概览
Kafka Connect 是一种用于在 Apache Kafka 和其他系统之间可扩展且可靠地流式传输数据的工具。 它使快速定义将大量数据移入和移出 Kafka 的连接器变得简单。 Kafka Connect 可以摄取整个数据库或从所有应用程序服务器收集指标到 Kafka 主题中,使数据可用于低延迟的流处理。 导出作业可以将数据从 Kafka 主题传送到二级存储和查询系统或批处理系统进行离线分析。
Kafka Connect有什么优势:
- 数据中心管道 - 连接使用有意义的数据抽象来拉或推数据到Kafka。
- 灵活性和可伸缩性 - Connect可以在单个节点(独立)上与面向流和批处理的系统一起运行,也可以扩展到整个集群的服务(分布式)。
- 可重用性和可扩展性 - Connect利用现有的连接器或对其进行扩展,以适应您的需要,并缩短生产时间。
Kafka Connect专注于Kafka之间的数据流,让你可以更简单地编写高质量、可靠和高性能的连接器插件。Kafka Connect还使框架能够保证使用其他框架很难做到的事情。当与Kafka和流处理框架结合时,Kafka Connect是ETL管道的一个不可或缺的组件。
为了更有效地讨论Kafka Connect的内部工作原理,我们需要建立几个主要的概念。
- Connector:通过管理任务来协调数据流的高级抽象
- Tasks:描述如何从Kafka复制数据
- Workers:执行连接器和任务的运行进程
- Converters:用于在 Connect 和发送或接收数据的系统之间转换数据的代码
- Transforms:改变由连接器产生或发送到连接器的每条消息的简单逻辑
- Dead Letter Queue:Connect 如何处理连接器错误
Connector
Kafka Connect 中的连接器定义了数据应该复制到哪里和从哪里复制。 连接器实例是一个逻辑作业,负责管理 Kafka 和另一个系统之间的数据复制。 连接器实现或使用的所有类都在连接器插件中定义。 连接器实例和连接器插件都可以称为“连接器”。

Kafka Connect可以很容易地将数据从多个数据源流到Kafka,并将数据从Kafka流到多个目标。Kafka Connect有上百种不同的连接器。其中最流行的有:
- RDBMS (Oracle, SQL Server, DB2, Postgres, MySQL)
- Cloud Object stores (Amazon S3, Azure Blob Storage, Google Cloud Storage)
- Message queues (ActiveMQ, IBM MQ, RabbitMQ)
- NoSQL and document stores (Elasticsearch, MongoDB, Cassandra)
- Cloud data warehouses (Snowflake, Google BigQuery, Amazon Redshift)
Tasks
任务是 Connect 数据模型中的主要参与者。 每个连接器实例协调一组实际复制数据的任务。 通过允许连接器将单个作业分解为多个任务,Kafka Connect 以很少的配置提供了对并行性和可扩展数据复制的内置支持。 这些任务中没有存储状态。 任务状态存储在 Kafka 中的特殊主题 config.storage.topic 和 status.storage.topic 中,并由关联的连接器管理。 因此,可以随时启动、停止或重新启动任务,以提供弹性、可扩展的数据管道。

任务再平衡
当连接器首次提交到集群时,workers会重新平衡集群中的全套连接器及其任务,以便每个workers拥有大致相同的工作量。 当连接器增加或减少它们需要的任务数量时,或者当连接器的配置发生更改时,也会使用相同的重新平衡过程。 当workers失败时,任务会在活动工作人员之间重新平衡。 当任务失败时,不会触发重新平衡,因为任务失败被视为例外情况。 因此,失败的任务不会由框架自动重新启动,而应通过 REST API 重新启动。

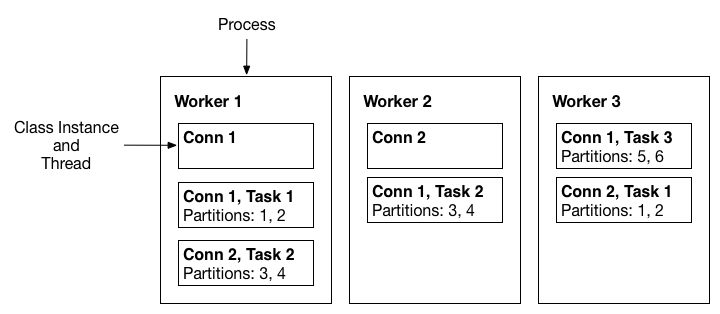
Workers
连接器和任务是工作的逻辑单元,必须安排在流程中执行。 Kafka Connect 将这些进程称为Worker,并且有两种类型的worker:独立的和分布式的。
独立的workers
独立模式是最简单的模式,其中一个进程负责执行所有连接器和任务。
由于它是单个进程,因此需要最少的配置。 独立模式便于入门、开发期间以及某些只有一个进程有意义的情况,例如从主机收集日志。 但是,因为只有一个进程,所以它的功能也更有限:可扩展性仅限于单个进程,除了您添加到单个进程的任何监控之外,没有容错能力。
分布式workers
分布式模式为 Kafka Connect 提供了可扩展性和自动容错能力。 在分布式模式下,您使用相同的 group.id 启动许多工作进程,它们会自动协调以安排所有可用workers之间的连接器和任务的执行。 如果您添加workers、关闭workers或workers意外失败,其余workers会检测到这一点并自动协调以在更新的可用workers之间重新分配连接器和任务。 请注意与消费者组重新平衡的相似性。 在后台,连接workers正在使用消费者群体进行协调和重新平衡。
具有相同 group.id 的所有工作人员将在同一个连接集群中。 例如,如果worker-a 的group.id=connect-cluster-a 和worker-b 的group.id 相同,则worker-a 和worker-b 将组成一个名为connect-cluster-a 的集群。
Converters
在向 Kafka 写入或从 Kafka 读取数据时,转换器是必要的,以使 Kafka Connect 部署支持特定的数据格式。 任务使用转换器将数据格式从字节更改为 Connect 内部数据格式,反之亦然。
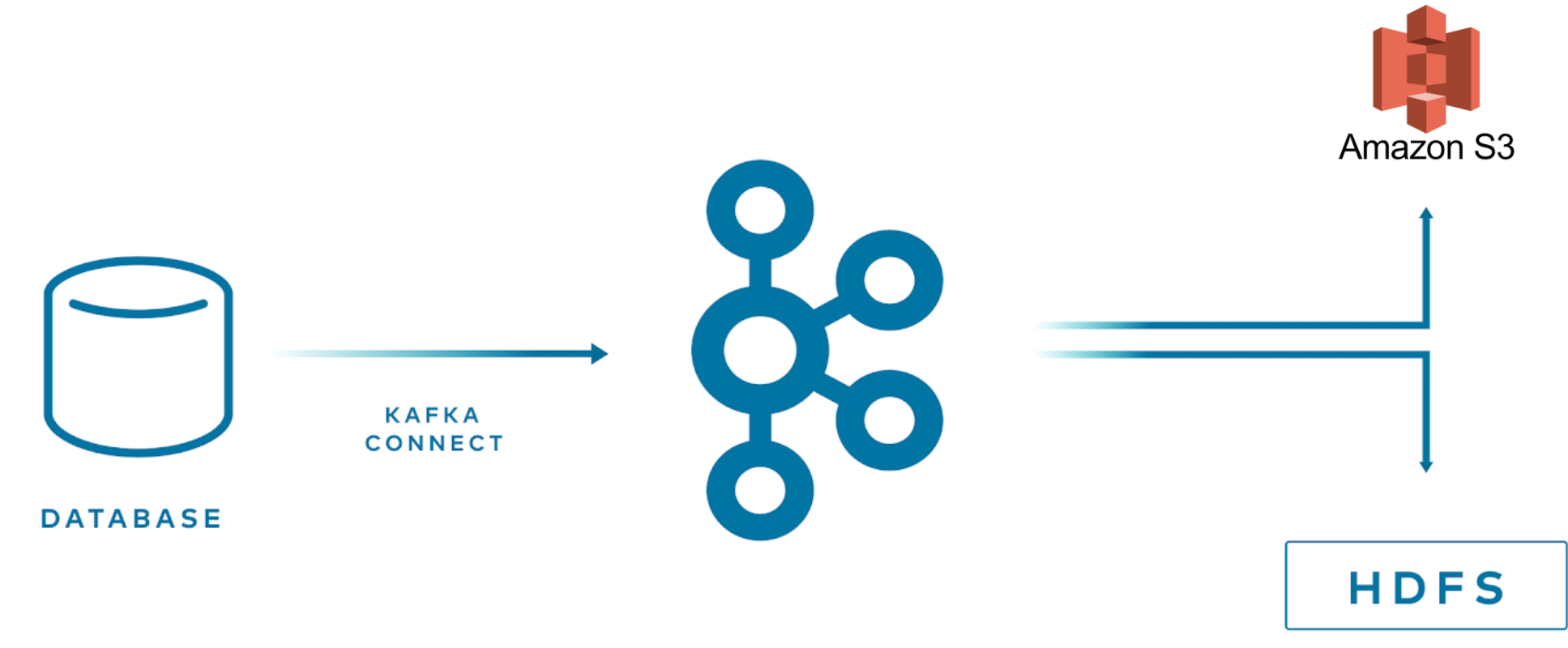
转换器与连接器本身分离,以允许自然地在连接器之间重用转换器。 例如,使用相同的 Avro 转换器,JDBC Source Connector 可以将 Avro 数据写入 Kafka,而 HDFS Sink Connector 可以从 Kafka 读取 Avro 数据。 这意味着可以使用相同的转换器,例如,JDBC 源返回一个最终作为 parquet 文件写入 HDFS 的 ResultSet。
下图显示了在使用 JDBC 源连接器从数据库读取、写入 Kafka 以及最后使用 HDFS 接收器连接器写入 HDFS 时如何使用转换器。

Transforms
连接器可以配置转换以对单个消息进行简单和轻量级的修改。这对于细微的数据调整和事件路由很方便,并且可以在连接器配置中将多个转换链接在一起。
转换是一个简单的函数,它接受一个记录作为输入并输出一个修改过的记录。 Kafka Connect 提供的所有转换都执行简单但通常有用的修改。请注意,您可以使用自己的自定义逻辑实现 Transformation 接口,将它们打包为 Kafka Connect 插件,并将它们与任何连接器一起使用。
当转换与源连接器一起使用时,Kafka Connect 将连接器生成的每个源记录传递给第一个转换,它进行修改并输出新的源记录。这个更新的源记录然后被传递到链中的下一个转换,它生成一个新的修改源记录。这对于剩余的变换继续。最终更新的源记录转换为二进制形式写入Kafka。
转换也可以与接收器连接器一起使用。 Kafka Connect 从 Kafka 读取消息并将二进制表示转换为接收器记录。如果有转换,Kafka Connect 将通过第一个转换传递记录,该转换进行修改并输出一个新的、更新的接收器记录。更新后的接收器记录然后通过链中的下一个转换,生成新的接收器记录。对于剩余的转换,这将继续,然后将最终更新的接收器记录传递给接收器连接器进行处理。
Dead Letter Queue
由于多种原因,可能会出现无效记录。 一个例子是当一条记录到达以 JSON 格式序列化的接收器连接器时,但接收器连接器配置需要 Avro 格式。 当接收器连接器无法处理无效记录时,将根据连接器配置属性 errors.tolerance 处理错误。
死信队列仅适用于接收器连接器。
此配置属性有两个有效值:none(默认)或 all。
当errors.tolerance 设置为none 时,错误或无效记录会导致连接器任务立即失败并且连接器进入失败状态。 要解决此问题,您需要查看 Kafka Connect Worker 日志以找出导致故障的原因、纠正它并重新启动连接器。
当errors.tolerance 设置为all 时,所有错误或无效记录都将被忽略并继续处理。 没有错误写入 Connect Worker 日志。 要确定记录是否失败,您必须使用内部指标或计算源处的记录数并将其与处理的记录数进行比较。
Kafka Connect是如何工作的?
您可以将 Kafka Connect 部署为在单台机器上运行作业的独立进程(例如日志收集),也可以部署为支持整个组织的分布式、可扩展、容错服务。 Kafka Connect 提供了低门槛和低运营开销。 您可以从小规模的独立环境开始进行开发和测试,然后扩展到完整的生产环境以支持大型组织的数据管道。
Kafka Connect包括两个部分:
- Source连接器 – 摄取整个数据库并将表更新流式传输到 Kafka 主题。 源连接器还可以从所有应用程序服务器收集指标并将这些指标存储在 Kafka 主题中,从而使数据可用于低延迟的流处理。
- Sink 连接器——将数据从 Kafka 主题传送到二级索引(例如 Elasticsearch)或批处理系统(例如 Hadoop)以进行离线分析。
Kafka Connect使用场景
任何时候,当你想把数据从另一个系统流到Kafka,或者把数据从Kafka流到其他地方,Kafka Connect应该是你的第一个调用端口。下面是一些使用Kafka Connect的常见方式:
流数据管道
Kafka Connect 可用于从事务数据库等源中摄取实时事件流,并将其流式传输到目标系统进行分析。 由于 Kafka 将数据存储到每个数据实体(主题)的可配置时间间隔内,因此可以将相同的原始数据向下传输到多个目标。 这可能是针对不同的业务需求使用不同的技术,或者将相同的数据提供给拥有自己的系统来保存数据的业务中的不同领域。
从应用程序写入数据存储

在您的应用程序中,您可以创建要写入目标系统的数据。 这可能是一系列要写入文档存储的日志事件,也可能是要持久保存到关系数据库的数据。 通过将数据写入 Kafka 并使用 Kafka Connect 负责将数据写入目标,您可以简化占用空间。
将旧系统迁往新系统
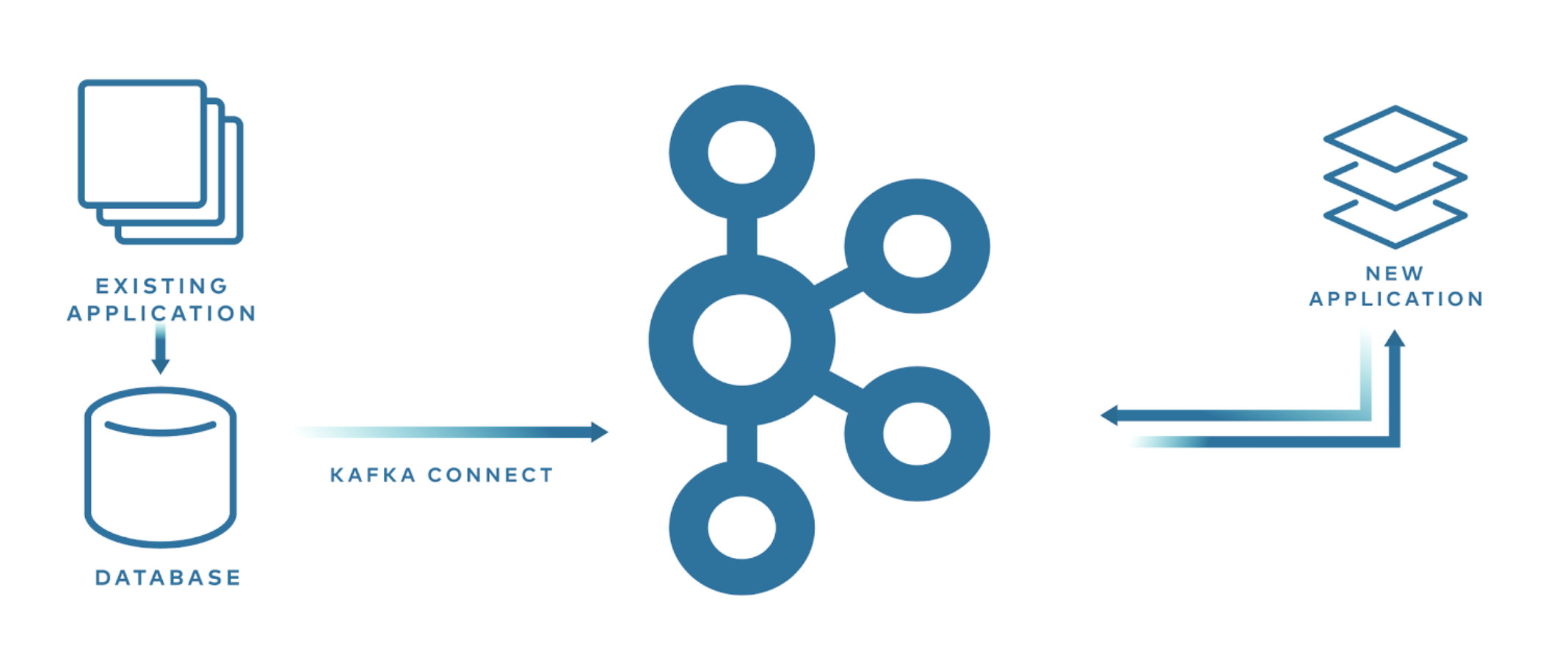
在 NoSQL 存储、事件流平台和微服务等较新的技术出现之前,关系数据库 (RDBMS) 是应用程序中所有数据的实际写入位置。 RDBMS 在我们构建的系统中仍然扮演着非常重要的角色——但并非总是如此。 有时我们会希望使用 Kafka 作为独立服务之间的消息代理以及永久的记录系统。 这两种方法非常不同,但与过去的技术变革不同,它们之间存在一条无缝的路线。
通过利用变更数据捕获 (CDC),可以近乎实时地将数据库中的每个 INSERT、UPDATE 甚至 DELETE 提取到 Kafka 中的事件流中。 CDC 对源数据库的影响非常小,这意味着现有应用程序可以继续运行(并且不需要对其进行任何更改),同时可以构建新应用程序,由从数据库捕获的事件流驱动。 当原始应用程序在数据库中记录某些内容时(例如,订单被接受),任何订阅 Kafka 事件流的应用程序都将能够根据事件采取行动,例如新的订单履行服务。
使您的系统实现实时性
许多组织的数据库中都有静态数据,例如 Postgres、MySQL 或 Oracle,并且可以使用 Kafka Connect 从现有数据中获取价值,将其转换为事件流。 您可以在流管道示例中看到这一点,使用现有数据推动分析。
为什么要使用Kafka Connect而不是自己写一个连接器呢?
Apache Kafka 拥有自己非常强大的生产者和消费者 API 以及支持多种语言的客户端库,包括 C/C++、Java、Python 和 Go。 因此,您想知道为什么不直接编写自己的代码从系统中获取数据并将其写入 Kafka 是非常正确的——编写一小段消费者代码以从系统读取数据是否有意义? 主题并将其推送到目标系统?
问题是,如果您要正确地执行此操作,那么您将意识到您需要满足故障、重新启动、日志记录、弹性扩展和再次缩减以及跨多个节点运行的需求。 那是在我们考虑序列化和数据格式之前。 一旦你完成了所有这些事情,你就编写了一些可能更像 Kafka Connect 的东西,但没有多年的开发、测试、生产验证和社区。
与 Kafka 的流式集成是一个已解决的问题。 可能存在一些适合定制解决方案的边缘情况,但总的来说,您会发现 Kafka Connect 应该是您与 Kafka 集成的第一个有效工具。
标签:记录,workers,Kafka,读懂,Connect,连接器,数据 From: https://www.cnblogs.com/felixzh/p/17151505.html