和平面设计的强大工具。
然而,使用巨型数据集来训练商业模型(如DALL·E和Stable Diffusion)可能带来的法律和道德风险。由于这些数据集太大,人类很难仔细地对它们进行策划,并确保数据源合法且具有适当的知识产权。这可能会导致人们对扩散模型生成的输出的原创性产生疑虑。
此外,大模型记忆训练数据的能力意味着,扩散模型有可能直接复制训练集中的数据,或在没有适当归属的情况下展示多个训练图像的拼贴画。这引发了关于使用扩散模型进行商业用途的伦理和合法性的问题,并突显出进一步研究这些模型在这种情况下潜在风险和影响的必要性。
所以,模型究竟是真正学会了,还是仅仅学会了copy-paste?让我们记住这个问题。
原则上来说,复制训练数据的部分或完整信息对于扩散模型的合法使用具有相关性,特别是对于对艺术家和摄影师的归属。此外,复制品有时会是有益的,有时会是有害的。在某些情况下,内容复制可能被认为是可接受或合法使用的,而在其他情况下,它可能被认为是偷窃。不过这不属于本文探讨的范围,作者旨在研究和探讨扩散模型究竟只会复制已有的模式还是会创造新的模式。
贡献
本文主要研究如何检测内容复制,并考虑了自监督学习和图像检索社区中开发的一系列图像相似度度量。此外,通过使用真实的和专门构建的合成数据集对不同的图像特征提取器的性能进行了基准测试。
借助强大的工具,作者在一系列具有不同数据集属性的扩散模型中搜索数据复制行为。他们表明,对于小型和中型数据集,复制经常发生,而对于在大型和多样化的 ImageNet 数据集上训练的模型,复制似乎是无法检测到的。
或者是还没足够的能力检测到这种复制行为?
从表面来看,复制对于大规模模型不是问题。但是,更大的 Stable Diffusion 模型在各种形式中都表现出明显的复制(如上图所示)。此外,作者相信,在 Stable Diffusion 中确定的内容复制率很可能低估了真实率,因为该模型是在 LAION 的大型 2B 图像分割上进行训练的,但作者只在 12M 图像 aesthetics 子集中搜索匹配。
实际上,某事物被认为是复制所需的图像相似度比较是非常主观的,可能取决于图像类别内的多样性以及观察者。作者发现的一些复制行为是明确的,而在其他情况下它们处于模糊状态。
背景
图像检索与复制检测
搜索数据库以查找包含来源图像参考特征的图像的过程被称为图像检索。相关的不精确复制检测任务需要源图像和匹配图像之间具有高语义相似性。图像检索使用基于所有类型神经网络的图像描述符。高性能描述符可以在无监督训练后使用结构光流或对比目标进行特定调整以进行检索。图像检索方法的自然基础是自监督模型,它们天生学会强大的特征描述符,将相似图像与相似表示相匹配。例如,一种特别相关的 SSL 方法便是 DINO,它被证明在实例检索任务中表现出色。
近年来许多方法采用 Transformer 作为检索的架构骨干。公共图像相似性挑战跟踪了该领域的历史进展。最近的 SOTA 方法是 SSCD,它建立在之前自监督表示学习的工作之上,并使用熵正则化和一系列特定于任务的数据扩充优化了用于复制检测的描述符。
深度学习中的记忆
尽管大家都知道大模型可以记忆数据,但没有普遍接受的记忆定义。对于 ML 专家来说,记忆与过拟合是同义词。在成员推断攻击领域,人们寻求确定所选图像是否是训练集的一部分。事实上,已经证明模型保留了训练集内容的记忆,特别是在重复训练样本时。请注意,成员推断可以通过从模型重构原始训练数据来完成,尽管这不是大多数成员推断方法的目标。从分类器的训练集中显式重构图像的问题被称为模型反演,最近的研究已经能够用卷积模型和变换器模型来实现。但是,很重要的一点是要注意记忆、成员推断、反演和复制的关系:记忆数据的生成模型可能允许模型反演或仅允许成员推断,但相同的模型可能永远不会意外地生成训练数据。
语言模型中的记忆
众所周知,生成语言模型因为从训练集中复制数据而存在风险。复制的数据量与模型的大小、训练集中数据点的重复量以及提示词的数量成正比。有趣的是,即使模型没有过拟合训练数据,也会出现这种复制行为。
扩散模型
扩散,其实是一种将样本从高斯噪声分布转换为从任意复杂分布(如自然图像的分布)的样本的过程。其中,稳定扩散是一种最先进的文本条件潜在扩散模型,它在 LAION-5B 数据库上进行了训练,并使用来自 laionaesthetics v2 5+ 子集的 1200 万张图像进行了微调,该子集按图像质量进行了过滤。
复制
上面我们一直在说,扩散模型很可能存在复制行为,那究竟什么是复制呢?
首先,让我们考虑定义一个生成图像的复制内容,如果它包含一个对象(前景或背景),在训练图像中完全相同,忽略可能由数据增强产生的外观的微小变化。在这个定义的基础上,设计一个检测复制内容的系统是一个有挑战性的任务,因为为了确定生成图像中对象是否与训练图像中对象完全相同,检测系统需要准确地识别和比较两个图像中的对象,这对于机器学习模型来说是一个困难的任务,因为它需要高度的视觉理解能力以及推广到新图像的能力。因此,设计一个检测复制内容的系统可能需要大量的研究和开发。
因此,一种好的思路是仅关注对象级别的相似性,同时尽可能忽视由数据增强解释的外观上的小差异,因为这些变化通常与版权声明无关。另一个概念是风格相似或语义相似。我们这里不关注这样的定义,因为它们具有高度主观性,通常不被认为是知识产权侵权,也因为许多图像缺乏明确的风格(例如,标准相机的自然未过滤图像)。
本文的目标是构建一个检测复制内容的系统,根据上面的定义。为了找到一个强大的系统,作者考虑了 10 种不同的特征提取器原型,从 SSL 和图像检索文献中得到。通过使用 10 种不同的数据集(包括合成数据集和真实数据集)来比较和对比这些方法,这些数据集通常可用于衡量复制检测器的性能。

感觉兴趣的小伙伴可以直接查阅原论文,下面让我们从定性和定量的角度观察模型是否真的再复制。
定性观察
先来看两张实验的结果对比图。
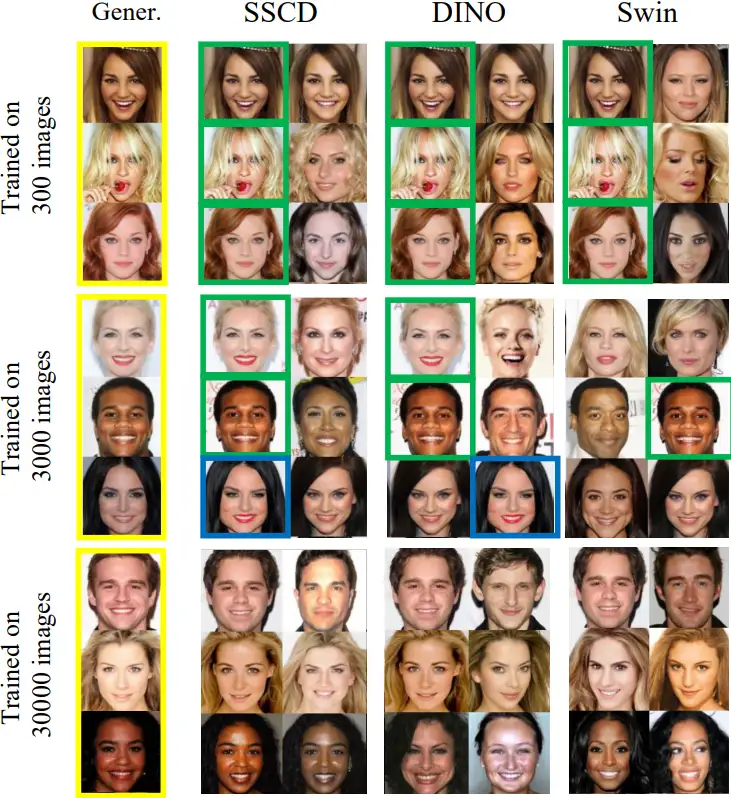 图3
图3
可以看到,当训练数据集规模为 300、3000 和 30000 时,多数模型都能够生成与训练图像完全相同的图像(用绿色框标出)。然而,在训练整个数据集的模型中,第一个匹配非常相似,但并不完全相同。(用蓝色框标出)
 图4
图4
上图中的每一行展示了基于 DINO split-product 提取器的给定生成的前 6 个匹配,可以看到,从上到下,完全复制的情况逐渐减少。
总的来说,上述图片显示了生成的图像及其对应的训练数据集中的最优匹配。该实验结果考虑了训练数据量不同的扩散模型DDPM。在 Celeb-A 数据集下,训练了 300 和 3000 张图像的扩散模型明显从它们的训练图像复制。然而,当模型训练了整个数据集时,生成的图像可能与训练样本相似,但不完全相同。我们在训练了 Oxford Flowers 数据集的扩散模型中也观察到了类似的趋势。有趣的是,训练了 1083 张图像的模型已经能够创建唯一的训练数据变化。请注意,上面的样本并不是作者精心挑选出来的,而是从 20 张与训练数据的 top-1 相似度最高的图像中选择的。
定量分析
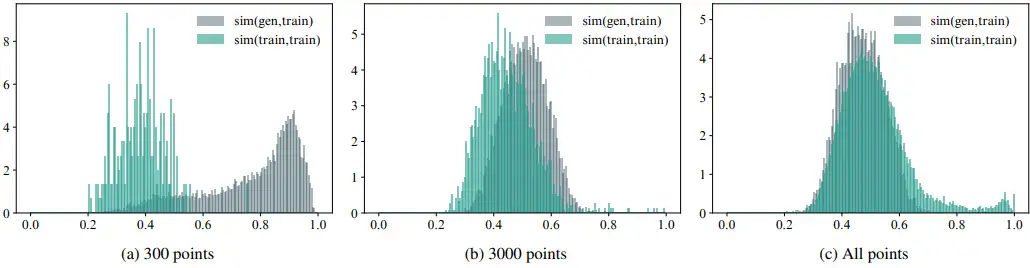 图5
图5
另一方面,作者检查了生成的图像和训练样本之间相似性分数的分布。上图显示的是包含几个迭代之间相似性得分的直方图以及它们与训练数据的最佳匹配。作为baseline,文中还绘制随机训练图像并计算与剩余训练图像最接近的匹配的相似度。如果生成的图像和训练图像之间的大多数分数位于该基线的右侧,则该模型生成的图像与其训练样本之间的距离比训练样本之间的距离更近。
上图中的柱状图展示了生成图像与其训练数据集中的最佳匹配之间的相似性分数的分布。例如,当训练数据集规模为 300 个样本时,大多数生成的图像与训练数据集非常相似,因此具有非常高的相似性分数。然而,当我们将模型训练在 3000 个样本上时,直方图的分布中心明显向左移动。虽然可以观察到这个模型的明显复制行为,但这种现象非常罕见,当使用全数据集模型计算的相似性分数的直方图高度重叠。以上充分表明,生成图像(灰色)的直方图不再具有较长的右尾,表明该模型不太可能生成与其训练样本完全相同的图像。请注意,图5(c)中的少量数据集自相似性分数大于0.9,表明训练数据中存在大量重复或近似重复。
总结
本研究的目的是评估扩散模型是否能够从其训练数据中复制高保真内容,根据作者的结论不难发现这种现象是普遍存在的。
虽然大规模模型的典型图像似乎不包含我们的特征提取器可检测到的复制内容,但复制似乎出现得足够频繁,以至于它们的存在不容易被忽略;如下图所示,数据集相似度 ≥.5 的稳定扩散图像占整体随机生成的约 1.88%.
 图 7. 使用从 LAION 图像中采样的字幕选择的稳定扩散生成,相似度得分 ≥ 0.5。
图 7. 使用从 LAION 图像中采样的字幕选择的稳定扩散生成,相似度得分 ≥ 0.5。
其实在 Stable Diffusion 中对复制的搜索仅涵盖了 LAION 数据集 aesthetic split 中的 1200 万张图像。该模型首先在 20 亿张图像上进行训练,然后对 aesthetic split 进行微调,aesthetic split 仅占总训练数据的 0.6%。
即使 LAION-2B 仅用于训练的初始阶段,该模型在微调期间也没有忘记这些数据。它显然能够从 aesthetic split 以外的图像中复制图像——通过在下图可以观察到这一点。
 Stable Diffusion generates the painting “The Scream”
Stable Diffusion generates the painting “The Scream”
此外,还有一个可能便是本文作者提供的检索方法无法识别存在复制。由于这两个原因,这里的结果系统性地低估了稳定扩散和其他模型中的复制数量。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度
入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet
标签:学到,一文,训练,模型,剖析,复制,图像,扩散,数据 From: https://www.cnblogs.com/wxkang/p/17161569.html